
Python数据分析易错知识点归纳(一):基础知识
一、python基础
字符串replace方法
txt = txt.replace(s, ' ')
# 光是txt.replace(s, ' ')是不会对txt产生影响的
# 下面每次循环replace后,w的值是不改变的
w = 'China520'
for x in w:
if '0' <= x <= '9':
continue
else:
k = w.replace(x, '')
print(k) # Chin520
字符串join方法
li = [1, 's', '4', 'b']
s = ','.join([str(each) for each in li]) # 注意必须先转成字符串列表,否则报错
如何对字典中的value进行排序
words = {}
for word in txt_list:
words[word] = words.get(word, 0) + 1
words_list = list(words.items()) # 每一个元素为(key,value)元组, 直接利用list(),这里很妙!!!
words_list.sort(key=lambda x:x[1], reverse=True)
# 或
words_list = sorted(words_list, key=lambda x:x[1], reverse=True)
字符串全部改为小写,并将特殊字符剔除
def getText():
txt = open("hamlet.txt", "r").read()
txt = txt.lower() # 这里不用循环
for s in '!"#$%&()*+,-./:;<=>?@[\\]^_‘{|}~':
txt = txt.replace(s, ' ')
return txt
字符串切割split
txt_list = txt.split() # 不带参数时默认用空格切割
字典update/pop方法
clerkDict.update({"mobile":"18930964799","city":"shanghai"}) # 更新或新增合并到clerkDict
clerkDict.pop("city") # 删除city项 这里不带参数
巧用set去重
s = s.replace('\n', ' ')
names = set(s.split())
巧用list()
字典转元组嵌套的列表方法:li = list(dic.items())
遍历过程中对list进行操作
dat = ['1', '2', '3', '0', '0', '0']
for item in dat:
if item == '0':
dat.remove(item) # 每次只删除第一次匹配的
print(dat)
'''
['1', '2', '3', '0']
'''
eval()的用法: 用来执行一个字符串表达式,并返回表达式的值。
input = input()
input_dict = eval(input) # 这里不需要再加dict()
>>>x = 7
>>> eval( '3 * x' )
21
>>> eval('pow(2,2)')
4
>>> eval('2 + 2')
4
>>> n=81
>>> eval("n + 4")
85
捕获异常是try... except...finally
try:
...
except: # 这里可以不写具体的错误类型
print('输入错误')
进制
含b 二进制
含o 八进制
含x 十六进制
oct() 转八进制
hex() 转十六进制
int() 转八进制或十六进制
print(0o1) # 1
print(0x01) # 1
print(oct(64)) # 0o100
print(hex(255)) # 0xff
print(int('0100')) # 100
print(int('0o100', 8)) # 64
print(int('0x40', 16)) # 64
# eval函数也可以转换,但速度会稍慢些
print(eval('100')) # 100
print(eval('0o100')) # 64
print(eval('0x40')) # 64
File
fileStr=fileStr.strip() # 去除头尾空格、\n、\r、\t
# lstrip() 去除左边的 rstrip() 去除右边的
# open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
f = open(path)
for each_line in f.readlines():
li = each_line.strip().split(',')
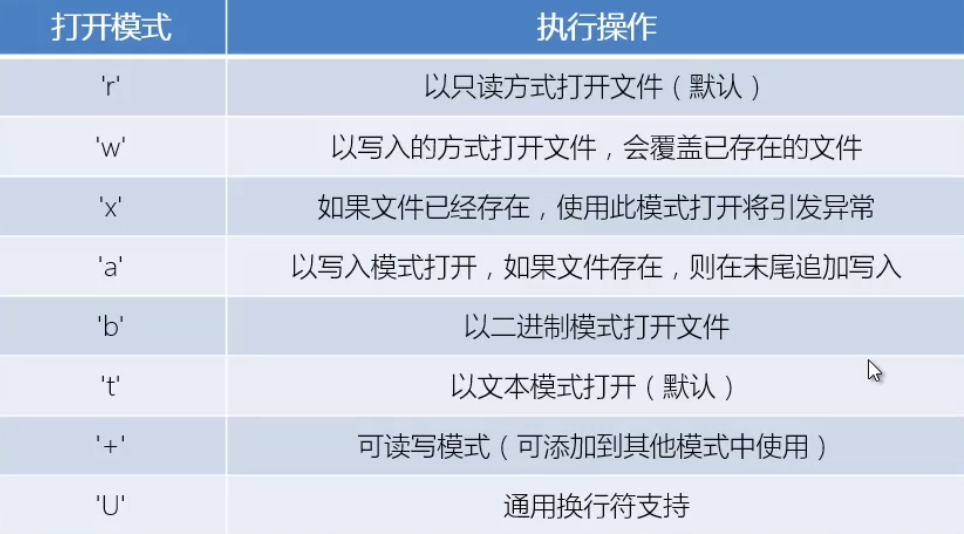
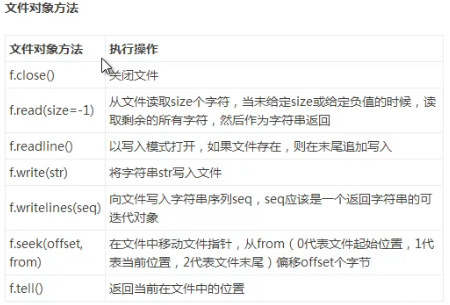
os/os.path


pickle
file = open("c:/person.txt", "wb") # python3必须以二进制写入模式
pickle.dump(person, file) # 将字典序列化写入文件
file.close()
# 将person字典从文件中读取
file = open("c:/person.txt", "rb")
personFromFile = pickle.load(file)
# numpy读取文件
data = np.loadtxt('iris_data.csv')
逗号和分号
# 一行写几条语句,也是python唯一用分号的地方
x = 1;y = 2;z = 3
a,b,c = 1,2,3
# 赋值
x = y = z = 1
range
# start和end一样时,不执行
for i in range(1, 1):
print(i)
列表比较
list1 = [1, 2]
list4 = [1, 2, 3, 4]
print(list1 < list4) # True
$ | - ^
注意一定要是set(集合)才能做此操作,否则报错
top_10_by_perc = set(df_sort_by_perc[:10]['no'].values.tolist())
top_10_by_vol = set(df_sort_by_vol[:10]['no'].values.tolist())
print('涨幅和成交量均在前10名的股票:')
print(sorted(top_10_by_perc & top_10_by_vol))
print('涨幅或成交量在前10名的股票:')
print(sorted(top_10_by_perc | top_10_by_vol))
print('涨幅前10名,但成交量未进前10名的股票:')
print(sorted(top_10_by_perc - top_10_by_vol))
print('涨幅和成交量不同时在前10名的股票:')
print(sorted(top_10_by_perc ^ top_10_by_vol)) # ^号等于|减去&
God will send the rain when you are ready.You need to prepare your field to receive it.
