深度学习之文本分类模型-基于attention机制
1、HAN
HAN(Hierarchical Attention Networks)是由Zichao Yang[1]等人提出的一种算法,其主要思想是利用attention机制,将单词进行编码,得到句子的向量s,接着用同样的方式对句子进行编码,最终得到文章的向量V,最终,可以在V上加入softmax,进而进行分类模型的构建。最终在多个数据集上达到了SOTA,其模型结构图如下所示:

整体的架构包括四个部分:word encoder, word attention, sentence encoder, sentence attention。
- word encoder
给定一个句子中的单词\(w_{it} t \in [0,T]\),我们首先得到单词的embedding信息,通过矩阵\(W_{e}\),\(x_{ij} = W_{e} * w_{it}\),接着,我们将得到的单词信息依次的通过双向的GRU网络,分别得到相应每个单词隐藏层输出信息。公式如下所示
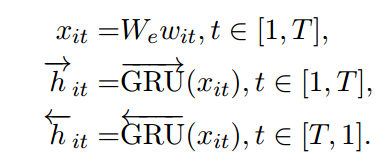
- Word Attention
我们将\(h_{it}\)输入到一个多层感知机(MLP)中,激活函数是tanh函数,并得到\(u_{it}\)向量,接下来,我们通过上下文向量\(v_{w}\)与\(u_{it}\)进行向量操作,并通过一个softmax层,最终得到单词的重要性矩阵\(\alpha _{it}\),表示第\(i\)个句子中第t的位置的重要性。最后我们将重要性的矩阵加到\(h_{it}\)上,得到句子的向量\(s_{i}\),具体公式如下:

- Sentence Encoder
Sentence Encoder和word encoder相似,同样输入到一个双向的GRU中,并将两个双向的向量进行拼接,得到第\(i\)个句子\(h_{i}\) - Sentence Attention
接下来我们按照上述方式,得到句子的重要性矩阵\(\alpha _{i}\),并将其作用到\(h_{i}\)中,最终得到文章的向量\(v\),公式如下
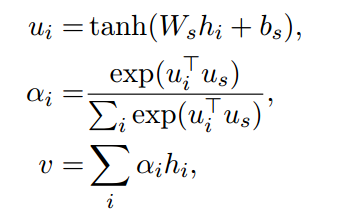
- Document Classification
当我们得到文档的向量后,我们就可以加上全连接层,输出节点的个数是类别数量,构建模型进行训练了。
2、inner-attention for NLI
这里介绍一个自然语言推测(NLI)的任务,NLI讲的是一个句子是否可以推测出另外一个句子,这种可以看做是一个分类任务,类别有三种,分别是Entailment (inferred to be true), Contradiction (inferred to be false) and Neutral (truth unknown),例如:

Yang Liu[2]等人提出了将mean pooling 和 inner-attention方法加入到了这种任务中。其思想整体架构图如下所示
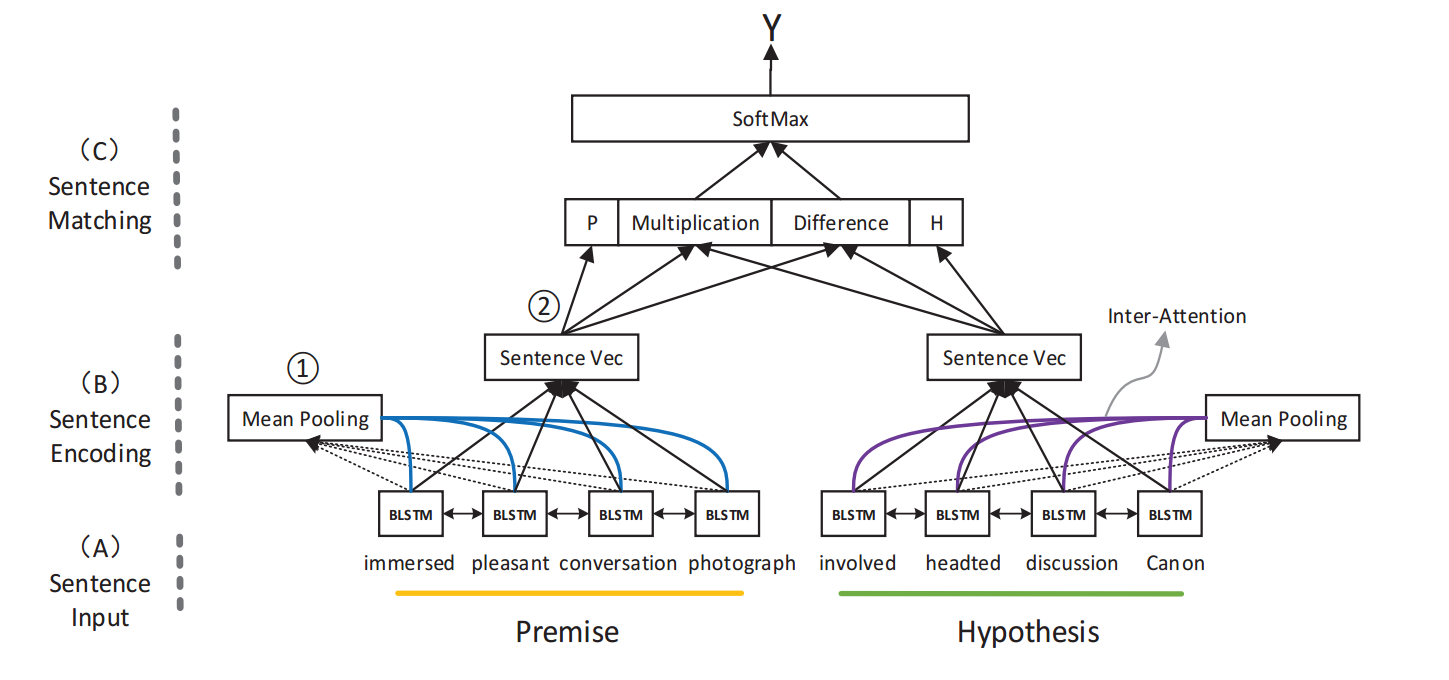
其网络结构可以看做是孪生网络结构,我们输入"前提"句子和"假设"句子,通过共享的多层网络,最终得到两个句子的表达,最后将两个句子做一个拼接,最后加上一个softmax层,作为最终的分类。
其网络结构由三部分组成:sentence input,sentence encoding, sentence matching
- sentence input
sentence input 模块主要是将单词转化为词向量,这里就不做过多的讲解了,可以利用固定词向量,或者是随着网络自己训练。 - sentence encoding
sentence encoding首先将词向量通过双向的LSTM,得到对应的表达,接下来包括两个阶段,第一个阶段是将最顶端的LSTM的输出进行average pooling操作,得到对应的向量,第二个阶段是Inner attention,其公式如下
![]()
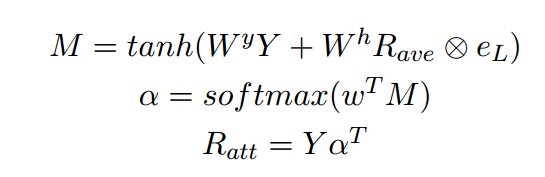
其中Y表示双向LSTM的输出,\(R_{ave}\)表示的平均池化的输出,\(\alpha\)表示attention矩阵,这里论文中的参数介绍的并不是很详细,我理解之所以叫Inner attention是因为它用了内部的LSTM的表达。
- sentence matching
我们将两个句子分别得到相应的表达,那么拼接的方式有三种:a、直接拼接。b、元素之间相乘。c、元素之间求差异(没明白啥意思)。最终,我们在最后加上softmax层。
3、Attentive Pooling
AP(Attentive Pooling)是用于QA的,其由IBM的Cicero dos Santos(3)等人提出的一种算法,其基本思想是利用一个权重矩阵,将问题Q和答案A进行信息的交互关联,也就是说Q的表达中包含A的一些信息,A的表达中又包含了Q的一些信息,在最后,我们各自提取每个维度的max pooling的值,各自经过softmax,得到相应的表达。总体的结构图如下所示
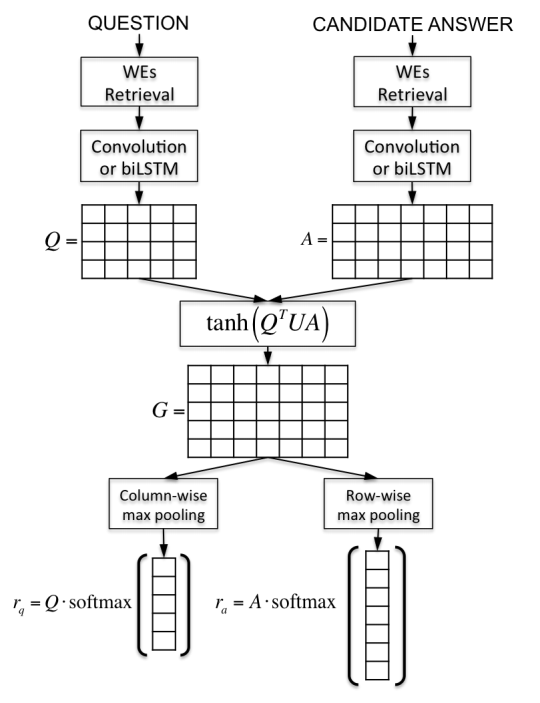
由图所示,我们首先得到question和answer的表达,即各自的词向量WEs,接下来,我们利用LSTM或者是CNN提取深层次的特征,对于模型利用LSTM来说,我们叫AP-LSTM,对于利用CNN的模型来说,叫做AP-CNN,接着,我们得到对应的输出Q和A,接着建立一个向量矩阵G,我们利用\(tanh(Q^{T} G A)\)得到Q和A相关的表达G,接下来,利用max pooling,得到row的表达和column的表达,将这两个表达分别进行softmax,进而乘以各自的原始向量Q,A,得到表达\(r_{q}\)和\(r_{a}\),我们利用向量相似性计算方式,得到两者的结果。
4、LEAM
LEAM是Guoyin Wang[4]等人提出的将单词和分类的label同时进行embedding,接着利用两者向量的cosin余弦值获得矩阵向量,利用"划窗"方法(这个名字是我自己取得)得到对应的向量,最后输出层依旧是softmax,进行分类预测。整体逻辑架构如下图所示

这里(a)表示的是传统的分类方法,(b)是作者提出的算法。我们分别来进行讲解。
-
step1
我们首先得到单词的embedding向量和label的embedding向量。假设单词的embedding向量维度为V=(128,100),label的embedding向量为C=(10,100)其中,128代表输入单词的个数,10代表类别标签的个数。 -
step2
接下来进行C和V的cosin操作,这里将C和V进行矩阵操作,得到(128,10)的矩阵,\(\hat{G}\)也是(128,10)的矩阵,将这两个向量进行相除,得\(G\)。为啥会有个\(\hat{G}\)这个矩阵呢,我们知道cosin余弦最后要除以两个向量模的乘积,所以在\(\hat{G}\)的每个单元格中,分别代表各自向量模的乘积。
![]()
-
step3
接着,我们将这个(128,10)的矩阵进行一些操作,对于其中的一条向量,我们选择其上下各r个向量,包括该向量本身,组成一个(2r+1,10)的矩阵,这里\(W_{1}\)是一个(2r+1)的向量,\(b_{1}\)为(10)维向量,我们对(2r+1,10)的这个矩阵进行操作,首先与\(W_{1}\)进行矩阵乘法,得到(10)维向量,再与\(b_{1}\)进行相加,得到(10)维向量。最后,我们利用max_pooling取这个(10)维向量中最大的,得到\(m_{l}\)
![]()
![]()
-
step4
经过多次这样的操作,我们会得到一个长度为L的向量\(m\),对\(m\)进行softmax操作,最终得到\(\beta\)。
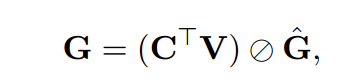
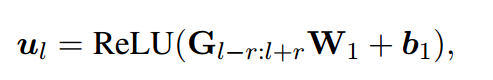

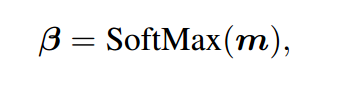
- step5
\(\beta\)为一个长度为L的向量,其中每一个维度都表示当前单词\(l\)的一些权重信息,我们将权重信息乘以最后的单词信息\(v_{l}\)上,本质上是对单词向量加上权重,并将所有词向量的各个维度进行相加,最终得到向量维度为10的固定向量。有了这个表达向量,我们就可以进行最后的softmax操作,进行分类的训练了。
![]()

5、DRCN
DRCN(Densely-connected Recurrent and Co-attentive neural Network )是由韩国人Seonhoon Kim[5]等人提出的一种算法,其整体思想是将embedding层,RNN隐藏层和经过attention之后的向量进行拼接,并进行多次这样的操作,最终通过一个AE,池化,和全连接操作,得到相应的结果。其主要包括Word Representation Layer、Densely connected Recurrent Networks、Densely-connected Co-attentive networks、Bottleneck component、Interaction and Prediction Layer。接下来我们一步一步来进行解释。
首先我们先放上论文中模型的结构图。
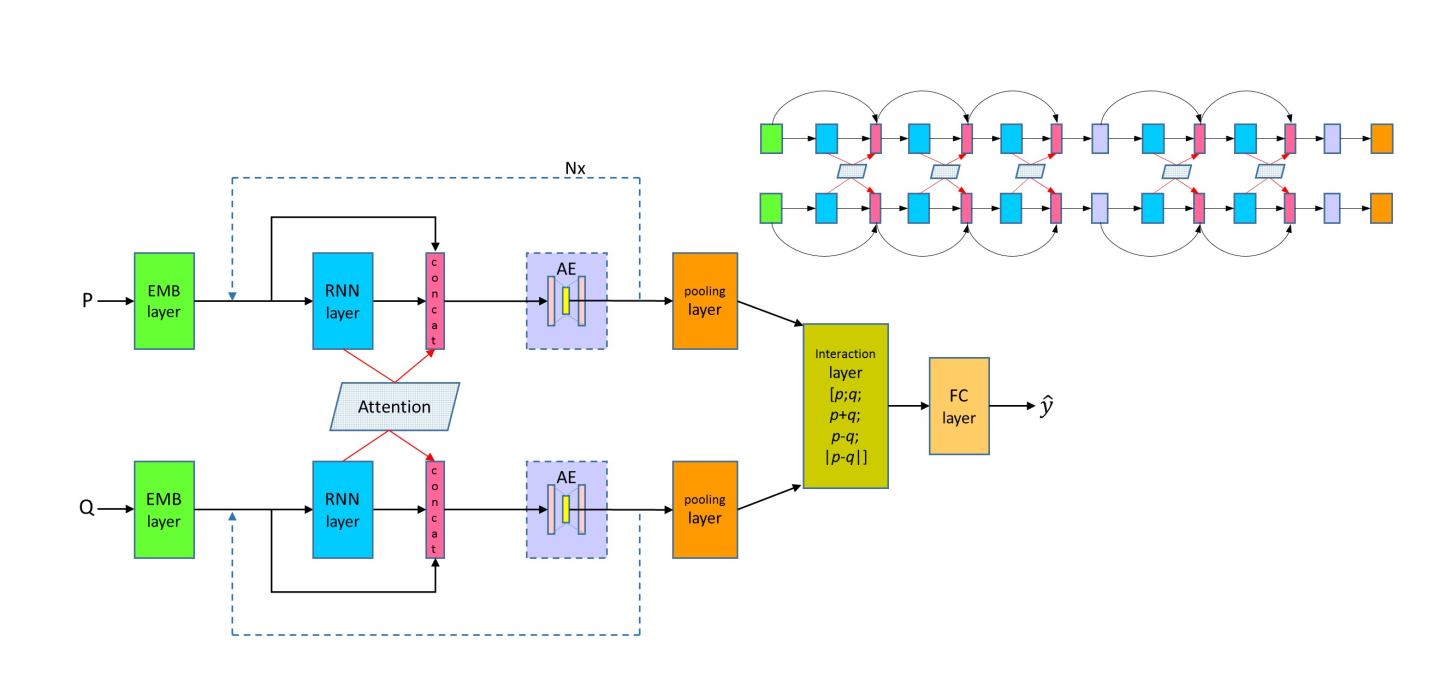
- Word Representation Layer
词向量的输入,词向量的输入分为四个部分,并将这四个部分进行拼接,第一部分是用固定词向量,这里可以利用word2vec或者glove等其他词向量获取方式得到词向量。第二部分是可训练词向量,这里其实也可以利用word2vec或者glove等训练的词向量,或者使用随机初始化的词向量,这一部分的词向量会在训练时更新参数。这里作者给出了两者的优缺点,固定词向量可以防止过拟合,但是对于特定领域的数据不灵活,可训练的词向量可以得到特征间的关系的表达,但是容易过拟合,所以将两者一起使用。第三个部分是字符级别的embedding,这里的embedding经过一个卷积神经网络,得到对应的表达,第四个部分表示当前单词是否出现在另外一个句子中,这样将这四个部分词向量进行拼接,得到模型的输入词向量。公式如下
![]()

其中\(e_{p_{i}}^{fix}\)表示第二部分,固定词向量。\(e_{p_{i}}^{tr}\)表示第二部分,可训练词向量。\(c_{p_{i}}\)表示第三部分,字符级别向量。\(f_{p_{i}}\)表示第四部分。最后将这些向量进行拼接,得到输入向量。
-
Densely connected Recurrent Networks
这一部分就是得到RNN的输出向量,这里也有三种方式,第一种,直接利用RNN的输出向量\(h_{i}\),第二种,将RNN的输出向量\(h_{i}\)和输入向量\(x_{i}\)进行加和,第三种,将\(h_{i}\)和\(x_{i}\)进行拼接。 -
Densely-connected Co-attentive networks
这一部分,我们需要获得attention的表达,公式如下
![]()

在每一个步骤中,我们都会得到两个句子的RNN隐藏层表达,分别为\(h_{p_{i}}\)和\(h_{q_{j}}\),我们初始化有一个attention权重矩阵\(\alpha_{ij}\)表示第一个句子第\(i\)个单词和第二个句子第\(j\)个单词的权重,首先,我们根据权重矩阵\(\alpha_{ij}\)和第二个句子\(h_{q_{j}}\)得到第一个句子相应的表达\(\alpha_{p_{i}}\),接下来,我们更新权重矩阵\(\alpha_{ij}\),首先我们获得\(h_{p_{i}}\)和\(h_{q_{j}}\)的\(\cosin\)余弦值以及\(h_{p_{i}}\)和其他单词的余弦值,但其实这里我有个疑问,就是在第一轮的时候,后面的RNN隐藏层单元还没有得到,这里我们怎么计算余弦值?这里先空着,如果后续有答案了再补上。最终,我们将上面两个部分得到的向量进行拼接,最终得到新的输入向量。

- Bottleneck component
这里加入了一个AE,说是由于参数量过大,目的是为了减少参数量。 - Interaction and Prediction Layer
最终,我们得到两个句子的输出,我们可以利用\(p+q\),\(p-q\),\(|p-q|\)等操作,以及原始\(p,q\)进行拼接,再加上一个全连接层,最终得到相应的输出。
6、ABCNN
ABCNN(attention based CNN)是由Wenpeng Yin[6]等人提出,其目的是将attention机制加入到CNN中,实验结果取得了SOTA的效果。其模型总共由三个,分别是ABCNN-1,ABCNN-2,ABCNN-3。下面分别来进行介绍。
这两节主要介绍了文本匹配,其实文本匹配在形式上也是一种分类任务,在输出端为二分类,表示相关和不相关,所以将其放在文本分类中进行讲解。
-
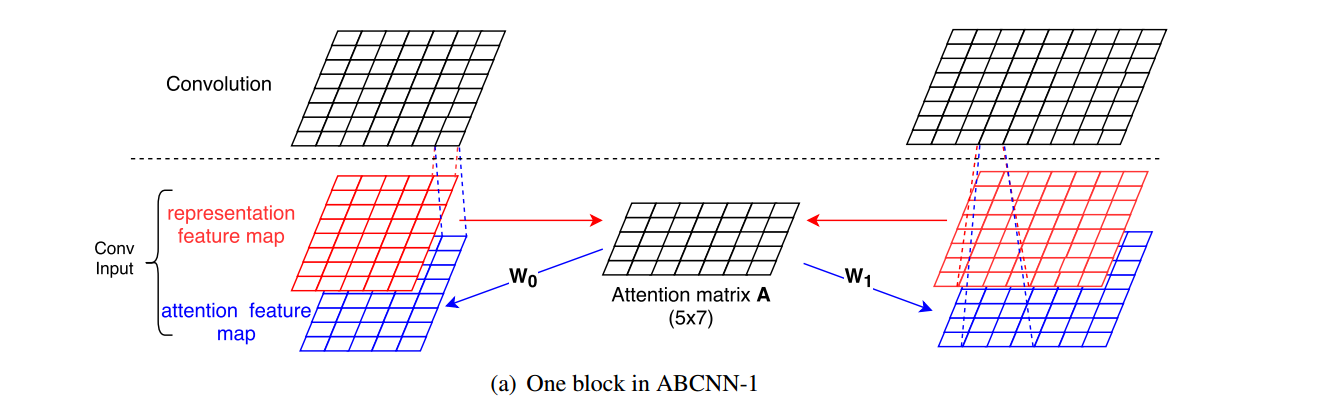
ABCNN-1
红色框框为输入的文本向量表达,我们看到由两个红色的框框,分别表示两段文本,假设其中一段文本维度为[5,8],另一段文本为[7,8],首先,我们利用一些求相似性的手段,论文中用\(1/(1 + |x - y|)\)其中,x,y分别表示[1,8]和[1,8]的文本,其中\(|.|\)表示欧式距离,这样我们就可以得到attention matrix的矩阵A,其维度为[5,7],接下来,我们用两个向量\(w_{0},w_{1}\)来对矩阵\(A\)进行向量操作,其中\(w_{0}\)的维度是[7,8],\(w_{1}\)的维度是[5,8],这样就可以得到attention feature map,其维度分别为[5,8]和[7,8],我们将这两个attention feature map 和 原始的representation feature map进行组合,输入到卷积神经网络中,得到输出。
![]()
-
ABCNN-2
由图所示,我们假设conv input的两个句子分别为[5,8]和[7,8]的矩阵,首先,经过一个卷积层,得到[7,8]和[9,8]的矩阵,之所以维度会增大是因为在输入的句子中加入了padding向量。接下来,我们依旧通过一些操作得到attention matrix A,A的维度是[7,9],方法依旧可以用ABCNN-1的方法来进行获得。接着,我们将A的行和列分别进行相加,得到[1,7]和[1,9]的向量,并用卷积层对原始的[7,8]和[9,8]的矩阵进行卷积操作,这里不进行padding,窗口大小为3,filter大小为[3,8],我们先将[1,7]的对应3维向量和filter,以及原始矩阵进行相乘,并在相应维度进行相加求平均操作,得到[1,8]向量,经过5次卷积,得到[5,8]向量,最后,我们可以根据得到的两个[5,8]矩阵进行操作。
![]()
-
ABCNN-3
ABCNN-3就是将ABCNN-1和ABCNN-2进行合并
![]()


7、Multiway Attention Networks
这篇论文是Chuanqi Tan[7]等人发表的,这篇论文的主要思路是使用了四种attention的方式对句子进行表达,分别是Concat Attention、Bilinear Attention、Dot Attention、Minus Attention四种attention方式,模型整体架构如图所示分为编码层,多方式attention匹配层,聚合层、预测输出层。

- 编码层
这一层对输入的单词进行编码,这里使用预训练的语言模型来获取单词的词向量。对于句子P,Q来说,得到这两个句子中每个单词的词向量。接下来我们分别将其输入到双向GRU得到输出\(h_{t}^{q} = [ \xrightarrow [h_{t}^{q}] , \xleftarrow[h_{t}^{q}] ]\)以及\(h_{t}^{p} = [ \xrightarrow [h_{t}^{p}] , \xleftarrow[h_{t}^{p}] ]\) - 多方式attention匹配层
这一层为整体逻辑的核心层,其中attention的方式包括四种,分别是Concat Attention、Bilinear Attention、Dot Attention、Minus Attention,接下来,我们罗列出每一种attention相应的公式。
![]()
我们以Concat Attention方式进行讲解,\(h_{t}^{p}\)表示\(t\)时刻p的输出,我们将这个输出乘以一个\(W_{c}^{2}\)接着加上q中第\(j\)个单词输出乘以\(W_{c}^{1}\)的结果,在外层加上一个tanh激活函数,再乘以\(v_{c}^{T}\)得到q的第j个单词的输出\(s_{j}^{t}\),当我们得到q中所有单词的\(s_{j}^{t}\)后,进行一个softmax操作,得到\(\alpha_{i}^{t}\),将结果加在\(h_{t}^{q}\)上,得到结果\(q_{t}^{c}\)。其他几种方式得到类似的结果。 - 聚合层
聚合层的作用是将上一层多种方式得到的输出进行合并
![]()
- 预测输出层
将上一层得到的结果进行组合输出。

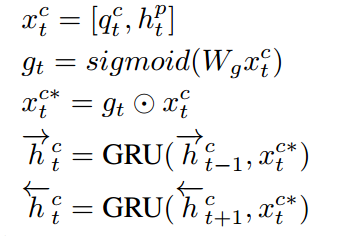
8、aNMM
aNMM(Attention-Based Neural Matching Model)是由Liu Yang[8]等人提出的一种方法,其主要创新点是应用了一个Value-shared Weighting的方式将变长的矩阵转换成固定维度的矩阵,其整体逻辑结构如下图所示

主要部分有word embedding,QA Matching Matrix,Value-shared Weighting,Question Attention Network四个部分,接下来我们一一进行讲解
- word embedding
首先,我们获取Q,A的单词的词向量,这里论文中用的方式是word2vec。假设Q中有M个单词,A中有N个单词,向量维度为D,则我们会得到两个矩阵[M,D],[N,D]。 - QA Matching Matrix
这一步我们得到上述两个矩阵相乘的结果矩阵,维度为[M,N],其中第\(i\)行第\(j\)列表示Q中第\(j\)个单词和A中第\(j\)个单词的词向量进行cosin余弦操作。 - Value-shared Weighting
由于A是变长的序列,所以这里的N是变长的,如果我们想把向量输出到固定维度,传统的做法是利用CNN进行卷积操作,得到固定维度向量。论文中提出了一种新的方法,即由于cosin余弦值的范围是在[-1,1]那么我们可以将其以0.1进行分割,分成21份,[-1,-0.9),[-0.9,-0.8).....[0.9,1),[1]。这样,我们建立一个参数个数为21的向量,这样,对于其中一个值为0.85,我们就可以用[0.8,0.9)的这个权值和0.85进行相乘操作,这个输出的维度我们可以固定,这一部分的结构图如下所示。图中的21变为了3。
![]()
- Question Attention Network
图中得到的固定维度的输出,图中为4,我们将这4个值进行相加并利用sigmoid函数将进行激活,并作用到Q向量上,加上一个softmax,输出层利用一个两个节点表示相关与否,并将上一层与这一层进行一个全连接操作。

[2]Yang Liu(2016)Learning Natural Language Inference using Bidirectional LSTM model and Inner-Attention
[3]Cicero dos Santos(2016)Attentive Pooling Networks.
[4]Guoyin Wang(2018)Joint Embedding of Words and Labels for Text Classification.
[5]Seonhoon Kim(2018)Semantic Sentence Matching with Densely-connected Recurrent and Co-attentive Information
[6]Wenpeng Yin(2018)ABCNN: Attention-Based Convolutional Neural Network for Modeling Sentence Pairs
[7]Chuanqi Tan.Multiway Attention Networks for Modeling Sentence Pairs
[8]Liu Yang(2019)aNMM: Ranking Short Answer Texts with Attention-Based Neural Matching Model.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号