
深度学习之超参数调试
前言
以下内容是个人学习之后的感悟,转载请注明出处~
超参数调试
在深度学习中,超参数有很多,比如学习率α、使用momentum或Adam优化算法的参数(β1,β2,ε)、层数layers、不同层隐藏
单元数hidden units、学习率衰退、mini=batch的大小等。其中一些超参数比其他参数重要,其优先级可以分为以下几级,如图,红色
框最优先,橙色次之,紫色再次之,最后没有框住的一般直接取经验值(当然你也可以自己取)。
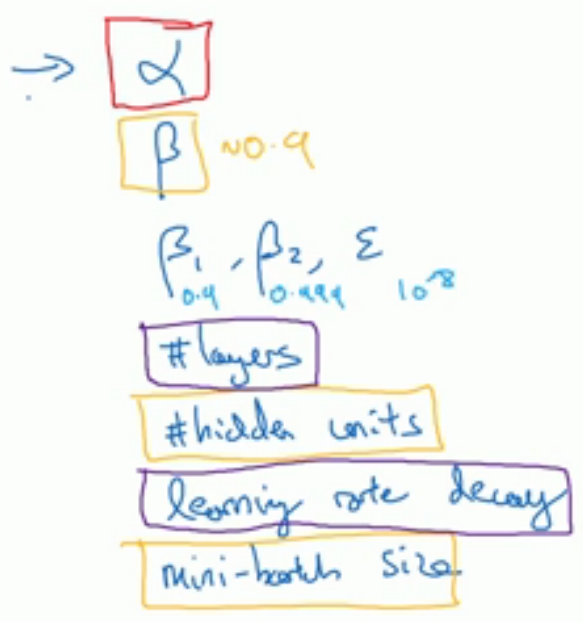
那么如何来调试超参数呢?
以下图的2维超参数为例(即只调两个超参数,当然有时候需要调的超参数很多时,就需要很多维,不便画出)首先可以在一定的范
围内对这两个超参数随机取值(如图中黑点),若发现其中几个黑点的效果最好,则缩小范围(即蓝色方框)进行细化参数,寻找最适合
的超参数。此法从粗略搜索再到精密搜索,可以达到很好的效果。

上面提到的随机取值,并非是在有效值范围内的随机均匀取值,而是选择合适的标尺。比如对于隐藏单元数n和隐藏层数L,如下图所
示,其合适的标尺恰好是在有效范围内均匀取值,可以实现很好的调试效果。

然而,这对某些超参数是不适用的,比如学习率α,其范围在0.0001到1之间,有经验的我们怀疑α有很大可能在0.0001到0.1之间,但
是如果随机均匀取值,那么在0.1到1之间将用去90%的资源,这看上去不对啊,资源没有用在刀刃上。因此,我们需要选择更加合适的标
尺——对数标尺,分别取0.0001、0.001、0.01、0.1、1,这样可以充分利用资源,达到理想的效果。当然,如果你怀疑α是在0.9到0.999之
间,那么(1-α)就在0.1到0.001之间,其实做法是一样的。

有时候,你训练好超参数不久,你的数据在逐渐的改变,意味着之前训练好的超参数不再适用于现今的数据,那么该如何做呢?我们需
要经常照看模型。一般有以下两种方式,第一种是只有一个模型,如下图中左边所示,该模型的代价函数随时间的变化而变化,我们需要不
断调整其超参数,使曲线不上升;第二种就是建许多个模型,如下图中右边所示,每个模型的代价函数随时间的变化而变化,我们只需要挑
当时表现比较好的模型用于预测数据即可。可以看出,在计算量允许的情况下,第二种方式是非常好的。

以上是全部内容,如果有什么地方不对,请在下面留言,谢谢~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号