
Java 编译器
javac
javac 就是一个编译器;编译器就是把一种语言转换成另一种语言,也就是将对人友好的语言转换成对机器友好的语言。因此,javac 是把 *.java 源代码编译成 *.class 字节码,JVM 可以识别的二进制。
主要由4个模块组成:
词法剖析器:识别 java 中的 if、else、for、while 等关键字及其语句的合法性,构成符合标准的 token 流。
语法剖析器:对构成的 token 流进行语法剖析,检查它们构成的组合是否符合 java 语法标准,构成抽象的语法树。
语义剖析器:将 foreach、注解等杂乱的语法转换成最简略的语法,构成注解往后的语法树。
字节码生成器:将注解往后的语法树翻译器字节码。
Jit
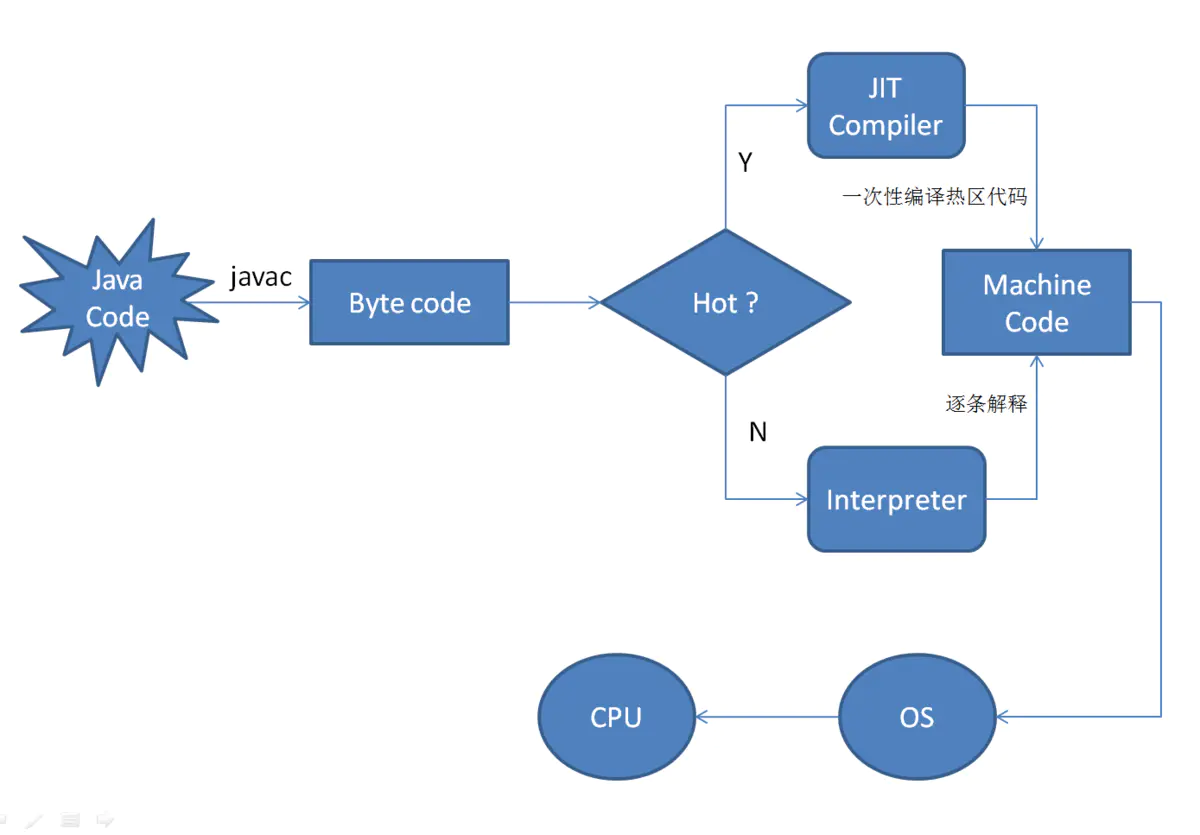
Jit 是 just in time 的缩写, 也就是即时编译编译器。使用即时编译器技术,能够加速 Java 程序的执行速度。下面,就对该编译器技术做个简单的讲解。
首先,我们大家都知道,通常通过 javac 将程序源代码编译,转换成 java 字节码,JVM 通过解释字节码将其翻译成对应的机器指令,逐条读入,逐条解释翻译。很显然,经过解释执行,其执行速度必然会比可执行的二进制字节码程序慢很多。为了提高执行速度,引入了 JIT 技术。
在运行时 JIT 会把翻译过的机器码保存起来,以备下次使用,因此从理论上来说,采用该 JIT 技术可以接近以前纯编译技术。下面我们看看,JIT 的工作过程。
初级调优:客户模式或服务器模式
JIT 编译器在运行程序时有两种编译模式可以选择,并且其会在运行时决定使用哪一种以达到最优性能。这两种编译模式的命名源自于命令行参数(eg: -client 或者 -server)。JVM Server 模式与 client 模式启动,最主要的差别在于:
-server 模式启动时,速度较慢,但是一旦运行起来后,性能将会有很大的提升。原因是:当虚拟机运行在-client 模式的时候,使用的是一个代号为 C1 的轻量级编译器,而-server 模式启动的虚拟机采用相对重量级代号为 C2 的编译器。C2 比 C1 编译器编译的相对彻底,服务起来之后,性能更高。
通过 java -version 命令行可以直接查看当前系统使用的是 client 还是 server 模式。例如:

中级编译器调优
大多数情况下,优化编译器其实只是选择合适的 JVM 以及为目标主机选择合适的编译器(-client,-server 或是 -XX:+TieredCompilation)。多层编译经常是长时运行应用程序的最佳选择,短暂应用程序则选择毫秒级性能的 client 编译器。
优化代码缓存
当 JVM 编译代码时,它会将汇编指令集保存在代码缓存。代码缓存具有固定的大小,并且一旦它被填满,JVM 则不能再编译更多的代码。我们可以很容易地看到如果代码缓存很小所具有的潜在问题。有些热点代码将会被编译,而其他的则不会被编译,这个应用程序将会以运行大量的解释代码来结束。
这是当使用 client 编译器模式或分层编译时很频繁的一个问题。当使用普通 server 编译器模式时,编译合格的类的数量将被填入代码缓存,通常只有少量的类会被编译。但是当使用 client 编译器模式时,编译合格的类的数量将会高很多。
在 Java 7 版本,分层编译默认的代码缓存大小经常是不够的,需要经常提高代码缓存大小。大型项目若使用 client 编译器模式,则也需要提高代码缓存大小。
现在并没有一个好的机制可以确定一个特定的应用到底需要多大的代码缓存。因此,当需要提高代码缓存时,这将是一种凑巧的操作,一个通常的做法是将代码缓存变成默认大小的两倍或四倍。
可以通过 –XX:ReservedCodeCacheSize=Nflag(N 就是之前提到的默认大小)来最大化代码缓存大小。
代码缓存的管理类似于 JVM 中的内存管理:有一个初始大小(用-XX:InitialCodeCacheSize=N 来声明)。代码缓存的大小从初始大小开始,随着缓存被填满而逐渐扩大。代码缓存的初始大小是基于芯片架构(例如 Intel 系列机器,client 编译器模式下代码缓存大小起始于 160KB,server 编译器模式下代码缓存大小则起始于 2496KB)以及使用的编译器的。重定义代码缓存的大小并不会真正影响性能,所以设置 ReservedCodeCacheSize 的大小一般是必要的。
再者,如果 JVM 是 32 位的,那么运行过程大小不能超过 4GB。这包括了 Java 堆,JVM 自身所有的代码空间(包括其本身的库和线程栈),应用程序分配的任何的本地内存,当然还有代码缓存。
所以说代码缓存并不是无限的,很多时候需要为大型应用程序来调优(或者甚至是使用分层编译的中型应用程序)。比如 64 位机器,为代码缓存设置一个很大的值并不会对应用程序本身造成影响,应用程序并不会内存溢出,这些额外的内存预定一般都是被操作系统所接受的。
编译阈值
在 JVM 中,编译是基于两个计数器的:一个是方法被调用的次数,另一个是方法中循环被回弹执行的次数。回弹可以有效的被认为是循环被执行完成的次数,不仅因为它是循环的结尾,也可能是因为它执行到了一个分支语句,例如 continue。
当 JVM 执行一个 Java 方法,它会检查这两个计数器的总和以决定这个方法是否有资格被编译。如果有,则这个方法将排队等待编译。这种编译形式并没有一个官方的名字,但是一般被叫做标准编译。
但是如果方法里有一个很长的循环或者是一个永远都不会退出并提供了所有逻辑的程序会怎么样呢?这种情况下,JVM 需要编译循环而并不等待方法被调用。所以每执行完一次循环,分支计数器都会自增和自检。如果分支计数器计数超出其自身阈值,那么这个循环(并不是整个方法)将具有被编译资格。
这种编译叫做栈上替换(OSR),因为即使循环被编译了,这也是不够的:JVM 必须有能力当循环正在运行时,开始执行此循环已被编译的版本。换句话说,当循环的代码被编译完成,若 JVM 替换了代码(前栈),那么循环的下个迭代执行最新的被编译版本则会更加快。
标准编译是被-XX:CompileThreshold=Nflag 的值所触发。Client 编译器模式下,N 默认的值 1500,而 Server 编译器模式下,N 默认的值则是 10000。改变 CompileThreshold 标志的值将会使编译器相对正常情况下提前(或推迟)编译代码。在性能领域,改变 CompileThreshold 标志是很被推荐且流行的方法。事实上,您可能知道 Java 基准经常使用此标志(比如:对于很多 server 编译器来说,经常在经过 8000 次迭代后改变次标志)。
我们已经知道 client 编译器和 server 编译器在最终的性能上有很大的差别,很大程度上是因为编译器在编译一个特定的方法时,对于两种编译器可用的信息并不一样。降低编译阈值,尤其是对于 server 编译器,承担着不能使应用程序运行达到最佳性能的风险,但是经过测试应用程序我们也发现,将阈值从 8000 变成 10000,其实有着非常小的区别和影响。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号