
阅记-纵向优化-《多流水线 循环优化》循环展开|打满流水线宽度|SIMD
目录
HPC1 计算CPU频率
文章 高性能计算(HPC)系列之二:深入基础软件开发第一篇
方法:执行时长/周期数 约等于 1/lscpu 查看到的频率
[1/2] 固定cpu运行频率
我的测试环境cpu频率管理是intel_pstate:
$ lscpu | grep -i hz
Model name: Intel(R) Core(TM) i5-10500 CPU @ 3.10GHz
CPU max MHz: 4500.0000
CPU min MHz: 800.0000
$ echo 1 | sudo tee /sys/devices/system/cpu/intel_pstate/no_turbo
1
$ echo 100 | sudo tee /sys/devices/system/cpu/intel_pstate/min_perf_pct
100
$ echo 100 | sudo tee /sys/devices/system/cpu/intel_pstate/max_perf_pct
100
查看设置结果:
$ sudo cpupower -c 0 frequency-info
...
current policy: frequency should be within 3.10 GHz and 3.10 GHz.
...
$ grep "cpu MHz" /proc/cpuinfo
...
cpu MHz : 3100.000
cpu MHz : 3100.665
对应执行一条指令耗时:
(1*1000*1000*1000)ns/(3.1*1000*1000*1000)Hz = 1/3.1ns
[2/2] 实验和实验结果
代码:
inc1.c
#include <stdlib.h>
#include <stdint.h>
#include <stdio.h>
#include <sys/time.h>
#if defined(__x86_64__)
#include <x86intrin.h>
#else
# error "Not support"
#endif
#define MY_CPU_GHZ (3.1)
#define TIME_PER_INST_NS (1/MY_CPU_GHZ) // (1*1000*1000*1000)ns/(3.1*1000*1000*1000)Hz = 1/3.1ns
#define TIME_PER_INST_MS (1/(MY_CPU_GHZ*1000*1000))
#define delta_timeval_ms(t1, t2) ((t2.tv_sec - t1.tv_sec) * 1000 + ((float)t2.tv_usec - (float)t1.tv_usec) / 1000)
int work(int limit)
{
register int k = 0, i = 0, limit_r = limit;
uint64_t begin = 0, end = 0;
unsigned int ui;
struct timeval tv1, tv2;
gettimeofday(&tv1, 0);
begin = __rdtscp(&ui);
for (; i < limit_r; i++) {
k = k + 1;
}
end = __rdtscp(&ui);
gettimeofday(&tv2, 0);
printf("LOOP: %i\n", limit);
printf("TSC : %ld(=%lfms, Hz:%.1fGHz)\n", end - begin, (end - begin)*TIME_PER_INST_MS, MY_CPU_GHZ);
printf("%ld.%ld - %ld.%ld = %f\n", tv2.tv_sec, tv2.tv_usec / 1000, tv1.tv_sec, tv1.tv_usec / 1000,
delta_timeval_ms(tv1, tv2));
return k;
}
int main(int argc, char *argv[])
{
work(100000000);
return 0;
}
执行结果:
$ gcc -g -O0 inc1.c -o app_inc1
$ taskset -c 0 ./app_inc1
LOOP: 100000000
TSC : 100731034(=32.493882ms, Hz:3.1GHz)
1725688663.855 - 1725688663.822 = 32.535999
HPC2 优化循环
拆分成两条加法流水线(循环减半)
inc2.c:
...
#include <stdlib.h>
#include <stdint.h>
#include <stdio.h>
#include <sys/time.h>
#if defined(__x86_64__)
#include <x86intrin.h>
#else
# error "Not support"
#endif
#define MY_CPU_GHZ (3.1)
#define TIME_PER_INST_NS (1/MY_CPU_GHZ) // (1*1000*1000*1000)ns/(3.1*1000*1000*1000)Hz = 1/3.1ns
#define TIME_PER_INST_MS (1/(MY_CPU_GHZ*1000*1000))
#define delta_timeval_ms(t1, t2) ((t2.tv_sec - t1.tv_sec) * 1000 + ((float)t2.tv_usec - (float)t1.tv_usec) / 1000)
int work(int limit)
{
register int k1 = 0, k2 = 0, i, j, limit_r = limit;
uint64_t begin = 0, end = 0;
unsigned int ui;
struct timeval tv1, tv2;
gettimeofday(&tv1, 0);
begin = __rdtscp(&ui);
for (i = 0, j = 1; i < limit_r; i += 2, j += 2) {
k1 += i;
k2 += j;
}
k1 += k2;
end = __rdtscp(&ui);
gettimeofday(&tv2, 0);
printf("LOOP: %i\n", limit);
printf("TSC : %ld(=%lfms, Hz:%.1fGHz)\n", end - begin, (end - begin)*TIME_PER_INST_MS, MY_CPU_GHZ);
printf("%ld.%ld - %ld.%ld = %f\n", tv2.tv_sec, tv2.tv_usec / 1000, tv1.tv_sec, tv1.tv_usec / 1000,
delta_timeval_ms(tv1, tv2));
return k1;
}
int main(int argc, char *argv[])
{
work(100000000);
return 0;
}
实验结果:
$ taskset -c 0 ./app_inc2
LOOP: 100000000
TSC : 90521095(=29.200353ms, Hz:3.1GHz)
1725641969.893 - 1725641969.864 = 29.239000
实验结果变化分析
指令数变化(汇编代码)

测试代码从3条增加至5条(多了k2+=j, j+=2)
循环次数减半
sudo perf stat -C 0 taskset -c 0 /data/products/hpc001/app_inc1
sudo perf stat -C 0 taskset -c 0 /data/products/hpc001/app_inc2
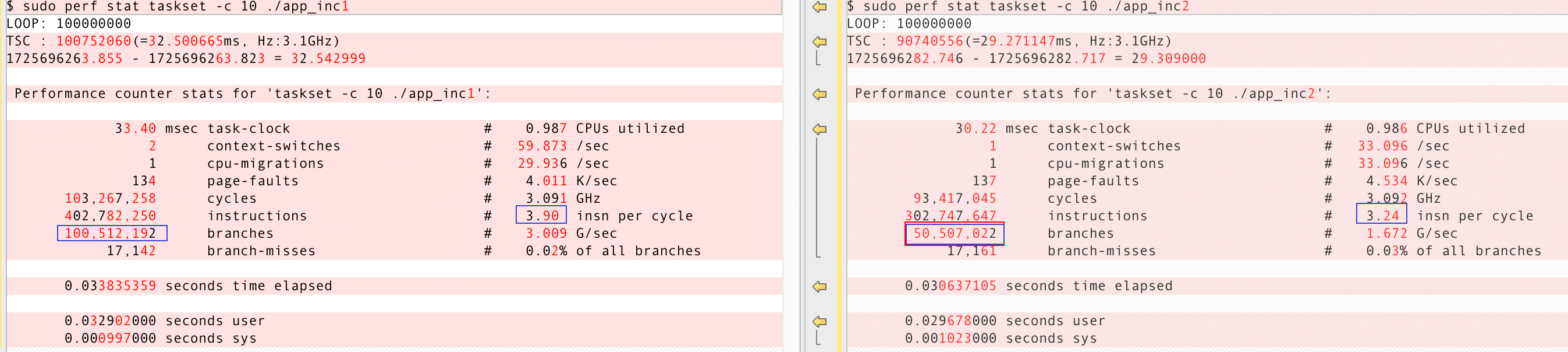
HPC3 使用SIMD指令
点击查看代码
#include <stdlib.h>
#include <stdint.h>
#include <stdio.h>
#include <sys/time.h>
#if defined(__x86_64__)
#include <x86intrin.h>
#else
# error "Not support"
#endif
#include <immintrin.h>
#define MY_CPU_GHZ (3.1)
#define TIME_PER_INST_NS (1/MY_CPU_GHZ) // (1*1000*1000*1000)ns/(3.1*1000*1000*1000)Hz = 1/3.1ns
#define TIME_PER_INST_MS (1/(MY_CPU_GHZ*1000*1000))
#define delta_timeval_ms(t1, t2) ((t2.tv_sec - t1.tv_sec) * 1000 + ((float)t2.tv_usec - (float)t1.tv_usec) / 1000)
int work(int limit)
{
register int i = 0, limit_r = limit;
int k = 0;
uint64_t begin = 0, end = 0;
unsigned int ui;
struct timeval tv1, tv2;
// 使用AVX2初始化向量
__m256i sum = _mm256_setzero_si256(); // 将 ymm4 初始化为全 0
__m256i index_vec = _mm256_setr_epi32(0, 1, 2, 3, 4, 5, 6, 7); // ymm2 = {0, 1, 2, 3, 4, 5, 6, 7}
__m256i batch_vec = _mm256_set1_epi32(8); // ymm0 = {8, 8, 8, 8, 8, 8, 8, 8}
gettimeofday(&tv1, 0);
begin = __rdtscp(&ui);
// 使用内联汇编的部分
asm volatile (
// ymm4 初始化为 0 已经在 C 代码中完成
"1: \n\t" // 标签1开始循环
"vpaddd %[vec2], %[vec4], %[vec4] \n\t" // ymm4 = ymm4 + ymm2
"vpaddd %[vec0], %[vec2], %[vec2] \n\t" // ymm2 = ymm2 + ymm0 (即 ymm2每次加8)
"add $8, %[i] \n\t" // i = i + 8
"cmp %[limit], %[i] \n\t" // 判断 i 是否小于 limit
"jl 1b \n\t" // 若 i < limit,则跳回标签1
// 将最终的累加结果存储在 ymm4 中
: [i] "+r" (i), [vec2] "+x" (index_vec), [vec4] "+x" (sum)
: [limit] "r" (limit), [vec0] "x" (batch_vec)
: "cc"
);
end = __rdtscp(&ui);
gettimeofday(&tv2, 0);
// 将 SIMD 结果累加到标量 k
int tmp[8] = { 0 };
_mm256_storeu_si256((__m256i*)tmp, sum);
k = tmp[0] + tmp[1] + tmp[2] + tmp[3] + tmp[4] + tmp[5] + tmp[6] + tmp[7];
printf("LOOP: %i\n", limit);
printf("TSC : %ld(=%lfms, Hz:%.1fGHz)\n", end - begin, (end - begin)*TIME_PER_INST_MS, MY_CPU_GHZ);
printf("%ld.%ld - %ld.%ld = %f\n", tv2.tv_sec, tv2.tv_usec / 1000, tv1.tv_sec, tv1.tv_usec / 1000,
delta_timeval_ms(tv1, tv2));
return k;
}
int main(int argc, char *argv[])
{
work(100000000);
return 0;
}
C语言部分1:
- 初始化ymm0为8个整数8,初始化ymm2为0,1,2,3,4,5,6,7,初始化ymm4为0
内联汇编部分:
- ymm0和ymm2作为输入参数,ymm4作为输入输出型参数
- ymm4 = ymm4 + ymm2
- ymm2 = ymm2 + ymm0
- i = i + 8
- 判断i是否小于limit,是则继续循环
C语言部分2:
- 对ymm4的8个数进行累加,得到累加值
gcc -g -O0 -mavx2 -o app_inc3 inc3.c
[root@localhost test]# taskset -c 0 ./app_inc1
LOOP: 100000000
TSC : 80869340(=29.951607ms, Hz:2.7GHz)
1726664752.455 - 1726664752.416 = 38.508999
sum : 887459712
[root@localhost test]# taskset -c 0 ./app_inc2
LOOP: 100000000
TSC : 71770096(=26.581517ms, Hz:2.7GHz)
1726664754.752 - 1726664754.718 = 34.176998
[root@localhost test]# taskset -c 0 ./app_inc3
LOOP: 100000000
TSC : 12463862(=4.616245ms, Hz:2.7GHz)
1726664757.717 - 1726664757.711 = 5.936000
sum : 887459712
本文来自博客园,作者:LiYanbin,转载请注明原文链接:https://www.cnblogs.com/stellar-liyanbin/p/17966340



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统