Hadoop API使用 大坑
这几天一直在困扰我 pycurl 版本和本机的版本不符合 他连接又连接的自己自带的版本 与系统不相同 低级也会报错
https://blog.csdn.net/u010910682/article/details/89496550/?ops_request_misc=&request_id=&biz_id=102&utm_term=pycurl7.45.2%20%E6%90%AD%E9%85%8Dlibcurl%E6%98%AF%E4%BB%80%E4%B9%88%E7%89%88%E6%9C%AC&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-1-89496550.142^v86^control,239^v2^insert_chatgpt&spm=1018.2226.3001.4187
搞了半年 可算把这个搞定了 还是用我知道的aconda 再构建一个虚拟的环境 aconda自己可以去搞定 各种因版本产生的问题。
成功导入pycurl,在使用pycurl时 没有很多的使用案例与hadoop集群相关的。唯一一个csdn上面给的也是说明不清楚。 在调用的时候 ,官网没给出具体的用法 csdn又是直接用的官网的api 例子
最主要是这个知乎的博主直接让我原地踏步。
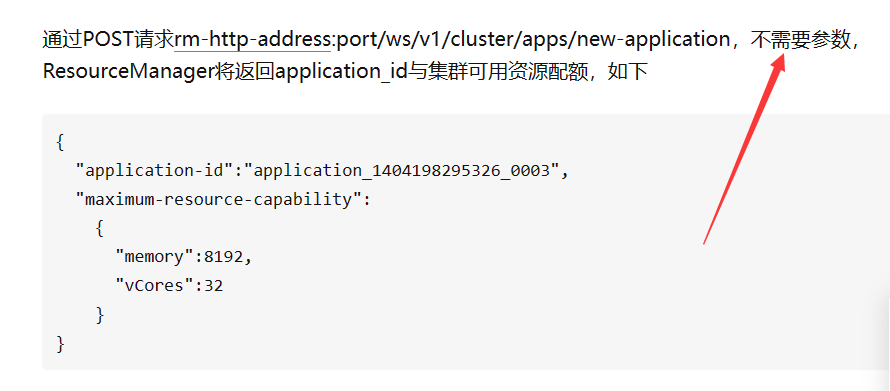
一个不需要参数 一直让我以为 直接就是这个代码上面都不需要换 系统会自动去找。网上也没有相关的东西。我自己测试百度又可以获取状态码,输入这个又是什么都没有,直接报错pycurl错误3.想来想去我把port换了换成8088发现还是错误码3 又把前面rm-http-address 中的http-address换成node1还是错误码3 直接按照正常网站的格式 直接把前面全去掉直接node1:8088/ws/v1/cluster/apps/直接成功获取了状态码200。

网上的相关教程 可谓少之又少基本就这一个
其中这个

是本机的地址替换上去

这个用hadoop的端口号替换上去
即可进行运行最初始的代码
然后问题又来了
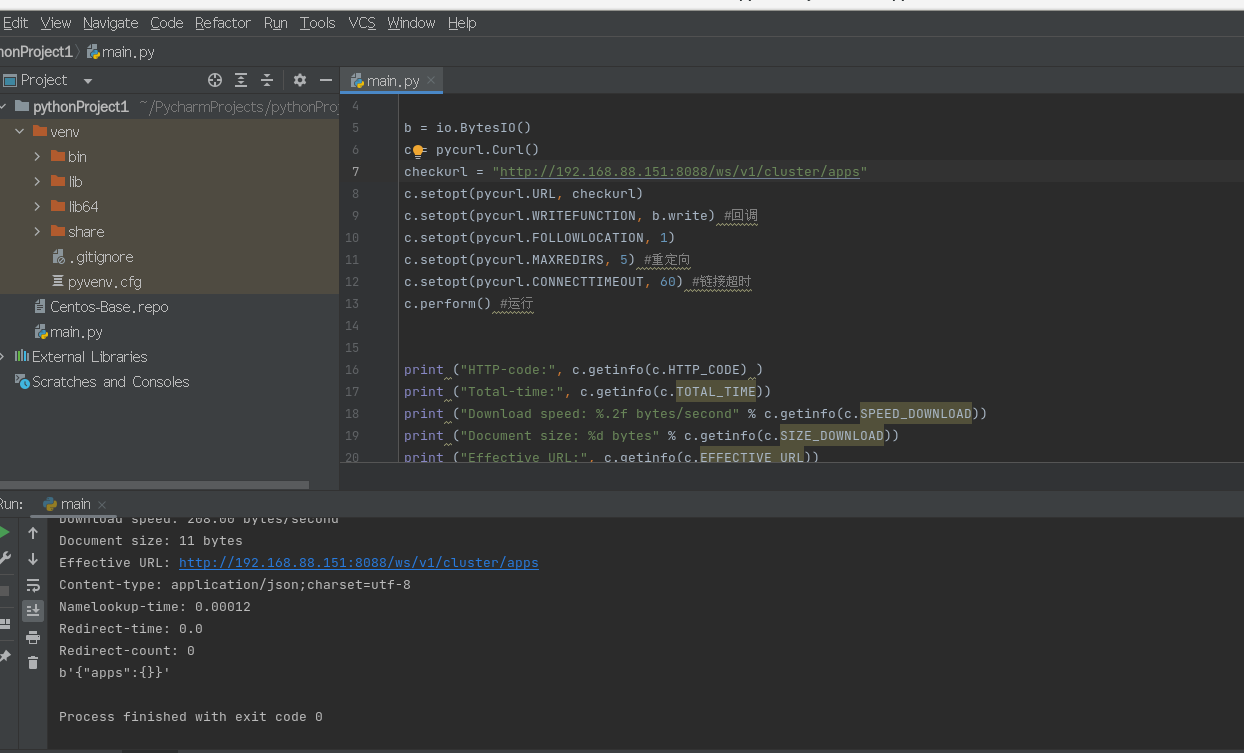
获取的apps json为空 。
让我苦恼很久 按理最少应该也会返回用户名
最后百度 csdn 谷歌 搜了个遍什么都没有 2个小时 我都想放弃了。唯一的能用到的就是hadoop的api说明 又重新从头认真读了一遍 发现。

这个东西他只能读取你当前在队列里面 没有完成的任务

我重新启动三台虚拟机 找到以前运行的大数据项目的代码

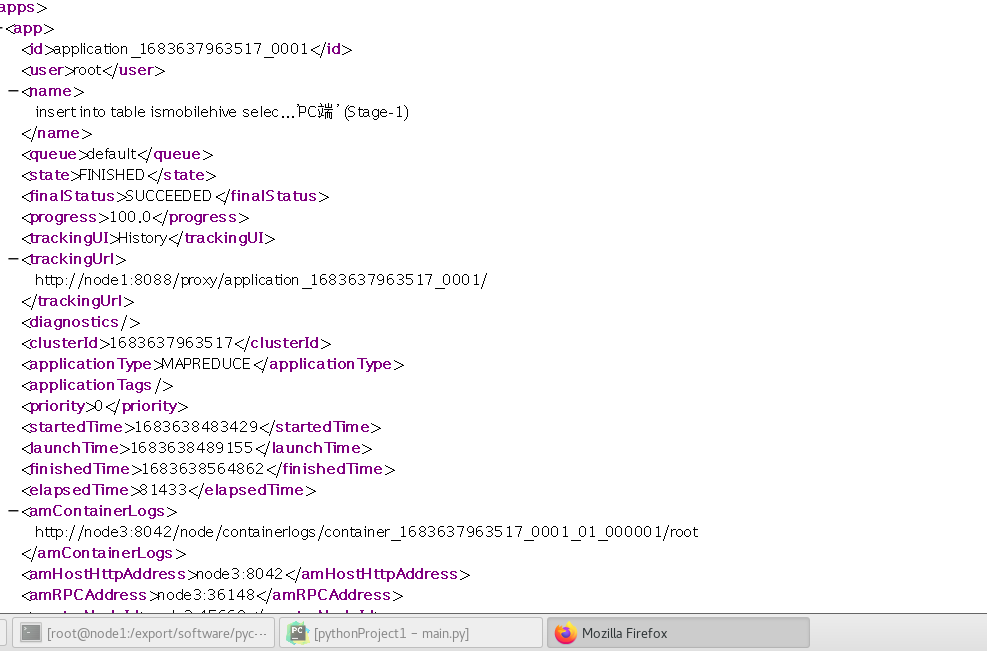
成功读取到了信息
不过在运行虚拟机hadoop集群加上pycharm Navicat 成功直接卡死。
重启后

 浙公网安备 33010602011771号
浙公网安备 33010602011771号