[线程同步互斥]多线程模型
线程的实现方式
线程的实现可以分为两类:用户级线程(User-LevelThread, ULT)和内核级线程(Kemel-LevelThread, KLT)。内核级线程又称为内核支持的线程。
在用户级线程中,有关线程管理的所有工作都由应用程序完成,内核意识不到线程的存在。应用程序可以通过使用线程库设计成多线程程序。通常,应用程序从单线程起始,在该线程中开始运行,在其运行的任何时刻,可以通过调用线程库中的派生例程创建一个在相同进程中运行的新线程。图2-2(a)说明了用户级线程的实现方式。
在内核级线程中,线程管理的所有工作由内核完成,应用程序没有进行线程管理的代码,只有一个到内核级线程的编程接口。内核为进程及其内部的每个线程维护上下文信息,调度也是在内核基于线程架构的基础上完成。图2-2(b)说明了内核级线程的实现方式。
在一些系统中,使用组合方式的多线程实现。线程创建完全在用户空间中完成,线程的调度和同步也在应用程序中进行。一个应用程序中的多个用户级线程被映射到一些(小于或等于用户级线程的数目)内核级线程上。图2-2(c)说明了用户级与内核级的组合实现方式。

多线程模型
用户线程:受内核支持,而无需内核管理
内核线程:直接由操作系统支持和管理
在用户线程和内核线程之间必然存在一种联系。
用户线程和内核线程有三种关系:多对一,一对一,多对多。
有些系统同时支持用户线程和内核线程由此产生了不同的多线程模型,即实现用户级线程和内核级线程的连接方式。
1) 多对一模型
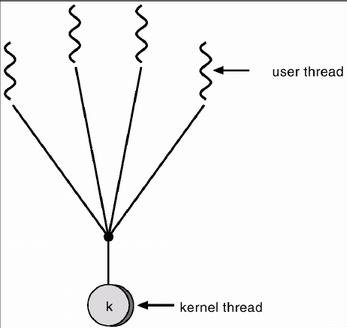
将多个用户级线程映射到一个内核级线程,线程管理在用户空间完成。
此模式中,用户级线程对操作系统不可见(即透明)。
优点:线程管理是在用户空间进行的,因而效率比较高。
缺点:当一个线程在使用内核服务时被阻塞,那么整个进程都会被阻塞;多个线程不能并行地运行在多处理机上。
将多个用户级线程映射到一个内核线程。线程管理在用户空间进行,效率较高。 但是如果一个线程执行了阻塞系统调用,那么整个进程会阻塞。 而且,任何时刻只有一个线程使用CPU,多个线程也不能运行在多CPU上。 什么意思呢?先不考虑线程,内核眼里只有进程,而且是重量级进程。而这其中的进程有些是多线程的。 比如现在有3个进程A,B,C。其中A,B是单线程,C有3个线程。 那么,CPU是在A,B,C之间平分的,比如每个进程用5秒,轮到C了,C里面的3个线程分享这个5秒的时间片。
2) 一对一模型

将每个用户级线程映射到一个内核级线程。
优点:当一个线程被阻塞后,允许另一个线程继续执行,所以并发能力较强。
缺点:每创建一个用户级线程都需要创建一个内核级线程与其对应,这样创建线程的开销比较大,会影响到应用程序的性能。
将每个用户线程映射到一个内核线程。该模型在一个线程执行阻塞系统调用时,能允许另一个线程继续执行。 它能允许多个线程并行的运行在多处理器系统上。 缺点是一个用户线程就对应着一个内核线程,而且这种线程在创建和切换时开销较大。而且总的线程数是受限制的。 这种模型是什么模型呢? 还是拿三个进程A,B,C举例子。C有三个线程,C1,C2,C3。在一对一的模型中,CPU看到的是A, B, C1,C2,C3这样五个东西, 这里进程C占了3/5的CPU。这不是和进程一样吗?实际上就是进程,这样的线程称为轻量级进程。(内核管理的用户级线程) Linux里面就是这种模型。Linux的clone函数在创建进程时有很多参数,可以选择共享地址空间等。比如下面4个参数: CLONE_FS 共享文件系统信息 CLONE_SIGHAND 共享信号处理程序 CLONE_VM 共享内存空间 CLONE_FILES 共享打开文件列表 Linux里的线程就是通过指定这几个参数来创建的。
一对一的线程模型,一个用户级线程对应一个内核级线程,但是内核级线程不一定有对应的用户级线程。Window的CreateThread和_beginthreadex都是创建的一对一的线程模型。
3) 多对多模型
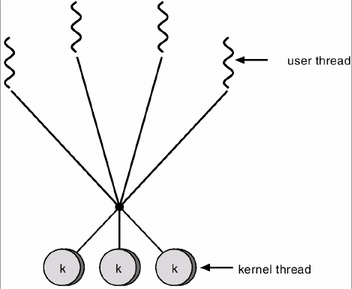
将 n 个用户级线程映射到 m 个内核级线程上,要求 m <= n。
特点:在多对一模型和一对一模型中取了个折中,克服了多对一模型的并发度不高的缺点,又克服了一对一模型的一个用户进程占用太多内核级线程,开销太大的缺点。又拥有多对一模型和一对一模型各自的优点,可谓集两者之所长。
还是用A, B, C的例子,这次C有4个线程,假设对应2个内核线程,CPU看到的是这样的东西。A, B , C1, C2。 而实际C的四个线程是c1,c2,c3,c4。那么轮到C1了,4个人可以得到CPU的执行,但是得一个一个的,轮到C2了,4个人又可以轮流执行。 假如c1在C1阶段将CPU惹生气了,需要买点礼物给CPU,CPU不把气撒在c1上,因为它不知道c1,它只知道C1,因此CPU生C1的气, 等C1给我礼物我再让你执行,C1里面实际上是c1要去买礼物,但是这样就连累了c2,c3,c4。不过,咱们是多对多,C1被CPU抛弃了, 还有C2呢,于是c2,c3,c4就在C2阶段得到CPU执行了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号