
pymongo是python连接mongodb数据库的一个模块。
import pymongo client = pymongo.MongoClient(host='127.0.0.1',port=27017)#连接mongodb服务器,默认不写参数就是127.0.0.1:27017,这个是没有密码的
#有密码的应该这么写
db = client.test #指定数据库
collection = db.ip_proxy #指定集合
转载自https://blog.csdn.net/zwq912318834/article/details/77689568
查
查询这里有两个方法第一个:
find_one()
如果找到返回一个文档即字典
collection.find_one() 返回的数据类型是字典,find_one里的参数同find方法中的参数
find()
返回的是一个Cursor类型,相当于迭代器用__iter__,和__next__方法,我们需要遍历取到所有的结果,每一个结果都是字典类型
find(filter=None, projection=None, skip=0, limit=0, no_cursor_timeout=False, cursor_type=CursorType.NON_TAILABLE,
sort=None, allow_partial_results=False, oplog_replay=False, modifiers=None,
batch_size=0, manipulate=True, collation=None, hint=None, max_scan=None,
max_time_ms=None, max=None, min=None, return_key=False,
show_record_id=False, snapshot=False, comment=None, session=None) # filter 过滤条件 是一个字典参数 # projection 返回要显示的字段,该参数可以是一个字典{"name":True},也可以是一个列表["name"] #session 这个不清楚,以后用到再查 #skip 要跳过的文档数 #limit 返回的最大结果数,默认为0,即没有限制 # no_cursor_time 如果为False(默认值),则服务器将在10分钟不活动后关闭任何返回的光标。如果设置为True,返回的光标将永远不会在服务器上超时。应注意确保没有打开光标超时的光标正确关闭。 # cursor_type 光标类型,暂时没有用 # sort 排序 ,值为一个列表, [("age",pymongo.ASCENDING)] #batch_size 限制单批次返回的文档数 # max_time_ms 指定查询的最大时间限制
collection.count():返回集合中有多少条数据
collection.find():返回一个对象,想要得到里边的数据需要for循环
collection.find({'type':"HTTPS"}):指定文档的字段查询
collection.find({},projection={'_id':True,"ip":True}) 指定要显示的字段,把要显示的字段设为True,就可以,
{'_id': ObjectId('5cc13530a11f4a2cc00fae2c'), 'ip': '119.102.24.217'}
{'_id': ObjectId('5cc13530a11f4a2cc00fae2d'), 'ip': '119.102.25.220'}
{'_id': ObjectId('5cc13530a11f4a2cc00fae2e'), 'ip': '112.85.170.221'}
{'_id': ObjectId('5cc13530a11f4a2cc00fae2f'), 'ip': '115.53.23.56'}
collection.find({},projection=['port',"ip"]) #用字典指定要显示的字段,包含_id字段
{'_id': ObjectId('5cc13530a11f4a2cc00fae2c'), 'ip': '119.102.24.217', 'port': '9999'}
{'_id': ObjectId('5cc13530a11f4a2cc00fae2d'), 'ip': '119.102.25.220', 'port': '9999'}
{'_id': ObjectId('5cc13530a11f4a2cc00fae2e'), 'ip': '112.85.170.221', 'port': '18118'}
pprint()
比print更直观
import pprint pprint.pprint(posts.find_one()) # 格式化输出 #结果 {'_id': ObjectId('5dba823d23641bfd50dab939'), 'author': 'Mike', 'data': datetime.datetime(2019, 10, 31, 6, 42, 5, 878000), 'tag': ['mongodb', 'python', 'pymongo'], 'text': 'My first blog post'}
指定查询条件
比较:=,!=,>, <, >=, <=
$ne:不等于(not equal) $gt:大于(greater than) $lt:小于(less than) $lte:小于等于(less than equal) $gte:大于等于(greater than equal)
# 示例二:不相等 # select _id,key,sales,date from galance20170801 where sales != 0 queryArgs = {'sales':{'$ne':0}} projectionFields = ['key','sales','date'] searchRes = db_coll.find(queryArgs, projection = projectionFields) # 结果:{'_id': 'B01M996469', 'date': '2017-08-01', 'key': 'stereos', 'sales': 2}
# 示例三:大于 # where sales > 100 queryArgs = {'sales':{'$gt':100}} # 结果:{'_id': 'B010OYASRG', 'date': '2017-08-01', 'key': 'Sound Bar', 'sales': 124}
# 示例四:小于 # where sales < 100 queryArgs = {'sales':{'$lt':100}} # 结果:{'_id': 'B011798DKQ', 'date': '2017-08-01', 'key': 'pro audio', 'sales': 0}
# 示例五:指定范围 # where sales > 50 and sales < 100 queryArgs = {'sales':{'$gt':50, '$lt':100}} # 结果:{'_id': 'B008D2IHES', 'date': '2017-08-01', 'key': 'Sound Bar', 'sales': 66}
and
# 示例一:不同字段,并列条件 # where date = '2017-08-01' and sales = 100 queryArgs = {'date':'2017-08-01', 'sales':100} # 结果:{'_id': 'B01BW2YYYC', 'date': '2017-08-01', 'key': 'Video', 'sales': 100}
# 示例二:相同字段,并列条件 # where sales >= 50 and sales <= 100 # 正确:queryArgs = {'sales':{'$gte':50, '$lte':100}} # 错误:queryArgs = {'sales':{'$gt':50}, 'sales':{'$lt':100}} # 结果:{'_id': 'B01M6DHW26', 'date': '2017-08-01', 'key': 'radios', 'sales': 50}
or
# 示例一:不同字段,或条件 # where date = '2017-08-01' or sales = 100 queryArgs = {'$or':[{'date':'2017-08-01'}, {'sales':100}]} # 结果:{'_id': 'B01EYCLJ04', 'date': '2017-08-01', 'key': 'pro audio', 'sales': 0}
# 示例二:相同字段,或条件 # where sales = 100 or sales = 120 queryArgs = {'$or':[{'sales':100}, {'sales':120}]} # 结果: # {'_id': 'B00X5RV14Y', 'date': '2017-08-01', 'key': 'Chargers', 'sales': 120} # {'_id': 'B0728GGX6Y', 'date': '2017-08-01', 'key': 'Glasses', 'sales': 100}
in,not in,all
# 示例一:in # where sales in (100,120) # 这个地方一定要注意,不能用List,只能用元组,因为是不可变的 # 如果用了 {'$in': [100,120]},就会出现异常:TypeError: unhashable type: 'list' queryArgs = {'sales':{'$in': (100,120)}} # 结果: # {'_id': 'B00X5RV14Y', 'date': '2017-08-01', 'key': 'Chargers', 'sales': 120} # {'_id': 'B0728GGX6Y', 'date': '2017-08-01', 'key': 'Glasses', 'sales': 100}
# 示例二:not in # where sales not in (100,120) queryArgs = {'sales':{'$nin':(100,120)}} # 结果:{'_id': 'B01EYCLJ04', 'date': '2017-08-01', 'key': 'pro audio', 'sales': 0}
# 示例三:匹配条件内所有值 all # where sales = 100 and sales = 120 queryArgs = {'sales':{'$all':[100,120]}} # 必须同时满足 # 结果:无结果
# 示例四:匹配条件内所有值 all # where sales = 100 and sales = 100 queryArgs = {'sales':{'$all':[100,100]}} # 必须同时满足 # 结果:{'_id': 'B01BW2YYYC', 'date': '2017-08-01', 'key': 'Video', 'sales': 100}
字段是否存在
# 示例一:字段不存在 # where rank2 is null queryArgs = {'rank2':None} projectionFields = ['key','sales','date', 'rank2'] searchRes = db_coll.find(queryArgs, projection = projectionFields) # 结果:{'_id': 'B00ACOKQTY', 'date': '2017-08-01', 'key': '3D TVs', 'sales': 0} # mongodb中的命令 db.categoryAsinSrc.find({'isClawered': true, 'avgCost': {$exists: false}})
# 示例二:字段存在 # where rank2 is not null queryArgs = {'rank2':{'$ne':None}} projectionFields = ['key','sales','date','rank2'] searchRes = db_coll.find(queryArgs, projection = projectionFields).limit(100) # 结果:{'_id': 'B014I8SX4Y', 'date': '2017-08-01', 'key': '3D TVs', 'rank2': 4.0, 'sales': 0}
正则表达式匹配:$regex(SQL:like)
# 示例一:关键字key包含audio子串 # where key like "%audio%" queryArgs = {'key':{'$regex':'.*audio.*'}} # 结果:{'_id': 'B01M19FGTZ', 'date': '2017-08-01', 'key': 'pro audio', 'sales': 1}
数组中必须包含元素:$all
# 查询记录,linkNameLst是一个数组,指定linkNameLst字段必须包含 'Electronics, Computers & Office' 这个元素。 db.getCollection("2018-01-24").find({'linkNameLst': {'$all': ['Electronics, Computers & Office']}}) # 查询记录,linkNameLst是一个数组,指定linkNameLst字段必须同时包含 'Wearable Technology' 和 'Electronics, Computers & Office' 这两个元素。 db.getCollection("2018-01-24").find({'linkNameLst': {'$all': ['Wearable Technology', 'Electronics, Computers & Office']}})
(5.1.2.8). 按数组大小查询
两个思路: 第一个思路:使用$where(具有很大的灵活性,但是速度会慢一些) # priceLst是一个数组, 目标是查询 len(priceLst) < 3 db.getCollection("20180306").find({$where: "this.priceLst.length < 3"}) 关于$where,请参考官方文档:http://docs.mongodb.org/manual/reference/operator/query/where/。 第二个思路:判断数组中的某个指定索引的元素是否存在(会比较高效) 例如:如果要求 len(priceLst) < 3:就意味着 num[ 2 ]不存在 # priceLst是一个数组, 目标是查询 len(priceLst) < 3 db.getCollection("20180306").find({'priceLst.2': {$exists: 0}}) 例如:如果要求 len(priceLst) > 3:就意味着 num[ 3 ]存在 # priceLst是一个数组, 目标是查询 len(priceLst) > 3 db.getCollection("20180306").find({'priceLst.3': {$exists: 1}})
限定数量:limit
# 示例一:按sales降序排列,取前100 # select top 100 _id,key,sales form galance20170801 where key = 'speakers' order by sales desc queryArgs = {'key':'speakers'} projectionFields = ['key','sales'] searchRes = db_coll.find(queryArgs, projection = projectionFields) topSearchRes = searchRes.sort('sales',pymongo.DESCENDING).limit(100)
排序:sort
# 示例二:按sales降序,rank升序 # select _id,key,date,rank from galance20170801 where key = 'speakers' order by sales desc,rank queryArgs = {'key':'speakers'} projectionFields = ['key','sales','rank'] searchRes = db_coll.find(queryArgs, projection = projectionFields) # sortedSearchRes = searchRes.sort('sales',pymongo.DESCENDING) # 单个字段 sortedSearchRes = searchRes.sort([('sales', pymongo.DESCENDING),('rank', pymongo.ASCENDING)]) # 多个字段 # 结果: # {'_id': 'B000289DC6', 'key': 'speakers', 'rank': 3.0, 'sales': 120} # {'_id': 'B001VRJ5D4', 'key': 'speakers', 'rank': 5.0, 'sales': 120}
随机从查询的条件中取出一个文档
ret = collection.find({'port':'9999'},projection={'port':True,"ip":True})
r = random.choice(list(ret))
print(r)
结果:
{'_id': ObjectId('5cc13530a11f4a2cc00fae6b'), 'ip': '112.85.130.123', 'port': '9999'}
分页
results = collection.find().sort('name', pymongo.ASCENDING).skip(2).limit(2)
添加
单条插入
# 示例一:指定 _id,如果重复,会产生异常 ID = 'firstRecord' insertDate = '2017-08-28' count = 10 insert_record = {'_id':ID, 'endDate': insertDate, 'count': count} insert_res = db_coll.insert_one(insert_record) print(f"insert_id={insert_res.inserted_id}: {insert_record}") # 结果:insert_id=firstRecord: {'_id': 'firstRecord', 'endDate': '2017-08-28', 'count': 10}
# 示例二:不指定 _id,自动生成 insertDate = '2017-10-10' count = 20 insert_record = {'endDate': insertDate, 'count': count} insert_res = db_coll.insert_one(insert_record) print(f"insert_id={insert_res.inserted_id}: {insert_record}") # 结果:insert_id=59ad356d51ad3e2314c0d3b2: {'endDate': '2017-10-10', 'count': 20, '_id': ObjectId('59ad356d51ad3e2314c0d3b2')}
批量插入
# 更高效,但要注意如果指定_id,一定不能重复 # ordered = True,遇到错误 break, 并且抛出异常 # ordered = False,遇到错误 continue, 循环结束后抛出异常 insertRecords = [{'i':i, 'date':'2017-10-10'} for i in range(10)] insertBulk = db_coll.insert_many(insertRecords, ordered = True) print(f"insert_ids={insertBulk.inserted_ids}") # 结果:insert_ids=[ObjectId('59ad3ba851ad3e1104a4de6d'), ObjectId('59ad3ba851ad3e1104a4de6e'), ObjectId('59ad3ba851ad3e1104a4de6f'),
ObjectId('59ad3ba851ad3e1104a4de70'), ObjectId('59ad3ba851ad3e1104a4de71'), ObjectId('59ad3ba851ad3e1104a4de72'), ObjectId('59ad3ba851ad3e1104a4de73'),
ObjectId('59ad3ba851ad3e1104a4de74'), ObjectId('59ad3ba851ad3e1104a4de75'), ObjectId('59ad3ba851ad3e1104a4de76')]
更新
# 根据筛选条件_id,更新这条记录。如果找不到符合条件的记录,就插入这条记录(upsert = True) updateFilter = {'_id': item['_id']} updateRes = db_coll.update_one(filter = updateFilter, update = {'$set': dict(item)}, upsert = True) print(f"updateRes = matched:{updateRes.matched_count}, modified = {updateRes.modified_count}")
# 根据筛选条件,更新部分字段:i是原有字段,isUpdated是新增字段 filterArgs = {'date':'2017-10-10'} updateArgs = {'$set':{'isUpdated':True, 'i':100}} updateRes = db_coll.update_many(filter = filterArgs, update = updateArgs) print(f"updateRes: matched_count={updateRes.matched_count}, " f"modified_count={updateRes.modified_count} modified_ids={updateRes.upserted_id}") # 结果:updateRes: matched_count=8, modified_count=8 modified_ids=None
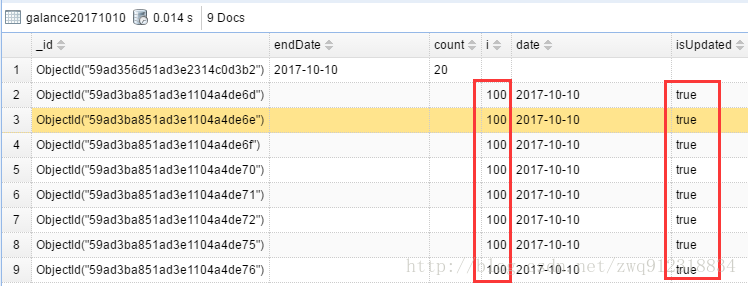
find_one_and_update()
找到一个文档并更新它,返回更新前的文档或更新后的文档
find_one_and_update(filter, update, projection=None, sort=None, return_document=ReturnDocument.BEFORE, array_filters=None, session=None, **kwargs)
return_document就是控制返回更新前的文档还是更新后的文档,默认返回更新前的文档,如果要返回更新后的文档这样改,ReturnDocument.AFTER
upsert 默认是False,找不到该文档不私自创建
array_filtersz 这个参数还没有研究出
删除
删除一条数据
# 示例一:和查询使用的条件一样 queryArgs = {'endDate':'2017-08-28'} delRecord = db_coll.delete_one(queryArgs) print(f"delRecord={delRecord.deleted_count}") # 结果:delRecord=1
批量删除多个
# 示例二:和查询使用的条件一样 queryArgs = {'i':{'$gt':5, '$lt':8}} # db_coll.delete_many({}) # 清空数据库 delRecord = db_coll.delete_many(queryArgs) print(f"delRecord={delRecord.deleted_count}") # 结果:delRecord=2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号