Thinking in file encoding and decoding?
> General file encoding ways
We most know, computer stores files with binary coding like abc\xe4\xbd\xa0\xe5\xa5\xbd\xef\xbc\x81.
Generally, we do have some ways to encoding a file to solve other character excluding English which can'd be encoding. Like below:
- unicode : At least use 16 bytes.
- utf-8 : A compress set of unicode, use less space to store encoding code.
- GBK : Specific for Chinese words.
- GB2312 : Old version for Chinese words.
- etc.
> How encoding works?
When we see below picture, we could know every coding set is the sub-set of unicode.
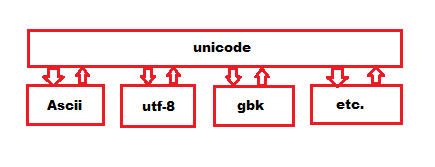
- Every coding set is the sub-set of unicode.
- Every coding set can convert between itself and unicode rather than with the reset of them.
- *Of all the sub-set coding sets, they are based on ASCII code. So for English, there are no difference in using each of them.
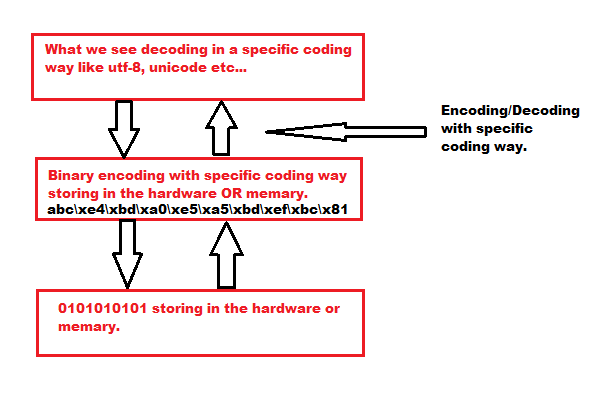
- We must point to a way to encoding/decoding a file.
- Be ware of where is the location(hardware OR memory) regarding the content you are seeing.
> See some examples
When you download a file which are binary code with specific encoding(like utf-8) off a site, you have to use the corresponding decoding set(Here is utf-8) to see the content of it.
Opening a file between the .open('a.txt', encoding='utf-8') method in Python and the opening with pycharm(See the far right-bottom decoding indicator) are the fuck same essentially.
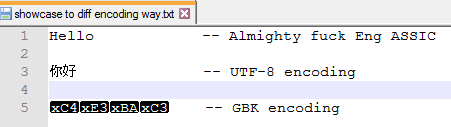
In the notepad++, we can choose different way to encoding/decoding a file.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号