Linux多线程编程
——本文一个例子展开,介绍Linux下面线程的操作、多线程的同步和互斥。
前言
线程?为什么有了进程还需要线程呢,他们有什么区别?使用线程有什么优势呢?还有多线程编程的一些细节问题,如线程之间怎样同步、互斥,这些东西将在本文中介绍。下面是一道面试题:
是否熟悉POSIX多线程编程技术?如熟悉,编写程序完成如下功能: 1)有一int型全局变量g_Flag初始值为0; 2) 在主线称中起动线程1,打印“this is thread1”,并将g_Flag设置为1 3) 在主线称中启动线程2,打印“this is thread2”,并将g_Flag设置为2 4) 线程序1需要在线程2退出后才能退出 5) 主线程在检测到g_Flag从1变为2,或者从2变为1的时候退出
我们带着这题开始这篇文章,结束之后,大家就都会做了。本文的框架如下:
- 1、进程与线程
- 2、使用线程的理由
- 3、有关线程操作的函数
- 4、线程之间的互斥
- 5、线程之间的同步
- 6、试题最终代码
1、进程与线程
进程是程序执行时的一个实例,即它是程序已经执行到何种程度的数据结构的汇集。从内核的观点看,进程的目的就是担当分配系统资源(CPU时间、内存等)的基本单位。线程是进程的一个执行流,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。一个进程由几个线程组成(拥有很多相对独立的执行流的用户程序共享应用程序的大部分数据结构),线程与同属一个进程的其他的线程共享进程所拥有的全部资源。
"进程——资源分配的最小单位,线程——程序执行的最小单位"
进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其它进程产生影响,而线程只是一个进程中的不同执行路径。线程有自己的堆栈和局部变量,但线程没有单独的地址空间,一个线程死掉就等于整个进程死掉,所以多进程的程序要比多线程的程序健壮,但在进程切换时,耗费资源较大,效率要差一些。但对于一些要求同时进行并且又要共享某些变量的并发操作,只能用线程,不能用进程。
2、使用线程的理由
从上面我们知道了进程与线程的区别,其实这些区别也就是我们使用线程的理由。总的来说就是:进程有独立的地址空间,线程没有单独的地址空间(同一进程内的线程共享进程的地址空间)。
使用多线程的理由之一是和进程相比,它是一种非常"节俭"的多任务操作方式。我们知道,在Linux系统下,启动一个新的进程必须分配给它独立的地址空间,建立众多的数据表来维护它的代码段、堆栈段和数据段,这是一种"昂贵"的多任务工作方式。而运行于一个进程中的多个线程,它们彼此之间使用相同的地址空间,共享大部分数据,启动一个线程所花费的空间远远小于启动一个进程所花费的空间,而且,线程间彼此切换所需的时间也远远小于进程间切换所需要的时间。据统计,总的说来,一个进程的开销大约是一个线程开销的30倍左右,当然,在具体的系统上,这个数据可能会有较大的区别。
使用多线程的理由之二是线程间方便的通信机制。对不同进程来说,它们具有独立的数据空间,要进行数据的传递只能通过通信的方式进行,这种方式不仅费时,而且很不方便。线程则不然,由于同一进程下的线程之间共享数据空间,所以一个线程的数据可以直接为其它线程所用,这不仅快捷,而且方便。当然,数据的共享也带来其他一些问题,有的变量不能同时被两个线程所修改,有的子程序中声明为static的数据更有可能给多线程程序带来灾难性的打击,这些正是编写多线程程序时最需要注意的地方。
除了以上所说的优点外,不和进程比较,多线程程序作为一种多任务、并发的工作方式,当然有以下的优点:
- 提高应用程序响应。这对图形界面的程序尤其有意义,当一个操作耗时很长时,整个系统都会等待这个操作,此时程序不会响应键盘、鼠标、菜单的操作,而使用多线程技术,将耗时长的操作(time consuming)置于一个新的线程,可以避免这种尴尬的情况。
- 使多CPU系统更加有效。操作系统会保证当线程数不大于CPU数目时,不同的线程运行于不同的CPU上。
- 改善程序结构。一个既长又复杂的进程可以考虑分为多个线程,成为几个独立或半独立的运行部分,这样的程序会利于理解和修改。
从函数调用上来说,进程创建使用fork()操作;线程创建使用clone()操作。Richard Stevens大师这样说过:
fork is expensive. Memory is copied from the parent to the child, all descriptors are duplicated in the child, and so on. Current implementations use a technique called copy-on-write, which avoids a copy of the parent's data space to the child until the child needs its own copy. But, regardless of this optimization, fork is expensive.
IPC is required to pass information between the parent and child after the fork. Passing information from the parent to the child before the fork is easy, since the child starts with a copy of the parent's data space and with a copy of all the parent's descriptors. But, returning information from the child to the parent takes more work.
Threads help with both problems. Threads are sometimes called lightweight processes since a thread is "lighter weight" than a process. That is, thread creation can be 10~100 times faster than process creation.
All threads within a process share the same global memory. This makes the sharing of information easy between the threads, but along with this simplicity comes the problem of synchronization.
3、有关线程操作的函数
#include <pthread.h> int pthread_create(pthread_t *tid, const pthread_attr_t *attr, void *(*func) (void *), void *arg); int pthread_join (pthread_t tid, void ** status); pthread_t pthread_self (void); int pthread_detach (pthread_t tid); void pthread_exit (void *status);
pthread_create用于创建一个线程,成功返回0,否则返回Exxx(为正数)。
pthread_t *tid:线程id的类型为pthread_t,通常为无符号长整型unsigned long int,当调用pthread_create成功时,通过*tid指针返回。
const pthread_attr_t *attr:指定创建线程的属性,如线程优先级、初始栈大小、是否为守护进程等。可以使用NULL来使用默认值,通常情况下我们都是使用默认值。
void *(*func) (void *):函数指针func,指定当新的线程创建之后,将执行的函数。
void *arg:线程将执行的函数的参数。如果想传递多个参数,请将它们封装在一个结构体中。
pthread_join用于等待某个线程退出,成功返回0,否则返回Exxx(为正数)。
pthread_t tid:指定要等待的线程ID
void ** status:如果不为NULL,那么线程的返回值存储在status指向的空间中(这就是为什么status是二级指针的原因!这种才参数也称为“值-结果”参数)。
pthread_self用于返回当前线程的ID。
pthread_detach用于是指定线程变为分离状态,就像进程脱离终端而变为后台进程类似。成功返回0,否则返回Exxx(为正数)。变为分离状态的线程,如果线程退出,它的所有资源将全部释放。而如果不是分离状态,线程必须保留它的线程ID,退出状态直到其它线程对它调用了pthread_join。
进程也是类似,这也是当我们打开进程管理器的时候,发现有很多僵死进程的原因!也是为什么一定要有僵死这个进程状态。
pthread_exit用于终止线程,可以指定返回值,以便其他线程通过pthread_join函数获取该线程的返回值。
void *status:指针线程终止的返回值。
知道了这些函数之后,我们试图来完成本文一开始的问题:
1)有一int型全局变量g_Flag初始值为0; 2)在主线称中起动线程1,打印“this is thread1”,并将g_Flag设置为1 3)在主线称中启动线程2,打印“this is thread2”,并将g_Flag设置为2 4)线程序1需要在线程2退出后才能退出
这4点很简单嘛!!!不就是调用pthread_create创建线程,然后在thread1中等待thread2结束。
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>
int g_flag = 0;
void* thread1(void*);
void* thread2(void*);
int main(int argc, char **argv)
{
printf("enter main\n");
pthread_t tid1,tid2;
if(pthread_create(&tid2, NULL, thread2, NULL) != 0)
{
printf("Create thread error!\n");
exit(1);
}
if(pthread_create(&tid1, NULL, thread1, &tid2) != 0)
{
printf("Create thread error!\n");
exit(1);
}
sleep(3);
printf("leave main\n");
exit(0);
}
void* thread1(void *arg)
{
printf("enter thread1\n");
printf("this is thread1, g_flag:%d, thread1 id is %lu\n", g_flag, pthread_self());
g_flag = 1;
printf("this is thread1, g_flag:%d, thread1 id is %lu\n", g_flag, pthread_self());
pthread_join(*(pthread_t *)arg, NULL);
printf("leave thread1\n");
pthread_exit(0);
}
void* thread2(void *arg)
{
printf("enter thread2\n");
printf("this is thread2, g_flag:%d, thread2 id is %lu\n", g_flag, pthread_self());
g_flag = 2;
printf("this is thread1, g_flag:%d, thread2 id is %lu\n", g_flag, pthread_self());
sleep(1);
printf("leave thread2\n");
pthread_exit(0);
}
对代码进行编译:
$ gcc -Wall -pthread -o test test.c
大家肯定已经注意到了,我们在线程函数thread1()、thread2()执行完之前都调用了pthread_exit。如果我是调用exit()又或者是return会怎样呢?自己动手试试吧! pthread_exit()用于线程退出,可以指定返回值,以便其他线程通过pthread_join()函数获取该线程的返回值。 return是函数返回,只有线程函数return,线程才会退出。 exit是进程退出,如果在线程函数中调用exit,进程中的所有函数都会退出!
4、线程之间的互斥
线程共享进程的资源和地址空间,对这些资源进行操作时,必须考虑线程间同步与互斥问题
- 互斥锁
- 信号量
- 条件变量
互斥锁
用简单的加锁方法控制对共享资源的原子操作
只有两种状态: 上锁、解锁
可把互斥锁看作某种意义上的全局变量
在同一时刻只能有一个线程掌握某个互斥锁,拥有上锁状态的线程能够对共享资源进行操作
若其他线程希望上锁一个已经被上锁的互斥锁,则该线程就会挂起,直到上锁的线程释放掉互斥锁为止
互斥锁保证让每个线程对共享资源按顺序进行原子操作
互斥锁分类
区别在于其他未占有互斥锁的线程在希望得到互斥锁时是否需要阻塞等待
快速互斥锁
•调用线程会阻塞直至拥有互斥锁的线程解锁为止
•默认为快速互斥锁
检错互斥锁
•为快速互斥锁的非阻塞版本,它会立即返回并返回一个错误信息
互斥锁主要包括下面的基本函数:
互斥锁初始化:pthread_mutex_init() 互斥锁上锁:pthread_mutex_lock() 互斥锁判断上锁:pthread_mutex_trylock() 互斥锁解锁:pthread_mutex_unlock() 消除互斥锁:pthread_mutex_destroy()

#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>//sleep()函数使用这个头文件
#define THREAD_NUM 3
#define REPEAT_TIMES 5
#define DELAY 4
pthread_mutex_t mutex;
void* th_func(void *arg);
int main(int argc, char *argv[])
{
pthread_t th_tid[THREAD_NUM];
void *ret;
srand((int)time(0));
pthread_mutex_init(&mutex, NULL);
for (int i = 0; i < THREAD_NUM; ++i)
{
if (pthread_create(&th_tid[i], NULL, th_func, (void*)i) != 0)
{
printf("Create thread %d error!\n", i);
exit(1);
}
else
{
printf("Create thread %d success!\n", i);
}
}
for (int i = 0; i < THREAD_NUM; ++i)
{
if (pthread_join(th_tid[i], &ret) != 0)
{
printf("Join thread %d error\n", i);
exit(1);
}
else
{
printf("Join thread %d success\n", i);
}
}//for
pthread_mutex_destroy(&mutex);
return 0;
}
void* th_func(void *arg)
{
int th_num = (int)arg;
int delay_time;
if (pthread_mutex_lock(&mutex) != 0)
{
printf("thread %d lock failed!\n", th_num);
pthread_exit(NULL);
}
printf("thread %d is starting\n", th_num);
for (int i = 0; i < REPEAT_TIMES; ++i)
{
delay_time = (int)(DELAY * (rand() / (double)RAND_MAX)) + 1;//1~4的随机数
sleep(delay_time);
printf("\tthread %d: job %d delay =%d.\n", th_num, i, delay_time);
}
printf("thread %d is exiting.\n", th_num);
pthread_mutex_unlock(&mutex);
pthread_exit(NULL);
}
执行结果:
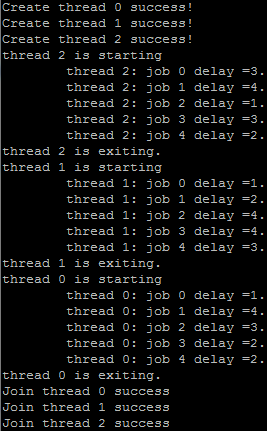
可以看到,这三个线程互斥的访问临界段代码。
信号量
- PV原子操作:对整数计数器信号量sem的操作
- 一次P操作使sem减一,而一次V操作使sem加一
- –在执行完P原子操作之后,当信号量sem的值大于等于零时,该进程(或线程)具有公共资源的访问权限
- –在执行完P原子操作之后,当信号量sem的值小于零时,该进程(或线程)就将阻塞直到信号量sem的值大于等于0为止
- 互斥,几个线程只设置一个信号量sem。
- 同步,会设置多个信号量,安排不同初值来实现它们之间的顺序执行。同步的时候,有几类线程,则用几个信号量。
信号量函数 sem_init() 创建一个信号量,并初始化它 sem_wait()和sem_trywait(): P操作,在信号量大于零时将信号量的值减一 •区别: 若信号量小于零时,sem_wait()将会阻塞线程,sem_trywait()则会立即返回 sem_post(): V操作,将信号量的值加一同时发出信号来唤醒等待的线程 sem_getvalue(): 得到信号量的值 sem_destroy(): 删除信号量


实现一个子线程的结束方式,线程号依次递减,直到最小,然后在结束最大的线程。类似一个环的方式结束线程。
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>
#include <semaphore.h>
#define THREAD_NUM 3
#define REPEAT_TIMES 5
#define DELAY 4
sem_t sem[THREAD_NUM];
void *th_func(void *arg);
int main(int argc, char *argv[])
{
pthread_t th_tid[THREAD_NUM];
void *ret;
srand((int)time(0));
for (int i = 0; i < THREAD_NUM - 1; ++i)
{
sem_init(&sem[i], 0 ,0);
}
sem_init(&sem[2], 0, 1);
for (int i = 0; i < THREAD_NUM; ++i)
{
if (pthread_create(&th_tid[i], NULL, th_func, (void*)i) != 0)
{
printf("Create thread %d error!\n", i);
exit(1);
}
else
{
printf("Create thread %d success!\n", i);
}
}
for (int i = 0; i < THREAD_NUM; ++i)
{
if (pthread_join(th_tid[i], &ret) != 0)
{
printf("Join thread %d error!\n", i);
exit(1);
}
else
{
printf("Join thread %d success!\n", i);
}
}
for (int i = 0; i < THREAD_NUM; ++i)
{
sem_destroy(&sem[i]);
}
return 0;
}
void* th_func(void *arg)
{
int th_num = (int)arg;
int delay_time;
sem_wait(&sem[th_num]);
printf("thread %d is starting.\n", th_num);
for (int i = 0; i < REPEAT_TIMES; ++i)
{
delay_time = (int)(DELAY * (rand() / (double)RAND_MAX)) + 1;
sleep(delay_time);
printf("\tthread %d : job %d delay = %d.\n", th_num, i, delay_time);
}
printf("thread %d is exiting.\n", th_num);
sem_post(&sem[(th_num + THREAD_NUM - 1) % THREAD_NUM]);
pthread_exit(0);
}
代码执行的结果:
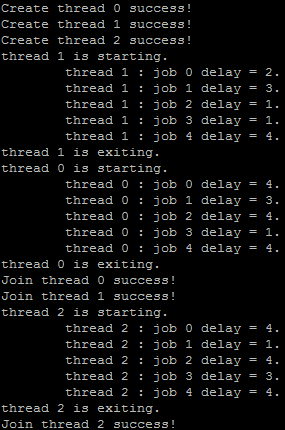
从执行结果中可以看出,main第一次被阻塞0号线程的join中,等0号线程结束后,又被阻塞在1号线程的join中,1号线程结束后,又被阻塞在2号线程的join上。
回到开始提出的问题,我们可以看到,上面的代码似乎很好的解决了问题的前面4点要求,其实不然!!!因为g_flag是一个全局变量,线程thread1和thread2可以同时对它进行操作,需要对它进行加锁保护,thread1和thread2要互斥访问才行。下面我们就介绍如何加锁保护——互斥锁。
互斥锁: 使用互斥锁(互斥)可以使线程按顺序执行。通常,互斥锁通过确保一次只有一个线程执行代码的临界段来同步多个线程。互斥锁还可以保护单线程代码。
互斥锁的相关操作函数如下:
#include <pthread.h> int pthread_mutex_lock(pthread_mutex_t * mptr); int pthread_mutex_unlock(pthread_mutex_t * mptr); //Both return: 0 if OK, positive Exxx value on error
在对临界资源进行操作之前需要pthread_mutex_lock先加锁,操作完之后pthread_mutex_unlock再解锁。而且在这之前需要声明一个pthread_mutex_t类型的变量,用作前面两个函数的参数。具体代码见第5节。
5、线程之间的同步
第5点——主线程在检测到g_Flag从1变为2,或者从2变为1的时候退出。就需要用到线程同步技术!线程同步需要条件变量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号