Big Data(五)关于Hadoop的HA的实践搭建
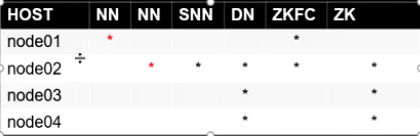
JoinNode 分布在node01,node02,node03
1.停止之前的集群
2.免密:node01,node02
node02: cd ~/.ssh ssh-keygen -t dsa -P '' -f ./id_dsa cat id_dsa.pub >> authorized_keys scp ./id_dsa.pub node01:`pwd`/node02.pub node01: cd ~/.ssh cat node02.pub >> authorized_keys
3.zookeeper 集群搭建 java语言开发(需要jdk)
node02: tar xf zook....tar.gz mv zoo... /opt/bigdata cd /opt/bigdata/zoo.... cd conf cp zoo_sample.cfg zoo.cfg vi zoo.cfg dataDir=/var/bigdata/hadoop/zk server.1=node02:2888:3888 server.2=node03:2888:3888 server.3=node04:2888:3888 mkdir /var/bigdata/hadoop/zk echo 1 > /var/bigdata/hadoop/zk/myid vi /etc/profile export ZOOKEEPER_HOME=/opt/bigdata/zookeeper-3.4.6 export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin . /etc/profile cd /opt/bigdata scp -r ./zookeeper-3.4.6 node03:`pwd` scp -r ./zookeeper-3.4.6 node04:`pwd` node03: mkdir /var/bigdata/hadoop/zk echo 2 > /var/bigdata/hadoop/zk/myid *环境变量 . /etc/profile node04: mkdir /var/bigdata/hadoop/zk echo 3 > /var/bigdata/hadoop/zk/myid *环境变量 . /etc/profile node02~node04: zkServer.sh start
4.配置hadoop的core和hdfs
core-site.xml <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>node02:2181,node03:2181,node04:2181</value> </property> hdfs-site.xml #下面是重命名 <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/var/bigdata/hadoop/ha/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/var/bigdata/hadoop/ha/dfs/data</value> </property> #以下是 一对多,逻辑到物理节点的映射 <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>node01:8020</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>node02:8020</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>node01:50070</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>node02:50070</value> </property> #以下是JN在哪里启动,数据存那个磁盘 <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://node01:8485;node02:8485;node03:8485/mycluster</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/var/bigdata/hadoop/ha/dfs/jn</value> </property> #HA角色切换的代理类和实现方法,我们用的ssh免密 <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_dsa</value> </property> #开启自动化: 启动zkfc <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property>
5.分发两个配置文件
6.开启1,2,3台的journalnode
hadoop-daemon.sh start journalnode
7.选择一个NN 做格式化
hdfs namenode -format
8.启动该NN的namenode
hadoop-daemon.sh start namenode
9.在另一台NN进行同步
hdfs namenode -bootstrapStandby
10.在node01下格式化zk
hdfs zkfc -formatZK
11.启动
start-dfs.sh
12.验证
kill -9 xxx a)杀死active NN b)杀死active NN身边的zkfc c)shutdown activeNN 主机的网卡 : ifconfig eth0 down 2节点一直阻塞降级 如果恢复1上的网卡 ifconfig eth0 up 最终 2 变成active

 浙公网安备 33010602011771号
浙公网安备 33010602011771号