基于高斯过程的贝叶斯优化(四)分类问题
在前面的文章中,我们所解决的问题都可以看做是基于高斯过程的回归问题。假设输入为$\{x,y\}_{n=1}^N$,则对于隐变量f有:$f\sim \mathcal{N}(0,K)$,回归问题在于若$y=f+\varepsilon$,$\varepsilon$为服从某正态分布的误差项,在给定任意$x_*$,预测$f_* | x_*,X,\mathbf{y}$分布。
该问题可以拓展至基于高斯过程的分类问题:
假设输入为$\{x,y\}_{n=1}^N$,则对于隐变量f有:$f\sim \mathcal{N}(0,K)$,分类问题在于若$y=\sigma(f)$,在给定任意$x_*$,预测$f_* | X , \mathbf { y } , \mathbf { x } _ { * }$分布。
那么用于回归问题的相同的思想能否用于解决分类问题呢?
考虑如下一个二分类问题:
\[\pi ( \mathbf { x } ) \triangleq p ( y = + 1 | \mathbf { x } ) = \sigma ( f ( \mathbf { x } ) )\]
令$X,\mathbf{y}$表示全部观测数据,$\mathbf{y}$只能取0与1,$\mathbf{f}=f(\mathbf{x})$生成隐变量,由
\[p \left( f _ { * } | X , \mathbf { y } , \mathbf { x } _ { * } \right) = \int p \left( f _ { * } | X , \mathbf { x } _ { * } , \mathbf { f } \right) p ( \mathbf { f } | X , \mathbf { y } ) d \mathbf { f }\]
以及
\[\overline { \pi } _ { * } \triangleq p \left( y _ { * } = + 1 | X , \mathbf { y } , \mathbf { x } _ { * } \right) = \int \sigma \left( f _ { * } \right) p \left( f _ { * } | X , \mathbf { y } , \mathbf { x } _ { * } \right) d f _ { * }\]
可以看到,由于$p \left( f _ { * } | X , \mathbf { x } _ { * } , \mathbf { f } \right)$部分是易于求解的高斯分布,求解$p \left( f _ { * } | X , \mathbf { y } , \mathbf { x } _ { * } \right)$最需要的找到的是$p ( \mathbf { f } | X , \mathbf { y } )$的估计。
注意到有$p ( \mathbf { f } | X , \mathbf { y } ) = p ( \mathbf { y } | \mathbf { f } ) p ( \mathbf { f } | X ) / p ( \mathbf { y } | X )$成立,
该等式将右边分子分母同时乘$p(X)$即可快速证明:
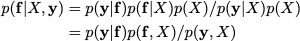

注意到由于$\mathbf{f}$应包含$X$的信息,且$y$直接由$\mathbf{f}$决定,因此有$p(\mathbf{y}|\mathbf{f}) = p(\mathbf{y}|\mathbf{f},\mathbf{x})$,因此得证。并且有$p(\mathbf{f}|X,\mathbf{y}) \propto p(\mathbf{y} | \mathbf{f})p(\mathbf{f}|X)$
针对$p(\mathbf{f}|X,\mathbf{y})$进行估计可以采用Laplace逼近方法。Laplace逼近方法是利用taylor展开进行函数逼近的方法,以一元函数为例,将$f(x)$在$x_0$处进行展开,有:
\[f ( x ) = f \left( x _ { 0 } \right) + f ^ { \prime } \left( x _ { 0 } \right) \left( x - x _ { 0 } \right) + \frac { 1 } { 2 } f ^ { \prime \prime } \left( x _ { 0 } \right) \left( x - x _ { 0 } \right) ^ { 2 } + R\]
当$f(x)$函数取到极值时其一阶导数值为0,因此有
\[f ( x ) \approx f \left( x _ { 0 } \right) - \frac { 1 } { 2 } \left| f ^ { \prime \prime } \left( x _ { 0 } \right) \right| \left( x - x _ { 0 } \right) ^ { 2 }\]
对任意M,a,b,对上式两边取exp并进行积分,则有
\[e ^ { M f ( x ) } \approx e ^ { M f \left( x _ { 0 } \right) } e ^ { - M \left| f ^ { \prime \prime } \left( x _ { 0 } \right) \right| \left( x - x _ { 0 } \right) ^ { 2 } / 2 }\]
注意到等式右边前半部分$e ^ { M f \left( x _ { 0 } \right) }$是一个常数,而等式右边后半部分$e ^ { - M \left| f ^ { \prime \prime } \left( x _ { 0 } \right) \right| \left( x - x _ { 0 } \right) ^ { 2 } / 2 }$是一个近似正态分布的表达形式(仅相差常数倍),因此,$e ^ { M f ( x ) }$项可采用正态分布的形式进行逼近。
对于本问题
\[logp(\mathbf{f}|X,\mathbf{y}) \propto \Psi ( \mathrm { f } ) \triangleq \log p ( \mathrm { y } | \mathrm { f } ) + \log p ( \mathrm { f } | X )\]
\[\Psi ( \mathrm { f } )= \log p ( \mathbf { y } | \mathbf { f } ) - \frac { 1 } { 2 } \mathbf { f } ^ { \top } K ^ { - 1 } \mathbf { f } - \frac { 1 } { 2 } \log | K | - \frac { n } { 2 } \log 2 \pi\]
求其一阶导与二阶导分别为:
\[\nabla \Psi ( \mathbf { f } ) = \nabla \log p ( \mathbf { y } | \mathbf { f } ) - K ^ { - 1 } \mathbf { f }\]
\[\nabla \nabla \Psi ( \mathbf { f } ) = \nabla \nabla \log p ( \mathbf { y } | \mathbf { f } ) - K ^ { - 1 } = - W - K ^ { - 1 }\]
则根据Laplace逼近方法,对$\Psi ( \mathrm { f } )$进行taylor展开,
\[\Psi(\mathbf{f}) = \Psi(\widehat{\mathbf{f}})+\nabla\Psi(\widehat{\mathbf{f}}) ^ { T } ( \mathbf { f } - \widehat { \mathbf { f } } ) - \frac { 1 } { 2 } ( \mathbf { f } - \widehat { \mathbf { f } } ) ^ { T } \nabla\nabla\Psi(\widehat{\mathbf{f}}) ( \mathbf { f } - \widehat { \mathbf { f } } )\]
其中$\widehat { \mathbf { f } } = \mathbf { f } _ { \mathrm { MAP } }$,根据MAP估计定义,此时$\nabla \Psi ( \mathbf { f } )=0$,$ \mathbf { f } _ { \mathrm { MAP } }$可以根据牛顿-拉夫森法进行求解,即
\[\begin{aligned} \mathbf { f } ^ { \text { new } } = \mathbf { f } - ( \nabla \nabla \Psi ) ^ { - 1 } \nabla \Psi & = \mathbf { f } + \left( K ^ { - 1 } + W \right) ^ { - 1 } \left( \nabla \log p ( \mathbf { y } | \mathbf { f } ) - K ^ { - 1 } \mathbf { f } \right) \\ & = \left( K ^ { - 1 } + W \right) ^ { - 1 } ( W \mathbf { f } + \nabla \log p ( \mathbf { y } | \mathbf { f } ) ) . \end{aligned}\]
由于此时
\[\mathrm{exp}(\Psi(\mathbf{f})) = \mathrm{exp}(\Psi(\widehat{\mathbf{f}}))\mathrm{exp}(- \frac { 1 } { 2 } ( \mathbf { f } - \widehat { \mathbf { f } } ) ^ { T } \nabla\nabla\Psi(\widehat{\mathbf{f}}) ( \mathbf { f } - \widehat { \mathbf { f } } )\]
可以看出左侧可以由一个正态分布实现逼近,且该正态分布均值为$\mathbf { f } _ { \mathrm { MAP }}$,方差为$(- W - K ^ { - 1 })^{-1}$,即
\[q ( \mathbf { f } | X , \mathbf { y } ) = \mathcal { N } \left( \hat { \mathbf { f } } , \left( K ^ { - 1 } + W \right) ^ { - 1 } \right)\]
Reference
[1] Brochu E , Cora V M , De Freitas N . A Tutorial on Bayesian Optimization of Expensive Cost Functions, with Application to Active User Modeling and Hierarchical Reinforcement Learning[J]. Computer Science, 2010.
[2] Rasmussen C E , Williams C K I . Gaussian Processes for Machine Learning[M]. MIT Press, 2005.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号