R语言2数据结构
生信技能树R语言部分学习笔记
03 数据框、矩阵和列表
3.1 数据结构简介
(1) Vector向量:一维
从1:100个整数中,随机取7个数,默认不放回取,如果要有放回取样,需要设置参数replace = TRUE
> sample(1:100,7)
[1] 38 80 74 96 63 26 3
(2) Matrix矩阵:两个维度,而且必须矩阵每列长度相同,数据类型相同
> x1 <- sample(1:100,7)
> x2 <- 11:17
> x3 <- sample(1:10,7)
> cbind(x1,x2,x3)
x1 x2 x3
[1,] 73 11 1
[2,] 95 12 7
[3,] 10 13 3
[4,] 4 14 8
[5,] 76 15 10
[6,] 64 16 9
[7,] 57 17 5
(3) Dataframe数据框:必须满足每列长度相同,数据类型可以不同
> y1 <- sample(1:100,7)
> y2 <- letters[1:7]
> y3 <- sample(1:10,7)
> data.frame(y1,y2,y3)
y1 y2 y3
1 85 a 8
2 58 b 4
3 80 c 5
4 78 d 1
5 76 e 10
6 72 f 2
7 66 g 9
(4) List列表:长度可以不同,数据类型也可以不同;没有行和列的概念,可以有多级元素
> df <- list(c(1,2,3),
data.frame(a=c(1,2,3),b=c("a","b","c")),
matrix(1:6,3),
list(1:3,1:5))
> df
[[1]]
[1] 1 2 3
[[2]]
a b
1 1 a
2 2 b
3 3 c
[[3]]
[,1] [,2]
[1,] 1 4
[2,] 2 5
[3,] 3 6
[[4]]
[[4]][[1]]
[1] 1 2 3
[[4]][[2]]
[1] 1 2 3 4 5
3.2 数据框的来源:
(1)在R中新建
df <- data.frame(gene = paste0("gene",1:3),
sam = paste0("sample",1:3),
exp = c(32,34,45))
(2)由已有数据转换或处理得到
(3)从文件中读取
df2 <- read.csv("gene.csv")
df2
(4)内置数据集:iris
3.3 数据框属性描述
(1)维度:dim(),nrow(),ncol()
(2)行名/列名:rownames(),colnames()
3.4 数据框取子集(一个,一行,一列,多行多列)
(1)向量:位置下标或者元素名
(2)矩阵:二维坐标(df[1,5])或者行名/列名(df[,'a'],不能用$符号来取)
(3)数据框:二维坐标(df[1,5])或者行名/列名(df[,'a'],df$exp)
(4)列表:df[[1]]或者df$x1(注意:df[1]取出来的是一个列表,df[[1]]取出来的是元素)
3.5 数据框修改
取子集$或[] + 赋值操作
修改数据框的行名和列名
修改全部行名:rownames(df) <- c("r1", "r2", "r3") 将取出的行名看做一个向量
修改一个行名:rownames(df)[2] <- "x"修改第二列的行名,就是修改行名这个向量的第二个元素
3.6 数据框进阶
(1)行数较多的数据框截取前/后几行查看(默认取6行)
head(iris)
tail(iris)
(2)行列数都多的数据框可取前几行前几列查看
iris[1:3, 1:3]
不经过赋值,只是输出看看
(3)查看每一列数据类型和具体内容
str(iris)
(4)去除含有缺失值的行:na.omit(df)
仅按照某一列来去除缺失值、缺失值替换:tidyr包 ?
(5)两个表格的连接
按列连接:cbind --->行数相同
按行连接:rbing --->列数相同
两个表格融合:merge(test1,test2,by="name") --->按照共同的列名name连接
merge(test1,test3,by.x = "name",by.y = "NAME") --->共同的列在两个表格中名字不同,需要指明分别是什么名字
交集、并集、补集、全集等,参照dplyr包 ?
(6)如果列名顺序错乱,如何按照指定顺序重排?
> df <- data.frame(matrix(rnorm(15),3))
> colnames(df) <- letters[c(3,1,2,5,4)]
> df
c a b e d
1 2.1271489 1.33107589 -0.9421655 0.7767287 0.8719409
2 0.7305057 -0.33669955 -1.3113782 0.7261399 -1.2010060
3 1.2703832 0.01927116 0.9627874 -0.3740854 0.5651674
> s <- letters[1:5]
> s
[1] "a" "b" "c" "d" "e"
> df2 <- df[,match(s,colnames(df))]
> df2
a b c d e
1 1.33107589 -0.9421655 2.1271489 0.8719409 0.7767287
2 -0.33669955 -1.3113782 0.7305057 -1.2010060 0.7261399
3 0.01927116 0.9627874 1.2703832 0.5651674 -0.3740854
3.7 矩阵新建和取子集
(1) 新建:
> m <- matrix(1:9, 3)
> m
[,1] [,2] [,3]
[1,] 1 4 7
[2,] 2 5 8
[3,] 3 6 9
(2) 矩阵的转置和转换
> m <- matrix(1:9,3)
> colnames(m) <- c("a","b","c")
> m
a b c
[1,] 1 4 7
[2,] 2 5 8
[3,] 3 6 9
> as.data.frame(m)
a b c
1 1 4 7
2 2 5 8
3 3 6 9
(3) 矩阵画热图
> pheatmap::pheatmap(m)
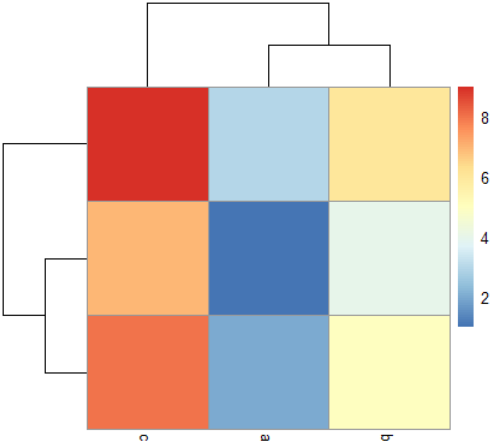
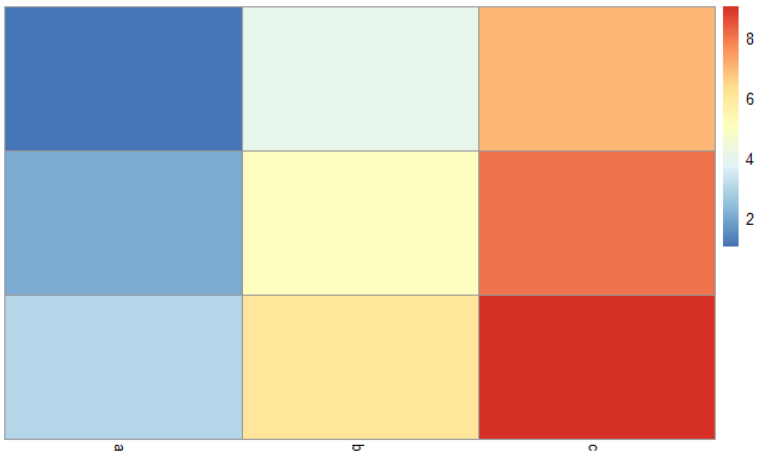
从图中可以看出颜色块和对应矩阵的元素不对应,这是因为默认经过聚类,如果要对应,则需要指定参数,不需要聚类即可:
> pheatmap::pheatmap(m, cluster_cols = F, cluster_rows = F)
3.8 列表新建和取子集
(1) 新建
> l <- list(m = matrix(1:9, 3), df = data.frame(gene = paste0("gene",1:3), sam = paste0("sample",1:3), exp = c(32, 34, 45)),x = c(1,3,5))
> l
$m
[,1] [,2] [,3]
[1,] 1 4 7
[2,] 2 5 8
[3,] 3 6 9
$df
gene sam exp
1 gene1 sample1 32
2 gene2 sample2 34
3 gene3 sample3 45
$x
[1] 1 3 5
(2) 取子集(以下两种方法等价)
l[[2]], l$df
3.9 删除(环境中的)变量
删除一个:rm(l)
删除多个:rm(df, m) (df, m是两个变量名)
删除全部变量:rm(list = ls())
清空控制台: ctrl + l
3.10 数据结构总结:
| 新建 | 取子集 | |
|---|---|---|
| 向量 x | x <- c() |
x[n] |
| 数据框 df | df <- data.frame() |
df[x,y], df[x,], df[,y],$ |
| 矩阵 m | m <- matrix() |
m[x,y] |
| 列表 l | l <- list() |
l[[n]], $ |
补充: 元素的名字(给向量中的元素命名)----- names()
> x <- 1:10
> names(x) <- letters[1:10]
> x
a b c d e f g h i j
1 2 3 4 5 6 7 8 9 10
> x["a"]
a
1
作业题:
match的应用:
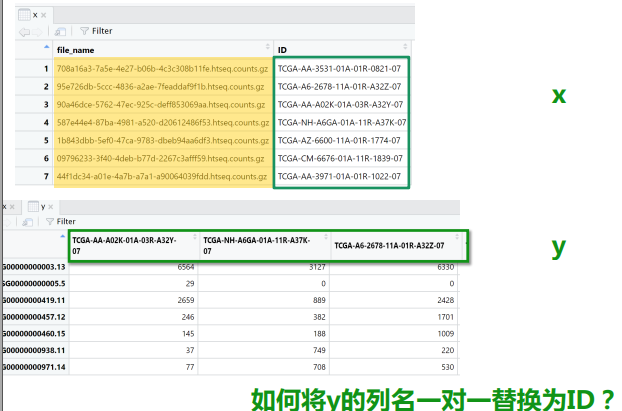
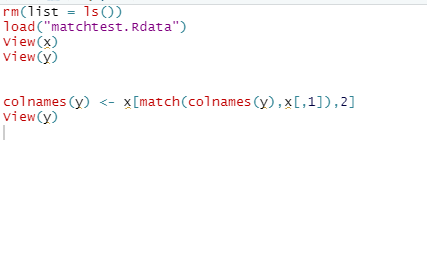

 浙公网安备 33010602011771号
浙公网安备 33010602011771号