本周内容回顾
本周内容
- 迭代器
- 异常捕获
- 生成器
- 模块
- 软件开发目录
- 常见的内置模块
常见的内置函数
1.abs()
# abs: 取绝对值 print(abs(-66)) # 66 print(abs(-77)) # 77 print(abs(55)) # 55
2.all()与any()
# all()与any都是判断容器中只有的数据值对应的布尔值 l1 = [11, 22, 33, 44] l2 = [11, 22, 33, 44, 0] l3 = [0, None, [], {}] print(all(l1)) # True print(all(l2)) # False print(all(l3)) # False # all() 所有的数据类型必须是True结果才会是True 有一个是False结果就是False print(any(l1)) # True print(any(l2)) # True print(any(l3)) # False # any() 所有的数据类型必须是False结果才会是False 有一个是True结果就是True
3.bin()、oct()、hex()
# bin() oct() hex()都是把其他进制数转换为各自的进制数 print(bin(10)) # 0b1010 print(oct(10)) # 0o12 print(hex(10)) # 0xa print(oct(0b1010)) # 0o12 print(oct(0xa)) # 0o12 # bin和hex也可以吧其他进制数转换为各自的进制数
4.int()
# int() 就是可以进行类型转换和进制转换 # 类型转换 res1 = '11' print(res1, type(res1)) # 11 <class 'str'> res2 = int(res1) print(res2, type(res2)) # 11 <class 'int'> # 将其他进制转换成十进制 print(int(0b1010)) # 10 print(int(0o12)) # 10 print(int(0xa)) # 10
5.bytes()
# bytes 类型转换 # 以前我们想对一个文本信息进行解码或则编码的时候我们需要关键字encode和decode res1 = '台湾是中国的一个省份'.encode('utf8') print(res1) # b'\xe5\x8f\xb0\xe6\xb9\xbe\xe6\x98\xaf\xe4\xb8\xad\xe5\x9b\xbd\xe7\x9a\x84\xe4\xb8\x80\xe4\xb8\xaa\xe7\x9c\x81\xe4\xbb\xbd' res2 = res1.decode('utf8') print(res2) # 台湾是中国的一个省份 ''' 之前我们有可能会把encode和decode搞混 现在我们是需要在文本信息前加上bytes即可 ''' res1 = bytes('台湾是中国的一个省份', 'utf8') print(res1) # b'\xe5\x8f\xb0\xe6\xb9\xbe\xe6\x98\xaf\xe4\xb8\xad\xe5\x9b\xbd\xe7\x9a\x84\xe4\xb8\x80\xe4\xb8\xaa\xe7\x9c\x81\xe4\xbb\xbd' res2 = str(res1, 'utf8') # 我们只需要通过str就可以转换成字符串 print(res2) # 台湾是中国的一个省份
6.callable()
# callable call在it行业中可以翻译为 调用>>>加括号执行 # 就是判断某个变量是否可以被调用 name = 'tony' def index(): print('from index') print(callable(index)) # True print(callable(name)) # False # 因为index已经被定义为函数名了 所以index加括号就可以被调用 index() # from index name() # 报错
7.chr()和ord()
# chr() ord() 根据ASCII码实现字符与数字的转换 # chr 将指定的数字根据ASCII码转换成字符 print(chr(65)) # A print(chr(66)) # B print(chr(97)) # a print(chr(100)) # b # ord 将指定的字符根据ASCII码转换成数字 print(ord('a')) # 97 print(ord('z')) # 122 print(ord('A')) # 65 print(ord('Z')) # 90
8.dir()
# dir 获取对象内部可以通过句点符获取的数据 print(dir(list)) # 会生成一个列表里面都是list的方法
9.divmod
# divmod 可以获取除法之后的整数和余数 print(100 / 7) # 14.285714285714286 print(divmod(100, 7)) # (14, 2) print(9 / 3) # 3.0 print(divmod(9, 3)) # (3, 0) print(55 / 3) # 18.333333333333332 print(divmod(55, 3)) # (18, 1) # 可以把整数和余数提取出来然后组织成元祖返回 ''' 这个时候我们就可以通过这些来计算一些问题: 比如: 现在我们手上有N个数据需要在网页上展示每页只能展示10条数据需要几个网页 总数据 每页展示 网页数 100 10 10 98 10 10 10145 10 ? 我们可以通过divmod求出网页数 ''' real_num, more = divmod(10145, 10) if more: real_num += 1 print(real_num) # 1015
10.enumerate
# enumerate 枚举 # 现在我们需要把列表一个一个取出来然后加上索引 l = ['jason', 'tony', 'kevin', 'jerry', 'oscar'] # 我们可以使用for循环 count = 0 for i in l: print(count, i) count += 1 ''' 0 jason 1 tony 2 kevin 3 jerry 4 oscar ''' # 现在我们可以使用enumerate方法快速生成 for i, j in enumerate(l): print(i, j) ''' 0 jason 1 tony 2 kevin 3 jerry 4 oscar ''' # enumerate还可以指定开始的数字 for i, j in enumerate(l, start=10): # 可以是任何数字 print(i, j) ''' 10 jason 11 tony 12 kevin 13 jerry 14 oscar '''
11.eval()和exec()
# eval()和exec()是检测字符串中的python语法并执行 res = 'print(123)' print(res) # print(123) 如果只是打印字符串的话是不会识别代码 eval(res) # 123 exec(res) # 123 # exec可以识别复杂的代码而eval只能识别最简单的代码 res1 = 'for i in range(10):print(i)' eval(res1) # 报错 exec(res1) ''' 0 1 2 3 4 5 6 7 8 9 '''
12.hash()
# hash()是把传入的值通过某种算法然后返回一串随机的数字(哈希值) print(hash('jason')) # -1221214690944433835 print(hash('123')) # -7390004770846579291 print(hash('tony')) # 1425372491557816673 print(hash(123)) print(6655) # 数字就是返回原来的数字
13.help()
# help() 就是查看帮助信息 def index(): 'index的注释' print('form index') help(index) # 会查看函数的名字和注释 ''' index() index的注释 ''' help(len) # 也可以查看内置函数 ''' len(obj, /) Return the number of items in a container. '''
14.isinstance()
# isinstance 判断某个数据值是否是某个数据类型 print(isinstance(11, int)) # True print(isinstance(12, float)) # False print(isinstance([11, 22], list)) # True print(isinstance([], int)) # False
15.pow()
# pow() 就是幂指数 print(pow(2, 3)) # 8 print(pow(2, 10)) # 1024 # 前面的值是被幂指数 后面的值就是幂指数
16.round()
''' round() 四舍五入 round(参数, 保留的位数) 如果被约的5前面是奇数就会进1 如果前面是偶数就会舍弃5 如果5后面有非0数字也会进1 round()默认保留一位小数 传入一个数时默认返回整数 ''' print(round(11.56, 2)) print(round(11.5)) # 12 print(round(12.5)) # 12 print(round(12.53)) # 13 print(round(10)) # 10
可迭代对象
迭代就是更新换代>>每次更新都需要基于上次的成果更新
代码演示:
# 不属于迭代 while True: print(1) # 属于迭代 for i in range(10): print(i)
1.可迭代对象的判断
内置有__iter__方法的都可以叫做可迭代对象
内置就是可以通过句点符能够直接点出来的方法
__xxx__ 针对双下划线开头和双下划线结尾的方法 统一叫做 双下xxx
int # 整型不是可迭代对象 float # 浮点型不是可迭代对象 str # 字符串是可迭代对象 list # 列表是可迭代对象 dict # 字典是可迭代对象 tuple # 元祖是可迭代对象 set # 集合是可迭代对象 bool # 布尔值不是可迭代对象 def index(): # 函数名不是可迭代对象 pass f = open(r'a.txt', 'r', encoding='utf8') # 文件名是可迭代对象 pass """ 可迭代对象 字符串 列表 字典 元组 集合 文件对象(本身就是迭代器对象) 不是可迭代对象 整型 浮点型 布尔值 函数名 可迭代对象能够支持for循环取值 """
迭代器对象
''' 迭代器对象给我们提供了一种不依赖于索引取值的方式 因为想列表这种是可以通过索引取值的 但是字典、集合这种是无序的不能通过索引取值 正是因为有迭代器对象的存在 我们才能对字典、集合这些无序类型循环取值 '''
1.如何判断是否是迭代器对象
内置中有__iter__和__next__方法的对象都称之为迭代器对象
2.可迭代对象和迭代器对象的关系
可迭代对象调用了__iter__方法之后就会变成迭代器对象
迭代器对象调用__iter__方法无论多少次都还是迭代器对象本身
3.迭代器对象迭代取值
res = 'jason'.__iter__() # 现在已经是迭代器对象了 print(res.__next__()) # j print(res.__next__()) # a print(res.__next__()) # s print(res.__next__()) # o print(res.__next__()) # n print(res.__next__()) # 报错 #每次取一个值取多了会报错 l = ['jason', 'tony', 'kevin', 'jerry', 'oscar'].__iter__() print(l.__next__()) # jason print(l.__next__()) # tony print(l.__next__()) # kevin print(l.__next__()) # jerry print(l.__next__()) # oscar print(l.__next__()) # 报错 列表也是一次取一个值 取多报错 d = {'name': 'tony', 'pwd': '123'}.__iter__() print(d.__next__()) # name print(d.__next__()) # pwd print(d.__next__()) # 报错 字典只有k参与 ''' 可迭代对象只有调用了__iter__方法才能称为迭代器对象 才能够取值 '''
4.迭代器的反复使用
# l = [1, 2, 3, 4, 5] print(l.__iter__().__next__()) # 1 print(l.__iter__().__next__()) # 1 print(l.__iter__().__next__()) # 1 print(l.__iter__().__next__()) # 1 print(l.__iter__().__next__()) # 1 # l.__iter__方法每次都是产生新的迭代器对象 l = [1, 2, 3, 4, 5] res = l.__iter__() print(res.__iter__().__next__()) # 1 print(res.__iter__().__next__()) # 2 print(res.__iter__().__next__()) # 3 print(res.__iter__().__next__()) # 4 print(res.__iter__().__next__()) # 5 # 列表l首先使用__iter__方法变成了迭代器对象然后赋值给res 所以每次都是一个迭代器对象
5.针对双下方法
''' res1 = __iter__ 可以简写为 iter(res1) res2 = __next__可以简写为next(res2) '''
6.可迭代对象的特殊
可迭代对象 迭代器对象 通过打印操作无法直接看出内部数据的情况
这个时候就能够节省内存
取值的时候一个一个取 不会直接产生一个内存空间里面存放多个值
for循环的本质
for循环的本质其实就是循环可迭代对象
语法结构:
for 变量名 in 可迭代对象: for循环代码 ''' 1.for循环每次执行时都会自动将in后面的数据调用__iter__方法变成迭代器对象 2.之后每次取值都调用__next__方法取值 3.最后没有值__next__()就会报错,但是for循环可以自动处理改错误 让循环正常结束 '''
异常捕获
1.首先我们要了解什么是异常
程序在运行过程中如果出现了异常就会导致整个程序结束
而异常就是程序员空中所说的 bug
2.异常的结构
就是但我们的程序出bug时会出现什么
# 在整个py文件下面会出现多行红色的英文 Traceback (most recent call last): File "D:/MYpycharm/day18/yield.py", line 14, in <module> name NameError: name 'name' is not defined ''' 当出现bug时我们是有查看顺序的 ''' # 1.首先我们要看最后一行 name 'name' is not defined 有时候如果很简单的错误一看就知道是什么错误了 # 2.第二看关键字line, 它能精准的找到代码是哪行出错了, 鼠标点击链接就会跳转到bug处 # 3.第三看错误类型 就是最后一行冒号得到左侧的信息(NameError)他能告诉你是什么错误信息
3.异常的类型
异常的类型就是看错误的最后一行冒号左侧的名字
异常的类型有很多种:
NameError : 变量名错误
IndexError : 索引错误
KeyError : 字典key错误
SyntaxError : 语法错误
TypeError : 类型错误
......
4.异常的分类
异常分为两大类
1.语法错误
# 语法错误一旦出现就要立刻修改 在代码中不能出现 eg: if # if 后面什么也没有写的 while # while 后面也什么没有写的 .......
2.逻辑错误
# 逻辑错误是可以被允许的 出现修改即可 eg: l = [1, 2] print(l[10]) # 索引超出范围 修改即可 d = {'name': 'tony'} print(d['pwd']) # 字典中没有该键 修改即可
异常捕获的演练
1.什么时候我们需要编写代码处理异常
当我们不确定代码哪时候会报错的时候我们就需要编写代码提前写好措施
2.代码演示
2.1基本的语法结构
可以针对把不同的异常类型做出不同的措施
# 语法结构 try: 检测的代码 except 错误类型: 对应错误类型的解决措施 # except可以写多个 try: name l = [1, 2] print(l[10]) except NameError: print('根据NameError做出的措施') # 根据NameError做出的措施 except IndexError: print('根据IndexError做出的措施') # 根据IndexError做出的措施
还可以在错误类型后面加上as e
可以知道具体错误信息
try: name l = [1, 2] print(l[10]) d = {'name': 'tony'} print(d['pwd']) except NameError as e: print('根据NameError做出的措施') # 根据NameError做出的措施 print(e) # name 'name' is not defined except IndexError as e: print('根据IndexError做出的措施') # 根据IndexError做出的措施 print(e) # list index out of range except KeyError as e: print('根据KeyError做出的措施') # 根据KeyError做出的措施 print(e) # 'pwd' ''' e 就是具体的错误信息 '''
2.2 万能异常
就是比较笼统的处理方式
可以把所有的错误方式都可以捕获
try: # name l = [1, 2] print(l[10]) except Exception as e: print('针对都有的错误做出得到措施') # 针对都有的错误做出得到措施 print(e) # list index out of range ''' 这个语法不管是什么错误都可以捕捉并返回 '''
2.3 异常捕获的补充
2.3.1 try与else和finally的用法
try: # name l = [1, 2] print(l[10]) except Exception as e: print('针对都有的错误做出得到措施') # 针对都有的错误做出得到措施 print(e) # list index out of range else: print('try检测代码没有出错的情况下 才会执行else的子代码') finally: print('try检测代码不管有没有错误都会执行finally的子代码') ''' else就是当try检测的代码如果没有出错的情况下 就会执行else的子代码 如果出错了就会跳过else的子代码 finally就是当try检测的代码不管有没有错误 都会执行finally的子代码 '''
2.3.2 断言
name = 'tony' assert isinstance(name, list) # 就是判断获取的变量名是什么类型跳过不是第二个参数类型就会直接报错 print('name使用了列表的相关操作') # 如果是第二个参数的类型才会执行该行代码
2.3.4 主动抛异常
就是当我们输入了xxx我们检测就会报错
name = input('请输入名字>>>:').strip() if name == 'tony': raise NameError('就是不让tony正常') # raise Exception('是tony 就会报错') else: print('不是tony就不会报错') ''' 可以使用针对性的异常类型 也可以使用万能异常捕获 请输入名字>>>:tony Traceback (most recent call last): File "D:/MYpycharm/day18/yield.py", line 19, in <module> raise NameError('就是不让tony正常') NameError: 就是不让tony正常 '''
5.注意
捕获异常能少用就少用
被try检测的代码能少则少
实际代码的演练
l = [1, 2, 3, 4, 5, 6, 7] # 如何使用while循环模拟for循环取值 res = l.__iter__() while True: print(res.__next__()) ''' 如果就这样写的话当列表中值被取完的时候肯定会报错的 1 2 3 4 5 6 7 Traceback (most recent call last): File "D:/MYpycharm/day18/yield.py", line 16, in <module> print(res.__next__()) StopIteration 我们要加上异常捕获 ''' l = [1, 2, 3, 4, 5, 6, 7] # 如何使用while循环模拟for循环取值 res = l.__iter__() while True: try: print(res.__next__()) except Exception: print('值取完了 还想要你个死鬼') break ''' 这样就会正常结束不会报错 1 2 3 4 5 6 7 值取完了 还想要你个死鬼 '''
生成器对象
1.生成器对象的本质
其实就是迭代器对象
只不过迭代器对象是python解释器自带的
而生成器是我们自己手写的(手写不觉的很有成就感嘛)
写完之后内置方法里肯定有 双下iter和双下next方法的 __iter__ 和__next__
2.学习生成器的目的
学习生成器的目的就是为了能够很好的优化代码
一种可以不依赖于索引取值的通用取值方法
可以节省数据类型的内存占用空间
3.代码演示
如果需要自己手写生成器那么我们需要一个关键字yield
3.1 yield关键字
def index(): print('你猜我怎么执行') yield index() ''' 调用index时是不会执行函数体代码的 因为函数体代码中有yield关键字 如果函数名加括号调用的话是不执行函数体代码的 而是会由普通的函数变成迭代器对象(生成器) 而调用迭代器对象需要使用__next__方法才能取到值 而且在函数中可以编写多个yield 并且yield还可以传返回值 ''' def index(): print('你猜我怎么执行') yield 11 print('第二次执行') yield 22 print('第三次执行') yield 33 print('第四次执行') yield 44 print(index().__next__()) print(index().__next__()) print(index().__next__()) print(index().__next__()) ''' 这个不管执行多少次都都是在执行迭代器对象的本身 因为从始至终都只产生一个 你猜我怎么执行 11 你猜我怎么执行 11 你猜我怎么执行 11 你猜我怎么执行 11 ''' def index(): print('你猜我怎么执行') yield 11 print('第二次执行') yield 22 print('第三次执行') yield 33 print('第四次执行') yield 44 res = index() print(res.__next__()) print(res.__next__()) print(res.__next__()) print(res.__next__()) ''' yield就是执行函数体代码时遇到第一个yield会暂停函数到yield后面 再次调用__next__的时候就会继续执行后续代码直到遇到第二个yield又会暂停到yield后面 再次调用__next__就又会继续执行 直到遇到最后一个 最后一个还要还要调用的话 就会报错 你猜我怎么执行 11 第二次执行 22 第三次执行 33 第四次执行 44 yield后面可以写返回值写啥返回啥 如果是多个数据就会组织成元祖返回 '''
3.2利用yield编写range
这样我们就可以yield编写一个类型range的迭代器
def my_range(start_num, end_num=None): if not end_num: end_num = start_num start_num = 0 while start_num < end_num: yield start_num start_num += 1 for i in my_range(1, 10): print(i) ''' 1 2 3 4 5 6 7 8 9 ''' # 因为真正的range是有第三个参数的所以我们还要写入第三个形参 def my_range(start_num, end_num=None, temp=1): # 因为真正的range的第三个参数如果是负数的话是不会执行的所以直接使用return结束即可 # 真正的range的第三个参数也不能为0 我们自己用print代替即可 if temp == 0: print('temp不能为0') return if temp < 0: return if not end_num: end_num = start_num start_num = 0 while start_num < end_num: yield start_num start_num += temp for i in my_range(1, 10, 0): print(i) # temp不能为0 for i in my_range(1, 10, 2): print(i) ''' 1 3 5 7 9 '''
3.3yield的其他用法
def func(name, food=None): print(f'{name}准备干饭了') while True: food = yield print(f'{name}准备吃{food}') res = func('tony') res.__next__() res.__next__() res.__next__() ''' tony准备干饭了 tony准备吃None tony准备吃None 我们可以发现food没有参数这个时候我们可以使用seed关键字传入参数 ''' def func(name, food=None): print(f'{name}准备干饭了') while True: food = yield print(f'{name}准备吃{food}') res = func('tony') res.__next__() res.send('鲍鱼') res.send('腰子') ''' tony准备干饭了 tony准备吃鲍鱼 tony准备吃腰子 seed可以自动调用__next__方法 就可以传值了 '''
生成器表达式
# 其实就是之前所说的列表生成式很像 # 列表生成式 res = [i for i in range(10) if i > 2] print(res) # [3, 4, 5, 6, 7, 8, 9] # 生成器表达式 res = (i for i in range(10) if i < 7) print(res) # <generator object <genexpr> at 0x000002394EBF2C50> # 其实就是迭代器对象 只要调用__next__方法取值即可 print(res.__next__()) print(res.__next__()) print(res.__next__()) print(res.__next__()) print(res.__next__()) print(res.__next__()) print(res.__next__()) ''' 0 1 2 3 4 5 6 其实就是迭代器 只不过能够简便代码 节省内存空间取多了也是会报错的 '''
迭代取值与索引取值的差异
# 其实两者各有各的有点各有各的缺点主要用于不同的场景 # 索引取值 l1 = [1, 2, 3, 4, 5, 6] print(l1[0]) print(l1[1]) print(l1[2]) print(l1[3]) print(l1[4]) print(l1[5]) res = l1.__iter__() print(res.__next__()) print(res.__next__()) print(res.__next__()) print(res.__next__()) print(res.__next__()) print(res.__next__()) ''' 其实两者的结果都为 1 2 3 4 5 6 ''' l1 = [1, 2, 3, 4, 5, 6] print(l1[0]) print(l1[0]) print(l1[3]) print(l1[3]) # 但是索引取值可以随意反复的取值 # 这还是迭代取值所做不到的 ''' 索引取值: 优势: 可以随意反复的获取容器中任意数据 劣势: 针对无序容器的类型无法取值 迭代取值: 优势: 提供了一种通用的取值方式 劣势: 一旦开始取值就只能往前取值不能往后取值 '''
模块的简介
1.模块
我们可以把模块可以理解为是一系列功能的集合体
我们调用模块就可以使用集合体中得所有功能
ps:使用模块编程就是站在巨人的肩膀上
2.模块的分类
1.内置模块
解释器自带的,直接可以使用的模块
就比如我们之前使用过的time模块
import time print(time.time()) # 调用time模块, 我们就可以使用time模块中所有的功能
2.自定义模块
需要自己编写
比如我们之前编写号的注册和登入功能
我们可以在其他py文件调用这个注册和登入功能了
3.第三方模块
就是一些大佬编写好的模块然后放到网上给其他人用
使用的时候我们需要提前下载才能能使用
python之所以牛掰就是因为支持python的模块非常的多 非常的全 非常的好用
所以我们以后拿到一个项目的时候我不着急编写先想想看有没有相应的模块可以实现功能需求
3.模块的表现形式
1.py文件(一个py文件可以看成是一个模块)
2.含有多个py文件的文件夹(按照模块功能不同的划分不同的文件夹存储)
3.已被编译为共享库或DLL的c或C++扩展
4.使用C编写并链接到python解释器的内置模块
导入模块的两种方式
注意:
以后项目中的所有py文件的名称都是英文 没有所谓的中文与编号(毕竟python解释器是老外发明的嘛 理解理解)
如果出现中文与编号 那么我们想要导入这个py文件下的功能时就会导入不了
命名一定要是英文
eg:
01 模块.py (错误的)
text01.py (正确的)
py文件在被当做模块导入时不需要考虑后缀
第一种导入方式
1.语法结构:
import 模块名
就比如现在我在pycharm中创建了两个py文件
一个叫 md.py 一个叫 start.py
# 现在在md.py中有一下功能 print('我是来自md.py文件中') name = 'tony' def func(): print('from md.py func') def func1(): print(name) def func2(): global name name = 'kevin'
我们就可以在start.py文件中导入md.py文件
# 现在在start.py中 import md print(md.name) # tony md.func() ''' from md.py func tony ''' md.func1() ''' form md.py func1 from md.py func tony ''' name = 'jason' md.func2() print(name) # jason 名字是不会被修改的 因为md中func2修改name的名字修改的是md名称空间中的name print(md.name) # kevin 改变的是md中的name
主意:在同一个执行文件中反复的导入同一个模块 导入语句只会执行一次
import md # 正常导入 import md # 无效导入 import md # 无效导入
第二种导入方式
1.语法结构
from ... import ....
这种导入方式可以直接使用模块中某个功能
现在还是按照上面两个文件演示:
# 在start文件中 from md import name # 这就可以使用md模块中的name print(name) # tony name = 'jason' print(name) ''' 直接结果为:jason 这个时候机会直接改变name的数据值 因为现在这个时候会在start产生一个name然后指向md.py中的name内存地址 但我们重新赋值时就会让原先的name解除绑定然后在与'jason'绑定 ''' print(func) # 报错 现在这个时候start中就不会有func的mz print(md.func()) # 报错 这个时候就不能使用md.的形式调用
1.创建执行文件的名称空间
2.创建杯被导入文件的名称空间
3.执行被导入的文件的代码, 并把产生的所有名字都存到被导入的名称空间当中
4.在执行文件中获取指定的名字 指向被导入文件的名称空间
两种导入的优缺点
import的导入
1.优点:
可以通过md点的方式使用到模块中所有的名字并且不会冲突
2.缺点:
什么都可以导入,但是有时候作者并不想把所有的功能都给你使用
form...import...
1.优点
可以准确的找到我们需要使用的功能 不需要加模块名前缀
2.缺点
名字会与执行文件冲突(绑定关系容易被修改)
模块名字的主要事项
# 1.起别名 # 1.有时候会有多个作者起的名字会一样而我们有时候都想用到的时候我们就可以把其中的名字给修改掉即可 from md import name as md_name from md1 import name as md1_name # 我们可以通过关键字as把我们是需要的名字给修改掉 # 2.原有的模块名太复杂或太长 import user_interface as user # 我们也是通过as修改 # 2.导入多个模块名 import os,json,sys # 上述导入方式尽量导入的时候模块功能相似的时候才这样写 如果不是尽量分开写 import os import json import sys # 尽量这样写 from md import name, func,func1,func2 # 上述导入方式推荐使用 因为多个名字都是来自同一个模块 功能相似 # 名字与名字之间逗号隔开 # 3.全导入 # 需求:需要使用模块名称空间中多个名字,必须是from...import...导入 from md import * ''' 我们可以使用*号顶替 我们就可以在执行文件中使用md中所有的名字 *号还可以控制执行文件导入的数量的多少 我们可以在模块文件中写入__all__=['功能名称'] 控制*能够获取的名字 只有在列表中才能够被调用 '''
循环导入
循环导入就是两个py文件互相导入
循环导入很容易出现报错
就是需要另一个文件中的名字时很有可能还没有被定义没有准备好被调用, 就会报错
如何解决呢?
就是在一个文件中需要名字时另一个文件在import上面就先定义好即可
循环导入一定要尽量避免出现 , 如果避免不了就先在导入前定义好名字
文件的判断
当以后我们写项目时,一个项目中的文件会有很多个那么怎么判断它们是哪个文件呢
所有的py文件中都有一个__name_内置名
当py文件是执行文件的时候__name__的结果是__main__
当py文件时被导入文件的时候__name__的结果是模块名
__name__主要用于开发模块的作者测试自己的代码使用
if __name__ == __main__:
所有功能名字
只有是执行文件的时候才会执行if语句
一般只出现在整个文件中的启动文件
模块名字的查找顺序
1.查找顺序
1.统一先在内存中查找
2.然后再内置模块中查找
3.最后在sys.path中查找(程序系统的环境变量)
2.sys.path
1.导入一个文件 然后在运行过程中删除 发现还可以使用
import md import time time.sleep(15) print(md.name) ''' 当我们运行过程中删除md.py文件是不会报错的因为当我们执行的时候import已经运行过了就会把md文件暂存到了内存中所以还是能够找到md中的名字 但是如果再次运行就会报错了 '''
2.创建一个跟内置模块名相同的名字
import time print(time.time()) # 会获得一个时间戳 from time import name print(name) # 会报错因为time中没有name名字 ''' 这个时候我们就可以得知名字的查找顺序是先从内存中找然后在从内置中查找 就算自己编写了一个time.py文件也是先从内置中查找所以器模块名时尽量不要跟内置模块名冲突 '''
3.sys.path中查找
首先我们要知道导入模块时谁是执行文件
所有的路径都是参考执行文件来的
import sys print(sys.path) ''' [ 'D:\\MYpycharm\\day19', 'D:\\MYpycharm\\day19', 'D:\\PyCharm 2022.1.2\\plugins\\python\\helpers\\pycharm_display', 'D:\\python3.6\\python36.zip', 'D:\\python3.6\\DLLs', 'D:\\python3.6\\lib', 'D:\\python3.6', 'D:\\python3.6\\lib\\site-packages', 'D:\\PyCharm 2022.1.2\\plugins\\python\\helpers\\pycharm_matplotlib_backend' ] 我们会发现sys.path中的所有路径都是在一个列表中的只要模块名的路径在里面那么我们就可以调用这个模块 '''
如果想要调用的模块内存中没有内置模块也没有那么我们可以先把模块名的绝对路径添加到sys.path中就行了
因为sys.path中是一个列表所以我们只要在列表末尾添加即可
sys.path.append(模块名的路径)
# 在start文件同级别中创建一个xxx文件夹,该文件夹中有add.py文件 name = 'jason'
# 在start文件中 import sys # 添加不同级别的py文件 sys.path.append(r'D:\MYpycharm\day19\xxx') # py文件不需要添加 import add # 虽然add会飘红但是不影响程序运行 print(add.name) # jason
还有from...import...也可以从文件夹中导入模块名
from xxx import add print(add.name) # jason # 这个时候就不需要添加sys.path路径中了
如果文件夹下还有文件夹我也可以添加
from xxx.aaa.bbb.user import name print(name) # tony # 可以在文件夹后面是有点继续添加文件夹
绝对导入与相对导入
1.绝对导入
不管是绝对导入还是相对导入只要涉及到导入都是要看执行文件在哪
绝对导入就是以执行文件所在的sys.path为起始路径,往下一层一层的找
# 现在这个是执行文件 文件夹名字为xxx 模块名是 a.py ''' 如果导入的模块文件路径于执行文件的路径不在一个文件夹下 我们想要导入这个文件有两种方法 可以把导入的模块路径加入sys.path中 也可以使用from import ''' from xxx import a # 这个就是绝对导入
如果是多个文件夹下也可以使用from import语句
# 现在有个文件夹里面还有还套着两个文件夹最后一个文件夹中有模块名为a.py # 我们也可以使用from import语句 from aaa.bbb.ccc import a # 我们就可以使用a中的所有的功能了
如果一个文件夹下有两个模块文件 执行文件不在这个文件夹下
# a模块 print('from a') from xxx import b ############################## # b模块 print('from b') ############################## # 执行文件 import a # 绝对导入要看执行文件所在的路径在哪 我们要把绝对路径给找到才行
由于pycharm会把我们把项目的根目录自动添加到sys.path中
所以查找模块肯定不会报错的方法就是永远从根目录开始往下一层一层的找
但是如果其他人不是用pycharm运行代码的话那么我们就需要自己手动把
项目的根目录添加到sys.path中(会有一个模块会帮我们自动获取根目录>>>os模块)
相对导入
关于了解相对导入之前我们要知道一个小知识
. 在路径中的意思是当前路径
.. 在路径中的意思是上一层路径
../.. 在路径中的意思是上上层路径
相对导入其实是在模块与模块之间导入的,
因为一个执行文件可以有多个模块文件而如果模块中导入其他模块的话
也可以相对导入
当文件夹下有两个模块名并且其中一个模块要导入b模块
# a模块 print('from a') from . import b # 按照 . 的形式找到a的当前文件路径就可以找到b文件前提是(b和a是在同一个文件夹下) ############################## # b模块 print('from b') ############################## # 执行文件 import a # 这样是可以让b导入到a中的而且还不报错
相对导入可以不用参考执行文件所在路径 直接以当前模块文件路径为准
1.相对导入只能在模块文件中使用, 执行文件不能使用相对导入
2.相对导入如果实在项目比较复杂的情况下 可能会出错
所以相对导入尽量少用 推荐使用绝对导入
包的概念
1.如何理解包
1.专业的角度:
就是一个文件夹中有__init__.py文件夹
2.直观的角度:
就是一个文件夹里面有许多个py文件
2.包的作用
包的作用我们可以理解为一个文件夹中存放了多个py文件(模块文件)
仅仅是为了方便管理模块文件
3.具体使用
包名也是需要用英文这样才能被import使用
可以直接:
import 包名
导入一个包名其实导入的是__init__文件夹,里面有什么功能你才能使用什么
但是我们也可以跳过__init__文件夹,直接使用包里的其他模块
from 包名 import 模块名
其实现再在python3解释器中文件夹中有没有__init__文件夹其实已经不重要了
一个文件夹都可以是一个包 但是为什么还需要在包中写上__init__文件夹名称呢?
那是因为在python2中 包中必须有__init__文件夹 没有的话我们是用不了里面的模块的
所以为了兼容python2我们在创建包时还是需要在包中写上__init__文件夹(pycharm会帮我们自动创建)
编程思想的转变
现在我们在编写代码的时候其实已经经历了三个阶段:
1.小白阶段
就是在叠堆代码一行一行代码的写下来 单个文件夹
2.函数阶段
将代码按照需求的不同封装成不同的函数 单个文件夹
3.模块阶段
根据功能的不同拆分为不同的模块文件 多个文件夹
小白阶段就像把一堆文件都放到c盘中也不分类
函数阶段就像把一推文件都放到c盘中并且分类
而模块阶段就是按照文件的不同功能放到不同的盘
就是为了我们可以方便快捷高效的管理文件
软件开发目录的规范
根据上面的三个阶段 分模块文件多了之后还需要有文件夹
我们所使用的所有程序目录都是有一定的规范的(就是用多个文件夹存放多个不同功能的py文件)
python项目目录中有:
1.bin文件夹
里面是存储程序的启动文件 eg: start.py
2.conf文件夹
里面是存储程序的配置文件 eg: settings.py
3.core文件夹
里面是存储程序的核心逻辑 eg: src.py
4.lib文件夹
里面是存储程序的共同功能文件 eg: common.py
5.db文件夹
里面是存储程序的数据文件 eg: userinfo.txt
6.interface文件夹
里面式存储程序的接口文件 eg: user.py
7.log文件夹
里面是存储程序的日志文件 eg:log.log
8.readme文件(文本文件)
里面是存储一些程序的说明、介绍、广告 类似于产品的说明书
9.requirements.txt文件
里面是存储程序所需要的第三方模块名称与版本
我们编写软件项目的时候 可以不完全遵守上面的规范
启动文件可以不用放在bin文件夹中 直接放在项目根目录下
db文件夹可以被以后的数据库替代
log文件夹可以被以后专门日志服务替代
内置模块就是python解释器已经编写好的我们可以直接使用它的功能非常的方便
collectinos模块
我们之前学基本数据类型只有八大类(整型、浮点型、字符串、列表、字典、元祖、集合、布尔值)
现在collectinons模块又为我们提供了更多的数据类型
1.1 namedtuple(具名元祖)
from collections import namedtuple point = namedtuple('坐标', ['x', 'y']) res1 = point(11, 22) res2 = point(55, 66) print(res1, res2) # 坐标(x=11, y=22) 坐标(x=55, y=66) # 也可以不用列表直接使用字符串还可以传三个参数 point = namedtuple('坐标', 'x y z') res1 = point(11, 22, 33) res2 = point(55, 66, 77) print(res1, res2) # 坐标(x=11, y=22, z=33) 坐标(x=55, y=66, z=77)
1.2 deque(双端队列)
我们之前所说的队列就是存放数据的时候 先进先出
而双端队列就是可以两边都可以进
from collections import deque q = deque() q.append(11) q.append(22) q.append(33) q.append(44) print(q) # deque([11, 22, 33, 44]) # 我们还可以在q的左边添加数据值 q.appendleft(555) print(q) # deque([555, 11, 22, 33, 44])
1.3 OrderedDict(有序字典)
我们之前所了解的字典都是无序的而现在给我们提供了一个有序字典
from collections import OrderedDict d = dict([('a', 1), ('b', 2), ('c', 3)]) print(d) # {'a': 1, 'c': 3, 'b': 2} 是无序的 但是我们可以把它变成有序的 d1 = OrderedDict([('a', 1), ('b', 2), ('c', 3)]) print(d1) # OrderedDict([('a', 1), ('b', 2), ('c', 3)]) # 注意,OrderedDict的Key会按照插入的顺序排列,不是Key本身排序
1.4 defaultdict
# 快速生成字典 d = defaultdict(k1=[], k2=[]) print(d) # defaultdict(None, {'k1': [], 'k2': []})
1.5 Counter(计数器)
from collections import Counter # 现在有一个很乱的字符串 现在要计算里面每个字符的个数 # 组织成 {'字符':个数, '字符2':个数} s = 'dahujdhawuiohdio' # 最开始我们可以使用for循环解决 d = {} for i in s: if i in d: d[i] += 1 else: d[i] = 1 print(d) # {'d': 3, 'a': 2, 'h': 3, 'u': 2, 'j': 1, 'w': 1, 'i': 2, 'o': 2} # 不过我们现在可以使用计数器来计算 s = 'dahujdhawuiohdio' res = Counter(s) print(res) # Counter({'d': 3, 'h': 3, 'a': 2, 'u': 2, 'i': 2, 'o': 2, 'j': 1, 'w': 1}) # 这样会方便许多# 只要是能够被for循环的都可以当做参数传入Counter然后计算
time模块
时间的三种模式
1.时间戳 time.time()
2.结构化时间 time.gmtime()
3.格式化时间 time.strftime()
1.1 时间戳
就是从1970年0时0分0秒开始到现在总共多少秒了, 运行print(time.time()) 返回的是float类型
1.2结构化时间
就是计算机看的懂的时间有九大元素
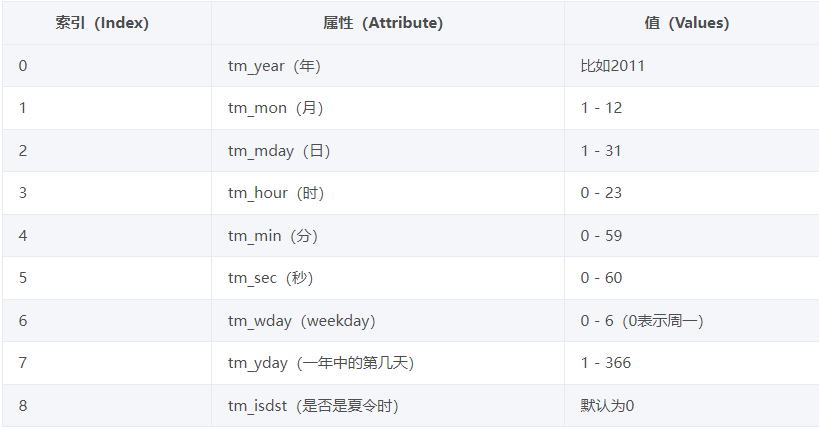
1.3 格式化时间
就是人类看的舒服的时间 2022-07-14 17:08:36
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(0-12)
%M 分钟数(0-59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示(e.g Thu Dec 10 09:54:27 2020)
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示(e.g 12/10/20)
%X 本地相应的时间表示(e.g 09:58:15)
%Z 当前时区的名称(e.g 中国标准时间)
%% %号本身
其中最主要的就是 %Y %m %d %H %M %S %X
import time print(time.time()) # 1657789972.6291883 print(time.gmtime()) # time.struct_time(tm_year=2022, tm_mon=7, tm_mday=14, tm_hour=9, tm_min=12, tm_sec=13, tm_wday=3, tm_yday=195, tm_isdst=0) print(time.strftime('%Y-%m-%d %H:%M:%S')) # 2022-07-14 17:12:13 print(time.strftime('%Y-%m-%d %X')) # 2022-07-14 17:12:13 # 时间获取的是当前运行文件时的时间
1.4 三者的互相转换
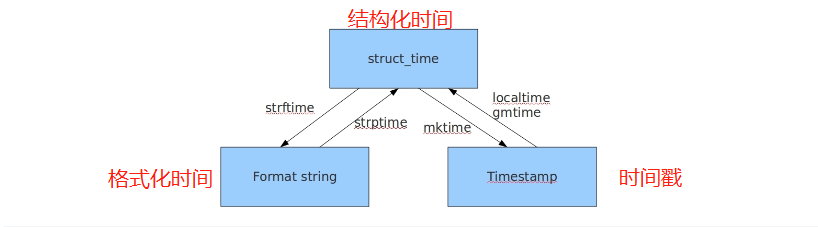
1.4.1 时间戳转结构化时间
1 # time.gmtime(时间戳) # UTC时间 与英国伦敦当地时间一致 2 # time.localtime(时间戳) # 当地时间例如我们现在在北京执行这个方法:与UTC时间相差8小时 UTC时间+8小时 = 北京时间 3 print(time.gmtime(1657789972)) 4 # time.struct_time(tm_year=2022, tm_mon=7, tm_mday=14, tm_hour=9, tm_min=12, tm_sec=52, tm_wday=3, tm_yday=195, tm_isdst=0) 5 print(time.localtime(1657789972)) 6 # time.struct_time(tm_year=2022, tm_mon=7, tm_mday=14, tm_hour=17, tm_min=12, tm_sec=52, tm_wday=3, tm_yday=195, tm_isdst=0)
1.4.2 结构化时间转时间戳
1 # 结构化时间转时间戳 2 # time.mktime(结构化时间) 3 time_tuple = time.localtime(1657789972) 4 print(time.mktime(time_tuple)) # 1657789972.0
1.4.3 格式化时间转结构化时间
1 print(time.strptime('2022-07-14 17:12:13', '%Y-%m-%d %H:%M:%S')) 2 time.struct_time(tm_year=2022, tm_mon=7, tm_mday=14, tm_hour=17, tm_min=12, tm_sec=13, tm_wday=3, tm_yday=195, tm_isdst=-1)
1.4.4 结构化时间转格式化时间
print(time.strftime('%Y-%m-%d %X')) # 2022-07-14 17:22:07 print(time.strftime("%Y-%m-%d", time.localtime(1657789972))) # 2022-07-14
datetime模块
与时间模块一样都是对时间继续相关操作
datetime模块里最主要的两个功能就是datetime.tody和date.tody
1 import datetime 2 3 res = datetime.datetime.today() 4 print(res) # 2022-07-15 17:11:55.376975 可以把描述精确到六位 5 6 res1 = datetime.date.today() 7 print(res1) # 2022-07-15 这个只显示年月份 # 还可以单独拿时间的关键字 print(res.year) # 2022 print(res.month) # 7 print(res.weekday()) # 4 print(res.isoweekday()) # 5 8 ''' 9 如果中间的英文是date 那么显示的就是年月日 10 如果中间的英文是datetime 那么显示的就是年月日 时分秒 11 '''
timedelta()
时间差值 给他一个参数就可以有一个时间数
import datetime res1 = datetime.date.today() res2 = datetime.timedelta(days=3) print(res1) # 2022-07-15 print(res1 + res2) # 2022-07-18 ''' 他还有很多单位: days, seconds, microseconds, milliseconds, minutes, hours, weeks 如果是其他的单位可以通过换算来达到 ''' 补充知识 : import datetime print(datetime.datetime.utcnow()) # 2022-07-15 10:51:26.211439 零时区的时间 print(datetime.datetime.now()) # 2022-07-15 18:51:26.227397 当前时区的时间 c =datetime.datetime(2022, 7, 15, 19, 00) print('指定日期:', c) # 指定日期: 2022-07-15 19:00:00 还可以自己编写时间
os模块
os模块主要跟当前程序的操作系统打交道
文件夹就是一个目录
1.创建目录
import os os.mkdir(r'aaa') # 就是创建一个单级目录 因为这是一个相对路径所以这个文件夹在项目的根目录下 os.makedirs(r'aaa\bbb\ccc') # 就是创建一个多级目录 也因为是一个相对路径所以创建的文件夹在项目的根目录下 # 多级目录还可以只创建一个单级目录 os.makedirs(r'eee') # 但是mkdir不能创建多级目录 os.mkdir(r'aaa\bbb\ccc') # 报错
2.删除目录
import os os.rmdir(r'eee') # 能够删除单级目录 # 单级目录下不能有数据要不然删除不掉 而且多级目录也删除不掉 # 文件夹a下有一个b.txt os.rmdir(r'a') # 会报错 因为文件夹a下有一个文本文件b.txt 所以删除不掉 os.rmdir(r'aaa\bbb\ccc') # 也会报错 因为多级文件也删除不掉 只能删除单级文件并且文件夹下还必须没有文件的才可以 os.removedirs(r'aaa') # 文件夹下如果有文件也是删除不掉的 os.removedirs(r'aaa\bbb\ccc') # 由内而外逐一删除 直到有数据的文件夹为止
3.列举文件指定路径下的所有文件名称
import os res = os.listdir(r'D:\MYpycharm\day21') print(res) # ['.idea', '11.py', 'a', 'db'] # 结果是一个列表 print(os.listdir(r'D://')) # D盘也是可以查看的
4.重命名文件 删除文件
import os os.rename(r'a.txt', 'bbb.txt') # 前面是老的文件名 后面是新的文件名 os.remove(r'bbb.txt') # 这样就可以删除文件了
5.获取当前工作路径
import os print(os.getcwd()) # D:\MYpycharm\day21 获取当前工作路径(绝对路径) os.chdir('..') # 切换路径 print(os.getcwd()) # D:\MYpycharm
6.与程序启动文件相关
import os print(os.path.abspath(__file__)) # D:\MYpycharm\day21\11.py 获取当前文件所在的绝对路径 print(os.path.dirname(__file__)) # D:/MYpycharm/day21 获取当前文件的根目录的绝对路径
7.判断路径是否存在(目录 文件)
import os print(os.path.exists(r'db')) # True 判断当前根目录下是否存在指定的文件夹 print(os.path.exists(r'ATM')) # False print(os.path.exists(r'aaa.txt')) # True 文件也可以 print(os.path.exists(r'jason.json')) # False 没有就返回False print(os.path.isfile(r'db')) # False 专门判断是否有没有指定的文件 db是一个文件夹所以是False print(os.path.isfile(r'aaa.txt')) # True print(os.path.isdir(r'aaa.txt')) #False 专门判断是否有没有指定的文件夹 aaa.txt是一个文件所以是False print(os.path.isdir('db')) # True
8.拼接路径
import os relative_path = 'a.txt' absolute_path = r'D:\MYpycharm\day21' # file_path = absolute_path + relative_path # print(file_path) # D:\MYpycharm\day21\\a.txt """ 涉及到文件的拼接的时候不要使用+号拼接 建议使用os模块中的join方法 """ print(os.path.join(absolute_path, relative_path)) # D:\MYpycharm\day21\a.txt # join方法可以自动识别当前所在的操作系统并自动切换正确的分隔符 windows:\ mac:/
9.获取文件的大小
import os print(os.path.getsize(r'aaa.txt')) # 获取的单位是bytes
sys模块
sys模块主要跟python解释器打交道
import sys print(sys.path) r''' 相当于是程序的环境变量 只要模块的路径在里面就可以使用该模块 [ 'D:\\MYpycharm\\day21', 'D:\\MYpycharm\\day21', 'D:\\PyCharm 2022.1.2\\plugins\\python\\helpers\\pycharm_display', 'D:\\python3.6\\python36.zip', 'D:\\python3.6\\DLLs', 'D:\\python3.6\\lib', 'D:\\python3.6', 'D:\\python3.6\\lib\\site-packages', 'D:\\PyCharm 2022.1.2\\plugins\\python\\helpers\\pycharm_matplotlib_backend' ] ''' print(sys.version) # 查看当前python解释器的版本 # 3.6.4 (v3.6.4:d48eceb, Dec 19 2017, 06:54:40) [MSC v.1900 64 bit (AMD64)] print(sys.platform) # 查看当前操作平台信息 # win32 res = sys.argv # ['D:/MYpycharm/day21/11.py'] if len(res) == 3: username = res[1] password = res[2] if username == 'jason' and password == '123': print('您可以正在执行该文件') else: print('用户名或密码错误') else: print('请填写用户名和密码 二者不可或缺') # 不过一定要在终端模式下运行 print(res) ''' 打印的是一个路径这个是在终端命令下才会显示出效果 在pycharm左下方可以点击Terminal就可以进入终端窗口 当切入到 python3 "11.py"这个路径时就会执行11.py这个文件 结果为: ['11.py'] 还可以在后面加上两个参数python "11.py" jason 123 就会添加到列表中 ['11.py', 'jason', '123'] 这样我们就可以使用用户和密码判断是否是jason如果是在运行 '''
json模块
json模块又称之为序列化模块
json模块时不同编程语言之间数据交互必备的模块(处理措施)
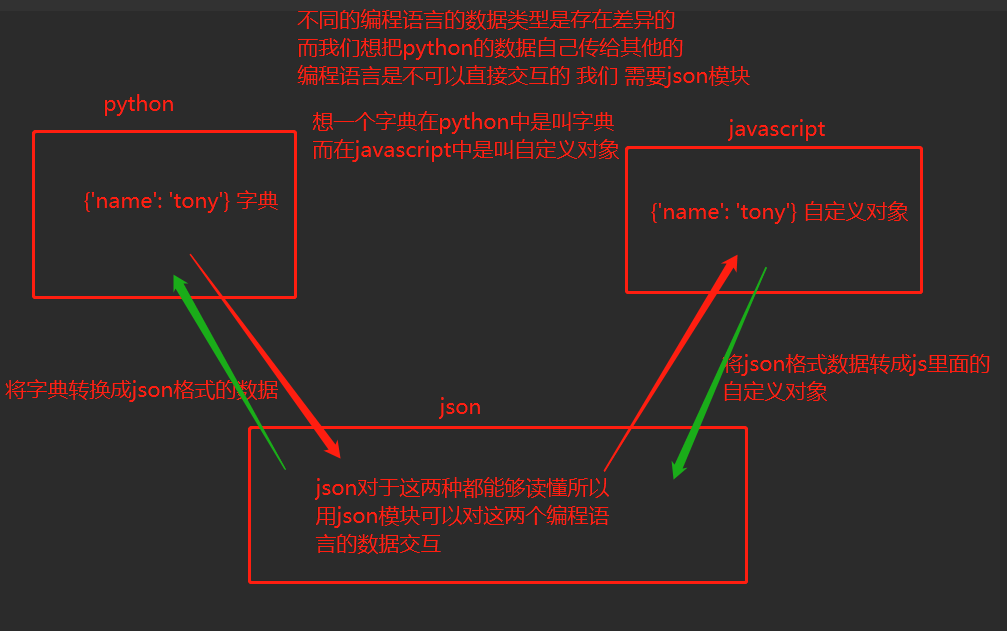
1.json格式的数据应该是什么
两个编程语言互相交互数据是通过网络传输数据的
而基于网络传输数据的单位都是二进制 那么在python中只有字符串可以通过调用encode方法转成二进制数
所以json格式数据也属于字符串
2.json格式数据的特征
json数据有一个很明显的特征
首先他是一个字符串 然后引号肯定是一个双引号
d = {'name': 'jason', 'pwd': 123}
# 需求:将上述字典保存到文件中 并且将来读取出来之后还是字典
d = {'name': 'jason', 'pwd': 123}
# 需求:将上述字典保存到文件中 并且将来读取出来之后还是字典
with open(r'b.txt', 'w', encoding='utf8') as f:
f.write(str(d))
with open(r'b.txt', 'r', encoding='utf8') as f:
data = f.read()
print(data, type(data)) # {'name': 'jason', 'pwd': 123} <class 'str'>
# 像这样直接使用str转换的话提取出来的时候还是一个字符串那么我们就不能对原来的字典进行操作了
我们可以使用json模块把其他数据类型转换成json格式的数据类型继续保存
然后在通过json模块给转回原来的数据数据类型继续提取
import json res = json.dumps(d) # 序列化 将其他数据类型转换成json格式字符串 print(res, type(res)) # # {"name": "jason", "pwd": 123} <class 'str'>这个时候字典就被转换成json格式的数据 d1 = {"name": "jason", "pwd": 123} print(d1) # {'name': 'jason', 'pwd': 123} 而我们自己打的双引号最后显示的还是一个单引号就是普通的字符串 res1 = json.loads(res) # 反序列化 将json格式字符串转换成对应编程语言中的数据类型 print(res1, type(res1)) # {'name': 'jason', 'pwd': 123} <class 'dict'> # 这样我们就可以把json数据转回原来的数据类型 import json with open(r'b.txt', 'w', encoding='utf8') as f: # f.write(json.dumps(d)) 这个dumps就是先转换成json数据然后在写入文件 json.dump(d, f) # 我们可以直接使用dump 直接让字典写入文件(json自动帮你完成转换) with open(r'b.txt', 'r', encoding='utf8') as f: # data = f.read() # res = json.loads(data) # 这个是先转换原来的数据类型 然后在赋值 # print(res, type(res)) res = json.load(f) # 也是自动装换成原来的数据直接赋值 print(res, type(res))
3.dumps与dump lords与lord的区别
''' dumps() 将其他数据类型转换成json格式字符串 lords() 将json格式字符串转换成对应的数据类型 dump() 将其他数据类型转成json格式字符串然后写入文件 lord() 将json格式字符串读取出来然后转换成对应的数据类型 '''
周末大作业
# 4.周末大作业 # # 项目功能 # 1.用户注册 # 2.用户登录 # 3.添加购物车 # 4.结算购物车 # # 项目说明 # 用户数据采用json格式存储到文件目录db下 一个用户一个单独的文件 # 数据格式 {"name":"jason","pwd":123} # # ps:文件名可以直接用用户名便于校验 # 用户注册时给每个用户添加两个默认的键值对(账户余额 购物车) # {"balance":15000,"shop_car":{}} # 添加购物车功能 商品列表可以自定义或者采用下列格式 # good_list = [ # ['挂壁面',3] # ['印度飞饼', 22] # ['极品木瓜', 666], # ['土耳其土豆', 999], # ['伊拉克拌面', 1000], # ['董卓戏张飞公仔', 2000], # ['仿真玩偶', 10000] # ] # 用户可以反复添加商品,在购物车中记录数量 # {'极品木瓜':[个数,单价]} # 结算购物车 # 获取用户购物车中所有的商品计算总价并结算即可 # 针对添加购物车和结算只有登录的用户才可以执行 import os import json is_login = { 'username': None } def login_auth(func): def wrapper(*args, **kwargs): if not is_login.get('username'): print('您为登入,请先登入') login() else: res = func(*args, **kwargs) return res return wrapper base_dir = os.path.dirname(__file__) db_dir = os.path.join(base_dir, 'db') if not os.path.exists(db_dir): os.mkdir(db_dir) def register(): while True: username = input('username>>>:').strip() password = input('password>>>:').strip() user_dict = { 'username': username, 'password': password, 'balance': 15000, 'shop_car': {} } file_path = os.path.join(db_dir, f'{username}.json') if os.path.exists(file_path): print('用户名已存在') break else: with open(file_path, 'w', encoding='utf8') as f: json.dump(user_dict, f) print('注册成功') break def login(): while True: username = input('username>>>:').strip() password = input('password>>>:').strip() file_path = os.path.join(db_dir, f'{username}.json') if os.path.exists(file_path): with open(file_path, 'r', encoding='utf8') as f: user_dict = json.load(f) if password == user_dict['password']: print('登入成功') is_login['username'] = username break else: print('密码错误') break else: print('用户名不存在') break @login_auth def add_shop_car(): goods_dict = [ ['挂壁面', 3], ['印度飞饼', 22], ['极品木瓜', 666], ['土耳其土豆', 999], ['伊拉克拌面', 1000], ['董卓戏张飞公仔', 2000], ['仿真玩偶', 10000] ] temp_shop_car = {} while True: for i, j in enumerate(goods_dict): print(f'商品编号:{i} | 商品名称:{j[0]} | 商品单价:{j[1]}') choice = input('请输入商品编号或则按(q)退出>>>:').strip() if choice == 'q': file_path = os.path.join(db_dir, f"{is_login.get('username')}.json") with open(file_path, 'r', encoding='utf8') as f1: user_dict = json.load(f1) real_shop_car = user_dict.get('shop_car') for good_name in temp_shop_car: if good_name not in real_shop_car: real_shop_car[good_name] = temp_shop_car[good_name] else: real_shop_car[good_name][0] += temp_shop_car[good_name][0] user_dict['shop_car'] = real_shop_car with open(file_path, 'w', encoding='utf8') as f2: json.dump(user_dict, f2, ensure_ascii=False) print('购物车添加成功') break if not choice.isdigit(): print('商品编号必须是纯数字') continue choice = int(choice) if choice not in range(len(goods_dict)): print('没有该商品编号') continue target_num = input('请输入商品数量>>>:').strip() if target_num.isdigit(): target_num = int(target_num) target_shop_car = goods_dict[choice] target_goods_name = target_shop_car[0] target_goods_price = target_shop_car[1] if target_goods_name not in temp_shop_car: temp_shop_car[target_goods_name] = [target_num, target_goods_price] else: temp_shop_car[target_goods_name][0] += target_num else: print('商品数量必须是纯数字') @login_auth def close_shop_car(): file_path = os.path.join(db_dir, f"{is_login.get('username')}.json") with open(file_path, 'r', encoding='utf8') as f: user_dict = json.load(f) balance = user_dict.get('balance') real_shop_car = user_dict.get('shop_car') total_money = 0 if len(real_shop_car) == 0: print('没有商品,请先添加') return for good_num, good_price in real_shop_car.values(): total_money += good_price * good_num if balance >= total_money: user_dict['balance'] -= total_money user_dict['shop_car'] = {} with open(file_path, 'w', encoding='utf8') as f: json.dump(user_dict, f, ensure_ascii=False) print(f'今日消费{total_money}') else: print('余额不足') func_dict = { '1': register, '2': login, '3': add_shop_car, '4': close_shop_car } while True: print(""" 0. 退出 1. 注册 2. 登入 3. 添加购物车 4. 结算购物车 """) choice = input('请输入功能编号>>>:').strip() if not choice.isdigit(): print('功能编号必须是数字') continue if choice == '0': break if choice in func_dict: func_dict[choice]() else: print('没有该功能编号')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号