16 Top Big Data Analytics Platforms(Doug Henschen, InformationWeek, 2014-01-30)
16 Top Big Data Analytics Platforms(Doug Henschen, InformationWeek, 2014-01-30)
4. Amazon

Amazon does it all in cloud
Analytical DBMS: Amazon Redshift service (based on ParAccel engine); Amazon Relational Database Service.
In-memory DBMS: None. Third-party options on AWS include Altibase, SAP Hana, and ScaleOut.
Hadoop distributions: Amazon Elastic MapReduce. Third-party options include Cloudera and MapR.
Stream-processing technology: Amazon Kinesis.
Hardware/software systems: Not applicable.
Amazon Web Services hosts a who's who list of data-management services from third-party players -- Cloudera, Microsoft, Oracle, SAP, and many others -- but the cloud giant has its own long-term ambitions where big-data analysis is concerned(关于大数据分析 Amazon 有自己的远大目标,不仅仅是提高众多第三方产品选择,比如 Cloudera 的 Hadoop、微软的 SQL Server、Oracle或者SAP的Sybase). Building on its Elastic Compute Cloud (EC2) and Simple Storage Service (S3) storage infrastructure, Amazon launched its Hadoop-based Elastic MapReduce service way back in 2009. In 2013, AWS added the Redshift Data Warehousing service (based on the ParAccel DBMS), which is supported by another who's who list of independent data-integration, business intelligence, and analytics vendors. Rounding out AWS's big-data capabilities are the DynamoDB NoSQL database management service and Kinesis Stream Processing service.
Amazon's biggest appeal is clearly to organizations running data-intensive applications on its cloud. That said, leading Hadoop distributor Cloudera recently partnered with AWS, apparently reasoning that many enterprises are choosing hybrid strategies in which they're moving selected big-data workloads into the cloud while keeping sensitive data and mission-critical workloads on-premises. Look for AWS to exploit this opportunity by adding even more options to connect with enterprise data centers.
5. Cloudera

Cloudera eyes 'data hub' role
Analytical DBMS: HBase, and although not a DBMS, Cloudera Impala supports SQL querying on top of Hadoop.
In-memory DBMS: Although not a DBMS, Apache Spark supports in-memory analysis on top of Hadoop.
Hadoop distributions: CDH open-source distribution, Cloudera Standard, Cloudera Enterprise.
Stream-processing technology: Open-source stream-processing options on Hadoop include Storm.
Hardware/software systems: Partner appliances, preconfigured hardware, or both available from Cisco, Dell, HP, IBM, NetApp, and Oracle.
The market-leading distributor of Hadoop software, Cloudera is pushing hard to extend the data-processing framework into a comprehensive "enterprise data hub" that can serve as a first destination and central point of management for all data within enterprises.
Cloudera vows support for open-source Hadoop, but to ensure enterprise-grade performance, reliability, data-access control, and security, Cloudera offers proprietary software including Cloudera Manager, Cloudera Navigator, and certain vendor-exclusive components for backup and recovery. What's more, open-source components including Cloudera Impala and Cloudera Search are best managed at scale with the aid of Cloudera Manager to provision, manage, and monitor workloads, and Cloudera Navigator to provide access control and auditing.
Cloudera says its platform is steadily maturing to become the "center of gravity" for data management, and it believes relational databases eventually will be reserved for niche applications involving small sets of consistent, structured data. Whether or not that jibes with your priorities, expect Cloudera to stay focused on providing a maturing and broadly capable Hadoop platform.
6. HP

HP HAVEn architecture taps Vertica
Analytical DBMS: HP Vertica Analytics Platform Version 7 (Crane release).
In-memory DBMS: Vertica is not an in-memory database, but with high RAM-to-disk ratios the company says it can ensure near-real-time query performance.
Hadoop distribution: None.
Stream-processing technology: None.
Hardware/software systems: HP ConvergedSystem 300 for Vertica, plus a choice of reference architectures for Cloudera, Hortonworks, and MapR Hadoop distributions.
HP calls its big-data-platform architecture HAVEn, an acronym for Hadoop, Autonomy, Vertica, Enterprise Security, and "n" applications. HP doesn't have its own Hadoop distribution, but it provides reference hardware configurations for leading Hadoop software distributors. Autonomy's IDOL software addresses search and exploration of unstructured. Vertica is HP's massively parallel processing columnar analytical DBMS designed for speedy analysis of massive, structured data sets. Competing with the likes of IBM PureData for Analytics (Netezza) and Pivotal Greenplum, Vertica is intended to complement rather than replace legacy enterprise data warehouse environments such as Teradata. ——Teradata已经叫传统的企业数据仓库环境
With the Vertica 7 release, HP added a "FlexZone" designed to let users explore data in large data sets before defining the database scheme and related analyses and reports. Release 7 is also integrated with Hadoop through Hive's HCatalog metadata store, giving users a way to explore data on HDFS in a tabular view.
HP's ArcSight Logger software for collecting and analyzing machine data and its Operational Analytics offerings give it more of an IT-centric spin on big-data analysis than most of its rivals. IBM, SAP, and Oracle, for example, are much deeper on data-integration, BI, and analytics software for business applications. If HP is your IT systems management and hardware vendor of choice, the HAVEn platform and its components complement Hadoop and investments in third-party data-management and analytics software.
7. HortonWorks

Hortonworks Pursues Open Source Path
Analytical DBMS: HBase; although not a DBMS, Hive is Hortonworks' option for SQL querying on top of Hadoop.
In-memory DBMS: Although not a DBMS, Apache Spark supports in-memory analysis on top of Hadoop.
Hadoop distributions: Hortonworks Data Platform (HDP) 2.0, HDP for Windows, Hortonworks Sandbox (free, single-node desktop software offering Hadoop tutorials).
Stream-processing technology: Open-source stream-processing options on Hadoop include Storm.
Hardware/software systems: Partner appliances, preconfigured hardware, or both available from HP, Teradata and others.
Hortonworks is a massive contributor to the open-source Hadoop community focused on building it into a broadly capable data-management platform. Hortonworks sets itself apart from competitors Cloudera and MapR by eschewing proprietary components. Everything in the Hortonworks Data Platform (HDP) is freely available as open-source software.
To its critics -- the aforementioned competitors -- Hortonworks pushes this open-source point to a fault, waiting to ship sought-after functionality until it is community sanctified and avoiding new (and perhaps technically better approaches) that are not entirely open source. Hortonworks is sticking with -- and trying to improve -- Hive, for example, while Cloudera promises better SQL-on-Hadoop performance with Impala, which is open source, technically, but best managed with proprietary Cloudera Manager software.
In short, HDP is the conservative Hadoop distribution, and Hortonworks reportedly undercuts its competitors on support costs. Hortonworks makes the point that there's no threat of vendor lock-in with its distribution, and everything shipping has been thoroughly tested and proven. You won't get any surprises, but nor will you get anything ahead of the rest of the community in performance, ease of management, or functionality.
8. IBM

IBM takes a comprehensive approach
Analytical DBMS: DB2, Netezza.
In-memory DBMS: DB2 with BLU Acceleration, solidDB.
Hadoop distribution: InfoSphere BigInsights.
Stream-processing technology: InfoSphere Streams.
Hardware/software systems: PureData System For Operational Analytics (DB2), IBM PureData System for Analytics (Netezza); PureData System for Hadoop (BigInsights).
IBM has the broadest data-management portfolio in the industry, hands down. In addition to offering all the platforms mentioned above, as well as mainframes, IBM has a bevy of data-integration, data-cleansing, and data-quality software options to help capture and clean data. It also has plenty of business intelligence and analytics offerings, including Cognos, SPSS, text- and unstructured-data mining options, and IBM-developed tools for Hadoop including Big Sheets and BigSQL. IBM is also building out its SaaS portfolio and cloud infrastructure, with the $2 billion SoftLayer acquisition being a tangible example of the cloud commitment.
Although IBM has plenty of products and services, it's not a product-oriented provider of technology. IBM leads with its deep integration and consulting expertise in a consultative approach focused on building business-differentiating "solutions" that might incorporate multiple products. The upside is that it's not a cookie-cutter, one-size-fits-all approach, but competitors say beware of open-ended commitments and steep, ongoing consulting fees. Those choosing IBM expect an effective strategic approach that leads to significant business results. It's up to you to make sure you get what you pay for. ——IBM 不是面向产品的技术供应商,它的优势是行业方案以及说书的能力,到哪儿都是从战略说起,现在的技术的领先金融科技公司和互联网公司都不是空谈战略的官僚企业,去 IOE 的理念在这些公司深入人心。IBM 方法论的那一套受到挑战
9. InfiniDB

InfiniDB counts on Apache Hadoop
Analytical DBMS: InfiniDB (formerly Calpont).
In-memory DBMS: None.
Hadoop distribution: None.
Stream-processing technology: None.
Hardware/software systems: None (software-only vendor).
InfiniDB is the new name for the database management system formerly known by the company name, Calpont. This 14-year-old firm is on its fourth-generation massively parallel processing, columnar DBMS. The new product name is part of a push to step up sales and marketing efforts and get beyond the current base of about 50 customers.
The InfiniDB makeover isn't just a name change. The company has reengineered the DBMS to run on top of the Hadoop Distributed File System for SQL-on-Hadoop analysis -- much as Pivotal did with Greenplum to create HAWQ. Conventional deployment options include Linux, Windows, or cloud on Amazon Web Services. The company also open sourced InfiniDB under the GNU General Public License, a choice it made because it's a MySQL storage engine. The commercially supported Enterprise edition adds utilities for administration and automation as well as a management console.
The InfiniDB technology is most comparable to that of HP Vertica and Actian Matrix (formerly Actian ParAccel), but company executives claim that automated partitioning features make it easier to manage than these rivals. The company also claims SQL-on-Hadoop query performance advantages over Cloudera Impala, Hive, and other approaches. These assertions won't win many friends and alliances among Hadoop distributors, but the company is counting on aggressive pricing to win over Hadoop users and would-be DBMS customers.
10. Infobright

Infobright focuses on machine data
Analytical DBMS: Infobright.
In-memory DBMS: None.
Hadoop distribution: None.
Stream-processing technology: None.
Hardware/software systems: Infobright Infopliance.
Infobright is a focused analytical database provider with a column-store DBMS aimed at fast analysis of up to 50 terabytes per server; the database is designed for symmetric multiprocessor servers, not massively parallel processing. Fifty TB might sound small for big data, but Infobright's high compression ratio and data-skipping technology is particularly well suited to machine data such as clickstreams, mobile data, log files, and sensor data.
Infobright is often used in concert with Hadoop or large-scale enterprise data warehouses. The larger store supports long-term, high-scale storage while Infobright, a MySQL engine, quickly drills down on the latest subsets of data of interest. Columnar design and data-skipping technology ensure that only the information that is relevant to each query is analyzed, ensuring sub-second response times. Data is indexed automatically on ingest without partitioning, and minimal tuning is required. It's a low-cost, fleet-footed alternative for fast ad-hoc analysis. ——这款产品特别适合机器自动产生的数据,用于运维还是不错的
11. Kognitio

Kognitio steps up in-memory analysis
Analytical DBMS: Kognitio Analytical Platform.
In-memory DBMS: Kognitio Analytical Platform.
Hadoop distribution: None.
Stream-processing technology: None.
Hardware/software systems: Kognitio Appliance.
Kognitio's massively parallel processing DBMS competes against Actian Matrix (formerly ParAccel), HP Vertica, IBM PureData System for Analytics (formerly Netezza), and Pivotal Greenplum. The vendor has long supported RAM-intensive deployments and provides the administrative ability to run analyses and processes in memory. Customer Tivo Research Analytics deployed Kognitio with a high RAM-to-disk ratio to ensure fast query response times to report on TV ads viewed in 70 million cable-TV-equipped households.
Lately, Kognitio has put an even bigger emphasis on in-memory analysis, and it has developed an integration with the Hortonworks Data Platform that supports in-memory SQL analysis on top of Hadoop. It also offers an appliance and cloud-based services.
12. MapR

MapR sprints ahead on performance
Analytical DBMS: HBase; supports Drill, Hive, Impala, Shark, and other (non-DBMS) SQL-on-Hadoop options.
In-memory DBMS: MapR touts in-memory performance through (nib-DBMS) open-source projects Drill and Shark.
Hadoop distributions: MapR M3, MapR M5, MapR M7.
Stream-processing technology: MapR supports streaming analysis through Storm and through an integration with Informatica HParser.
Hardware/software systems: Hardware configurations available through partners including Cisco, HP, IBM, and NetApp.
MapR marches to the beat of its own drum, replacing bits and pieces of the Hadoop framework to deliver higher performance or to fill gaps in functionality. Early on, it replaced HDFS with an alternative based on the Network File System (NFS) to ensure high availability. In a tie between NFS and Informatica HParser software introduced in 2012, MapR introduced an option for stream processing on top of Hadoop. The 2013 MapR M7 Hadoop distribution addresses weakness in HBase by doing away with region servers, table splits and merges, and data-compaction steps. MapR also implemented its own architecture for snapshotting, high availability, and system recovery.
With M7, MapR also introduced optional LucidWorks Search software on top of Hadoop for building out recommendation engines, fraud-detection, and predictive applications. MapR promotes Apache Drill as its SQL-on-Hadoop option of choice, but it pragmatically touts open-source and commercial alternatives including Apache Hive, Impala, Shark-on-Spark, Hadapt and others, perhaps responding to rivals who slam MapR's go-it-alone ways.
The community addresses Hadoop's squeakiest wheels at its own pace, but MapR seems to thrive on moving ahead with commercial alternatives with the promise of better performance.
13. Microsoft

Microsoft is all in on big data
Analytical DBMS: SQL Server 2012 Parallel Data Warehouse (PDW).
In-memory DBMS: SQL Server 2014 In-Memory OLTP (option available with SQL Server 2014, set for release by second quarter of 2014).
Stream-processing technology: Microsoft StreamInsight.
Hadoop distribution: HDInsight/Windows Azure HDInsight Service (based on Hortonworks Data Platform).
Hardware/software systems: Dell Parallel Data Warehouse Appliance, HP Enterprise Parallel Data Warehouse Appliance.——基于PC服务器的数据仓库设备,肯定不是 Teradata 专用设备
Microsoft's vision is to provide a complete information production process for data -- all data. It has embraced Hadoop for high-scale and unstructured data, partnering to build HDInsight based on the Hortonworks Data Platform. HDInsight is available as a service on Microsoft's Azure Cloud or can be used on premises. You manage HDInsight with Microsoft Systems Center, virtualize its resources with Microsoft Virtual Machine Manager, and control access to its data with Active Directory. Drawing from the hundreds of terabytes or petabytes in Hadoop, Microsoft customers can then analyze boiled-down result sets in SQL Server Parallel Data Warehouse. PDW is a massively parallel processing DBMS that includes a PolyBase access layer for combining non-relational data from Hadoop and structured data from a PDW warehouse or mart.
Microsoft analyzes streaming data with Microsoft StreamInsight, and it handles high-volume machine-data and technical analysis with its High Performance Computing Cluster. No matter how complex or high-scale the challenge, Microsoft sees the analysis getting back to SQL Server Analysis Services, Information Integration Services, Reporting Services, Master Data Services, and the world's most popular BI tool, Office Excel with PowerPivot for in-memory analysis and PowerView for data visualization.
There's no doubt that Microsoft is amassing all the pieces, but it's early days for HDInsight, and we still don't see many PDW deployments after three years in the market. We're watching to see whether the release of SQL Server 2014, expected in the first half of this year, and the fast growth of the Windows Azure cloud, with its public data market and HDInsight service, help elevate Microsoft's name in enterprise big data.
14. Oracle

Oracle lives by its flagship database
Analytical DBMSs: Oracle Database, Oracle MySQL, Oracle Essbase.
In-memory DBMS: Oracle TimesTen, Oracle Database 12c In-Memory Option (announced in 2013 without details, roadmaps, or release dates).
Stream-analysis option: Oracle Event Processing.
Hadoop distribution: Resells and supports Cloudera Enterprise.
Hardware/software systems: Exadata, Exalytics, Oracle Big Data Appliance.
Oracle rivals IBM in the depth and breadth of its data-management offerings. It offers multiple databases, including market leaders Oracle Database and MySQL, and multiple options for data integration, data-quality management, master-data management, business intelligence, and analytics. Like IBM, it also has its own hardware unit (Oracle Sun) that supplies the servers used in its various "engineered systems."
In 2013, Oracle moved toward managing all of its data and big-data technologies with Oracle Enterprise Manager. That includes the Oracle Big Data Appliance, which packages Cloudera's Hadoop distribution and the Oracle NoSQL database. The company has also brought together multiple low-latency technologies as part of its "Oracle Fast Data" family. The components include Oracle Event Processing, Oracle Coherence, Oracle NoSQL, GoldenGate and Data Integrator (data integration), Oracle Business Analytics, and Oracle Real-Time Decisions. This collection spans low-latency demands from filtering and correlation to data movement and transformation to analysis and real-time decision support.
One area where Oracle has yet to deliver is in-memory performance tied to its flagship Oracle Database. The company announced an Oracle Database 12c In-Memory Option at Oracle Open World in 2013, but there's no beta or firm release data at this writing. Oracle's TimesTen in-memory database, originally developed by HP Labs in 1996, is for niche in-memory applications and does not match the broad applicability of SAP Hana or the soon-to-be-released SQL Server 2014 OLTP In-Memory option.
Oracle has Hadoop in its portfolio by way of its Cloudera partnership, but Oracle database executives have publicly dismissed Hadoop as "primitive and batch oriented," touting SQL extensions to Oracle Database for handling variable data such as stock trade data, clickstreams, or sensor data typically handled on Hadoop. Although Cloudera, Hortonworks, IBM, Pivotal, MapR, and others are working on ways to do SQL analysis, in-memory analysis, and even streaming analysis on top of Hadoop, Oracle sees this platform as a source from which to draw data sets for analysis within Oracle Database. In short, Oracle Database, as always, is at the center of this company's attention.
15. Pivotal

Pivotal eyes cloud, big data, and app development
Analytical DBMS: Pivotal Greenplum Database.
In-memory DBMS: Pivotal GemFire and SQLFire. Pivotal HD used in combination with GemFire XD and HAWQ for in-memory analysis on top of Hadoop.
Stream-analysis option: Pivotal is working a project aimed at integrating its GemFire (NoSQL) and SQLFire in-memory data grid capabilities with Pivotal Hadoop and Spring XD as a data-ingest mechanism to support scalable, streaming-data analysis.
Hadoop distribution: Pivotal HD.
Hardware/software systems: Pivotal Data Computing Appliance
There's no shortage of ambition at Pivotal, an EMC spinoff that offers big-data infrastructure as well as an abstraction layer for cloud computing (based on Cloud Foundry) and an agile application development environment (based on SpringSource). Pivotal's big-data and analytics capabilities blend the Pivotal HD Hadoop distribution with GemFire SQL Fire in-memory technology, the Greenplum database, and HAWQ (Hadoop With Query) SQL querying capabilities. It also has close ties and in-database integrations with SAS analytics.
The question with Pivotal is just how much energy, investment, and "oomph" it can bring to three bold fronts of next-generation computing: big data, cloud, and application development. Pivotal's largest competitors -- IBM, Oracle, and Microsoft -- can rely on the revenue from well-established data-integration, data-quality, BI, and analytics software that Pivotal lacks. Competitors such as Cloudera, Hortonworks, and Teradata can focus exclusively on big-data analytics. Time will tell if Pivotal's products and execution can keep up with its bold ambitions for big data as well as cloud integration and application development.——Pivotal 有雄心做全系列的工作,能否成功拭目以待
16. SAP
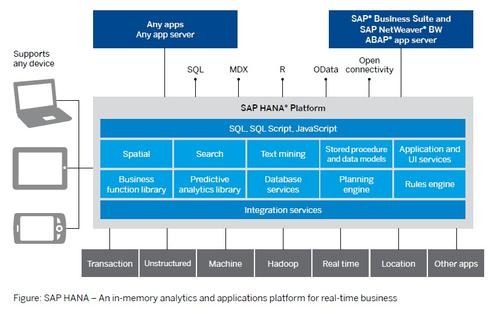
SAP puts Hana at the center of analysis
Analytical DBMSs: SAP Hana, SAP IQ.
In-memory DBMS: SAP Hana.
Stream-analysis option: SAP Event Stream Processing.
Hadoop distribution: Resells and supports Hortonworks, Intel; Hadoop integrations certified by Cloudera and MapR.
Hardware/software systems: Multiple hardware configuration partners include Dell, Cisco, Fujitsu, Hitachi, HP, and IBM.
Whether data sources are structured or unstructured, batch or streaming, large or small, SAP invariably puts forward its Hana in-memory platform as the answer to all needs -- whether analytic or transactional. When data is truly big or unstructured, SAP supports various Hadoop distributions, with Hana accessing data through Hive. When data needs to be archived for long-term historical analysis, SAP IQ (formerly Sybase IQ) offers a compressed, columnar DBMS adapted to support MapReduce processing as a SQL-based alternative to Hadoop.
Hana has a built-in predictive analytics library, R language support, spatial processing, natural language processing, and text analytics libraries. If need be, text and unstructured data analyses can be pushed down into Hadoop using SAP Data Services. Result sets can be returned to Hana for fast, in-memory analysis.
There are times when SAP seems tone deaf, incessantly promoting "real-time" whether there's a clear need for that level of performance or not. The upside of investing with SAP is that it's ahead of the curve on low-latency analysis with Hana as well as fast data-loading and stream-processing capabilities (the latter gained through the acquisition of Sybase). When you've spotted a clear opportunity for breakthrough, low-latency performance, SAP has the tools to take you there.
17. Teradata

Teradata delivers unified big data architecture
Analytical DBMS: Teradata, Teradata Aster.
In-memory DBMS: Although not an in-memory DBMS, Teradata Intelligent Memory monitors queries and automatically moves the most-requested data to the fastest storage tiers available, with options including RAM, flash, SSD, and various speeds of conventional spinning discs.
Stream-analysis option: None.
Hadoop distribution: Resells and supports the Hortonworks Data Platform.
Hardware/software systems: Teradata and Teradata Aster are integrated software/hardware systems. Hadoop is supported with two Teradata appliance offerings as well as standardized Dell configurations.
Teradata entered the big-data era boasting the largest roster of petabyte-scale enterprise data warehouse (EDW) customers of any vendor. It took a couple of years for the company to accept that SQL could not satisfy all needs, but in 2011 it acquired Aster Data and in 2012 it partnered with Hortonworks to build out what it calls its Unified Data Architecture (UDA).
The Teradata DBMS is at the heart of the UDA, supporting EDWs and marts for production BI and analytical needs. Options include SQL and various in-database analytic options including extensive support for SAS. The company has kept this DBMS at the forefront of performance with hybrid row and columnar compression and an Intelligent Memory feature for fast querying from RAM as well as SSDs, flash, or various speeds of spinning disks.
Aster is the UDA data-discovery platform, a small, transient store for day-to-day exploration of structured and multi-structured (clickstream, social, or machine) data. Analysis options include SQL, SQL-MapReduce, and SQL-graph analysis. Hadoop is the option for high-scale, low-cost storage, and subsets of data from this store can be copied to Teradata Aster or drawn into Teradata using SQL-H, the company's SQL-on-Hadoop option.
Hadoop boosters such as Cloudera would argue that cost and scale advantages will lead customers to do more of their analyses, including SQL, graph, and, of course, MapReduce, on Hadoop. Teradata is counting on its SQL-friendly ways -- and the foreign nature of Hadoop tools and languages for many practitioners -- to keep structured-data analyses in Teradata and variable-data analyses in Teradata Aster. The more popular, capable, and easy to use that Hadoop becomes, the less compelling a separate data-discovery platform will be. Regardless, there's no doubt that the core Teradata DBMS will continue to be a cornerstone of data management for lots of big and performance-driven companies.
posted on 2017-11-13 16:22 Stevens0102 阅读(220) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号