数据的内置方法
今日内容总结
- 可变于不可变类型
- 列表的内置方法
- 字典的内置方法
- 元祖的内置方法
- 集合的内置方法
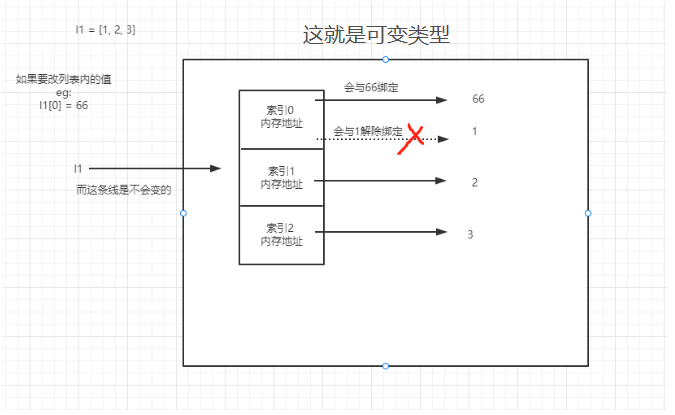
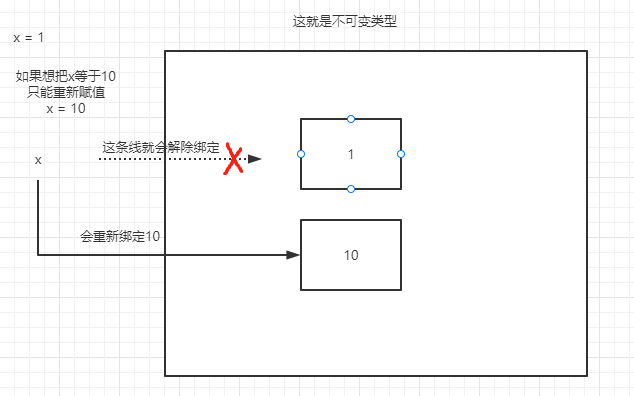
可变于不可变类型
1.可变类型
# 值改变 内存地址可以不变 l1 = [11, 22, 33] print(id(l1)) # 1931283911552 l1.append(44) # [11, 22, 33, 44] print(id(l1)) # 1931283911552
2.不可变类型
# 值改变 内存地址肯定变 s1 = '$hello$' print(id(s1)) # 1624061428432 s1 = s1.strip('$') print(id(s1)) # 1624061428432 a = 666 print(id(ccc)) # 2888916433776 a = 990 print(id(ccc)) # 2888886496976
列表的内置方法
1.列表的增删改查
我们在调用列表的内置方法时 是改变列表本身的值 不是产生新的值
1.1 列表的增操作
# 在列表的尾部添加数据值 1.关键字 :append 2.用法: l1 = [1, 2, 3, 4, 5] l2 = [11, 22, 33] l1.append(66) print(l1) # [1, 2, 3, 4, 5, 66] l1.append(l2) print(l1) # [1, 2, 3, 4, 5, 66, [11, 22, 33]] l1.append(44) print(l1) # [1, 2, 3, 4, 5, 66, [11, 22, 33], 44] '''append括号内无论写什么数据类型都当做一个数据值添加''' # 根据索引插入数据值 1.关键字 insert 2.用法 l1 = ['jason', 'tony', 11, 22, 'jerry'] l1.insert(0, 55) print(l1) # [55, 'jason', 'tony', 11, 22, 'jerry'] l1.insert(2, 'oscar') print(l1) # [55, 'jason', 'oscar', 'tony', 11, 22, 'jerry'] l1.insert(7, [1, 2, 3]) print(l1) # [55, 'jason', 'oscar', 'tony', 11, 22, 'jerry', [1, 2, 3]] ''' insert括号内第一个值是输入一个索引 第二个值是输入一个数据值 可以是任意数据类型 他会在索引位置添加你输入的数据值 原本的数据值就会往后 ''' # 扩展列表 1.关键字 2.用法 1.for循环 l1 = ['jason', 'tony', 1, 2, 3] l2 = [4, 5, 6] for i in l2: l1.append(i) print(l1) # ['jason', 'tony', 1, 2, 3, 4, 5, 6] 2.+ 号 l1 = ['jason', 'tony', 1, 2, 3] l2 = [4, 5, 6] l3 = l1 + l2 print(l3) # ['jason', 'tony', 1, 2, 3, 4, 5, 6] 3.extend() l1 = ['jason', 'tony', 1, 2, 3] l2 = [4, 5, 6] l1.extend(l2) print(l1) # ['jason', 'tony', 1, 2, 3, 4, 5, 6] ''' 就是把两个列表拼接起来可以用for循环也可以用加号 但是加号会浪费内存资源 推荐使用extend extend()其实就是for循环加上append() ''' l1 = ['jason', 'tony', 1, 2, 3] l1.extend([4, 5, 6]) print(l1) # ['jason', 'tony', 1, 2, 3, 1, 2, 3] '''extend括号内要放可迭代对象 就是可以支持for循环'''
1.2 列表的删操作
# 1.通用的删除方法 关键字 del l1 = ['jason', 'tony', 11, 22, 'jerry'] del l1[0] # 通过输入索引就可以想要删除你想要删除数据 print(l1) # ['tony', 11, 22, 'jerry'] del l1 print(l1) # 报错 因为列表被删除了 l1就会被认为没有定义 '''如果删除了整个列表那么这个列表就会被完全删除''' # 2.指名道姓删除 关键字 remove l1 = ['jason', 'tony', 11, 22, 'jerry'] l1.remove('jason') # 直接输入数据值 print(l1) # ['tony', 11, 22, 'jerry'] '''直接删除你想要的删除的数据值''' # 3.弹出删除 关键字 pop l1 = ['jason', 'tony', 11, 22, 'jerry'] # res = l1.remove('jason') # print(l1, res) # ['tony', 11, 22, 'jerry'] None res = l1.pop() print(l1, res) # ['jason', 'tony', 11, 22] jerry '''pop随机弹出列表的末尾 然后在删除''' res = l1.pop(0) # 可以输入索引 print(l1, res) # ['tony', 11, 22, 'jerry'] jason
1.3列表的改与查操作
# 1.改 l1 = ['jason', 'tony', 11, 22, 'jerry'] l1[0] = 12 # 输入索引就可以改变该列表的值 print(l1) # [12, 'tony', 11, 22, 'jerry'] l1[6] = 13 print(l1) # 会报错因为列表没有改索引 # 2.查 l1 = ['jason', 'tony', 11, 22, 'jerry'] print(l1) # ['jason', 'tony', 11, 22, 'jerry'] print(l1[0]) # jason print(l1[1:4]) # ['tony', 11, 22] ''' 可以查看列表所有的值 也可以靠索引查看数据值 也可以按切片方法查看 '''
2.index
# 1.意思 查看指定的数据对应的索引值 # 2.用法 l1 = ['jason', 'tony', 11, 22, 'jerry'] print(l1.index('tony')) # 1 """就是查看'tony'在列表l1中的索引是多少"""
3.sort
# 1.意思 排序 # 2.用法 l1 = [1, 2, 6, 5, 5, 6, 2, 56, 3, 5, 6] l1.sort() print(l1) # [1, 2, 2, 3, 5, 5, 5, 6, 6, 6, 56] l1.sort(reverse = True) print(l1) # [56, 6, 6, 6, 5, 5, 5, 3, 2, 2, 1] ''' sort括号内不写默认升序 sort括号内些了reverse = True 说明翻转为真 变为降序 '''
4.reverse
# 1.意思 翻转 # 2.用法 l1 = ['jason', 'kevin', 'oscar', 'jerry', 'tony', 'owen'] l1.reverse() print(l1) # ['owen', 'tony', 'jerry', 'oscar', 'kevin', 'jason'] '''就是把列表前后颠倒'''
5.count
# 1.意思 统计指定数据的个数 # 2.用法 l1 = ['jason', 'tony', 11, 22, 'jerry', 'jason', 'jason', 'jason'] print(l1.count('jason')) # 4 """就是查看'jason'在列表中有多少个"""
6.比较运算
l1 = [9, 8, 7] l2 = [1, 2, 3, 4, 5] print(l1 > l2) # True 是按位置顺序一一比较 l1 = ['a', 8, 7] l2 = [1, 2, 3, 4, 5] print(l1 > l2) # 报错 不同数据类型不能做比较 l1 = ['a', 8, 7] # a对应的是97 l2 = ['A', 2, 3, 4, 5] # A对应的是65 print(l1 > l2) # True 字母会有对应的ASCII码做比较 l1 = ['我', 8, 7] l2 = ['你', 2, 3, 4, 5] print(l1 > l2) # True 中文的也有对应的字符编码

字典的内置方法
1.类型转换
# 类型转换 print(dict([('name', 'jason'), ('pwd', 123)])) # {'name': 'jason', 'pwd': 123} print(dict(name='jason', pwd=123)) # {'name': 'jason', 'pwd': 123} '''字典很少涉及到类型转换 都是直接定义使用'''
2.字典的取值操作
d = { 'name': 'tony', 'age': 18, 'hobby': 'run' } 1.直接按k取值 print(d['name']) # tony print(d['xxx']) # 报错 k不存在会直接报错 2.get print(d.get('name')) # tony print(d.get('xxx')) # None k不存在不会报错 会返回None print(d.get('name', '键不存在返回的值 默认返回None')) # tony print(d.get('xxx', '键不存在返回的值 默认返回None')) # 键不存在返回的值 默认返回None ''' get取值时如果只写k 那么就算k不存在也不会报错 如果get里后面写了k和另外一个参数 那么k存在就会取k对应的v k不存在就会返回后面那个参数 如果get只写了k默认返回None '''
3.len
len就是计算字典里有多少对键值对 d = { 'name': 'tony', 'age': 18, 'hobby': 'run' } print(len(d)) # 3
4.修改和新增
d = { 'name': 'tony', 'age': 18, 'hobby': 'run' } d['name'] = 'jason' # 键存在就是修改k对应的值 print(d) # {'name': 'jason', 'age': 18, 'hobby': 'run'} d['addr'] = '上海' # 键不存在就是新增一对键值对 print(d) # {'name': 'jason', 'age': 18, 'hobby': 'run', 'addr': '上海'}
5.删除键值对
d = { 'name': 'tony', 'age': 18, 'hobby': 'run' } # 1.直接删除 del d['name'] print(d) # {'age': 18, 'hobby': 'run'} 直接删除 # 2.弹出删除 res = d.pop('name') print(d, res) # {'age': 18, 'hobby': 'run'} tony 跟列表一样删除的时候还可以调用一下 然后在删除 # 3.随机删除 d.popitem() print(d) # {'name': 'tony', 'age': 18} 随机删除一对键值对 # pycharm优化了popitem让它删除末尾的数
6.快速获取k v k:v键值对
1.快速获取键(k) d = { 'name': 'tony', 'age': 18, 'hobby': 'run' } print(d.keys()) # dict_keys(['name', 'age', 'hobby']) '''会单独提取出所有的键(k) 可以看作是元祖套列表''' print(d.values()) # dict_values(['tony', 18, 'run']) '''会单独提取出所有的值(v) 也可以看作是元祖套列表''' print(d.items()) # dict_items([('name', 'tony'), ('age', 18), ('hobby', 'run')]) '''会提取出所有的键值对 可以看作是列表套元祖'''
7.更新键值对
d = { 'name': 'tony', 'age': 18, 'hobby': 'run' } d.update({'name': 'jason'}) print(d) # {'name': 'jason', 'age': 18, 'hobby': 'run'}
d.update({'gender': 'male'}) print(d) # {'name': 'jason', 'age': 18, 'hobby': 'run', 'gender': 'male'} '''键存在则修改值 键不存在则新增'''
8.快速构造字典
res = dict.fromkeys([1,2,3],None) print(res) # {1: None, 2: None, 3: None} ''' 它是让第一个参数中所有的值当字典的k 然后把后面的值绑定给前面的所有k
所以所有k的值都是后面的参数 ''' new_dict = dict.fromkeys(['name', 'pwd', 'hobby'], []) new_dict['name'].append(123) new_dict['pwd'].append(123) new_dict['hobby'].append('read') print(new_dict) # {'name': [123, 123, 'read'], 'pwd': [123, 123, 'read'], 'hobby': [123, 123, 'read']} '''不管你是用哪个k来添加值 所有的v都会改变'''
9.setdefault
# 键存在则获取键对应的值 键不存在则设置 并返回设置的新值 d = { 'name': 'tony', 'age': 18, 'hobby': 'run' } res = d.setdefault('name', 'jasonNB') print(res, d) # tony {'name': 'tony', 'age': 18, 'hobby': 'run'} res1 = d.setdefault('xxx', 'jasonNB') print(res1, d) # jasonNB {'name': 'tony', 'age': 18, 'hobby': 'run', 'xxx': 'jasonNB'} '''就是如果键(k)存在就不会做改变 如果键不存在就会添加新的值'''

元祖的内置方法
1.元祖的类型转换
'''除了整数 浮点型 布尔值 其他的都可以转换为元祖 就是能支持for循环的都可以转换为元祖''' # 当元祖内只有一个数据值时 t = () i = (1) s = ('jason') l = ([1,2]) d = ({'name':'tony'}) print(type(t)) # tuple print(type(i)) # int print(type(s)) # str print(type(l)) # list print(type(d)) # dict ''' 当元祖内只有一个数据值时数据类型是不会变成元祖的 输入什么数据类型还是什么类型 必须要在数据值后面加一个逗号 ''' t = () i = (1,) s = ('jason',) l = ([1,2],) d = ({'name':'tony'},) print(type(t)) # tuple print(type(i)) # tuple print(type(s)) # tuple print(type(l)) # tuple print(type(d)) # tuple '''所以以后编写可以存放多个数据类型的时候里面只有一个数据时都要加上逗号'''
2.索引取值
t = (1, 2, 3, 4, 5, 6, 7) print(t[0]) # 1 print(t[-1]) # 7 '''元祖索引支持正向取值 也可以负向取值''' print(t[1:5]) # (2, 3, 4, 5) '''也支持切片操作(顾头不顾尾)''' print(t[0:5:2]) # (1, 3, 5) '''也支持分隔操作(顾头不顾尾)'''
3.增删改查操作
t = (1, 2, 3, 4, 5, 6, 7) print(t) # (1, 2, 3, 4, 5, 6, 7) print(t[0]) # 1 t[0] = 10 print(t) # 报错因为元祖不能修改 '''元祖不能修改绑定好的内存地址 元祖只能看 不能改''' t1 = (11, 22, 33, [11, 22]) t1[-1].append(1) print(t1) # (11, 22, 33, [11, 22, 1]) '''因为列表是可变类型修改列表内的值时不会改变列表的内存地址''' # 所以当定义好了一个元祖之后 就不能再修改删除添加元祖了 只能查看

集合的内置方法
1.集合的类型转换
1.类型的转换
支持for循环 并且数据类型是不可变类型
定义空集合必须是要用关键字set
集合内的数据必须是不可变类型(整型、浮点型、字符串、元祖、布尔值)
2.集合去重
# 去重 s1 = {1, 1, 2, 3, 2, 1, 4, 5, 4, 5, 6, 3, 2, 54, 1, 2, 6, 5, 4, 1, 25, 45, 122} print(s1) # {1, 2, 3, 4, 5, 6, 45, 54, 25, 122} '''可以把集合内的值去重把重复的值去掉只留下一个值''' l1 = ['jason', 'jason', 'tony', 'oscar', 'tony', 'oscar', 'jason'] s2 = set(l1) l1 = list(s2) print(l1) # ['tony', 'oscar', 'jason'] '''列表取值可以先把列表转换为集合 集合会自动去重 然后把去重的值在转换为列表赋值回原来列表的名字'''
3.集合的关系运算
# 模拟两个人的好友集合 f1 = {'jason', 'tony', 'oscar', 'jerry'} f2 = {'kevin', 'jerry', 'jason', 'lili'} # 1.求两个人的共同好友 print(f1 & f2) # {'jason', 'jerry'} # 2.求两个的所有好友 print(f1 | f2) # {'kevin', 'tony', 'lili', 'jason', 'jerry', 'oscar'} # 3.求f1独有的好友 print(f1 - f2) # {'oscar', 'tony'} 如果是求f2独有的好友: print(f2 - f1) # {'kevin', 'lili'} # 4.求两个不同的好友 print(f1 ^ f2) # {'lili', 'oscar', 'kevin', 'tony'} ''' & 求两个集合的共同值 | 求两个集合的所有值 - 求减号前面集合的独有的值 ^ 求两个集合不同的值 '''
作业
1.利用列表编写一个员工姓名管理系统
# 利用列表编写一个员工姓名管理系统 # 输入1执行添加用户名功能 # 输入2执行查看所有用户名功能 # 输入3执行删除指定用户名功能 # ps: 思考如何让程序循环起来并且可以根据不同指令执行不同操作 # 提示: 循环结构 + 分支结构 # 拔高: 是否可以换成字典或者数据的嵌套使用完成更加完善的员工管理而不是简简单单的一个用户名(能写就写 # 不会没有关系) # 1.定义一个空列表 user_data_list = [] # 2.循环打印功能编号 while True: print(""" 1.添加 2.查看 3.删除 """) # 3.输入功能编号 choice = input('请选择功能编号>>>:').strip() # 4.判断功能编号 if choice == '1': # 5.获取用户信息 username = input('请输入你的用户名>>>:').strip() # 6.判断用户名是否一存在 if username in user_data_list: print('用户名已存在') else: user_data_list.append(username) print('添加成功') elif choice == '2': # 7.查看 print(user_data_list) elif choice == '3': # 8.输入要删除的员工 delete_name = input('请输入您要删除的用户>>>:') # 9.判断输入的用户是否存在 if delete_name in user_data_list: # 10.删除用户 user_data_list.remove(delete_name) print('已删除该员工') else: print('该员工不存在') else: print('请输入正确的功能编号') # 拔高: 是否可以换成字典或者数据的嵌套使用完成更加完善的员工管理而不是简简单单的一个用户名 # 1.创建一个空字典 user_data_dict = {} # {'id':{'id':id, 'name':name}} # 2.循环打印功能 while True: print(""" 1.添加用户 2.查看用户 3.查看指定用户 4.修改薪资 5.删除用户 """) # 3.输入功能编号 choice = input('请输入功能编号>>>:').strip() # 4.判断用户是否输入 if len(choice) == 0: print('请输入编号') continue # 5.判断用户是否输入数字 if not choice.isdigit(): print('请输入数字') continue # 6.判断用户的选择 if choice == '1': # 添加用户信息 # 7.输入员工编号 emp_id = input('请输入员工编号>>>:').strip() # 8.判断员工编号是否存在 if emp_id in user_data_dict: print('员工编号已存在,无法添加') continue emp_name = input('请输入员工姓名>>>:').strip() emp_salary = input('请输入员工薪资>>>:').strip() # 9.创建大字典里的值 因为大字典里的值是个字典所以手动创建一个字典存储一个信息 user_dict = {'emp_id': emp_id, 'emp_name': emp_name, 'emp_salary': emp_salary} # 10.把小字典加入到大字典中 user_data_dict[emp_id] = user_dict # 11.提示信息 print('员工添加成功') elif choice == '2': # 12.员工信息都在大字典中的值中所以我们只要获取大字典的值 {'emp_id':emp_id, 'emp_name':emp_name, 'emp_salary':emp_salary} for staff in user_data_dict.values(): print('staff info'.center(30, '*')) print(""" 员工编号:%s 员工姓名:%s 员工薪资:%s """ % tuple(staff.values())) # 13.员工信息是小字典中的值 print('end'.center(30, '*')) elif choice == '3': # 14.输入编号 target_id = input('请输入要查看的员工编号>>>:').strip() # 15.判断编号是否存在 if target_id not in user_data_dict: print('员工编号不存在,无法查看') continue # 16.提取该员工编号的字典 user_dict = user_data_dict[target_id] # 只查看一个员工信息的话只要提取员工编号就可以 print('staff info %s'.center(30, '*')) print(""" 员工编号:%s 员工姓名:%s 员工薪资:%s """ % tuple(user_dict.values())) print('end'.center(30, '*')) elif choice == '4': # 4.修改薪资 # 17.输入员工编号 target_id = input('请输入要查看的员工编号>>>:').strip() # 18.判断员工编号是否存在 if target_id not in user_data_dict: print('员工编号不存在,无法修改') continue # 19.提取该员工编号的字典 user_dict = user_data_dict[target_id] # 20.输入新的薪资 new_salary = input('请输入该员工新的薪资>>>:').strip() # 21.修改小字典的值 user_dict['emp_salary'] = new_salary # 22.修改大字典 user_data_dict[target_id] = user_dict print(f'员工编号{target_id}已修改为{new_salary}') elif choice == '5': # 删除员工 # 23.输入员工编号 delete_id = input('请输入要查看的员工编号>>>:').strip() # 24.判断员工编号 if delete_id not in user_data_dict: print('员工编号不存在,无法修改') continue # 25.删除员工编号 res = user_data_dict.pop(delete_id) print(f'员工编号{delete_id}已删除', res) else: print('请输入正确的编号')
2.去重下列列表并保留数据值原来的顺序
# eg: [1, 2, 3, 2, 1] # 去重之后[1, 2, 3] l1 = [2, 3, 2, 1, 2, 3, 2, 3, 4, 3, 4, 3, 2, 3, 5, 6, 5] # 方式一 l1 = [2, 3, 2, 1, 2, 3, 2, 3, 4, 3, 4, 3, 2, 3, 5, 6, 5] s1 = set(l1) l1 = list(s1) print(l1) # 方式二 l1 = [2, 3, 2, 1, 2, 3, 2, 3, 4, 3, 4, 3, 2, 3, 5, 6, 5] new_l1 = [] for i in l1: if i not in new_l1: new_l1.append(i) new_l1.sort() l1 = new_l1 print(l1)
3.有如下两个集合,pythons是报名python课程的学员名字集合,linuxs是报名linux课程的学员名字集合
# pythons = {'jason', 'oscar', 'kevin', 'ricky', 'gangdan', 'biubiu'} # linuxs = {'kermit', 'tony', 'gangdan'} # 1.求出即报名python又报名linux课程的学员名字集合 pythons = {'jason', 'oscar', 'kevin', 'ricky', 'gangdan', 'biubiu'} linuxs = {'kermit', 'tony', 'gangdan'} print(pythons & linuxs) # {'gangdan'} #2. 求出所有报名的学生名字集合 print(pythons | linuxs) # {'biubiu', 'tony', 'jason', 'ricky', 'kermit', 'gangdan', 'oscar', 'kevin'} # 3.求出只报名python课程的学员名字 print(pythons - linuxs) # {'ricky', 'biubiu', 'jason', 'kevin', 'oscar'} # 4.求出没有同时这两门课程的学员名字集合 print(pythons ^ linuxs) # {'kermit', 'tony', 'biubiu', 'oscar', 'ricky', 'kevin', 'jason'}


 浙公网安备 33010602011771号
浙公网安备 33010602011771号