
python学习笔记-celery介绍和使用
一、celery介绍
1、简介
celery是分布式任务队列
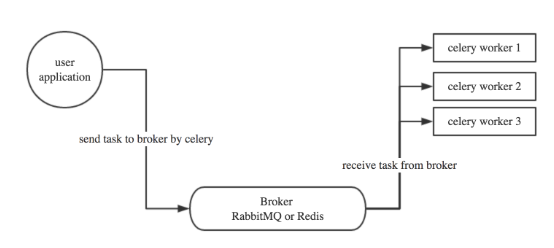
celery在执行任务时需要一个消息中间件来接收和发送消息,以及存储结果,一般使用rabbitmq,redis
celery的优先:
简单:配置和使用比较简单
高可用:当任务失败或执行过程中连接中断,celery会自动尝试重新执行
快速:每分钟可处理上百万个任务
灵活:几乎celery每个组件都可以被扩展和自定制
celery的工作流程:
2、定时任务
2.1、linux的定时任务
crontab
crontab -e 创建定时任务,第二步选择编辑器后进入

创建命令的具体语法,略。
2.2、celery实现定时任务功能,(示例基本工作流程)
步骤1:
celery安装
pip install celery (python安装celery库)
ubuntu上安装celery
$sudo apt install celery
步骤2:
新建py文件
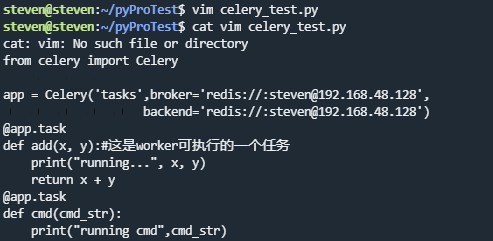
步骤3:
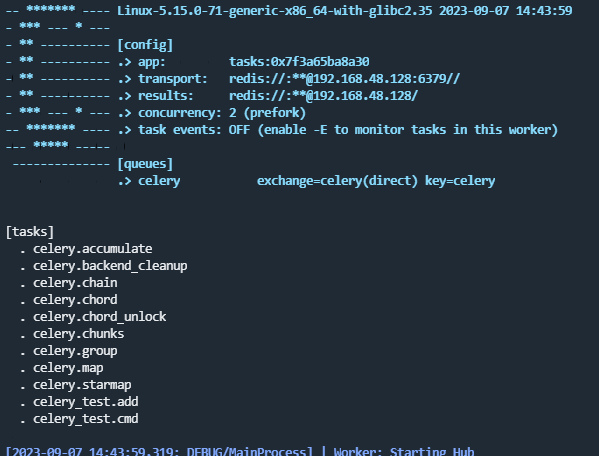
启动Celery Worker来开始监听并执行任务
celery -A celery_test worker -l debug (-l debug 表示日志等级)
步骤4:手动调用任务,再打开一个终端, 进行命令行模式
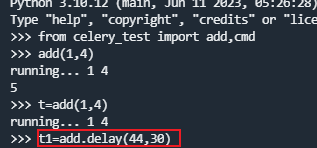
远程执行情况

步骤5:拿执行结果
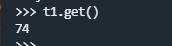
检查任务是否完成
t1.ready() #返回True表示已完成
二、celery在项目中使用
1、基本场景流程
示例2、项目名s3Celery,(使用linux环境)结构如下

》创建celery.py
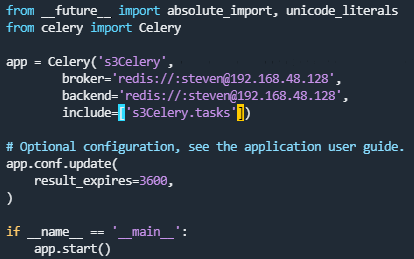
#第一行表示从绝对路径引用,表示第二行是从python的库中导入而不是自建的py文件
》创建任务

》启动worker

》打开终端,调用任务
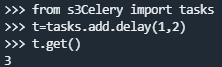
!Celery 任务执行有时成功有时失败(提示NotRegistered)
因为开发中使用的redis服务是共享的,且有多个部署了Celery的服务使用此Redis,但存储时未做db切割,因此任务在生成时会出现被别的服务领走情况,因此造成任务执行的失败。解决办法:做redis的数据库分割,避免冲突

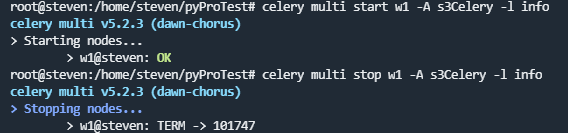
!后台启动worker
使用celery multi命令后台启动一个或多个worker,需要用管理权限
启动
$ celery multi start w1 -A s3Celery -l info
停止
$ celery multi stop w1 -A s3Celery -l info
2、celery定时任务
celery支持定时任务,设定好任务的执行时间,celery就会定时自动帮你执行, 这个定时任务模块叫celery beat
创建定时任务py文件periodic_task.py
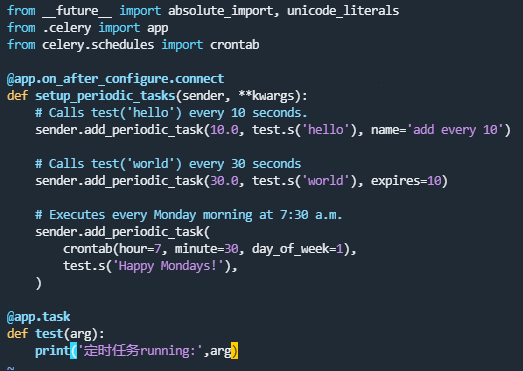
将定时任务添加到celery的include

启动worker,等待执行任务
$ celery -A s3Celery worker -l info
启动任务调度器 celery beat
任务添加好了,需要让celery单独启动一个进程来定时发起这些任务, 注意, 这里是发起任务,不是执行,这个进程只会不断的去检查你的任务计划, 每发现有任务需要执行了,就发起一个任务调用消息,交给celery worker去执行
$ celery -A s3Celery.periodic_task beat
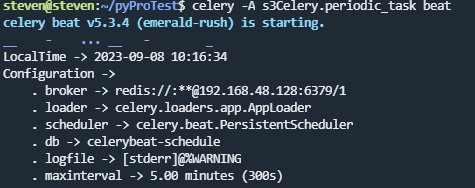
检查worker的执行情况
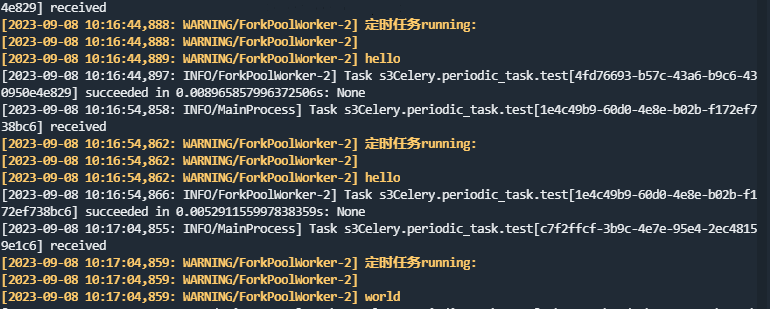
!!也可以像写配置文件 一样的形式添加定时任务, 下面是每15秒执行的任务
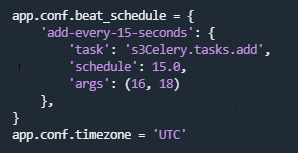
执行结果

*启动beat调度器显示错误,也能正常发起任务

*报错问题,把目录中的celerybeat-schedule文件删除,重新启动beat调度器,不报错
*更复杂的定时配置,用crontab功能,跟linux自带的crontab功能是一样的,可以个性化定制任务执行时间
'schedule': crontab(hour=7, minute=30, day_of_week=1),
三、celery在Django中实现定时任务
安装django对应包
$ pip3 install django-celery-beat
》添加到installed_apps
》更新数据表
python manage.py migrate
》启动Django服务,admin页有3张表

》新增记录创建定时任务,然后启动beat和worker,beat是从数据库读记录,命令如下
$ celery -A Djangopro beat -l info -S django
从worker可看到定时任务执行

