drf之序列化类
一、序列化类的常见字段类和常见参数
1.1常见的字段类
| 字段 | 字段构造方式 |
|---|---|
| BooleanField | BooleanField() |
| NullBooleanField | NullBooleanField() |
| CharField | CharField(max_length=None, min_length=None, allow_blank=False, trim_whitespace=True) |
| EmailField | EmailField(max_length=None, min_length=None, allow_blank=False) |
| RegexField | RegexField(regex, max_length=None, min_length=None, allow_blank=False) |
| SlugField | SlugField(maxlength=50, min_length=None, allow_blank=False) 正则字段,验证正则模式 [a-zA-Z0-9-]+ |
| URLField | URLField(max_length=200, min_length=None, allow_blank=False) |
| UUIDField | UUIDField(format=’hex_verbose’) format: 1) 'hex_verbose' 如"5ce0e9a5-5ffa-654b-cee0-1238041fb31a" 2) 'hex' 如 "5ce0e9a55ffa654bcee01238041fb31a" 3)'int' - 如: "123456789012312313134124512351145145114" 4)'urn' 如: "urn:uuid:5ce0e9a5-5ffa-654b-cee0-1238041fb31a" |
| IPAddressField | IPAddressField(protocol=’both’, unpack_ipv4=False, **options) |
| IntegerField | IntegerField(max_value=None, min_value=None) |
| FloatField | FloatField(max_value=None, min_value=None) |
| DecimalField | DecimalField(max_digits, decimal_places, coerce_to_string=None, max_value=None, min_value=None) max_digits: 最多位数 decimal_palces: 小数点位置 |
| DateTimeField | DateTimeField(format=api_settings.DATETIME_FORMAT, input_formats=None) |
| DateField | DateField(format=api_settings.DATE_FORMAT, input_formats=None) |
| TimeField | TimeField(format=api_settings.TIME_FORMAT, input_formats=None) |
| DurationField | DurationField() |
| ChoiceField | ChoiceField(choices) choices与Django的用法相同 |
| MultipleChoiceField | MultipleChoiceField(choices) |
| FileField | FileField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL) |
| ImageField | ImageField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL) |
| ListField | ListField(child=, min_length=None, max_length=None) |
| DictField | DictField(child=) |
# 这几个最常用 CharField BooleanField IntegerField DecimalField # 这两个是序列化列独有的 ListField: {name:'lqz',age:19,hobby:['篮球','足球']} # 可以以列表存储 DictField:{name:'lqz',age:19,wife:{'name':'jason','age':18}} # 可以以字典存储
1.2常见的参数
选项参数
| 参数名称 | 作用 |
|---|---|
| max_length | 最大长度 |
| min_lenght | 最小长度 |
| allow_blank | 是否允许为空 |
| trim_whitespace | 是否截断空白字符 |
| max_value | 最小值 |
| min_value | 最大值 |
# 给CharField字段使用的参数 max_length 最大长度 min_lenght 最小长度 allow_blank 是否允许为空 trim_whitespace 是否截断空白字符 # 给IntegerField字段类使用的参数 min_value 最小值 max_value 最大值
通用参数
| 参数名称 | 说明 |
|---|---|
| read_only | 表明该字段仅用于序列化输出,默认False |
| write_only | 表明该字段仅用于反序列化输入,默认False |
| required | 表明该字段在反序列化时必须输入,默认True |
| default | 反序列化时使用的默认值 |
| allow_null | 表明该字段是否允许传入None,默认False |
| validators | 该字段使用的验证器 |
| error_messages | 包含错误编号与错误信息的字典 |
| label | 用于HTML展示API页面时,显示的字段名称 |
| help_text | 用于HTML展示API页面时,显示的字段帮助提示信息 |
# 重点 read_only 表明该字段只能用于序列化输出给前端或其他 write_only 表明该字段只能用于反序列化输入
二、序列化类之source
# 该参数就是 修改序列化字段的名字 eg: # 现在我们编写了一个book表: class Book(models.Model): name = models.CharField(max_length=32) price = models.DecimalField(max_digits=5, decimal_places=2) publish_date = models.DateField() 然后我们编写一个获取图书的接口 需要用到序列化类 class BookSerializer(serializers.Serializer): name = serializers.CharField(min_length=3, max_length=8) price = serializers.CharField(min_length=3, max_length=8) publish = serializers.CharField(min_length=3, max_length=8) # 我们在使用序列化类 然后把书籍传到前端显示 接口 class BookView(APIView): def get(self, request): book_list = Book.objects.all() ser = BookSerializer(instance=book_list, many=True) return Response(ser.data) # 这个时候在前端的显示是这样的

# 序列化的字段名称写什么前端就会显示什么 现在如果我想要在前端的name字段这样显示: book_name 我们就可以使用source参数 class BookSerializer(serializers.Serializer): # name = serializers.CharField(min_length=3, max_length=8) book_name = serializers.CharField(min_length=3, max_length=8, source='name') # 字段名称写自己想要的 source后面跟上表的字段名称 # 这个时候就可以按照我们自己定义的字段名称显示

# source可以指定的是字段 也可以指定方法用于重命名 # source还可以跨表查询 eg: publish_name = serializers.CharField(min_length=3, max_length=8, source='publish.name') # 在前端直接显示出版社名称的时候可以使用跨表查询 在前端就会直接显示出版社的名称 xx = serializers.CharField(max_length=8, min_length=3,source='xx') #source的xx表示表模型中得方法

三、序列化类之定制序列化类的两种方式
就比如现在我想要在前端这样显示
{
"name": "西游记",
"price": 33,
"publish": {name:xx,city:xxx,email:sss}
}
# 显示出版社的具体信息按照我们上面的操作很难完成所以需要用到新的方 有两种方法可以实现
1. 在序列化类中写 SerializerMethodField
2.在模型类中写方法
1.序列化类中编写
# 直接在序列化类中编写SerializerMethodField 方法 class BookSerializer(serializers.Serializer): name = serializers.CharField(min_length=3, max_length=8) price = serializers.CharField(min_length=3, max_length=8) publish_date = serializers.DateField() publish = serializers.SerializerMethodField() # 写这个字段类的时候必须搭配下列方法 def get_publish(self, obj): # 方法名固定的(get_字段名) 该方法返回什么这个字段就是什么 # obj就是当前序列化的对象 就是视图类中所需要序列化的对象 return {'name': obj.publish.name, 'city': obj.publish.city, 'email': obj.publish.email} # 这个时候就可以返回出版社全部的信息了

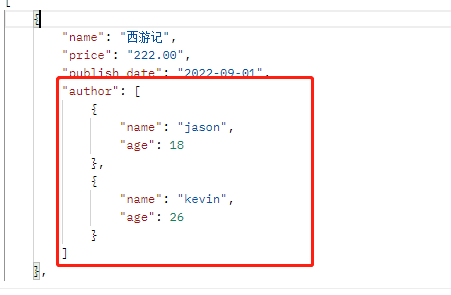
小练习:使用方法1在前端显示所有的作者信息
# 因为作者与书籍是多对多关系所以一本书会有多个作者 class BookSerializer(serializers.Serializer): name = serializers.CharField(min_length=3, max_length=8) price = serializers.CharField(min_length=3, max_length=8) publish_date = serializers.DateField() authors = serializers.SerializerMethodField() def get_author(self, obj): # 因为是多对多关系 所以要把所有的作者for循环出来 author_list = [] for author in obj.authors.all(): author_list.append({'name': author.name, 'age': author.age}) return author_list
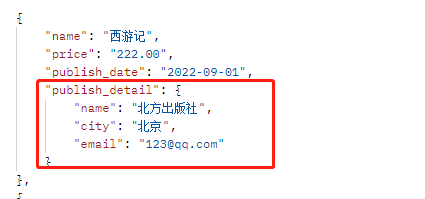
2.在模型类中写方法
# 直接在模型类中编写方法 class Book(models.Model): name = models.CharField(max_length=32) price = models.DecimalField(max_digits=5, decimal_places=2) publish_date = models.DateField() def publish_detail(self): # 方法名不要与字段名冲突 return {'name': self.publish.name, 'city': self.publish.city, 'email': self.publish.email} # 写好之后还要在序列化类中编写参数 class BookSerializer(serializers.Serializer): name = serializers.CharField(min_length=3, max_length=8) price = serializers.CharField(min_length=3, max_length=8) publish_date = serializers.DateField() publish_detail = serializers.DictField() # 按照模型类中的方法名显示到前端
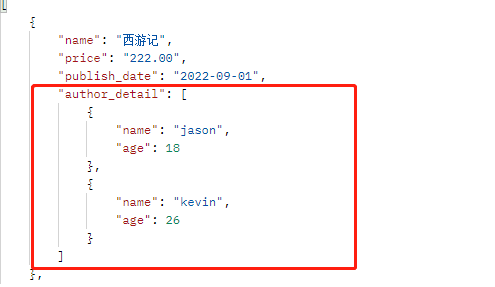
小练习:使用方法2在前端显示所有作者信息
class Book(models.Model): name = models.CharField(max_length=32) price = models.DecimalField(max_digits=5, decimal_places=2) publish_date = models.DateField() publish = models.ForeignKey(to='Publish', on_delete=models.CASCADE) authors = models.ManyToManyField(to='Author') def author_detail(self): # 因为书籍与作者是多对多关系所以需要for循环出来 author_list = [] for author in self.authors.all(): author_list.append({'name': author.name, 'age': author.age}) return author_list # 序列化类: class BookSerializer(serializers.Serializer): name = serializers.CharField(min_length=3, max_length=8) price = serializers.CharField(min_length=3, max_length=8) publish_date = serializers.DateField() author_detail = serializers.ListField() # 因为作者有多个所以用列表的形式会好点
3.有关联关系表的反序列化的保存
# 我们在序列化的时候想要在前端显示什么 那么我们就把表中的字段序列化即可 # 模型类 class Book(models.Model): name = models.CharField(max_length=32) price = models.DecimalField(max_digits=5, decimal_places=2) publish_date = models.DateField() publish = models.ForeignKey(to='Publish', on_delete=models.CASCADE) authors = models.ManyToManyField(to='Author') # 序列化类 class BookSerializer(serializers.Serializer): name = serializers.CharField(min_length=3, max_length=8) price = serializers.CharField(min_length=3, max_length=8) publish_date = serializers.DateField() publish_detail = serializers.DictField() author_detail = serializers.ListField() # 视图类 class BookView(APIView): def get(self, request): book_list = Book.objects.all() ser = BookSerializer(instance=book_list, many=True) return Response(ser.data)
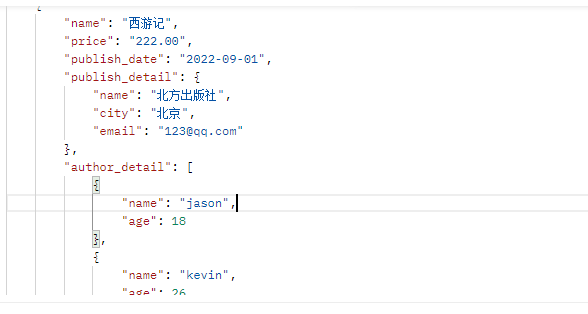
# 是能够把所有的字段序列化出来的 # 但是我们在保存数据的时候 会遇到外键字段 而外键字段基本都是按照id来保存的 # 我们在保存数据的时候 表中有什么字段 那么我们就需要传入什么字段(除了可以为空的字段不用传) 那么序列化的时候就需要序列化什么 所以我们需要在序列化字段额外加上两个字段 # 而且publish_detai和author_detail这两个字段都不是存储数字的 所以要额外加上两个字段 class BookSerializer(serializers.Serializer): name = serializers.CharField(min_length=3, max_length=8) price = serializers.CharField(min_length=3, max_length=8) publish_date = serializers.DateField() publish = serializers.CharField() authors = serializers.ListField() publish_detail = serializers.DictField() author_detail = serializers.ListField() # 然后我们就可以按照两个字段是序列化 两个字段是反序列化来区分 publish = serializers.CharField(write_only=True) authors = serializers.ListField(write_only=True) # 这两个字段就是在反序列化的时候需要传入数据 就是保存数据的时候 会反序列化 publish_detail = serializers.DictField(read_only=True) author_detail = serializers.ListField(read_only=True) # 这两个字段只有在序列化的时候需要传入数据
1.传入数据外键字段怎么写
# 外键字段只需要写外键id即可 # 如果是多对多关系 那么序列化是什么字段类型 就用什么字段类型传入
2.编写反序列化数据的保存的代码
# 视图类: class BookView(APIView): def post(self, request): ser = BookSerializer(data=request.data) if ser.is_valid(): ser.save() # 因为我们在继承的序列化类时Serializer 所以要重写create方法 return Response({'code': 100, 'msg': '保存成功'}) else: return Response({'code': 101, 'msg': ser.errors}) # 序列化类 class BookSerializer(serializers.Serializer): name = serializers.CharField(min_length=3, max_length=8) price = serializers.CharField(min_length=3, max_length=8) publish_date = serializers.DateField() publish = serializers.CharField(write_only=True) authors = serializers.ListField(write_only=True) publish_detail = serializers.DictField(read_only=True) author_detail = serializers.ListField(read_only=True) def create(self, validated_data): book = Book.objects.create(name=validated_data.get('name'), price=validated_data.get('price'), publish_date=validated_data.get('publish_date'), publish_id=validated_data.get('publish') ) authors = validated_data.get('authors') book.authors.add(*authors) return book
4.继承Serializer类的缺点
# 1.在序列化中需要编写每个字段 无论是序列化还是反序列化 # 2.如果是新增或是修改都需要 在序列化类中重新编写create和update方法 # 为了解决这些问题 我们可以继承 ModelSerializer 来序列化
四、模型类序列化器()的使用
# 序列化类 class BookModelSerializer(serializers.ModelSerializer): # ModelSerializer其实也是继承了Serializer class Meta: model = Book # 这里写需要序列化的表 fields = '__all__' # 这里写__all__就是序列化表中全部的字段 # 试图类 # 还是获取全部图书 class BookView(APIView): def get(self, request): book_list = Book.objects.all() ser = BookModelSerializer(instance=book_list, many=True) return Response(ser.data)

1.ModelSerialiser定制化字段
1.1 方式1
# 我们在使用ModelSerializer定制化字段的时候也是一样的写法 只不过需要一点改变 class BookModelSerializer(serializers.ModelSerializer): # ModelSerializer其实也是继承了Serializer class Meta: model = Book # 这里写需要序列化的表 fields = ['name', 'price', 'publish_date', 'publish', 'authors', 'publish_detail', 'author_list'] # 列表中有什么字段 就序列化什么字段 然后把我们定制的字段添加到列表中 # 方式一 publish_detail = serializers.SerializerMethodField() def get_publish_detail(self, obj): return {'name': obj.publish.name, 'city': obj.publish.city, 'email': obj.publish.email} author_list = serializers.SerializerMethodField() def get_author_list(self, obj): author_list = [] for author in obj.authors.all(): author_list.append({'name': author.name, 'age': author.age}) return author_list
1.2 方式2
# 模型类 class Book(models.Model): name = models.CharField(max_length=32) price = models.DecimalField(max_digits=5, decimal_places=2) publish_date = models.DateField() publish = models.ForeignKey(to='Publish', on_delete=models.CASCADE) authors = models.ManyToManyField(to='Author') def publish_detail(self): return {'name': self.publish.name, 'city': self.publish.city, 'email': self.publish.email} def author_list(self): author_list = [] for author in self.authors.all(): author_list.append({'name': author.name, 'age': author.age}) return author_list # 序列化类 class BookModelSerializer(serializers.ModelSerializer): # ModelSerializer其实也是继承了Serializer class Meta: model = Book # 这里写需要序列化的表 fields = ['name', 'price', 'publish_date', 'publish', 'authors', 'publish_detail', 'author_list'] # 列表中有什么字段就序列化什么字段 publish_detail = serializers.DictField() author_list = serializers.ListField() # 前端显示的也是一样的
1.3 方式1和方式2的前端显示
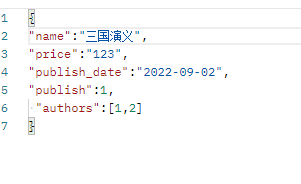
{ "name": "西游记", "price": "222.00", "publish_date": "2022-09-01", "publish": 1, "authors": [ 1, 2 ], "publish_detail": { "name": "北方出版社", "city": "北京", "email": "123@qq.com" }, "author_list": [ { "name": "jason", "age": 18 }, { "name": "kevin", "age": 26 } ] } # 这个时候我们可以看到 外键字段也序列化出去了 这样会有点难看 我们可以把这两个字段专门是反序列化的 然后定制字段的是序列化的
因为我们是用ModelSerializer来序列化的 所以我们在给外键字段添加参数的时候是不能直接写的 需要用到关键字段
class BookModelSerializer(serializers.ModelSerializer): # ModelSerializer其实也是继承了Serializer class Meta: model = Book # 这里写需要序列化的表 # fields = '__all__' # 这里写__all__就是序列化表中全部的字段 fields = ['name', 'price', 'publish_date', 'publish', 'authors', 'publish_detail', 'author_list'] # 列表中有什么字段就序列化什么字段 extra_kwargs = { 'publish': {'write_only': True}, 'authors': {'write_only': True}, # 这样就可以给表中的字段添加参数 两个外键字段都只是在反序列化的时候传入参数 不会序列化了 'name': {'max_length': 8} # 任意字段都可以都可以添加 如果不写默认用模型表中的参数 } publish_detail = serializers.DictField(read_only=True) author_list = serializers.ListField(read_only=True)
总结
'''任何使用''' # 1.定义一个类继承ModelSerializer # 2.类内部在写一个类 Meta(名字不能写错) # 3.在内部类中指定model(要序列化的表) # 4.在内部类中指定fields(要序列化的字段,写__all__包含全部字段,不包含方法,也可以写列表 列表中写一个一个字段) # 5.在内部类中指定extra_kwargs,给字段添加字段参数 # 6.在序列化类中可以重写某个字段,优先使用我们重写的字段 name = serializers.SerializerMethodField() def get_name(self, obj): return '爆款---' + obj.name # 就是在每本书前加上爆款 # 7.以后不需要重写create和update了 ModelSerializer写好了,兼容性更好,任意表都可以直接存
五、反序列化之数据校验
# 在我们保存数据的时候 数据肯定是要校验的 只有校验成功才能保存到数据库中 # 跟forms组件很像 1.有字段自己的校验 2.局部钩子 3.全局钩子
1.字段自己的校验
# 1.继承了Serializer的写法 class BookSerializer(serializers.Serializer): name = serializers.CharField(min_length=3, max_length=8, error_messages={'min_length': '书名最短三位', 'max_length': '书名最长8位'}) # 校验规则是一样的 # 2.继承了ModelSerializer的写法 class BookModelSerializer(serializers.ModelSerializer): # ModelSerializer其实也是继承了Serializer class Meta: model = Book # 这里写需要序列化的表 # fields = '__all__' # 这里写__all__就是序列化表中全部的字段 fields = ['name', 'price', 'publish_date', 'publish', 'authors', 'publish_detail', 'author_list'] # 列表中有什么字段就序列化什么字段 extra_kwargs = { 'publish': {'write_only': True}, 'authors': {'write_only': True}, 'name': {'max_length': 8, 'min_length': 3, 'error_messages': {'min_length': "书名最短三位"}}, } # 是使用extra_kwargs添加参数 但是校验规则也是一样的
2.局部钩子
# 继承了ModelSerializer和Serializer的写法是一样的 class BookModelSerializer(serializers.ModelSerializer): # ModelSerializer其实也是继承了Serializer def validate_name(self, name): if name == '三国演义': raise ValidationError('书名不能是三国演义') else: return name class BookModelSerializer(serializers.Serializer): def validate_name(self, name): if name == '三国演义': raise ValidationError('书名不能是三国演义') else: return name
3.全局钩子
# 继承了ModelSerializer和Serializer的用法是一样的 class BookModelSerializer(serializers.ModelSerializer): def validate(self, attrs): if attrs.get('name') == attrs.get('publish_date'): raise ValidationError('名字不能等于日期') else: return attrs class BookModelSerializer(serializers.Serializer): def validate(self, attrs): if attrs.get('name') == attrs.get('publish_date'): raise ValidationError('名字不能等于日期') else: return attrs
六、反序列化数据校验源码分析
# 入口:从哪开始看,哪个操作,执行了字段校验ser.is_valid() -BaseSerializer内的is_valid()方法 def is_valid(self, *, raise_exception=False): if not hasattr(self, '_validated_data'): # 判断我们写的序列化类中有没有_validated_data 方法 肯定没有写 所以走if分支 try: # 真正的走校验,如果成功,返回校验过后的数据 self._validated_data = self.run_validation(self.initial_data) except ValidationError as exc: return not bool(self._errors) -内部执行了:self.run_validation(self.initial_data)---》本质执行的Serializer的 -如果你按住ctrl键,鼠标点击,会从当前类中找run_validation,找不到会去父类找 -这不是代码的执行,代码执行要从头开始找,从自己身上再往上找 def run_validation(self, data=empty): #局部钩子的执行 value = self.to_internal_value(data) try: # 全局钩子的执行,从根上开始找着执行,优先执行自己定义的序列化类中得全局钩子 value = self.validate(value) except (ValidationError, DjangoValidationError) as exc: raise ValidationError(detail=as_serializer_error(exc)) return value -全局钩子看完了,局部钩子---》 self.to_internal_value---》从根上找----》本质执行的Serializer的 def to_internal_value(self, data): for field in fields: # fields:序列化类中所有的字段,for循环每次取一个字段对象 # 反射:去self:序列化类的对象中,反射 validate_字段名 的方法 validate_method = getattr(self, 'validate_' + field.field_name, None) try: # 这句话是字段自己的校验规则(最大最小长度) validated_value = field.run_validation(primitive_value) # 局部钩子 if validate_method is not None: validated_value = validate_method(validated_value) except ValidationError as exc: errors[field.field_name] = exc.detail return ret # 你自己写的序列化类---》继承了ModelSerializer---》继承了Serializer---》BaseSerializer---》Field

 浙公网安备 33010602011771号
浙公网安备 33010602011771号