一文读懂Base64编码
Base64编码
字符对应表
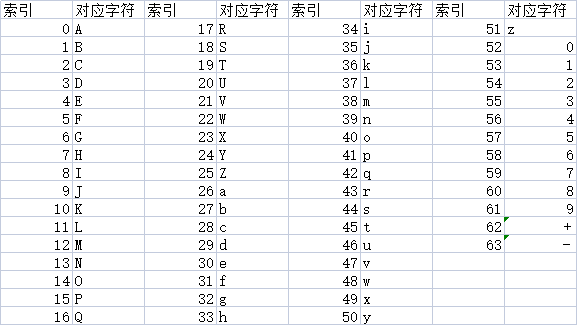
上表就是用来表示Base64,一共64个字符,A-Z,a-z,0-9,+,/(上表打错了),还有=(作为补位)
无论将文件,字符串,还是什么转为Base64,一定是用上表的字符表示。
转换方式是将三个字节分为一个单元,因为一个字节占8位,所以一个单元就是24位,然后将一个单元又分为四个部分,每一部分 是6位,在每个部分前面补00,于是一个单元就变成了32位,也就是4个字节,然后算出每一部分的十进制,再对应Base64字符对应表上面的 符号,一单元的四个部分加起来就是Base64,说得比较抽象,我们用图来说话

如上图我们对字符串"LIU"进行Base64编码,因为刚好为3个字节,所以为一个单元,LIU对应的ASCII码为76,73,85,对应的二进制分别为 01001100,01001001,01010101,然后将其分为四部分并补0后为,00010011,00000100,00100101,00010101,它们所对应的Base64 索引和字符为,19(T) , 4(E) , 37(l) , 21(V) , 所以"LIU"编译后的Base64编码为"TElV"
如果是两个字节

两个字节的情况分为三组,第三组只有四位(1001),这时候要再首尾都加2个0,为(00100100),计算出来是 TEk ,因为只有两个字节,所以第三个用=代替,加上=, 为 TEk=
如果一个字节
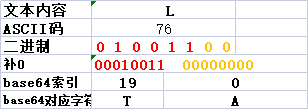
一个字节则分为两组,第二组为00,前面补00,后面补0000,为(00000000),在Base64上面对应A,所以为"TA",因为为一个字节,所以后两个用==代替,为 TA==
汉字转为Base64编码
对于汉字转Base64编码,首先要确定编码方式,又utf-8,utf-16,utf-32,gbk等等,每种编码的汉字对应的Base64是不相同的,比如"刘"的编码方式为utf-8 ,那么用Base64编码后为5YiY,如果编码方式为utf-16,那么经过Base64编码后为/v9SGA==,所以不同的编码方式对应不同的Base64编码, 如果用utf-8编码的文字转为Base64编码,用utf-16对Base64进行解码,那么解码得到的将为乱码。
JAVA API
编码
Base64.getEncoder().encode(byte[] bytes); Base64.getEncoder().encodeToString(byte[] bytes);
and so on
解码
Base64.getDecoder().decode(byte[] bytes); and so on
示例
/** * TODO * * @author 刘牌 * @version 1.0 * @date 2021/9/7 0007 21:25 */ public class Base64Test { public static void main(String[] args) { String str = "LIU"; String s = Base64.getEncoder().encodeToString(str.getBytes(Charset.forName("utf-16"))); System.out.println(s); byte[] bytes = Base64.getDecoder().decode(s.getBytes()); String s1 = new String(bytes, Charset.forName("utf-16")); System.out.println(s1); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号