查询表中的所有列数据,去除指定列相同的数据
数据表如下图:

1.查询保重的数据,如果名字重名的,取Id大的,如不重名则直接取出
select t.* from Table_1 t, (select max(id) id,name from Table_1 group by name) t1 where t.id=t1.id and t.name=t1.name
运行结果:
2.查询保重的数据,如果名字重名的,取birth大的,如不重名则直接取出
select * from [Table_1] t where not exists (select 1 from [Table_1] t1 where t.birth < t1.birth and t.name=t1.name)
运行结果:
3.错误写法:
select * from (select distinct(name) from [Table_1]) as a left join [Table_1] as b on a.name=b.name
运行结果: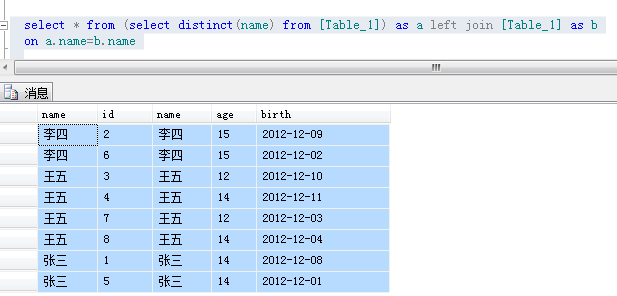
错误解析:left join 是可以一对多的,正因为“一对多”,所以就重复了。虽然说left join 是以左边为基准进行连接,但是要正确理解这句话:
如果左边一个“张三”,右边两个“张三”,left join后的记录就是2条。
left join的正确理解应该是:左边有这个名字,右边也有,则连接为一条数据;如果左边有这个名字,右边没有,则左边仍显示,但右边对应的连接部分显示为空
千万不要把“left join”理解为以左边为基准了,连接后的数据条数就是和left的数据条数一样
注意:1.不能用连接查询来做,因为用name不能唯一确定一行,只有加上id,才能唯一确定一行
2.如果用到group by的话,select中的字段要么是group by的字段,或者是聚合表达式字段,所以你给id加了max()聚合函数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号