Big Data(四)关于Hadoop的HA&CAP理论详解
问题
思路:
主从集群:结构相对简单,主与从协作
主:单点,数据一致好掌握
问题:
单点故障,集群整体不可用
压力过大,内存受限
解决方案
单点故障:
高可用方案:HA(High Available)
多个NN,主备切换,主压力过大,内存受限:
联邦机制:Federation(元数据分片)
多个NN,管理不同的元数据
Hadoop2.X只支持HA的一主一备
Hadoop3.x支持一主多备(官方推荐NN为3)
HDFS-HA解决方案
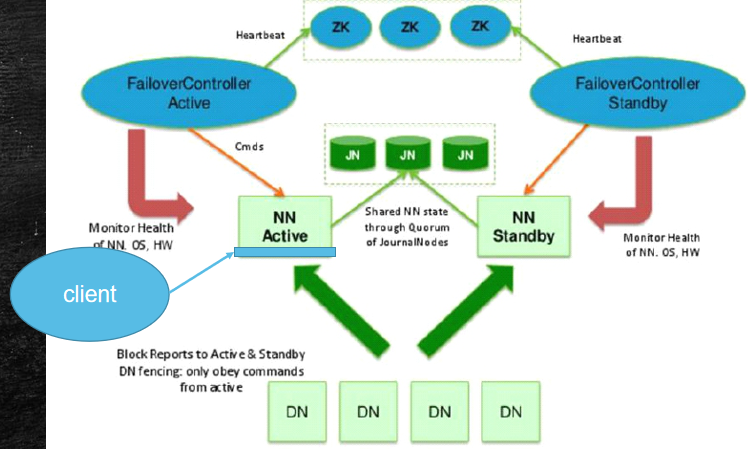
HA解决方案图
Client只能与一个NameNode去通信,在我们的NameNode中。
存储的元数据:
1.dn提交的block
2.Cli交互操作,例如mkdir等
有关这两个数据交互操作,数据同步吗?
1.DN可以将块向两个NameNode进行传递区块,问题解决
2.NNActive和NNStandby得满足CA,中间时间差不能太多
所以使用3台JoinNode集群。如果3台,那么应该得等3台写完,再返回,还是一台写完就返回呢??
这陷入一个怪圈。
所以我们使用选举制度,加上权重,JoinNode只要3台中有2台返回ok,那么NN可以读取3台中2台有数据,那么该数据可信。(基于Paxos算法)
上部分的ZK集群主要用于主备切换,如果有了下部分,也可以手动解决NN挂掉的案例
FailoverController是一个故障转移控制器(3只手):
1.一只手:一个进程来监控NNActive,另外一个进程监控NNStandby
2.第二只手:连接ZK(ZK用于分布式决策,JN是用于分布式存储)
3.目录树结构,假设x节点,两个ZKFC进行抢锁,某个人抢锁成功就是Active,另一个是Standby
4.随着时间推移,假设NNActive挂掉,那么ZKFC将会把锁删除,另一个ZKFC在一直进行Watch监控,会立即触发Call Back,进行新一轮抢锁
5.新一轮抢锁原先的NN已经没有了,所以不进行抢锁,把NNActive让给备用
6.右侧抢锁成功,将会将第三只手偷偷伸向对方,查看原先的NN是否真的挂掉,如果真的挂掉,将对方降为Standby,自己升级为Active
7.所有都挂掉,这个是运维的错误,情况太低了
8.所有网络都是不可靠的,所以上面的集群架构都是基于串口
CAP理论(参考博客http://www.ruanyifeng.com/blog/2018/07/cap.html)
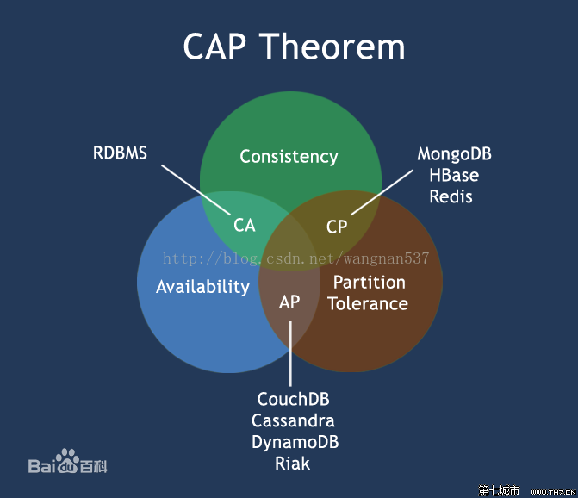
1998年,加州大学的计算机科学家 Eric Brewer 提出,分布式系统有三个指标。
Consistency:一致性
Availability:可用性
Partition tolerance:分区容忍性
Eric Brewer 说,这三个指标不可能同时做到。这个结论就叫做 CAP 定理。
Partition Tolerance
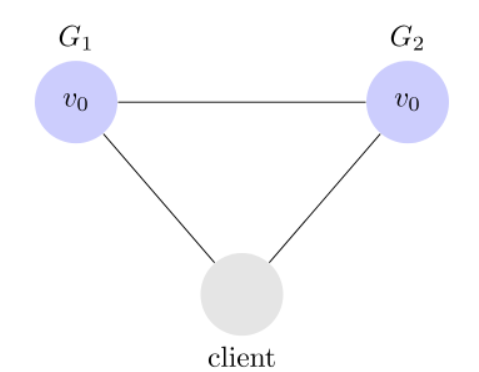
先看 Partition tolerance,中文叫做"分区容错"。
大多数分布式系统都分布在多个子网络。每个子网络就叫做一个区(partition)。分区容错的意思是,区间通信可能失败。比如,一台服务器放在中国,另一台服务器放在美国,这就是两个区,它们之间可能无法通信。
上图中,G1 和 G2 是两台跨区的服务器。G1 向 G2 发送一条消息,G2 可能无法收到。系统设计的时候,必须考虑到这种情况。
一般来说,分区容错无法避免,因此可以认为 CAP 的 P 总是成立。CAP 定理告诉我们,剩下的 C 和 A 无法同时做到。
Consistency
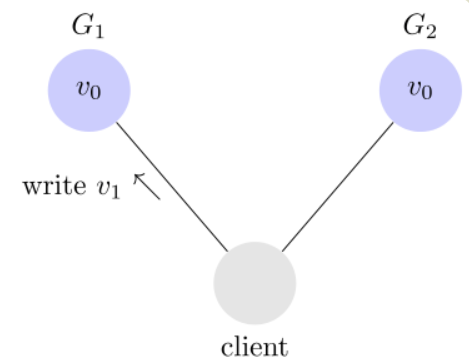
Consistency 中文叫做"一致性"。意思是,写操作之后的读操作,必须返回该值。举例来说,某条记录是 v0,用户向 G1 发起一个写操作,将其改为 v1。
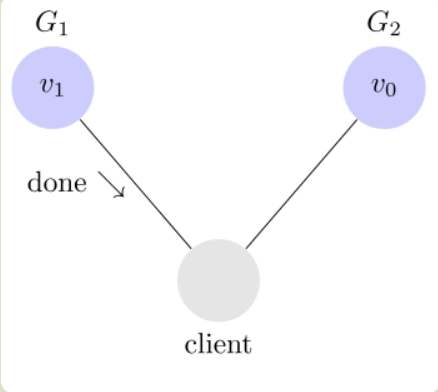
接下来,用户的读操作就会得到 v1。这就叫一致性。
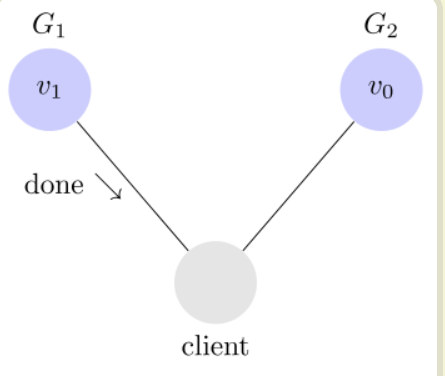
问题是,用户有可能向 G2 发起读操作,由于 G2 的值没有发生变化,因此返回的是 v0。G1 和 G2 读操作的结果不一致,这就不满足一致性了。
Availability
Availability 中文叫做"可用性",意思是只要收到用户的请求,服务器就必须给出回应。
用户可以选择向 G1 或 G2 发起读操作。不管是哪台服务器,只要收到请求,就必须告诉用户,到底是 v0 还是 v1,否则就不满足可用性。、
参考(https://baijiahao.baidu.com/s?id=1619807486368681081&wfr=spider&for=pc)
- 舍C保A(AP)的例子:
比如刚刚的微博这个例子,我们更新了一条微博,不是所有的人都能马上刷出来的,对于哪些还只能刷出旧的微博数据的人来说数据就和我真实的操作不一致了。然而这种业务也不需要要求我们强一致性,没有刷出我的最新微博,也不是什么大事,大不了认为我没有更新而已,对业务影响很小。但是呢也不能一直都不一致是吧,所以C还是不能丢的,可以迟到。
- 舍A保C(CP)的例子:
比如银行账户的例子,大家生活中也许也已经注意到了,银行转账需要几个小时甚至几天,都会显示正在转账中。这时就是视作一种丢失可用性的状态。当然这是业务决定的。
- 舍P保C又保A的场景:
不是分布式的场景的话,我们可以选择CA,比如我是个小银行,我的转账功能可以设计为多地账户不互通,只能本地转账,只在一台服务器上操作,保证可用性和一致性。但整体来看可用性和一致性都丢失了。(这是关系型数据库情况)
ACID特性(参考https://www.jianshu.com/p/0b245d972e23)
Atomic(原子性):指整个数据库事务是不可分割的工作单位。只有使据库中所有的操作执行成功,才算整个事务成功;事务中任何一个SQL语句执行失败,那么已经执行成功的SQL语句也必须撤销,数据库状态应该退回到执行事务前的状态。
Consistency(一致性):指数据库事务不能破坏关系数据的完整性以及业务逻辑上的一致性。例如对银行转帐事务,不管事务成功还是失败,应该保证事务结束后ACCOUNTS表中Tom和Jack的存款总额为2000元。
Isolation(隔离性):指的是在并发环境中,当不同的事务同时操纵相同的数据时,每个事务都有各自的完整数据空间。
Durability(持久性):指的是只要事务成功结束,它对数据库所做的更新就必须永久保存下来。即使发生系统崩溃,重新启动数据库系统后,数据库还能恢复到事务成功结束时的状态。
HDFS- Federation解决方案
NN的压力过大,内存受限问题:
1.元数据分治,复用DN存储
2.元数据访问隔离性
3.DN目录隔离block
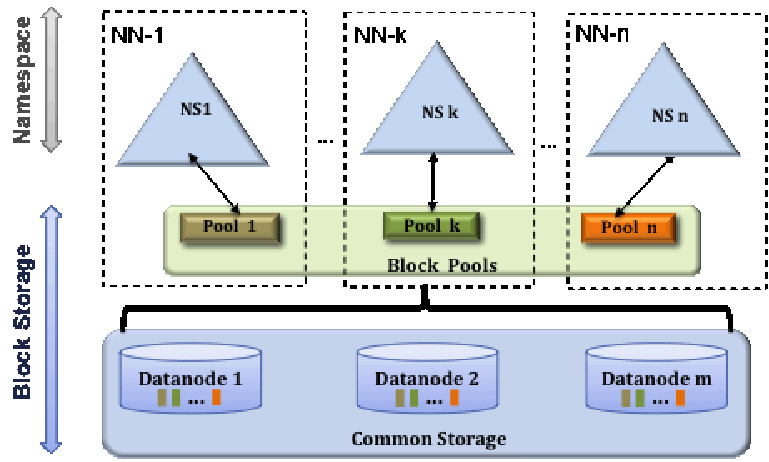
Federation的图示

 浙公网安备 33010602011771号
浙公网安备 33010602011771号