
BUAA OO 第一单元总结
BUAA OO 第一单元总结
第一次作业
作业简介
单变量多项式的括号展开(其中括号的深度至多为 1 层)
StarUML图与类结构
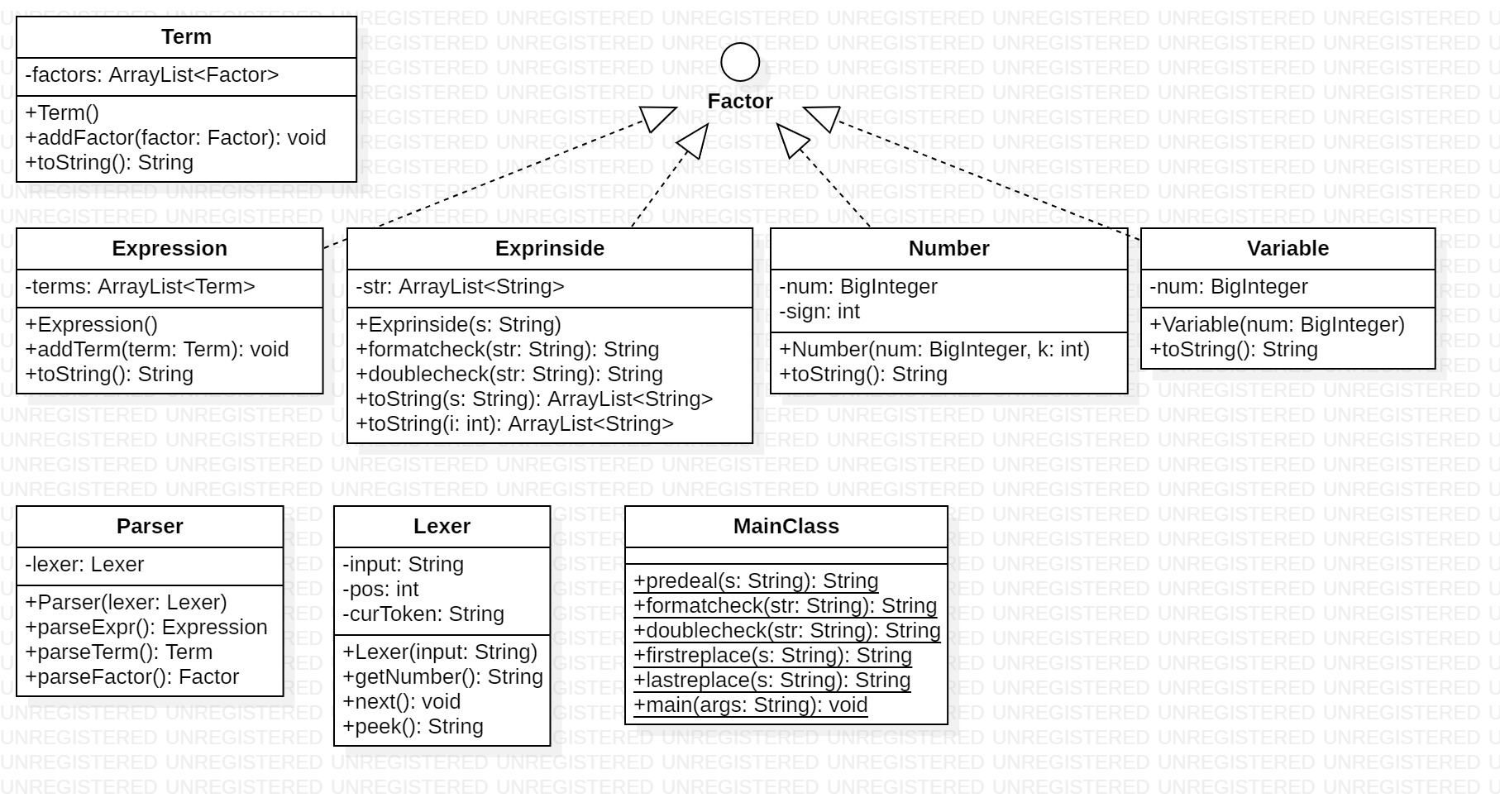
其中,各个类的含义如下:
|- MainClass:主类
|- Factor (interface):因子
|- Expression:总表达式类
|- Exprinside:表达式因子类
|- Number:数字类
|- Variable:变量类
|- Term:项类
|- Parser:递归下降解析器
|- Lexer:词法分析器
架构分析
作为java语言初学者,我在第一次作业的架构方面就遇到了困难,拿不定主意。
在完成了第一次训练后,发现助教提供的代码结构非常适合于此次作业,因而学习并模仿了过来。
整体思路
本次作业,从形式化描述中可以清晰地认识到一个表达式是由 “ 表达式-项-因子 ” 的层次结构构成的。因此整体架构的思路,也应该是构建起以 “ 表达式-项-因子 ” 为基础的树形结构。所以我建立了Expression表达式类、Term项类和Factor因子类,由于包含多种因子,我将因子设作接口,并构建了Number数字类、Variable变量类和Exprinside括号内表达式类。
建立架构的核心在于Parser类和Lexer类:
Lexer类的主要作用是,提取出表达式的“基础单元”,并传递给Parser类,起到了将一个字符串初步拆分的作用。
Parser类的主要作用是,接受Lexer类的信息,并根据表达式构造的逻辑,识别“基础单元”,通过其核心方法parseExpr()、parseTerm()与parseFactor()构建起表达式-项-因子的层次结构。
建立起树形结构后,对于如何去除多余的括号,我采取了基准思路的方法展开
- 对于形如 (\sum\limits_i a_i) + (\sum\limits_j b_j)(i∑a**i)+(j∑b**j) 的部分,将其展开为 \sum\limits_i a_i + \sum\limits_j b_ji∑a**i+j∑b**j 。
- 对于形如 (\sum\limits_i a_i) - (\sum\limits_j b_j)(i∑a**i)−(j∑b**j) 的部分,将其展开为 \sum\limits_i a_i + \sum\limits_j (-b_j)i∑a**i+j∑(−b**j) 。
- 对于形如 (\sum\limits_i a_i) \times (\sum\limits_jb_j)(i∑a**i)×(j∑b**j) 的部分,将其展开为 \sum\limits_i\sum\limits_ja_ib_ji∑j∑aib**j ,且不需要进行同类项的合并。
- 对于形如 a^ba**b 的部分,若 aa 含有括号,则将其展开为 a \times a \times a… \times aa×a×a…×a,共有 bb 个 aa ,接着使用第三条的思路进行展开。
展开过后,此时已经没有多余括号了,我采用formatcheck方法进行项内同类因子的合并:比如2*3合并为6。
经过项内同类项的合并,此时每个项应该都是形如 a*x**b 的形式,用doublecheck方法进行同类项的合并。
细节处理
1、为了避免指数符合 ''**'' 与乘号 ''*'' 混淆,将 ''**'' 替换为 "^"。
2、项间既可以用加号连接也可以用减号连接,将"-"替换为"+ -1"的形式来统一项间连接符。
比如 "1-x" 替换为 "1+-1x"。
3、避免空白字符干扰,第一个操作就把空白字符去除。
4、为了避免爆int,尽量使用BigInteger。
性能优化
1、项内同类因子合并、同类项合并。
2、省略为1的底数或指数
3、去除值为0的项
程序分析
度量分析
| class | OCavg | OCmax | WMC |
|---|---|---|---|
| Variable | 1.0 | 1.0 | 2.0 |
| Number | 1.5 | 2.0 | 3.0 |
| Expression | 1.6666666666666667 | 3.0 | 5.0 |
| Lexer | 2.0 | 4.0 | 8.0 |
| Parser | 2.5 | 5.0 | 10.0 |
| Term | 3.0 | 7.0 | 9.0 |
| Exprinside | 6.6 | 17.0 | 33.0 |
| Mainclass | 7.166666666666667 | 17.0 | 43.0 |
| Total | 113.0 | ||
| Average | 3.896551724137931 | 7.0 | 14.125 |
OCavg=Average opearation complexity(平均操作复杂度)
OCmax=Maximum operation complexity(最大操作复杂度)
WMC=Weighted method complexity(加权方法复杂度)
可以看到,Exprinside类和Mainclass类复杂度较高,可能的原因在于Exprinside类通过基准思路展开时,时间开销较大;Mainclass类的formatcheck方法和doublecheck方法合并同类项时,重新分析表达式,时间开销大。
其余类的复杂度尚可。
方法复杂度分析
| method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Expression.addTerm(Term) | 0.0 | 1.0 | 1.0 | 1.0 |
| Expression.Expression() | 0.0 | 1.0 | 1.0 | 1.0 |
| Expression.toString() | 3.0 | 1.0 | 3.0 | 3.0 |
| Exprinside.doublecheck(String) | 46.0 | 2.0 | 20.0 | 20.0 |
| Exprinside.Exprinside(String) | 1.0 | 1.0 | 2.0 | 2.0 |
| Exprinside.formatcheck(String) | 23.0 | 1.0 | 10.0 | 13.0 |
| Exprinside.toString(int) | 0.0 | 1.0 | 1.0 | 1.0 |
| Exprinside.toString(String) | 1.0 | 1.0 | 2.0 | 2.0 |
| Lexer.getNumber() | 3.0 | 1.0 | 4.0 | 4.0 |
| Lexer.Lexer(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Lexer.next() | 4.0 | 2.0 | 3.0 | 4.0 |
| Lexer.peek() | 0.0 | 1.0 | 1.0 | 1.0 |
| Mainclass.doublecheck(String) | 46.0 | 2.0 | 20.0 | 20.0 |
| Mainclass.firstreplace(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Mainclass.formatcheck(String) | 23.0 | 1.0 | 10.0 | 13.0 |
| Mainclass.lastreplace(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Mainclass.main(String[]) | 0.0 | 1.0 | 1.0 | 1.0 |
| Mainclass.predeal(String) | 35.0 | 1.0 | 13.0 | 16.0 |
| Number.Number(BigInteger, int) | 0.0 | 1.0 | 1.0 | 1.0 |
| Number.toString() | 1.0 | 2.0 | 2.0 | 2.0 |
| Parser.parseExpr() | 1.0 | 1.0 | 2.0 | 2.0 |
| Parser.parseFactor() | 8.0 | 4.0 | 5.0 | 5.0 |
| Parser.Parser(Lexer) | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.parseTerm() | 1.0 | 1.0 | 2.0 | 2.0 |
| Term.addFactor(Factor) | 0.0 | 1.0 | 1.0 | 1.0 |
| Term.Term() | 0.0 | 1.0 | 1.0 | 1.0 |
| Term.toString() | 13.0 | 1.0 | 7.0 | 7.0 |
| Variable.toString() | 0.0 | 1.0 | 1.0 | 1.0 |
| Variable.Variable(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| Total | 209.0 | 36.0 | 119.0 | 129.0 |
| Average | 7.206896551724138 | 1.2413793103448276 | 4.103448275862069 | 4.448275862068965 |
CogC=Cognitive complexity(认知复杂度)
ev(G)=Essential cyclomatic complexity(基本圈复杂度)
iv(G)=Design complexity(设计复杂度)
v(G)=cyclonmatic complexity(圈复杂度)
可以看到,formatcheck方法、doublecheck方法和predeal方法复杂度较高。
前两者是合并同类项方法,后者是预处理方法,说明在程序前后处理的算法方面还有待改进。
其余方法的圈复杂度尚可。
Bug分析
程序设计过程中的bug
程序设计过程中遇到过很多bug,多数为细节处理的考虑不周造成的。
比如对于负号的处理、合并同类项时判断同类项有误判、边界情况未考虑等等。
值得注意的是,我在调试过程中发现bug的地方,往往都是在预处理和最后的化简阶段引入的bug,而架构建立的部分基本上没有出现过bug。我认为其原因是递归下降解析字符串的算法比较完备,而我的预处理和化简算法较为繁琐,条件判断、循环查找的结构较多,因此遗留了一些bug隐患。这种特点也体现在了之前的复杂度分析中,预处理和化简方法的复杂度也是很高的。可以认为复杂度较高的代码,由于复杂的条件判断和循环,容易引入bug,以后的程序设计也需要注意。
公测中的bug
HW1的公测中,我的程序没有被检测出bug。
公测性能分被扣了一点,原因是没有把"x**2"化为"x*x",实属没有想到,下次一定。
互测中的bug
HW1的互测中,我的程序没有被检测出bug。
HW1的互测中,我未能发现房间中其他同学的bug。
测试思路
测试思路是 坑点针对测试+随机测试
其中坑点针对测试需要的是仔细分析指导书,找出指导书中表达式结构的一些边界情况
比如,最多能有几个连续的+-号?什么地方可以有空格?指数最大是多少?
针对这些边界情况或者易忽视的情况,构造测试数据进行测试。
随机测试就是随机构造数据,可以自己编写(或白嫖)测试程序。
我的感受
本次作业,我学会了java程序设计基础知识、递归下降方法等内容。
HW1要求较为简单,只涉及一层括号的嵌套,但对于我来说,似乎是本单元三次作业里花费时间最多的一次。
究其原因是,HW1是表达式系列任务的第一次编写,如何设计合适的架构、架构如何建立,都需要思考。
第一次作业的程序,在正确性上,经过反复调试,最终效果非常不错,公测互测中均无bug出现。
但是在可拓展性上,还是差了一些,我其实考虑过直接一步到位实现递归多层括号嵌套,但遇到了困难。
最终还是选择了将括号内表达式单独作为一个类,这样的话是不能满足后面括号多层嵌套的,可拓展性不高。
第二次作业
作业简介
较为复杂的表达式括号展开,加入了多层括号嵌套、三角函数(sin和cos)、求和函数与自定义函数
StarUML图与类结构
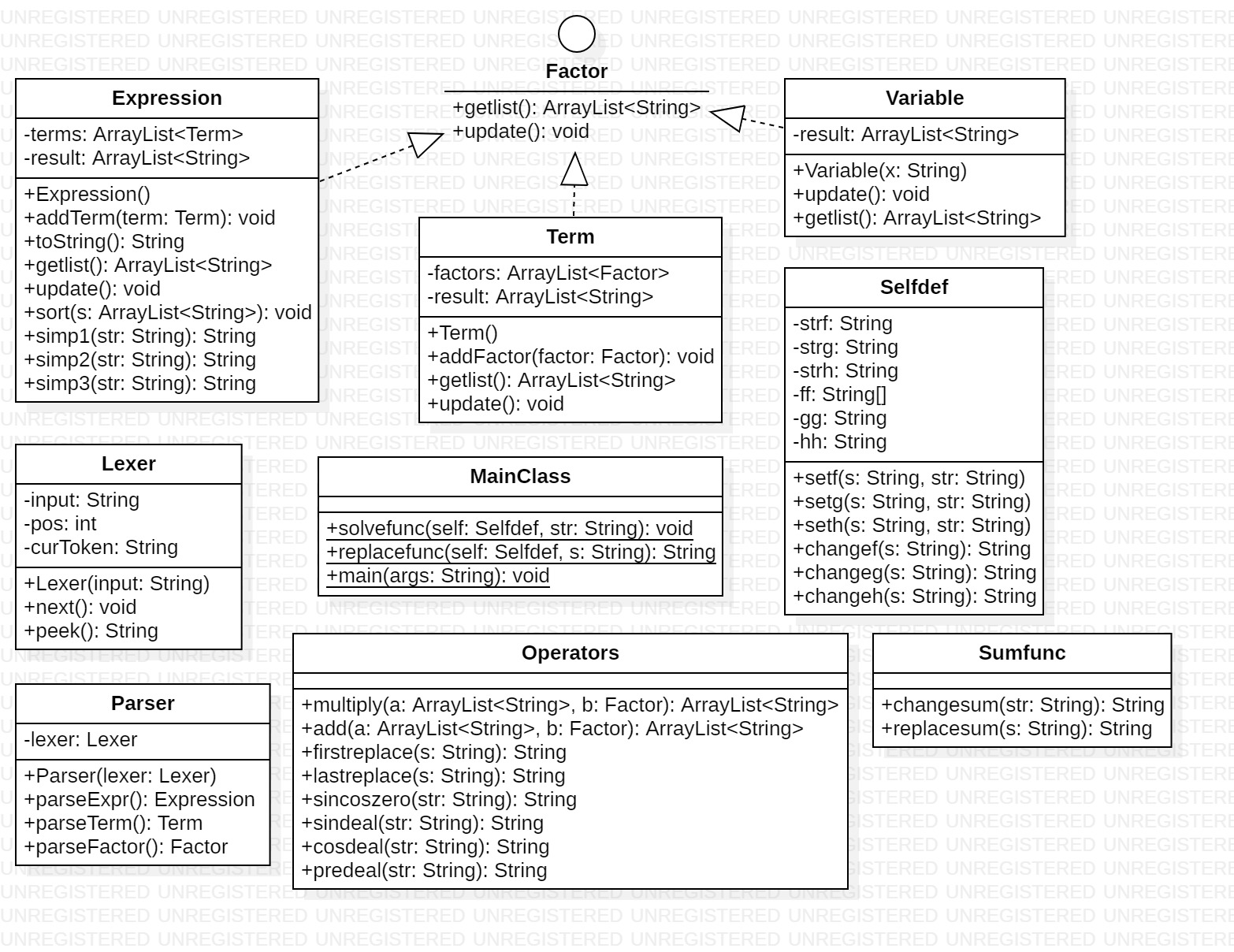
其中,各个类的含义如下:
|- MainClass:主类
|- Factor (interface):因子
|- Expression:表达式类
|- Term:项类
|- Variable:变量类
|- Operators:方法类(含预处理、化简相关方法)
|- Selfdef:自定义函数类
|- Sumfunc:求和函数类
|- Parser:递归下降解析器
|- Lexer:词法分析器
架构分析
整体思路
表达式的整体结构没变,依然是 "表达式-项-因子" 的结构,因此可以沿用之前的树型结构。
新增难点1:括号嵌套
此时Exprinside表达式因子类不再适用,改为在Parser类中递归调用parseExpr方法,实现表达式括号多次嵌套的解析。此时表达式与表达式因子不再作区分。
新增难点2:三角函数
第二次作业因子的变化巨大。第一次作业我的化简思路是建立在每一个项都可以化成固定形式(a*x**b)的基础上的,而这次由于三角函数的参与,项不再可以简单的化为某一固定形式。
由于此次作业,三角函数内部没有括号嵌套,形式也较为简单,无需在三角函数内部进一步操作:
<因子>在本次作业中只可能是常数因子或者变量因子中的幂函数
所以,我把三角函数( 如sin(x) )看作一个整体,用String直接存储。
相同因子的合并,我先将每个项中的因子用”*“分隔,然后分为四类:
数字、幂函数、sin函数和cos函数,前两类合并方法与HW1相同,后两类我采用字符串比大小的equal方法来判断是否是同类因子。
合并完毕同类因子后,我将sin函数与cos函数通过sort方法分别进行字符串大小排序。
最终每个项的表现形式为:
num * x**n1 * sin(...)**n2 * sin(...)**n3......* cos(...)**nk * cos(...)**n(k+1).....
的形式
字符串大小排序的作用是方便同类项的合并,下面进行解释:
对于sin(1)*sin(2)*sin(3)和sin(2)*sin(3)*sin(1)
两个项由于sin函数排列顺序不同,如果直接进行字符串比较,无法判断相等。
(其实可以通过数据结构,比如hashmap进行无序数据相等判断,但我没有采用hashmap的数据结构)
如果将二者sort一下,后者会被重排变成sin(1)*sin(2)*sin(3),这样就能通过equal方法判断相等了。
同类项的合并,分离项的数字,将其余部分用字符串比大小方法判断相等后合并。
新增难点3:求和函数和自定义函数
处理这两种因子,我的方法是提前替换。
提前进行替换,就是在解析整个表达式前,先把表达式中的所有自定义函数与求和函数都替换成表达式形式
比如
1
f(x,y) = x+y
(f(sin(x),2)+x)*2
我们先把f(sin(x),2)替换成(sin(x)+2)得到((sin(x)+2)+x)*2再进行进一步解析。
优点在于,替换后表达式相当于只是多了嵌套括号与三角函数,格式简化了。
缺点在于,较为繁琐,坑点也多。
细节处理
1、求和函数与自定义函数替换坑点
Sum求和函数替换i时,有可能会把sin中的i误替换
解决方法可以先将所有的sin替换为不相干符号例如 "?" ,再i替换后再将其换回sin
对于f(y,x)=x+y,待解析表达式为f(x,2)时
如果先替换y:得到x+x
再替换x:得到2+2,所得结果并非预期,其原因在于x同时可以作为形参和实参
解决方法可以是先处理x,也可以是先把形参x替换为一个不会出现的字符
2、sin(x**2)转换为sin(x*x)是非法的
3、HW1的细节处理在本次作业中仍然需要
性能优化
1、项内同类因子合并、同类项合并
2、省略为1的底数或指数
3、去除值为0的项
4、不在三角函数内的x**2替换为x*x
5、sin(0) = 0 , cos(0) = 1
6、cos函数内部取正,如cos(-8)=cos(8)
程序分析
度量分析
| class | OCavg | OCmax | WMC |
|---|---|---|---|
| Sumfunc | 5.5 | 7.0 | 11.0 |
| MainClass | 4.666666666666667 | 9.0 | 14.0 |
| Operators | 4.25 | 13.0 | 34.0 |
| Expression | 3.888888888888889 | 9.0 | 35.0 |
| Parser | 3.75 | 10.0 | 15.0 |
| Lever | 2.6666666666666665 | 6.0 | 8.0 |
| Selfdef | 2.0 | 3.0 | 12.0 |
| Term | 1.25 | 2.0 | 5.0 |
| Variable | 1.0 | 1.0 | 3.0 |
| Total | 137.0 | ||
| Average | 3.261904761904762 | 6.666666666666667 | 15.222222222222221 |
OCavg=Average opearation complexity(平均操作复杂度)
OCmax=Maximum operation complexity(最大操作复杂度)
WMC=Weighted method complexity(加权方法复杂度)
可以看到Operators类、MainClass类、Sumfunc类复杂度较高。
其中MainClass类相较于HW1复杂度有所下降,其原因是将MainClass类里的预处理方法和化简方法,移入了Operators类,简化了主类。
其余类复杂度尚可。
方法复杂度分析
| method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Operators.predeal(String) | 29.0 | 6.0 | 17.0 | 20.0 |
| MainClass.replacefunc(Selfdef, String) | 22.0 | 1.0 | 11.0 | 12.0 |
| Parser.parseFactor() | 17.0 | 7.0 | 10.0 | 10.0 |
| Sumfunc.replacesum(String) | 16.0 | 1.0 | 9.0 | 10.0 |
| Expression.simp3(String) | 15.0 | 1.0 | 8.0 | 8.0 |
| Expression.simp1(String) | 13.0 | 1.0 | 8.0 | 9.0 |
| Expression.simp2(String) | 11.0 | 2.0 | 7.0 | 8.0 |
| Lever.next() | 8.0 | 2.0 | 4.0 | 7.0 |
| Expression.sort(ArrayList) | 6.0 | 1.0 | 4.0 | 4.0 |
| Operators.cosdeal(String) | 6.0 | 4.0 | 3.0 | 4.0 |
| Operators.sincoszero(String) | 6.0 | 1.0 | 7.0 | 7.0 |
| Operators.sindeal(String) | 6.0 | 4.0 | 3.0 | 4.0 |
| Sumfunc.changesum(String) | 5.0 | 2.0 | 3.0 | 4.0 |
| MainClass.solvefunc(Selfdef, String) | 3.0 | 1.0 | 3.0 | 3.0 |
| Operators.multiply(ArrayList, Factor) | 3.0 | 1.0 | 3.0 | 3.0 |
| Selfdef.changef(String) | 3.0 | 3.0 | 3.0 | 3.0 |
| Selfdef.changeg(String) | 3.0 | 3.0 | 3.0 | 3.0 |
| Selfdef.changeh(String) | 3.0 | 3.0 | 3.0 | 3.0 |
| Expression.toString() | 1.0 | 1.0 | 2.0 | 2.0 |
| Expression.update() | 1.0 | 1.0 | 2.0 | 2.0 |
| MainClass.main(String[]) | 1.0 | 1.0 | 2.0 | 2.0 |
| Parser.parseExpr() | 1.0 | 1.0 | 2.0 | 2.0 |
| Parser.parseTerm() | 1.0 | 1.0 | 2.0 | 2.0 |
| Term.update() | 1.0 | 1.0 | 2.0 | 2.0 |
| Expression.Expression() | 0.0 | 1.0 | 1.0 | 1.0 |
| Expression.addTerm(Term) | 0.0 | 1.0 | 1.0 | 1.0 |
| Expression.getlist() | 0.0 | 1.0 | 1.0 | 1.0 |
| Lever.Lever(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Lever.peek() | 0.0 | 1.0 | 1.0 | 1.0 |
| Operators.add(ArrayList, Factor) | 0.0 | 1.0 | 1.0 | 1.0 |
| Operators.firstreplace(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Operators.lastreplace(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.Parser(Lever) | 0.0 | 1.0 | 1.0 | 1.0 |
| Selfdef.setf(String, String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Selfdef.setg(String, String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Selfdef.seth(String, String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Term.Term() | 0.0 | 1.0 | 1.0 | 1.0 |
| Term.addFactor(Factor) | 0.0 | 1.0 | 1.0 | 1.0 |
| Term.getlist() | 0.0 | 1.0 | 1.0 | 1.0 |
| Variable.Variable(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Variable.getlist() | 0.0 | 1.0 | 1.0 | 1.0 |
| Variable.update() | 0.0 | 1.0 | 1.0 | 1.0 |
| Total | 181.0 | 68.0 | 139.0 | 152.0 |
| Average | 4.309523809523809 | 1.619047619047619 | 3.3095238095238093 | 3.619047619047619 |
CogC=Cognitive complexity(认知复杂度)
ev(G)=Essential cyclomatic complexity(基本圈复杂度)
iv(G)=Design complexity(设计复杂度)
v(G)=cyclonmatic complexity(圈复杂度)
可以看到,predeal方法、replacefunc方法、replacesum方法、parseFactor方法复杂度较高。
predeal预处理方法复杂度较高,可能与循环的嵌套有关。
replacefunc方法与replacesum方法复杂度较高,可能与函数两层调用有关。
parseFactor方法复杂度较高,可能与处理括号时的递归使用有关。
其余方法复杂度尚可。
Bug分析
程序设计过程中的bug
程序设计过程中遇到过的bug,多数为细节处理的考虑不周造成的。
比如踩求和函数和自定义函数替换时的坑。
此外,复杂度较高的程序段,bug隐患也往往较高。
公测中的bug
HW2的公测中,我的程序没有被检测出bug。
公测性能分被扣了一点,原因是没有做三角函数平方和公式和二倍角公式的化简。
互测中的bug
HW2的互测中,我的程序没有被检测出bug。
HW2的互测中,我未能发现房间中其他同学的bug。
但是我发现了一位同房间同学误把三角函数中的x**2化为x*x的bug,即结果出现了sin(x*x)。
可惜互测不允许出现求和函数,不然可以hack一下~
测试思路
测试思路是 坑点针对测试+随机测试
其中坑点针对测试需要的是仔细分析指导书,找出指导书中表达式结构的一些边界情况
比如,sum函数里面的数字可以有多大?表达式什么地方可以出现空白字符?指数最大有多大?
针对这些边界情况或者易忽视的情况,构造测试数据进行测试。
随机测试就是随机构造数据,可以自己编写(或白嫖)测试程序。
我的感受
本次作业,我感受到了迭代开发的难度和如何根据新需求来改变已有架构的方法。
HW2难度提升很大,涉及多层括号的嵌套,三角函数,求和函数和自定义函数。
很多在HW1中很方便的规律在HW2中不再使用,比如项的结构在HW2中变得很复杂。
需求的增多与增强,带来的是对于原有架构的变更,甚至重新构建,此时可拓展性强的程序的优势就展现出来了。
我大体思路没变,但很多地方都进行了重构,重新梳理了思路,争取提高可拓展性,为HW3提供方便。
对于性能优化,我此次做得较少,虽然意识到了三角函数可以做优化,但是因为怕引入bug还是没有做太多优化。
在HW3中,我想尝试做更多优化,把这次没有考虑的求和公式与二倍角公式加进去。
第三次作业
作业简介
复杂的表达式括号展开,含多层括号嵌套,允许嵌套因子的三角函数,自定义函数调用允许任何一种因子
StarUML图与类结构
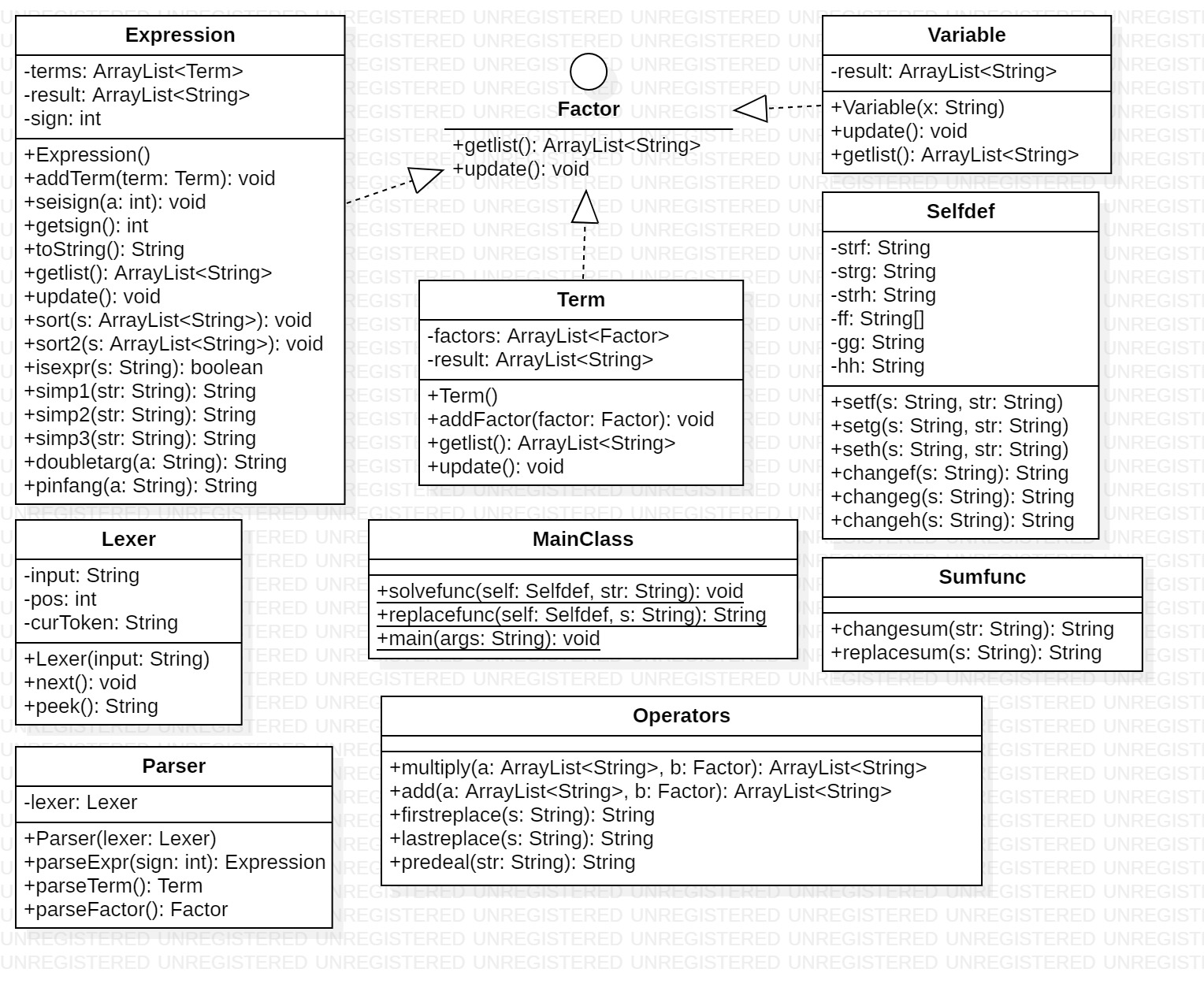
其中,各个类的含义如下:
|- MainClass:主类
|- Factor (interface):因子
|- Expression:表达式类
|- Term:项类
|- Variable:变量类
|- Operators:方法类(含预处理、化简相关方法)
|- Selfdef:自定义函数类
|- Sumfunc:求和函数类
|- Parser:递归下降解析器
|- Lexer:词法分析器
架构分析
整体思路
本次作业,功能上与HW2相比,有所增强,但并没有添加新的因子或其他。因此沿用HW2的架构,并作出调整。
新增难点1:三角函数内部允许存在表达式因子,并存在因子嵌套
这一变化代表着三角函数内部也有多余括号需要处理,故不能像HW2那样,将三角函数里外作为一个整体处理。
我采用的方法是,将三角函数也看作是一个 sin”表达式因子“ 或 cos”表达式因子“,我将三角函数第一层括号看作表达式因子的外括号,按照处理表达式因子的方法处理三角函数,这样就将三角函数与表达式因子作了统一。为了区别表达式因子到底是三角函数还是狭义的表达式因子,我在Expression类中新加入了属性sign,用以标识表达式因子的类别,普通为0,sin为1,cos为2。
新增难点2:自定义函数调用自定义函数或求和函数
这一变化,让之前简单的函数替换难以将自定义函数全部替换干净。
我采用的方法是,将自定义函数分层,使用多层循环,每次循环都替换最外面一层的,知道表达式中没有自定义函数为止。
例如:
2
f(x,y)=x+y
g(x,y)=x*y
f(g(1,2),g(2,3))+g(f(1,2),x)
第一层循环,表达式变成:g(1,2)+g(2,3)+f(1,2)*x
第二层循环,表达式变成:1*2+2*3+(1+2)*x
这样有一个缺点,就是可能时间开销略大,因为使用了多层循环。
细节处理
1、自定义函数作因子替换时注意增加必要的括号
例如:整体须增加括号
1
f(x,y)=x+y
f(x,y)*x
不加括号导致错误:x+y*x
添加括号才能正确:(x+y)*x
再如:因子须增加括号
1
f(x)=x**2
f(1)
不加括号不合法:1**2
添加括号才合法:(1)**2
2、sin(x**2)不可以盲目替换为sin(x*x),后者不合法
3、注意数字大小范围,尽量用BigInteger,以防爆int
4、HW2所处理的细节,在HW3仍需注意。
性能优化
1、三角函数之保留必要括号,比如sin(1)比sin((1))好。
2、项内同类因子合并、同类项合并
3、省略为1的底数或指数
4、去除值为0的项
5、适当的位置的x**2替换为x*x,如sin(x**2)就无须替换
6、sin(0) = 0 , cos(0) = 1,cos(-factor) = cos(factor)
7、必要的负负得正,如-sin(-8)可以替换为sin(8),-sin((-x-1))可以替换为sin((x+1))
8、负的项不要放在开头,如-x+sin(x)可以替换为sin(x)-x
9、三角函数平方和公式
10、三角函数二倍角公式
程序分析
度量分析
| class | OCavg | OCmax | WMC |
|---|---|---|---|
| Operators | 6.2 | 15.0 | 31.0 |
| Sumfunc | 5.5 | 7.0 | 11.0 |
| Expression | 5.266666666666667 | 12.0 | 79.0 |
| MainClass | 5.0 | 10.0 | 15.0 |
| Selfdef | 4.0 | 7.0 | 24.0 |
| Parser | 2.75 | 6.0 | 11.0 |
| Lever | 2.6666666666666665 | 6.0 | 8.0 |
| Term | 1.25 | 2.0 | 5.0 |
| Variable | 1.0 | 1.0 | 3.0 |
| Total | 187.0 | ||
| Average | 4.155555555555556 | 7.333333333333333 | 20.77777777777778 |
OCavg = Average opearation complexity(平均操作复杂度)
OCmax = Maximum operation complexity(最大操作复杂度)
WMC = Weighted method complexity(加权方法复杂度)
可以看到MainClass类、Sumfunc类、Expression类、Operators类复杂度较高。
Sumfunc与HW2复杂度相近,因为算法一致。
Operators复杂度增大,因为新增了三角函数平方和与三角函数二倍角等化简方法,复杂度有所提升。
MainClass类复杂度与HW2相比变化不大。
其余类复杂度尚可。
方法复杂度分析
| method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Operators.multiply(ArrayList, Factor) | 38.0 | 1.0 | 19.0 | 21.0 |
| Expression.doubletarg(String) | 34.0 | 8.0 | 10.0 | 13.0 |
| Expression.pinfang(String) | 32.0 | 7.0 | 12.0 | 12.0 |
| MainClass.replacefunc(Selfdef, String) | 31.0 | 1.0 | 16.0 | 17.0 |
| Operators.predeal(String) | 29.0 | 6.0 | 17.0 | 20.0 |
| Expression.update() | 16.0 | 1.0 | 4.0 | 8.0 |
| Sumfunc.replacesum(String) | 16.0 | 1.0 | 9.0 | 10.0 |
| Expression.simp3(String) | 15.0 | 1.0 | 8.0 | 8.0 |
| Expression.simp1(String) | 13.0 | 1.0 | 8.0 | 9.0 |
| Expression.isexpr(String) | 12.0 | 6.0 | 7.0 | 12.0 |
| Expression.simp2(String) | 11.0 | 2.0 | 7.0 | 8.0 |
| Selfdef.changef(String) | 9.0 | 3.0 | 7.0 | 8.0 |
| Selfdef.changeg(String) | 9.0 | 3.0 | 7.0 | 8.0 |
| Selfdef.changeh(String) | 9.0 | 3.0 | 7.0 | 8.0 |
| Expression.toString() | 8.0 | 4.0 | 6.0 | 6.0 |
| Lever.next() | 8.0 | 2.0 | 4.0 | 7.0 |
| Parser.parseFactor() | 7.0 | 5.0 | 6.0 | 6.0 |
| Expression.sort(ArrayList) | 6.0 | 1.0 | 4.0 | 4.0 |
| Expression.sort2(ArrayList) | 6.0 | 1.0 | 4.0 | 4.0 |
| Sumfunc.changesum(String) | 5.0 | 2.0 | 3.0 | 4.0 |
| MainClass.solvefunc(Selfdef, String) | 3.0 | 1.0 | 3.0 | 3.0 |
| MainClass.main(String[]) | 1.0 | 1.0 | 2.0 | 2.0 |
| Parser.parseExpr(int) | 1.0 | 1.0 | 2.0 | 2.0 |
| Parser.parseTerm() | 1.0 | 1.0 | 2.0 | 2.0 |
| Term.update() | 1.0 | 1.0 | 2.0 | 2.0 |
| Expression.Expression() | 0.0 | 1.0 | 1.0 | 1.0 |
| Expression.addTerm(Term) | 0.0 | 1.0 | 1.0 | 1.0 |
| Expression.getlist() | 0.0 | 1.0 | 1.0 | 1.0 |
| Expression.getsign() | 0.0 | 1.0 | 1.0 | 1.0 |
| Expression.setsign(int) | 0.0 | 1.0 | 1.0 | 1.0 |
| Lever.Lever(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Lever.peek() | 0.0 | 1.0 | 1.0 | 1.0 |
| Operators.add(ArrayList, Factor) | 0.0 | 1.0 | 1.0 | 1.0 |
| Operators.firstreplace(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Operators.lastreplace(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.Parser(Lever) | 0.0 | 1.0 | 1.0 | 1.0 |
| Selfdef.setf(String, String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Selfdef.setg(String, String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Selfdef.seth(String, String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Term.Term() | 0.0 | 1.0 | 1.0 | 1.0 |
| Term.addFactor(Factor) | 0.0 | 1.0 | 1.0 | 1.0 |
| Term.getlist() | 0.0 | 1.0 | 1.0 | 1.0 |
| Variable.Variable(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Variable.getlist() | 0.0 | 1.0 | 1.0 | 1.0 |
| Variable.update() | 0.0 | 1.0 | 1.0 | 1.0 |
| Total | 321.0 | 84.0 | 196.0 | 224.0 |
| Average | 7.133333333333334 | 1.8666666666666667 | 4.355555555555555 | 4.977777777777778 |
CogC=Cognitive complexity(认知复杂度)
ev(G)=Essential cyclomatic complexity(基本圈复杂度)
iv(G)=Design complexity(设计复杂度)
v(G)=cyclonmatic complexity(圈复杂度)
可以看到,multiply方法、doubletarg方法、pinfang方法、replacefunc方法、predeal方法复杂度较高。
其中doubletarg方法和pinfang方法为新增方法,分别为二倍角和平方和算法。
由于采用了类似暴搜的方式,因此复杂度较高。
其余方法复杂度尚可。
Bug分析
程序设计过程中的bug
程序设计过程中遇到过的bug,多数为细节处理的考虑不周造成的。
比如自定义函数替换不完全等。
此外,复杂度较高的程序段,bug隐患也往往较高。
公测中的bug
HW3的公测中,我的程序没有被检测出bug。
公测性能分相较于HW2有所进步,因为作了较为充分的优化。
互测中的bug
HW3的互测中,我的程序没有被检测出bug。
HW3的互测中,我hack成功了5次,也是我首次hack成功。
hack策略:
我发现了这次互测允许出现sum函数了,就针对性测试了一下
1、sum常数因子爆int的bug:hack了3位同学
2、sum函数求和表达式不支持高指数次幂函数,如 "i**3",hack了1位同学
3、sum函数求和表达式不支持高指数次幂三角函数,如"sin(i)**3",hack了1位同学
测试思路
测试思路是 坑点针对测试+随机测试
其中坑点针对测试需要的是仔细分析指导书,找出指导书中表达式结构的一些边界情况
比如,自定义函数调用嵌套因子?表达式什么地方可以出现空白字符?指数最大有多大?
针对这些边界情况或者易忽视的情况,构造测试数据进行测试。
随机测试就是随机构造数据,可以自己编写(或白嫖)测试程序。
我的感受
本次作业,体验感不错,HW2的架构可拓展性还可以,因此将之迁移、调整到满足HW3的要求并不费力。
我尝试了HW2没有尝试的三角函数公式性能优化,成效不错。
我认识到了,一个好的、可拓展性强的架构,可以大大节省之后的迭代时间,而节省下来的时间又可以用来进行算法的优化和性能的优化,可以说好处多多。
对第一单元的感受
第一单元通过3次迭代开发的作业,让我体会到了面向对象的思想特质、让我学会了java语言程序设计的基础知识和编程方法,熟悉了常见的类库、方法的使用,收获不小。
从面向过程到面向对象思维的转化,层次化设计的思想的培养仍需继续努力。
作业难度不小、颇具挑战,所幸测试充足,我在此次作业中的表现还是很令人满意的。
3次作业,我在公测和互测中没有被查出任何bug,以0bug结束第一单元的学习,还是很令人开心的。
今后课程的挑战会更多,我期望学习更多,收获更多。

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步