
什么叫消息队列
有的资料说:消息队列是消息中间件的一种实现方式。
消息(Message)是指在应用间传送的数据。消息可以非常简单,比如只包含文本字符串,也可以更复杂,可能包含嵌入对象。
MQ即消息队列(Message Queue)是一种应用程序之间的通信方式,消息发送后可以立即返回,由消息系统来确保消息的可靠传递。消息发布者只管把消息发布到 MQ 中而不用管谁来取,消息使用者只管从 MQ 中取消息而不管是谁发布的。这样发布者和使用者都不用知道对方的存在。
消息中间件是提供软件和软件之间连接的软件,以便于软件各部件之间的沟通。
使用消息中间件的优势
1.业务调用链短,用户等待时间短。
2.部分组件故障不会瘫痪整个业务
3.业务高峰期有缓冲。
4.业务高峰期不会产生大量的异步线程。
消息中间件的作用
1. .系统异步与解耦。上游系统对下游系统如果同步调用话,则会大大降低系统的吞吐量和并发度,且系统的耦合度太高,而异步调用会解决这个问题
2.限流削峰。如果微服务没有能力去处理超量消息,可以先把超量消息放到MQ中,以便系统可以慢慢处理,进而避免了消息丢失和系统被压垮。
3消息的广播
4.消息收集。分布式系统会产生海量的数据流,如业务日志、监控数据、用户行为等,针对这些数据流进行实时或批量采集汇总,然后对这些数据流进行大数据分析,这是当前互联网平台必备的技术,通过MQ完成此类数据是最好的选择
5.最终一致性处理。我发送到消息中间件的消息,微服务一定会处理。
常见的消息队列
rabbitmq: 延迟最低可以达到微秒,并发能力极强。其吞吐量相较于kafka和racoketmq小
kafka:延迟可以达到毫秒(ms)数据写在磁盘上,其最大的特点就是高吞吐率,常用于大数据领域的实时计算,日志采集等领域,其没有遵循任何的MQ协议,使用其自研的协议。
racoket,使用java编写的MQ产品,性能和稳定性非常高,其没有遵循任何的MQ协议,使用其自研的协议。
为何用消息队列
消息队列是一种应用见的异步作机制
我们想象一下我们注册的的情景,当我们提交注册后服务器的操作
1.检测用户返回的字段是否符合要求。
2.如果符合要求,则把注册信息填入到数据库中。
3.给用户发送注册成功邮箱。
4.分析用户的注册信息,以便以后给用户推荐相应的信息。
5.返回注册成功页面。
对于用户来说,它提交完信息后,只需要知道注册成功了没有,其他的它根本就不用立马知道,他就可以去做其他的事情。所以服务器只需要顺序执行1.2.5步操作就可以了,其他的不需要立即执行的操作,可以放到消息队列中来,这样对于用户来说,节省了请求的时间,可以取干其他事情,同时放到消息队列中的操作,对于用户来说是异步操作。
消息队列的特点和作用
消息队列的特点是异步处理,主要目的是减少用户请求的时间和解耦。
应用场景:将比较耗时不需要立即返回结果的操作放到消息队列中,把需要立即返回结果的操作先执行完。其实就是用在大并发的时候。
消息中间件最主要的作用是解耦,中间件最标准的用法是生产者生产消息传送到队列,消费者从队列中拿取消息并处理,生产者不用关心是谁来消费,消费者不用关心谁在生产消息,当消费者需要拿数据的时候,只需要和消息队列沟通,如果有就拿,如果没有就等待,当消息队列中消息满了,消息队列会告诉生产者别先生产了。这样看来生产者和消费者之间解耦了,生产者不用等待消费吃完再生产东西,消费者不用等待生产者把所有的东西都吃完再生产包子,从而达到解耦的目的。在分布式的系统中,消息队列也会被用在很多其它的方面,比如:分布式事务的支持,RPC的调用等等。
- 应用解耦
- 提速
- 广播
- 消峰
具体内容见
https://www.zhihu.com/question/34243607/answer/58314162 下边祁达方的回答
RabbitMQ
RabbitMQ 是一个由 Erlang 语言开发的 AMQP 的开源实现。rabbitMQ是一款基于AMQP协议的消息中间件,它能够在应用之间提供可靠的消息传输。在易用性,扩展性,高可用性上表现优秀。使用消息中间件利于应用之间的解耦,生产者(客户端)无需知道消费者(服务端)的存在。而且两端可以使用不同的语言编写,大大提供了灵活性。
rabbitmq高性能的原因
RabbitMQ 是一个由 Erlang 语言开发的,erlang是一门为交换机软件开发诞生的编程语言
erlang语言的特点:
erlang是通用的面向并发的编程语言,适用于分布式系统。
基于虚拟机解释运行,跨平台部署
erlang语言进程间上下文切换的效率远高于c语言和java语言
有着和原生socket一样的延迟,网络i/o的性能极高
AMQP
amqp协议作为rabbitmq的规范,规定了rabbitmq对外的接口
AMQP :Advanced Message Queue,高级消息队列协议。它是应用层协议的一个开放标准,为面向消息的中间件设计,基于此协议的客户端与消息中间件可传递消息,并不受产品、开发语言等条件的限制。
RabbitMQ 最初起源于金融系统,用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗。具体特点包括:
-
可靠性(Reliability)
RabbitMQ 使用一些机制来保证可靠性,如持久化、传输确认、发布确认。 -
灵活的路由(Flexible Routing)
在消息进入队列之前,通过 Exchange 来路由消息的。对于典型的路由功能,RabbitMQ 已经提供了一些内置的 Exchange 来实现。针对更复杂的路由功能,可以将多个 Exchange 绑定在一起,也通过插件机制实现自己的 Exchange 。 -
消息集群(Clustering)
多个 RabbitMQ 服务器可以组成一个集群,形成一个逻辑 Broker 。 -
高可用(Highly Available Queues)
队列可以在集群中的机器上进行镜像,使得在部分节点出问题的情况下队列仍然可用。 -
多种协议(Multi-protocol)
RabbitMQ 支持多种消息队列协议,比如 STOMP、MQTT 等等。 -
多语言客户端(Many Clients)
RabbitMQ 几乎支持所有常用语言,比如 Java、.NET、Ruby 等等。 -
管理界面(Management UI)
RabbitMQ 提供了一个易用的用户界面,使得用户可以监控和管理消息 Broker 的许多方面。 -
跟踪机制(Tracing)
如果消息异常,RabbitMQ 提供了消息跟踪机制,使用者可以找出发生了什么。 -
插件机制(Plugin System)
RabbitMQ 提供了许多插件,来从多方面进行扩展,也可以编写自己的插件。
作者:预流
链接:https://www.jianshu.com/p/79ca08116d57
來源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
rabbitMQ安装
ubuntu安装教程博客”: https://blog.csdn.net/u010889616/article/details/80643892
如果是阿里云服务器的话,别忘记配置安全组
for Linux: 安装配置epel源 $ rpm -ivh http://dl.fedoraproject.org/pub/epel/6/i386/epel-release-6-8.noarch.rpm 安装erlang $ yum -y install erlang 安装RabbitMQ $ yum -y install rabbitmq-server 注意:service rabbitmq-server start/stop
for Mac: bogon:~ yuan$ brew install rabbitmq bogon:~ yuan$ export PATH=$PATH:/usr/local/sbin bogon:~ yuan$ rabbitmq-server
rabbitMQ工作模型
模拟软件网址:http://tryrabbitmq.com/
简单模式
即exchange=" ",也就是说简单模式不用exchange模式,直接把数据放到队列中
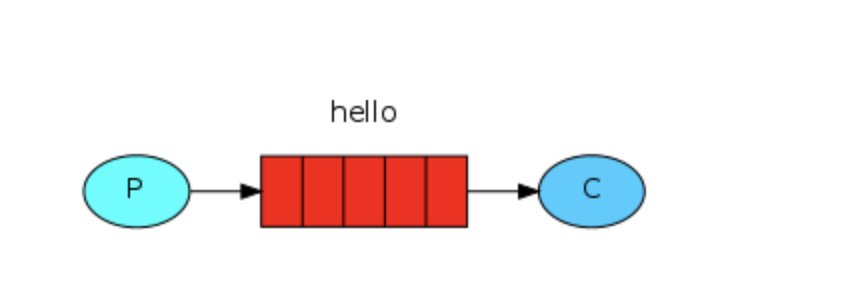
#生产者 import pika # 创建通向rabbitmq的连接 connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) # 获取rabbitmq通信的接口;channel channel = connection.channel() # 在rabbitmq通过channel创建一个队列:hello队列 channel.queue_declare(queue='q1',durable=True) #使用默认exchange时允许通过routing_key明确指定message将被发送给哪个queue #body参数指定了要发送的message内容 channel.basic_publish(exchange='', #工作模式为简单模式 routing_key='q1',#指定队列名字 body=('china'))#生产者生产的东西 print(" 生产者 Sent 'Hello World!'") #关闭与rabbimq Server间的连接 connection.close()
####消费者 import pika connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) # 获取rabbitmq通信的接口;channel channel = connection.channel() #在rabbitmq通过channel创建一个队列:hello队列,目的是,不管谁先启动都可以,这是一个好习惯 channel.queue_declare(queue='q1') #定义回调函数,一旦从queue中接收到一个message回调函数将被调用 def callback(ch, method, properties, body): #回调函数, print(" [x] Received %r" % body) #告诉rabbitmq使用callback来接收数据 channel.basic_consume(callback, queue='q1', no_ack=True)#默认是true,不对消息进行确认 print(' [*] Waiting for messages. To exit press CTRL+C') #开始循环从queue中接收message并使用callback进行处理 channel.start_consuming()
相关参数
(1)no-ack = False,是为了避免消费者客户端崩掉了,拿不到数据,如果消费者的客户端崩掉了,那么,RabbitMQ会重新将该任务添加到队列中。这样唯一的缺陷是效率变慢了.
- 回调函数中的
ch.basic_ack(delivery_tag=method.delivery_tag) - basic_comsume中的
no_ack=False
消息接收端应该这么写:

import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='10.211.55.4'))
channel = connection.channel()
channel.queue_declare(queue='hello')
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
import time
time.sleep(10)
print 'ok'
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_consume(callback,
queue='hello',
no_ack=False)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
(2) durable =True:防止rabbitMQ突然崩掉,队列中的消失消失,
# 生产者 #!/usr/bin/env python import pika connection = pika.BlockingConnection(pika.ConnectionParameters(host='10.211.55.4')) channel = connection.channel() # make message persistent channel.queue_declare(queue='hello', durable=True)########## channel.basic_publish(exchange='', routing_key='hello', body='Hello World!', properties=pika.BasicProperties( delivery_mode=2, # make message persistent )) print(" [x] Sent 'Hello World!'") connection.close() # 消费者 #!/usr/bin/env python # -*- coding:utf-8 -*- import pika connection = pika.BlockingConnection(pika.ConnectionParameters(host='10.211.55.4')) channel = connection.channel() # make message persistent channel.queue_declare(queue='hello', durable=True) def callback(ch, method, properties, body): print(" [x] Received %r" % body) import time time.sleep(10) print 'ok' ch.basic_ack(delivery_tag = method.delivery_tag) channel.basic_consume(callback, queue='hello', no_ack=False) print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming()
(3) 消息获取顺序
1.默认消息队列里的数据是按照顺序被消费者拿走,例如:消费者1 去队列中获取 奇数 序列的任务,消费者2去队列中获取 偶数 序列的任务。消费者1没有拿,消费者2就不能拿。
2.channel.basic_qos(prefetch_count=1) 表示谁来谁取,不再按照奇偶数排列。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='10.211.55.4'))
channel = connection.channel()
# make message persistent
channel.queue_declare(queue='hello')
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
import time
time.sleep(10)
print 'ok'
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(callback,
queue='hello',
no_ack=False)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
work queues
将耗时的消息处理通过队列分配给多个consumer来处理,我们称此处的consumer为worker,我们将此处的queue称为Task Queue,其目的是为了避免资源密集型的task的同步处理,也即立即处理task并等待完成。相反,调度task使其稍后被处理。也即把task封装进message并发送到task queue,worker进程在后台运行,从task queue取出task并执行job,若运行了多个worker,则task可在多个worker间分配。

###生产者 import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() # 仅仅对message进行确认不能保证message不丢失,比如RabbitMQ崩溃了queue就会丢失 # 因此还需使用durable=True声明queue是持久化的,这样即便Rabb崩溃了重启后queue仍然存在 channel.queue_declare(queue='task_queue', durable=True) # 从命令行构造将要发送的message message = ' '.join(sys.argv[1:]) or "Hello World!" # 除了要声明queue是持久化的外,还需声明message是持久化的 # basic_publish的properties参数指定message的属性 # 此处pika.BasicProperties中的delivery_mode=2指明message为持久的 # 这样一来RabbitMQ崩溃重启后queue仍然存在其中的message也仍然存在 # 需注意的是将message标记为持久的并不能完全保证message不丢失,因为 # 从RabbitMQ接收到message到将其存储到disk仍需一段时间,若此时RabbitMQ崩溃则message会丢失 # 况且RabbitMQ不会对每条message做fsync动作 # 可通过publisher confirms实现更强壮的持久性保证 channel.basic_publish(exchange='', routing_key='task_queue', body=message, properties=pika.BasicProperties( delivery_mode=2, # make message persistent )) print( " [x] Sent %r" % (message,)) connection.close()
消费者
import random import pika import time # 默认情况RabbirMQ将message以round-robin方式发送给下一个consumer # 每个consumer接收到的平均message量是一样的 # 可以同时运行两个或三个该程序进行测试 connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() # 仅仅对message进行确认不能保证message不丢失,比如RabbitMQ崩溃了 # 还需使用durable=True声明queue是持久化的,这样即便Rabb崩溃了重启后queue仍然存在其中的message不会丢失 # RabbitMQ中不允许使用不同的参数定义同名queue channel.queue_declare(queue='task_queue', durable=True) print( ' [*] Waiting for messages. To exit press CTRL+C') # 回调函数,函数体模拟耗时的任务处理:以message中'.'的数量表示sleep的秒数 def callback(ch, method, properties, body): print(" [x] Received %r" % (body,)) time.sleep(random.random()) print( " [x] Done") # 对message进行确认 ch.basic_ack(delivery_tag=method.delivery_tag) # 若存在多个consumer每个consumer的负载可能不同,有些处理的快有些处理的慢 # RabbitMQ并不管这些,只是简单的以round-robin的方式分配message # 这可能造成某些consumer积压很多任务处理不完而一些consumer长期处于饥饿状态 # 可以使用prefetch_count=1的basic_qos方法可告知RabbitMQ只有在consumer处理并确认了上一个message后才分配新的message给他 # 否则分给另一个空闲的consumer channel.basic_qos(prefetch_count=1) # 这里移除了no_ack=True这个参数,也即需要对message进行确认(默认行为) # 否则consumer在偶然down后其正在处理和分配到该consumer还未处理的message可能发生丢失 # 因为此时RabbitMQ在发送完message后立即从内存删除该message # 假如没有设置no_ack=True则consumer在偶然down掉后其正在处理和分配至该consumer但还未来得及处理的message会重新分配到其他consumer # 没有设置no_ack=True则consumer在收到message后会向RabbitMQ反馈已收到并处理了message告诉RabbitMQ可以删除该message # RabbitMQ中没有超时的概念,只有在consumer down掉后重新分发message channel.basic_consume(callback, queue='task_queue') channel.start_consuming()
exchange模型
exchange的作用
exchange是rabbitmq的核心,作用根据根据绑定关系和路由键。为消息提供路由,将消息转发至相应的队列
exchange模型与简单模式区别是,简单模式创建一个channel.queue_declare队列,而exchange模型创建的是channel.exchange_declare交换机。
3.1 发布订阅(广播路由)
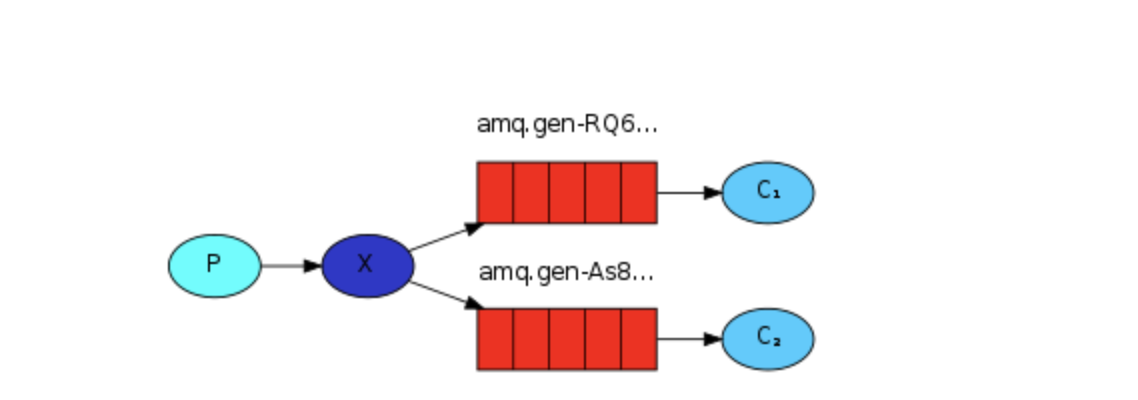
发布订阅和简单的消息队列区别在于,发布订阅会将消息发送给所有的订阅者,而消息队列中的数据只能被一个消息者取走。
routing key不需要指定哪个队列,banding key的名字随便起
所以,RabbitMQ实现发布和订阅时,会为每一个订阅者创建一个队列,而发布者发布消息时,会将消息放置exchange交换机中,然后交换机会把消息放到每个队列中,然后等待消费者的获取。
优点:保证生产者发出的消息传给每一个消费者。
exchange_type = fanout
# 生产者 #!/usr/bin/env python import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() #创建交换机 channel.exchange_declare(exchange='logs', exchange_type='fanout') message = ' '.join(sys.argv[1:]) or "info: Hello World!" #sys.argv[1:]在终端传入数据 channel.basic_publish(exchange='logs', routing_key='',#设置为空,因为不需要指定哪个队列,这里是交换机 body=message) print(" [x] Sent %r" % message) connection.close() # 消费者 #!/usr/bin/env python import pika connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() #创建一个交换机 channel.exchange_declare(exchange='logs', exchange_type='fanout') #每个消费者还需要创建一个队列 result = channel.queue_declare(exclusive=True) #随机生成一个队列 #拿到队列的名字 queue_name = result.method.queue #把创建的队列绑定到交换机上 channel.queue_bind(exchange='logs', queue=queue_name) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] %r" % body) channel.basic_consume(callback, queue=queue_name, no_ack=True) channel.start_consuming()
3.2 直接路由
配置规则:rouning key=Binding key,容易配置和使用
如果message中的routingkey 和bangdingkey一致, direct exchange 则将message发到对应的queue中

exchange_type = direct
之前事例,发送消息时明确指定某个队列并向其中发送消息,RabbitMQ还支持根据关键字发送,即:队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据 关键字 判定应该将数据发送至指定队列。
例子:生产者在发送数据的时候将关键字定义为info, 那么这个数据,只能被绑定关键字为info的消费者读取到。
# 生产者 #!/usr/bin/env python import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() #创建交换机 channel.exchange_declare(exchange='direct_logs', exchange_type='direct') message = " Hello World!" #sys.argv[1:]在终端传入数据 channel.basic_publish(exchange='logs', routing_key='info',#这里就是我们定义的关键字,当定义为info时,exchange只会把消息放到info队列中, body=message) print(" [x] Sent %r" % message) connection.close()
#消费者 #!/usr/bin/env python import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel()
# 创建交换机 channel.exchange_declare(exchange='direct_logs', type='direct')
#自动创建队列,自动生成队列名字,如果不想自动生成的话也可以在这里传入参数
result = channel.queue_declare(exclusive=True) # Only allow access by the current connection queue_name = result.method.queue severities = sys.argv[1:] #如果前端不返回值则走这步 if not severities: sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0]) sys.exit(1) # #如果有值 for severity in severities:
# 队列绑定交换机 channel.queue_bind(exchange='direct_logs', queue=queue_name, routing_key="info")#绑定哪个关键字 print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] %r:%r" % (method.routing_key, body)) channel.basic_consume(callback, queue=queue_name, no_ack=True) channel.start_consuming()
3.3 模糊匹配

exchange_type = topic
功能较为复杂,但是能降级为direct,建议优先使用,为以后使用留有余地
根据routing key及通配规则,将消息分发到指定的队列中
在topic类型下,可以让队列绑定几个模糊的关键字,之后发送者将数据发送到exchange,exchange将传入”路由值“和 ”关键字“进行匹配,匹配成功,则将数据发送到指定队列。
有两种匹配模式:
- # 表示可以匹配 0 个 或 多个 单词
- * 表示只能匹配 一个 单词
- 全匹配相当于direct
发送者的关键字为 消费者关键字为 匹配结果 old.boy.python old.* -- 不匹配 old.boy.python old.# -- 匹配成功
示例:
#!/usr/bin/env python
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='topic_logs',
type='topic')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
binding_keys = sys.argv[1:]
if not binding_keys:
sys.stderr.write("Usage: %s [binding_key]...\n" % sys.argv[0])
sys.exit(1)
for binding_key in binding_keys:
channel.queue_bind(exchange='topic_logs',
queue=queue_name,
routing_key=binding_key)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming
基于RabbitMQ的RPC
详情见博客
RPC(remote procedure call)远程程序调用,它是一种通过网络调用远程计算机上程序的函数或方法,而不需要了解底层网络的技术。是构件分布式程序的一种方式。
RPC是一种协议和模式,用于分布式系统中不同节点之间的通信和调用远程过程,在rpc中客户端可以像调用本地方法一样调用远程方法。无需关心底层的网络通信细节,rpc可以使用不同的传输协议TCP、UDP、HTTP等,也可以使用不同的序列化协议,比如json,xml等。
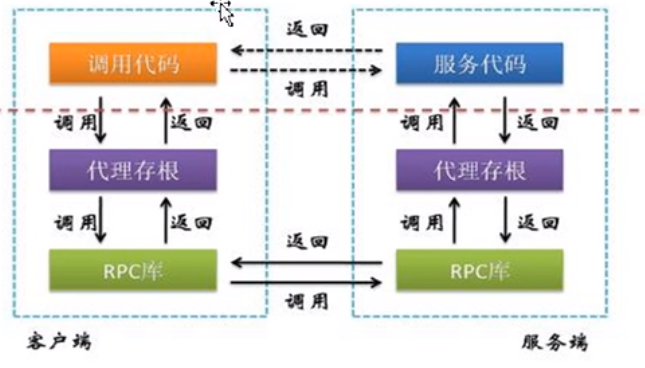
我们平时都是在一台服务器上调用,用不到rpc.
试想果我们需要在远程电脑上运行一个函数方法,并且还要等待一个返回结果,这种模式通常被我们称为远程过程调用或者RPC.
本文使用RabbitMQ实现RPC调用方式。
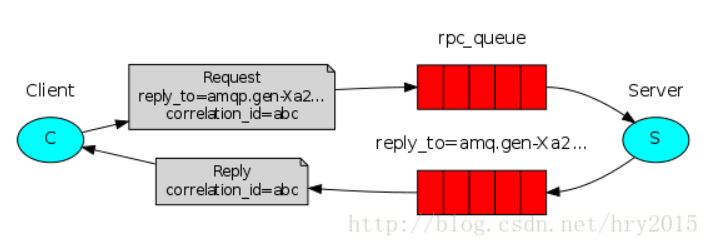
客户端启动后,
1.会生成一个correlation_id这个是为请求设立的唯一标识,用来以后根据这个标识来从回调队列中取数据。
2.把创建一个回调队列,这个回调队列的作用就是用来接收服务端返回的数据。
3.客户端绑定rabbitmq的请求队列routing_key,然后把correlation_id和reply_to即回调队列发送给客户端。
服务端:
1.创建一个请求队列,
2.从队列中拿前端发过来的数据,并把数据当做参数传给回调函数并执行回调函数
3.回调函数调用 处理数据的函数,并把处理完的数据和唯一标识发送到指定的回调队列中。
客户端拿到数据后:
客户端根据唯一标识从指定的回调队列中拿数据
客户端:
import pika import uuid class FibonacciRpcClient(object): def __init__(self): """ 客户端启动时,创建回调队列,会开启会话用于发送RPC请求以及接受响应 """ # 建立连接,指定服务器的ip地址 self.connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) # 建立一个会话,每个channel代表一个会话任务 self.channel = self.connection.channel() # 声明回调队列,再次声明的原因是,服务器和客户端可能先后开启,该声明是幂等的,多次声明,但只生效一次 result = self.channel.queue_declare(exclusive=True) # 将队列指定为当前客户端的回调队列 self.callback_queue = result.method.queue # 客户端订阅回调队列,当回调队列中有响应时,调用`on_response`方法对响应进行处理; self.channel.basic_consume(self.on_response, no_ack=True, queue=self.callback_queue) # 对回调队列中的响应进行处理的函数 def on_response(self, ch, method, props, body): if self.corr_id == props.correlation_id: self.response = body # 发出RPC请求 def call(self, n): # 初始化 response self.response = None # 生成correlation_id唯一标识符号 self.corr_id = str(uuid.uuid4()) # 发送RPC请求内容到RPC请求队列`rpc_queue`,同时发送的还有`reply_to`和`correlation_id` self.channel.basic_publish(exchange='', #这里用的是简单模式,一对一 routing_key='rpc_queue', #绑定请求队列 properties=pika.BasicProperties( reply_to=self.callback_queue, correlation_id=self.corr_id, ), body=str(n)) while self.response is None: #这步的意思是如果服务端没有返回数据将阻塞,知道有数据返回 self.connection.process_data_events() return int(self.response) # 建立客户端 fibonacci_rpc = FibonacciRpcClient() # 发送RPC请求 print(" [x] Requesting fib(30)") response = fibonacci_rpc.call(32) print(" [.] Got %r" % response)
服务端:
import pika connection=pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel=connection.channel() #声明RPC请求队列 channel.queue_declare(queue="rpc_queue") #数据处理方法 def fib(n): if n==0: return 0 elif n ==1: return 1 else: return fib(n-1)+fib(n-2) #对RPC请求队列中的请求进行处理 def on_request(ch,method,props,body): #因为前端传过来的是字符串 n = int(body) print("[.] fib(%s)"%n) #调用数据处理方法 response=fib(n) # 将处理结果(响应)发送到回调队列 ch.basic_publish(exchange='', routing_key=props.reply_to, #绑定回调函数队列 properties=pika.BasicProperties(correlation_id= \ props.correlation_id), #标识符 body=str(response)) #数据 ch.basic_ack(delivery_tag=method.delivery_tag) # 负载均衡,同一时刻发送给该服务器的请求不超过一个 channel.basic_qos(prefetch_count=1)
#将队列和on_request函数绑定 channel.basic_consume(on_request, queue='rpc_queue') print(" server Awaiting RPC requests.....")
#循环从队列中取数据并用on_request函数处理 channel.start_consuming()
注意这两段代码如果运行在同一服务器上时,试验时客户端只能运行一次,不在同一服务器上时,客户端可以运行多次,这是我遇见的最大的坑

 浙公网安备 33010602011771号
浙公网安备 33010602011771号