hadoop+spark伪分布式

准备工作
- VMware Workstation Pro(懂得都懂)
- jdk-8u401-linux-x64.tar.gz
- spark-3.2.1-bin-hadoop2.7.tgz
- hadoop-2.7.7.tar.gz
- CentOS-7-x86_64-Mini.iso
- ssh工具(MobaXterm_Personal、FinalShell等,Windows的cmd其实也行,我这里用XTerminal)
资源网上都有,请自行搜索下载
安装虚拟机
选择创建新的虚拟机
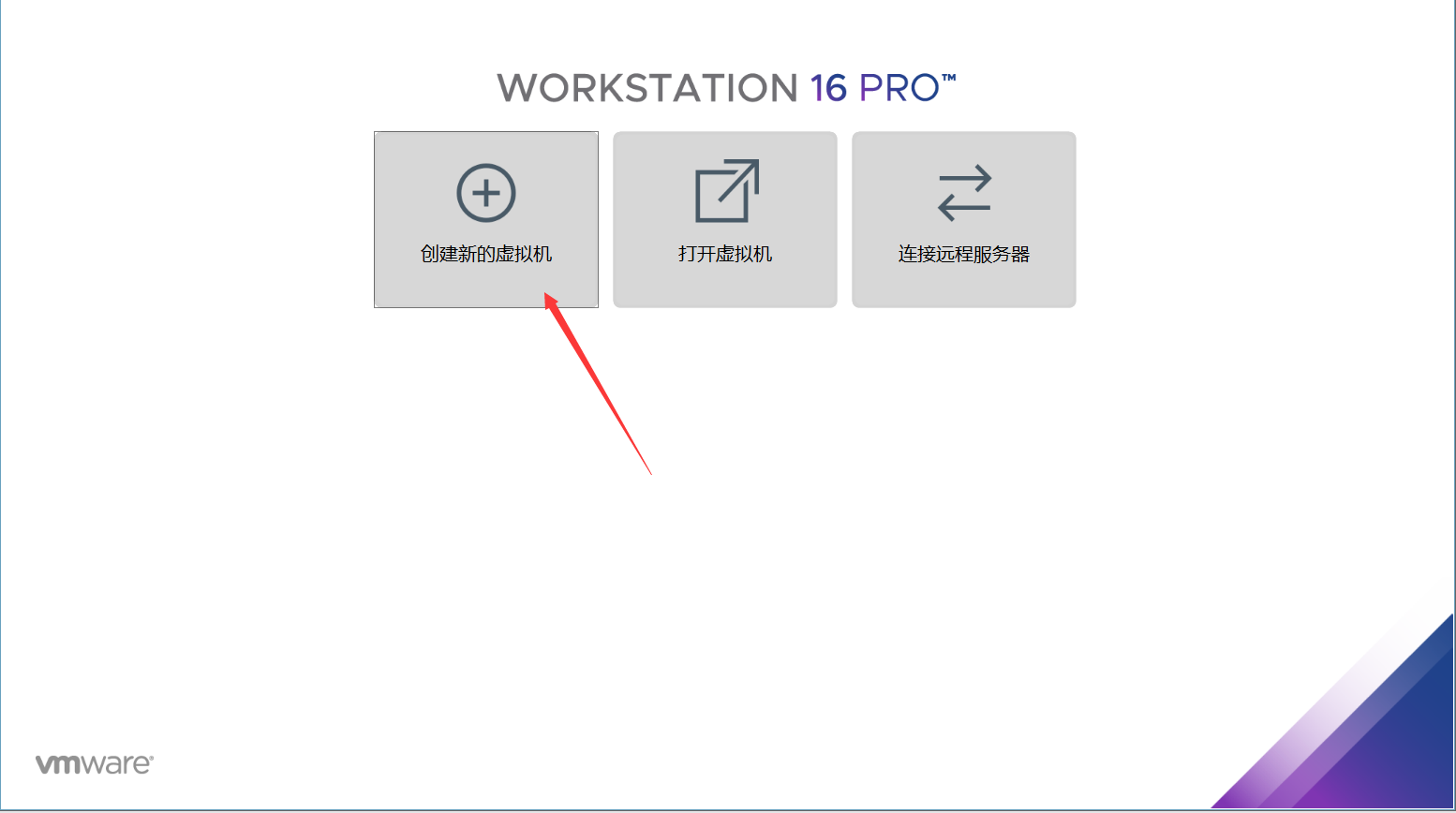
为了节省时间,这里使用推荐,你有兴趣,也可以自定义配置
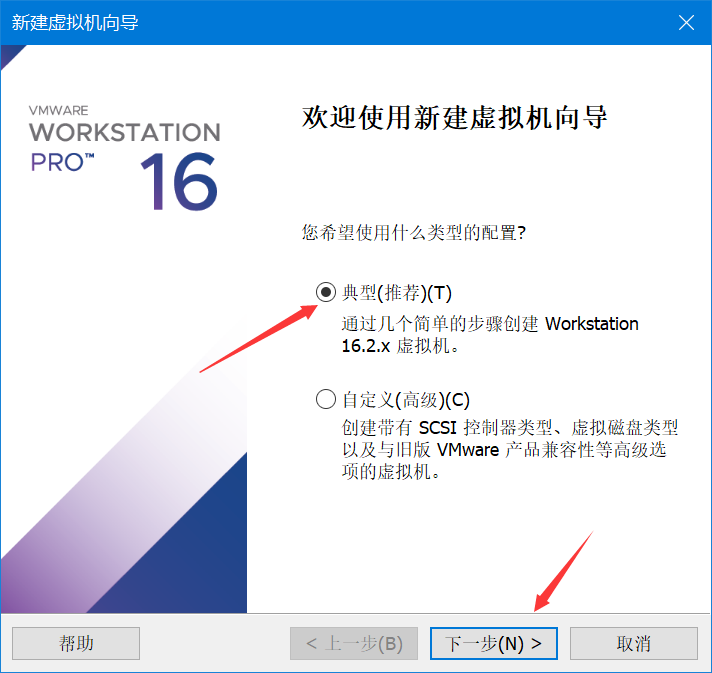
选择你下载好的centos镜像
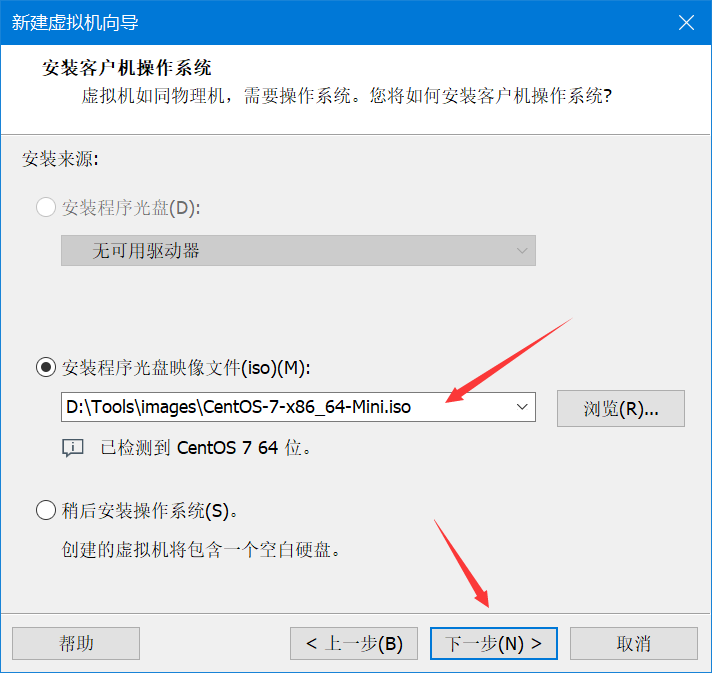
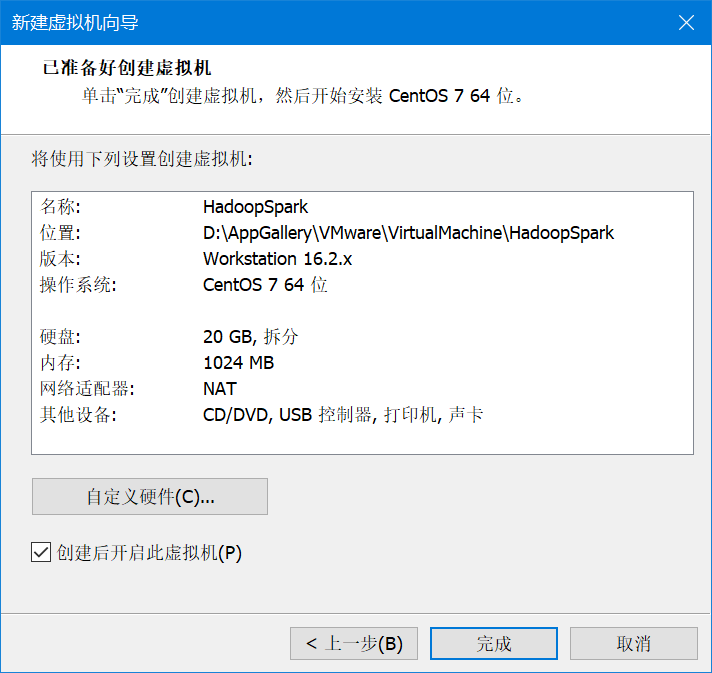
给虚拟机取个名,这里用HadoopSpark
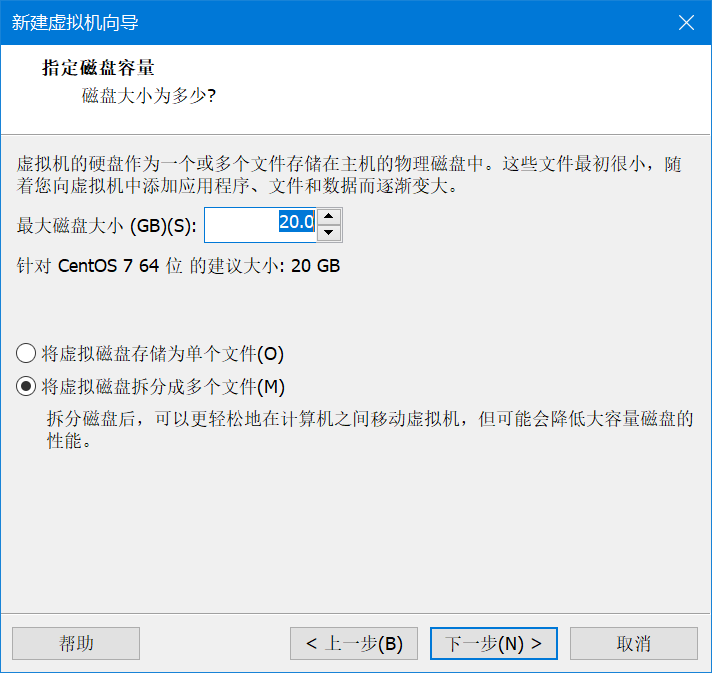
20G够用了,直接下一步,完成
直接回车确认安装
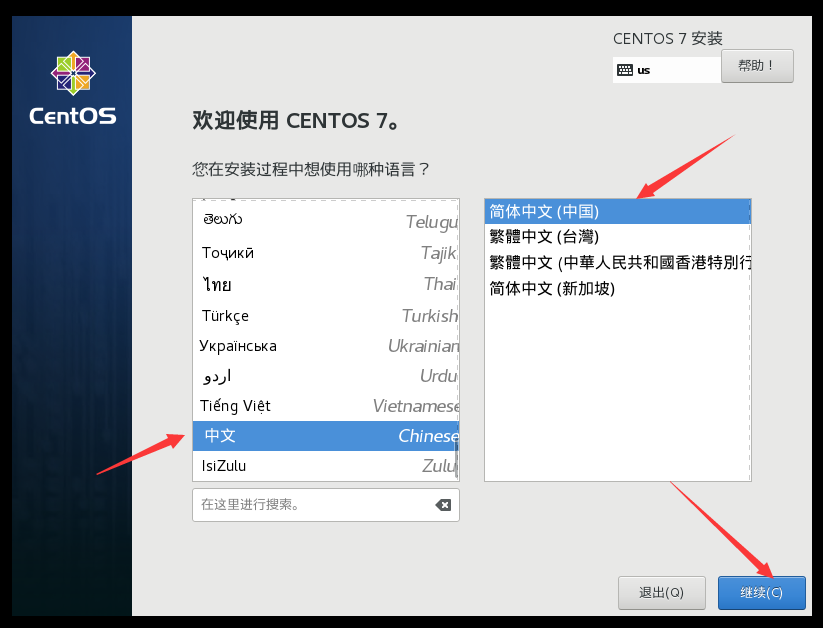
出现这个,选择中文(这里安装过程使用哪种语言,不是系统使用哪种语言)
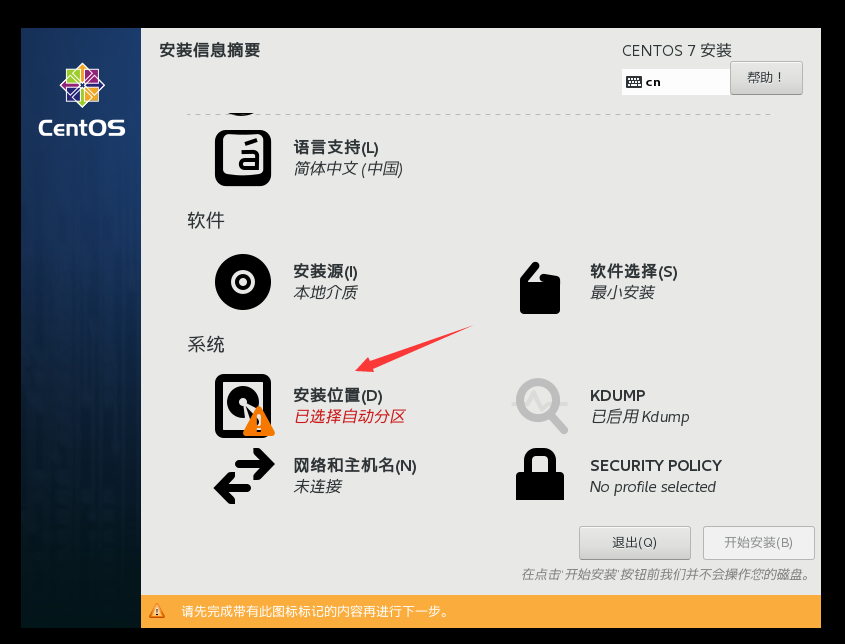
选择安装位置,然后选择完成,让它自动配置
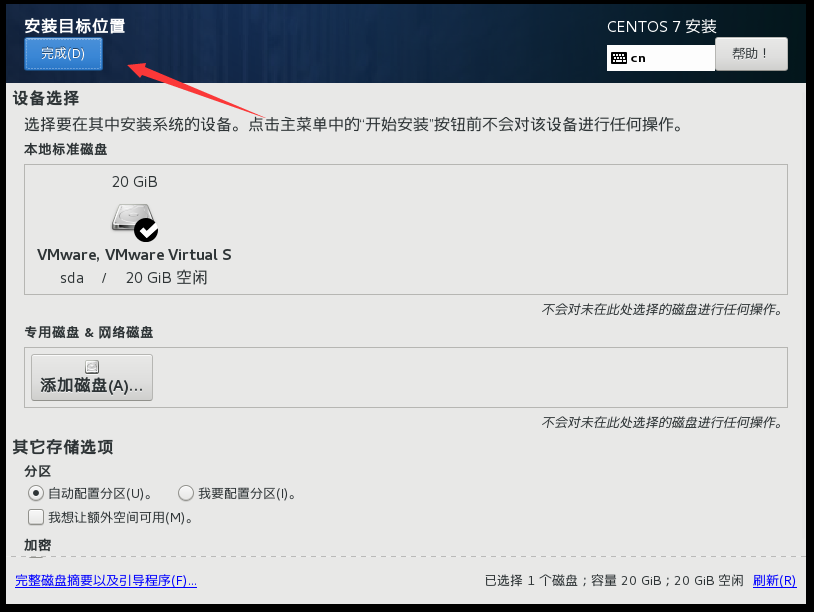
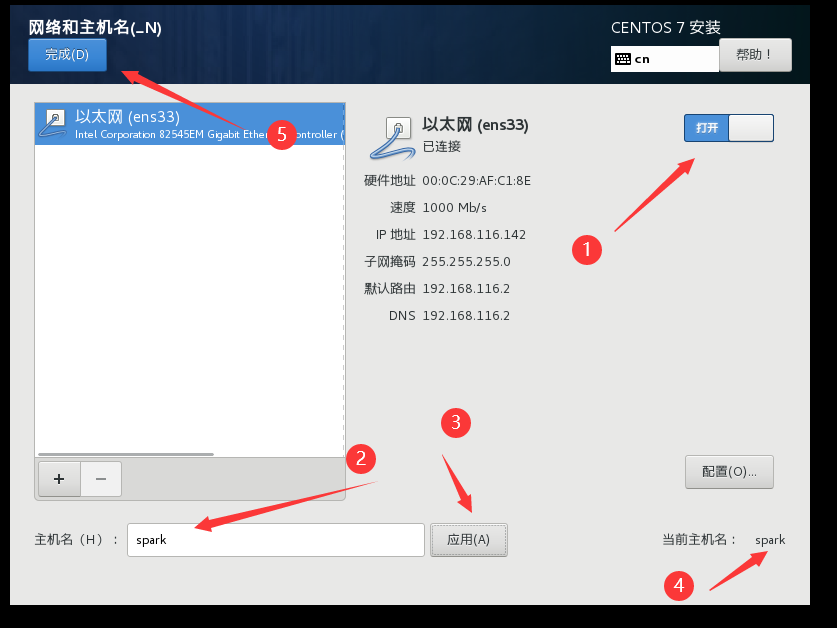
选择网络和主机名,打开以太网开关,更改主机名并应用(这里改了,进去就不用改了),完成配置
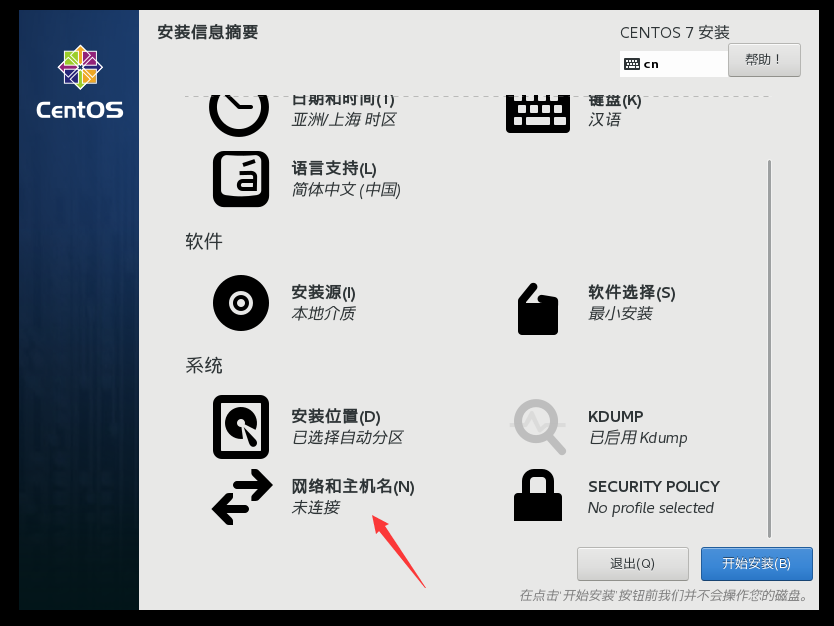
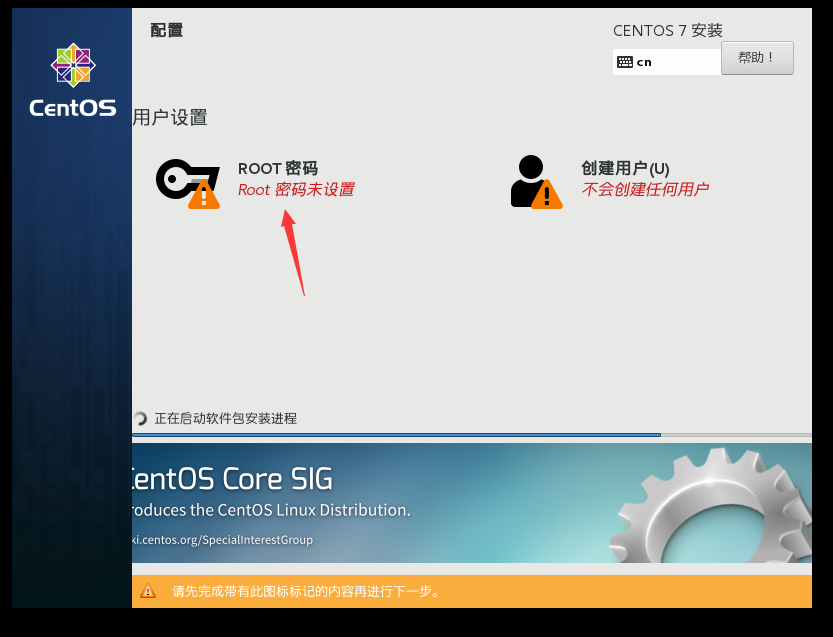
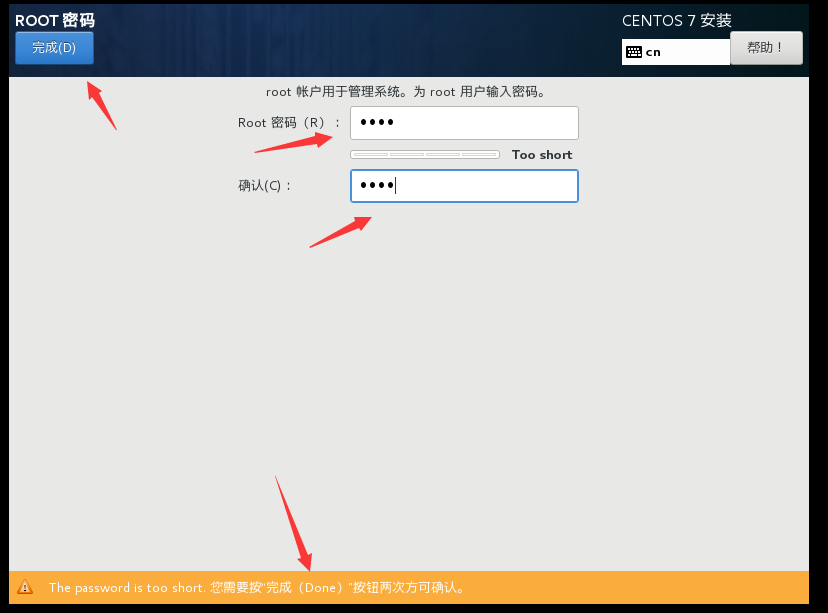
开始安装,然后设置root用户的密码,提示密码太短,点两下完成就可以了。这里就不再创建普通用户了。最后静待安装完成
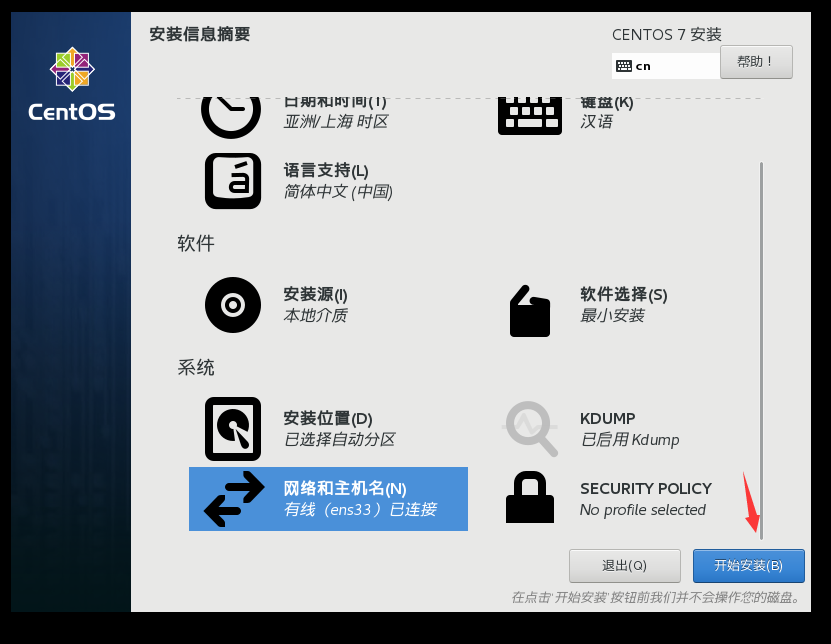
安装成功,选择重启
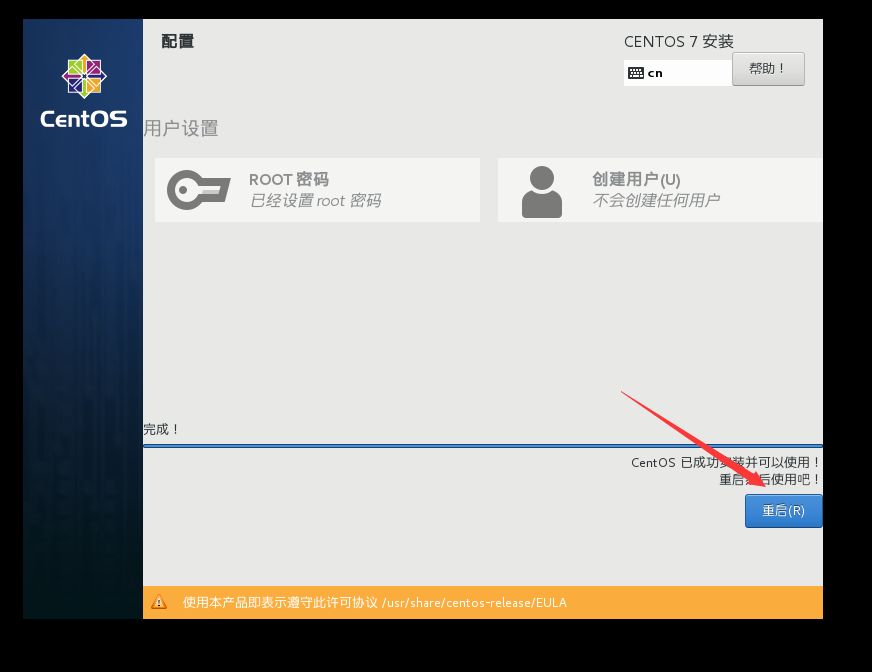
输入用户密码,登录成功
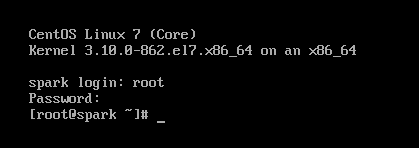
配置静态IP
输入ip addr,查看本机IP地址
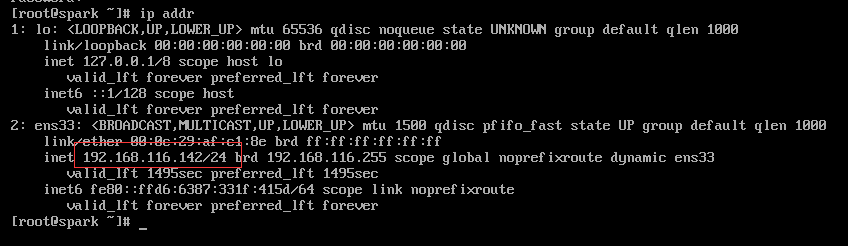
打开SSH工具,输入IP地址、用户名、密码,完成连接
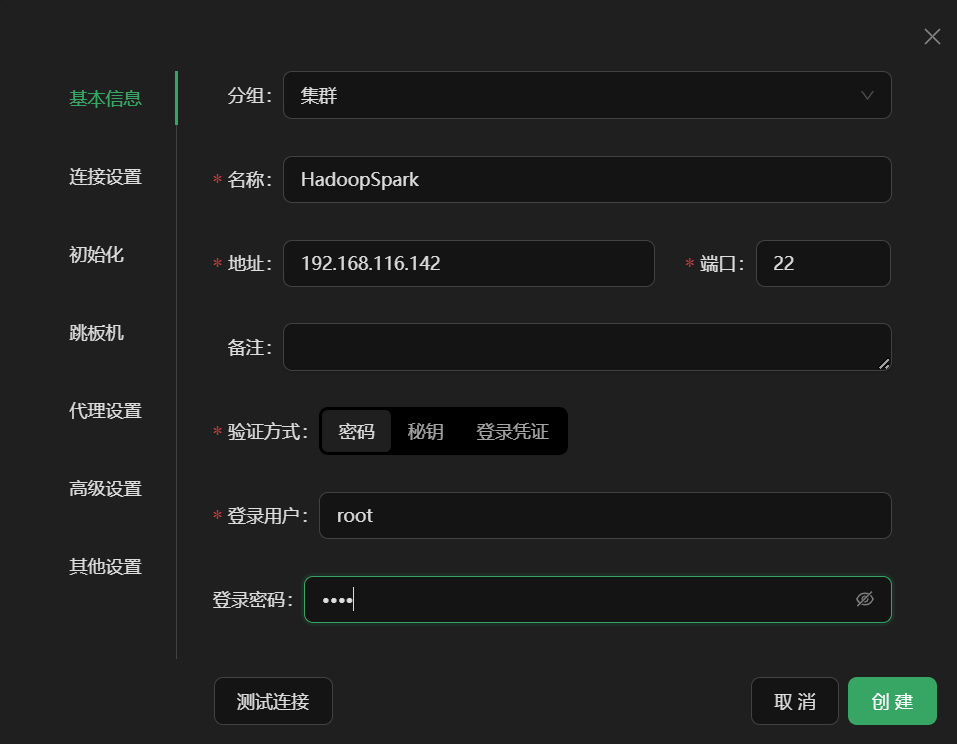
登录虚拟机后,输入yum update -y更新一下yum
接着输入yum install -y vim安装一下vim编辑器
接着打开网络配置文件修改为静态IP,按i进入编辑模式
vim /etc/sysconfig/network-scripts/ifcfg-ens33
!!!这里不要照抄!!!,往下看
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="a33fe36d-dca4-4030-a614-668e080b0f92"
DEVICE="ens33"
ONBOOT="yes"
IPADDR=192.168.116.142
NETMASK=255.255.255.0
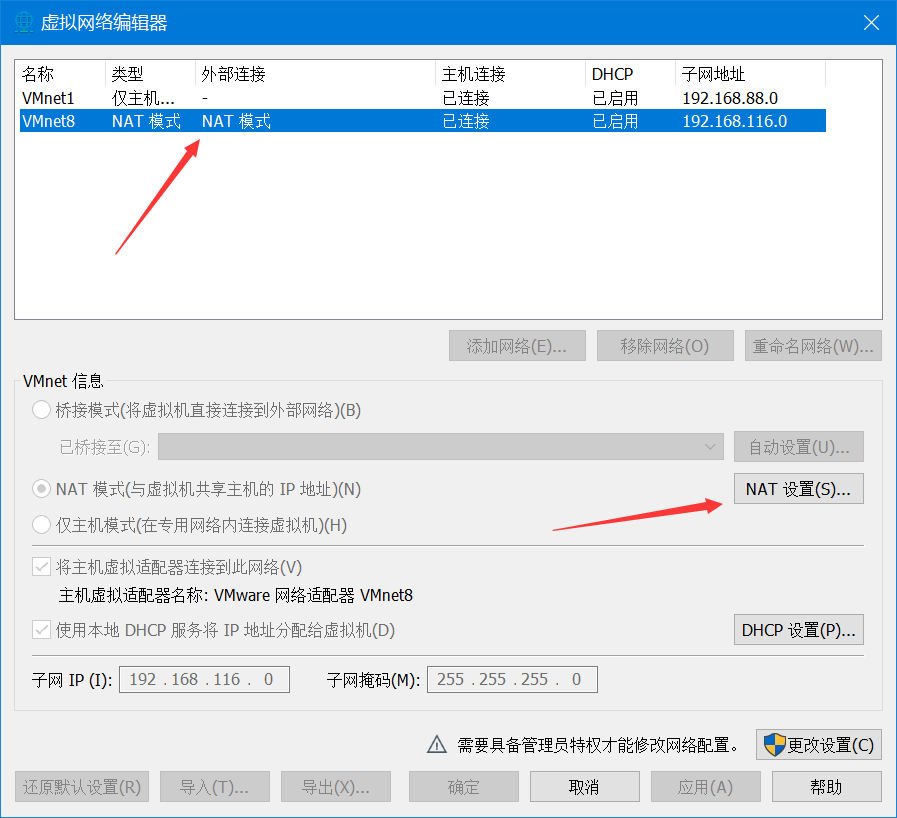
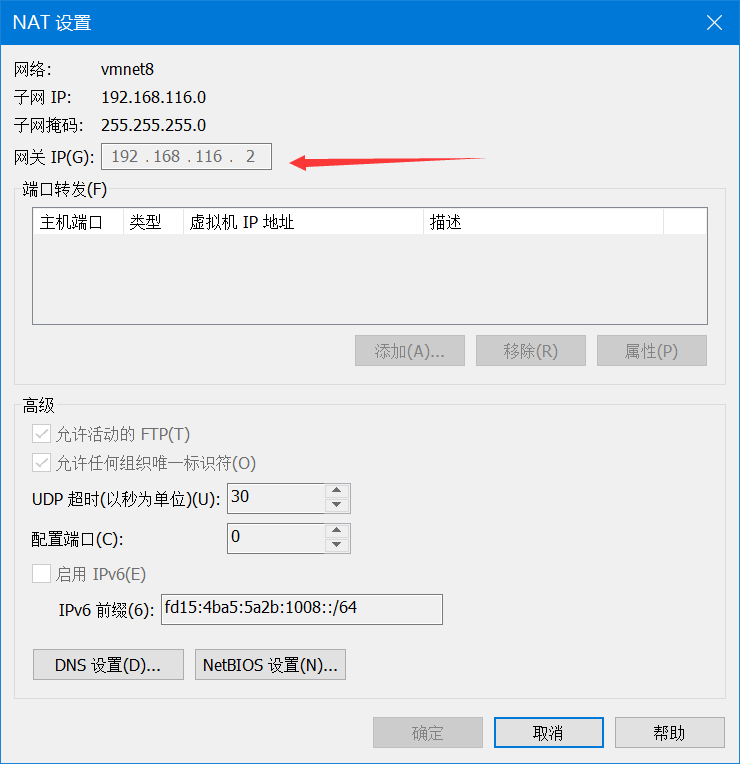
GATEWAY=192.168.116.2
DNS1=144.144.144.144
DNS2=8.8.8.8
把BOOTPROTO改为static,
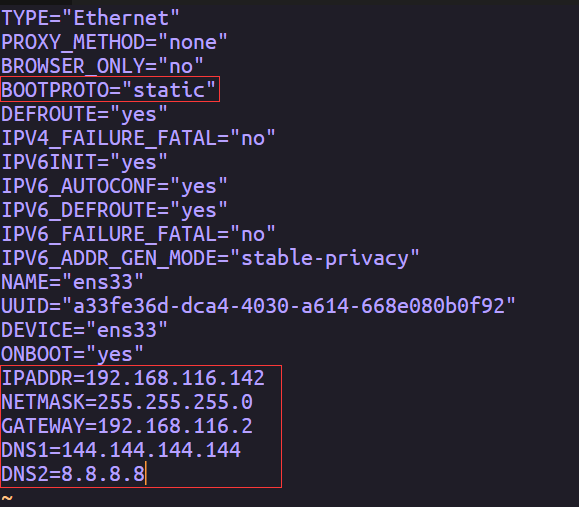
IPADDR,根据网关改,网关再这里看,只改第四段就行,不要和网关冲突
GATEWAY改成你查到的,剩下的和我一样就行

改好后,按一下键盘左上角Esc,输入:wq,保存退出
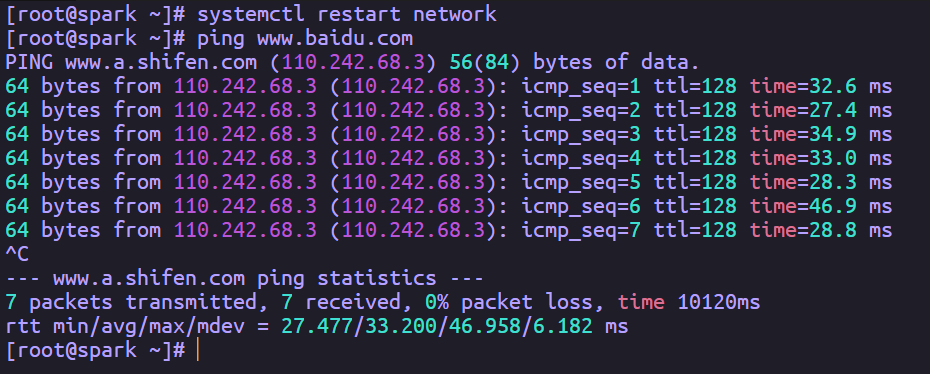
接着输入systemctl restart network,重启一下网络,无报错就行
这里我改的和原来的IP地址一样,所以没有重新连接
然后用ping www.baidu.com,看一下能否连接外网,我这里是OK的
关闭防火墙
为什么要关闭防火墙
在安装Hadoop的过程中,关闭防火墙是一个常见的步骤。这是因为Hadoop需要在集群的各个节点之间进行大量的网络通信,包括数据的传输和任务的调度等。如果防火墙开启,则会对这些网络通信进行限制,导致Hadoop无法正常工作。
具体来说,防火墙通常会对以下几个方面的网络通信进行限制:
- 端口:Hadoop使用多个端口进行节点之间的通信,包括数据传输、任务调度和节点管理等。如果防火墙关闭了这些端口,那么这些网络通信就无法建立。因此,我们需要关闭防火墙来确保这些端口的正常通信。
- 协议:Hadoop使用的通信协议有很多,包括TCP/IP、UDP等。如果防火墙关闭了某些协议,那么这些通信协议就无法通过防火墙进行传输。因此,我们需要关闭防火墙来确保这些通信协议的正常传输。
- IP地址:Hadoop集群中的节点可能使用不同的IP地址进行通信。如果防火墙关闭了某些IP地址,那么这些节点之间的通信就无法建立。因此,我们需要关闭防火墙来确保这些IP地址的正常通信。
综上所述,关闭防火墙是为了确保Hadoop集群中各个节点之间的网络通信能够正常建立,从而保证Hadoop的正常工作。
输入下面命令关闭防火墙
systemctl stop firewalld//暂时关闭,重新开机会自启
systemctl disable firewalld//永久关闭
firewall-cmd --state//查看防火墙状态

配置主机名与IP映射
编辑对应文件
vim /etc/hosts
格式IP地址(空格)主机名

设置SSH免密登录
SSH免密登录的原理可以理解为:如果某机器A试图要免密登录机器B,则需要在机器A上生成一个公钥(id_rsa.pub)和一个私钥(id_rsa),并将公钥添加到机器B的权限列(authorized_keys)中,这样在机器A上通过SSH就可以免密登录机器B了。
设置SSH免密登录前,需要生成秘钥,在主机中执行ssh-keygen -t rsa命令生成密钥,命令输入后,一直回车同意,直到显示密钥信息即为生成完毕。
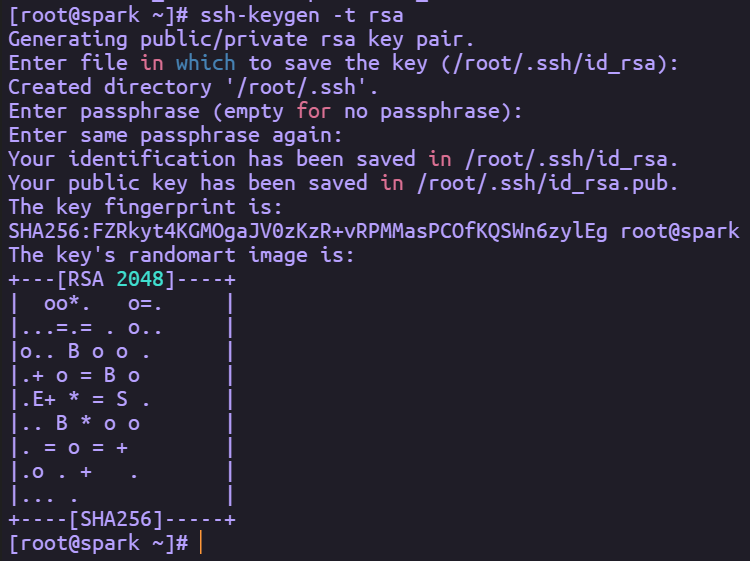
拷贝公钥
ssh-copy-id -i .ssh/id_rsa.pub 用户名字@主机ip
由于伪分布式的SSH免密登录操作就是将目录“.ssh/”下的公钥“id-rsa.pub”添加到当前目录的“.ssh/ authorized_keys”列表中。因此将公钥(id_rsa.pub)复制到当前目录的/ authorized_keys列表中,命令为cat id_rsa.pub >> authorized_keys或ssh-copy-id -i .ssh/id_rsa.pub root@spark,设置完成后通过执行ssh spark测试是否免密成功,如果直接登录则设置成功,如果需要输入密码,则设置失败。
中途需要输入yes完成确认,还要输入密码(这个密码是对应主机的密码)。也可以采用另一种方式,不需要这些操作
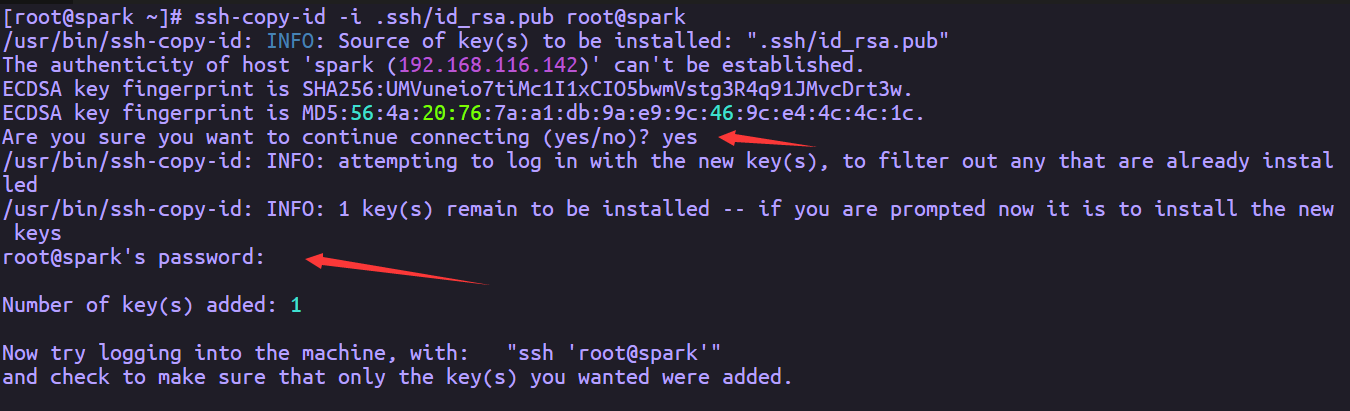
输入ssh spark测试一下,免密登录是否成功

安装Java运行环境
创建一个文件夹,来存放我们的软件
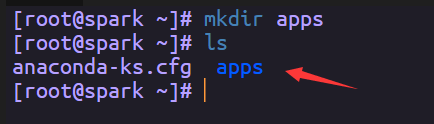
然后把我们下载好的jdk上传到虚拟机,用SSH工具可以直接拖进去
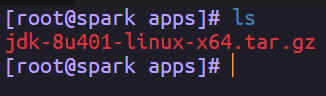
纯命令也行的
scp 本地路径 用户名@IP地址:虚拟机路径
解压一下,并重命名为Java
tar -zxvf jdk-8u401-linux-x64.tar.gz
mv jdk1.8.0_401 java

配置Java环境变量
vim /etc/profile
在末尾添加,路径填写你的具体路径
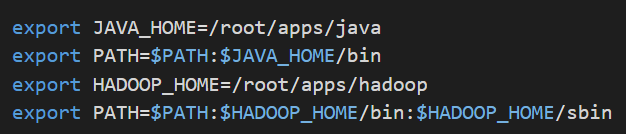
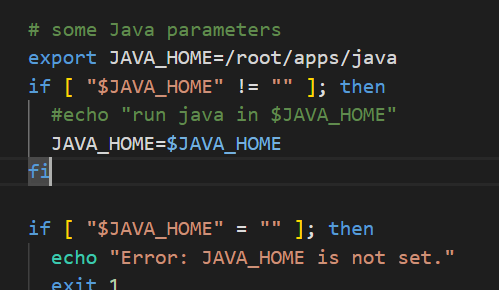
export JAVA_HOME=/root/apps/java
export PATH=$PATH:$JAVA_HOME/bin
刷新配置,是配置生效
source /etc/profile
查看Java是否安装成功
java -version

安装Hadoop
老规矩,上传、解压、改名
tar -zxvf hadoop-2.7.7.tar.gz
mv hadoop-2.7.7 hadoop

配置环境变量,刷新配置
vim /etc/profile
export HADOOP_HOME=/root/apps/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
检验是否安装成功hadoop version

修改Hadoop核心配置文件
Hadoop的配置文件有多个,包括hadoop-env.sh、yarn-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml和yarn-site.xml,所有的配置文件均存放于同一个目录(/root/apps/hadoop/etc/hadoop)。
修改hadoop-env.sh文件
cd hadoop/etc/hadoop/

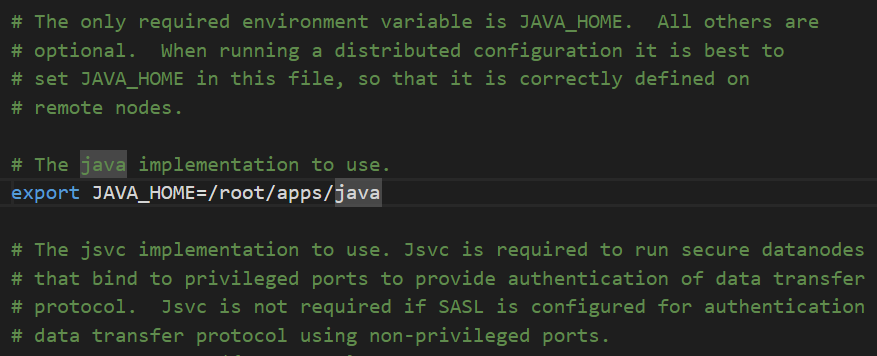
hadoop-env.sh配置文件主要是用来配置Hadoop运行所需的环境变量,主要是配置Java的环境变量。在此配置文件中修改JAVA_HOME的配置信息,将原来的值改为Java运行环境的安装路径
修改core-site.xml文件
core-site.xml文件是Hadoop核心全局配置文件,主要用于定义文件访问的格式。该文件主要配置文件系统采用hdfs实现、临时数据存放的位置、缓冲区大小(实际工作中根据服务器性能动态调整)、开启hdfs的垃圾桶机制(删除掉的数据可以从垃圾桶中回收,单位分钟)等
<configuration>
<!--定义文件系统的实现,默认是file:///本地文件系统,改成 hdfs://分布式文件存储系统,指定HDFS的namenode的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://spark:9000</value>
</property>
<!--Hadoop本地存储临时数据的目录,如果hdfs-site.xml中不配置namenode和datanode的存放位置,默认就放在这个路径中-->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/apps/hadoop/tmp</value>
</property>
</configuration>
修改hdfs-site.xml文件
此文件是HDFS相关的配置文件,用于配置Hadoop本地存储Namenode和Datanode数据的目录,配置副本的数量。
<configuration>
<property>
<!--配置HDFS保存数据的副本数量,默认值是3,伪分布式设置为1-->
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<!--配置NameNode元数据存储路径-->
<name>dfs.namenode.name.dir</name>
<value>file:/root/apps/hadoop/data/dfs/name</value>
</property>
<!--配置datanode中数据存储位置-->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/root/apps/hadoop/data/dfs/data</value>
</property>
</configuration>
启动HDFS
经过以上操作,伪分布式HDFS搭建完成,在第一次启动HDFS之前需要通过执行命令hdfs namenode -format进行格式化。 此命令hdfs集群配置过程只执行一次
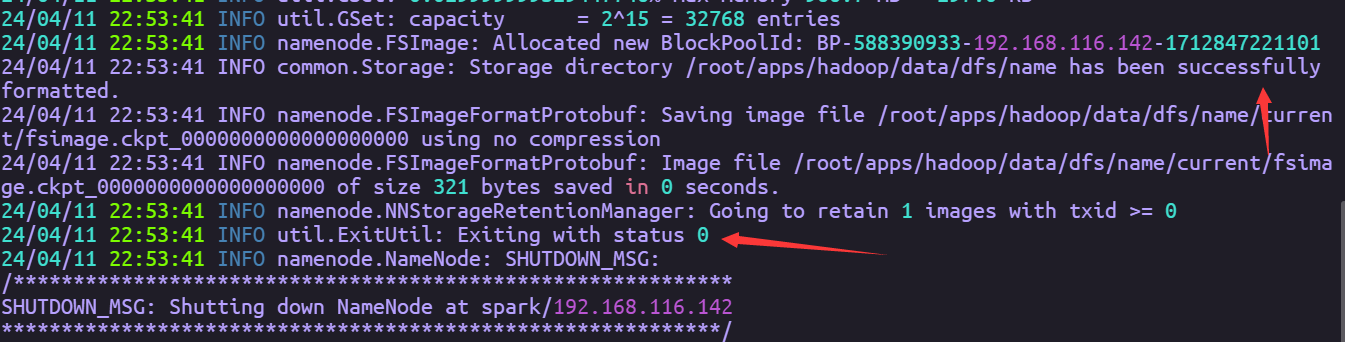
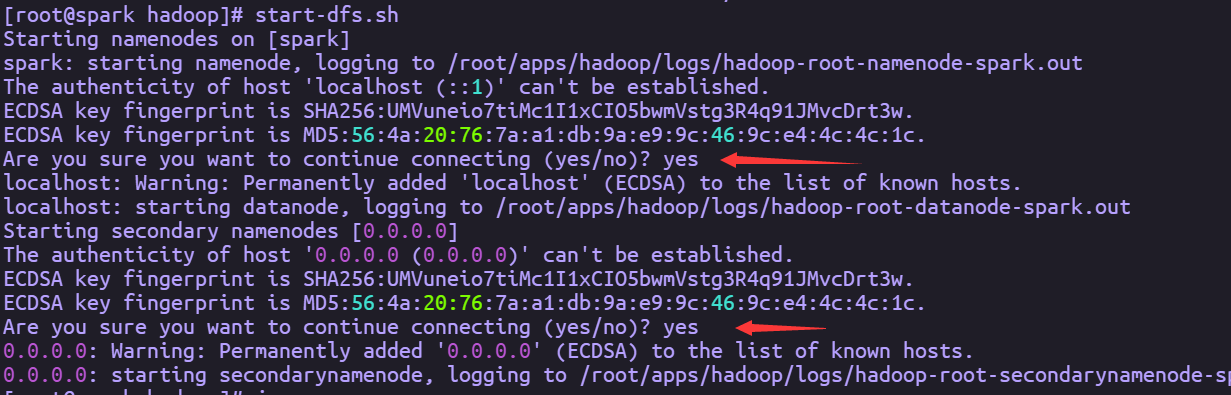
HDFS格式完成后,通过执行命令start-dfs.sh启动服务进程。执行完成后通过jps查看进程,如果出现NameNode、DataNode、SecondaryNameNode则表示HDFS伪分布式环境搭建成功
一路yes就行
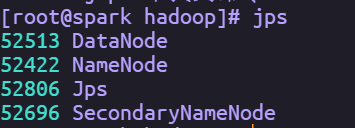
备注:要停止HDFS,直接运行stop-dfs.sh即可
配置伪分布式YARN
YARN的配置文件也存放于/root/apps/hadoop/etc/hadoop目录下,包括mapred-site.xml、yarn-site.xml、yarn-env.sh三个文件
修改mapred-site.xml文件
mapred-site.xml文件默认情况下不存在,需要通过mapred-site.xml.template文件创建一份
cp mapred-site.xml.template mapred-site.xml
执行命令vim mapred-site.xml,在mapred-site.xml中添加如下内容。
<configuration>
<property>
<!--指定Mapreduce程序调度在yarn上,默认是local就是本地模式-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改yarn-site.xml
yarn-site.xml文件是YARN框架的配置文件,需配置YARN进程及YARN相关属性。首先,需要指定ResourceManager守护进程的主机和监听的端口,其主机为spark,默认端口为8032。其次,指定ResourceManager使用的scheduler以及NodeManager的辅助服务等信息。在yarn-site.xml中添加如下内容。
<configuration>
<!--配置ResourceManager在哪台机器上-->
<property>
<name>yarn.resourcemanager.name</name>
<value>spark</value>
</property>
<!--配置在NodeManager中运行MapReduce服务-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
修改yarn-env.sh
yarn-env.sh文件是YARN框架运行环境的配置,同样需要修改JAVA_HOME的配置信息
把前面的#号去掉
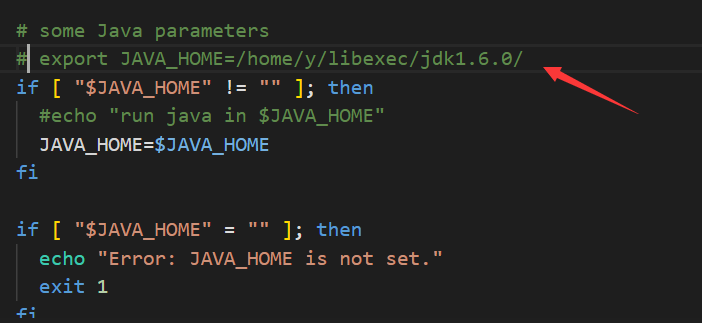
好像不该也行,下面写着如果为空则从环境变量里取
启动测试YARN
经过以上操作,伪分布式YARN搭建完成,通过执行命令start-yarn.sh启动服务进程,执行完成后通过jps查看进程,如果出现ResourceManager和NodeManager进程则表示YARN伪分布式环境搭建成功
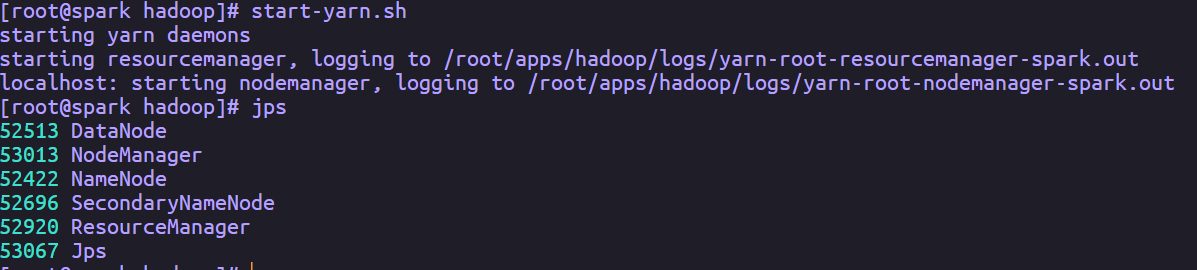
备注:要停止YARN,直接运行stop-yarn.sh即可。
通过Web浏览器访问Hadoop的集群环境
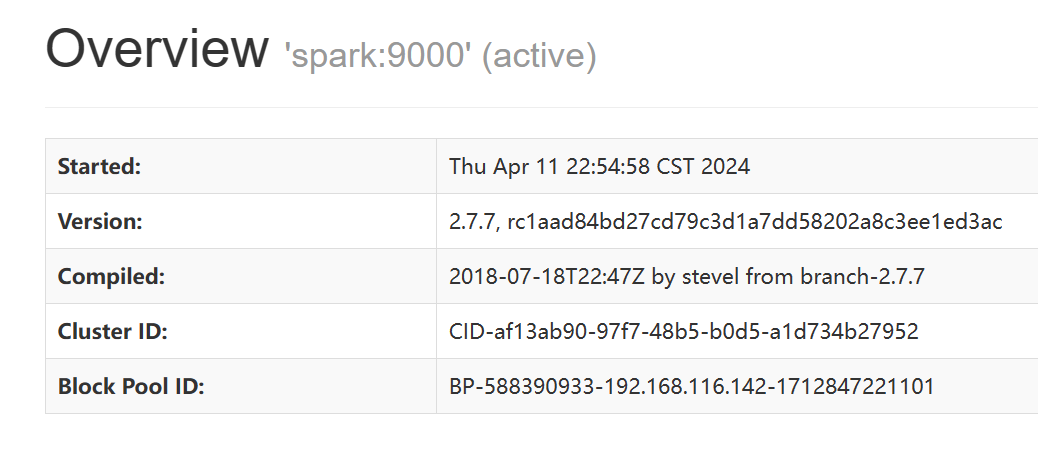
打开浏览器,输入http://192.168.116.142:50070(其中URL中的IP地址及集群服务器的静态IP),检查NameNode和DataNode的启动情况。见图,说明HDFS启动成功。
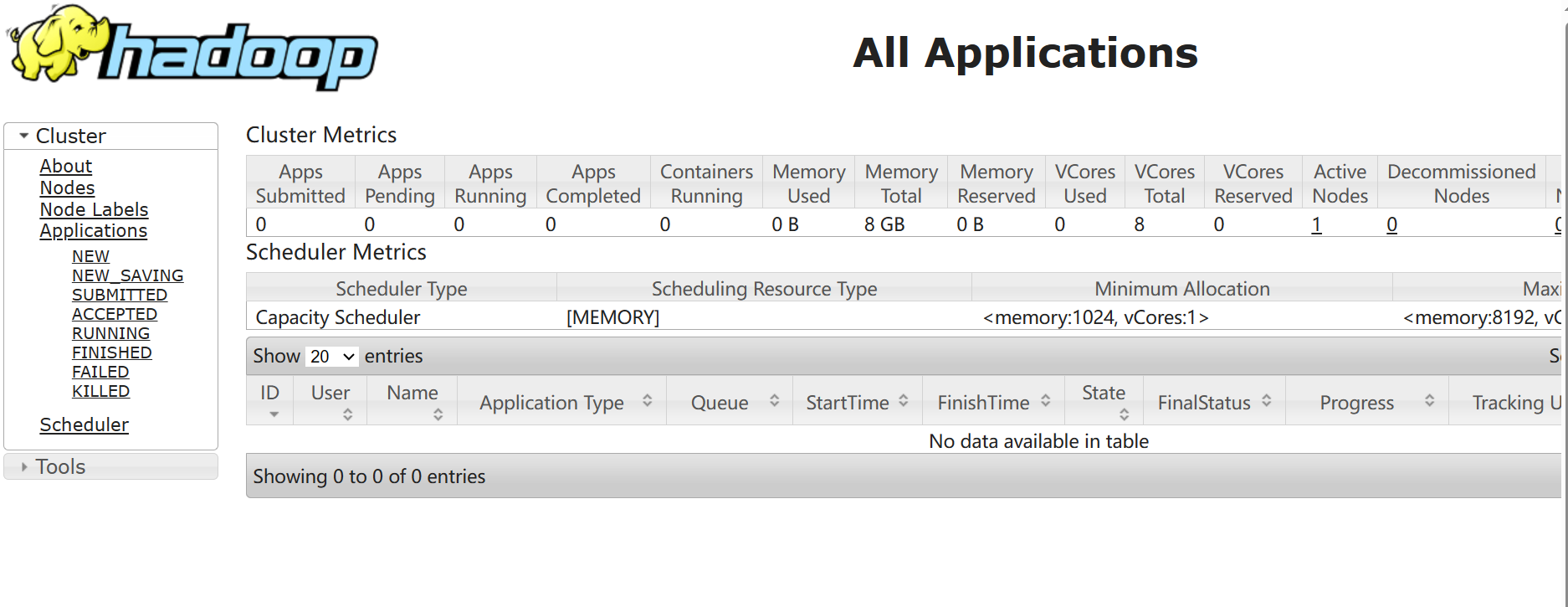
在浏览器中输入http://192.168.116.142:8088,检查YARN的启动情况,见图,说明YARN启动成功
安装Spark
一样的,上传、解压、重命名(好累啊/(ㄒoㄒ)/~~)
tar -zxvf spark-3.2.1-bin-hadoop2.7.tgz
mv spark-3.2.1-bin-hadoop2.7 spark

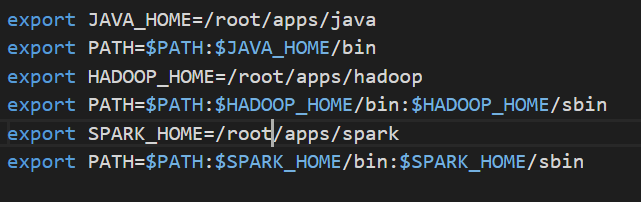
配置环境变量
vim /etc/profile
export SPARK_HOME=/home/hadoop/apps/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
别忘了刷新一下配置source /etc/profile
修改Spark配置文件
Spark部署相对Hadoop比较简单,只需要修改conf目录下的spark-env.sh、spark-defaults.conf和workers(低版本的是slaves)文件。
cd spark/conf/

复制一份
cp spark-env.sh.template spark-env.sh
执行vim spark-env.sh命令在文件中添加如下内容
export JAVA_HOME=/root/apps/java
export SPARK_MASTER_HOST=spark
export SPARK_MASTER_PORT=7077
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=10 -Dspark.history.fs.logDirectory=hdfs://spark:9000/spark"
export HADOOP_HOME=/root/apps/hadoop
export HADOOP_CONF_DIR=/root/apps/hadoop/etc/hadoop
复制一份
cp spark-defaults.conf.template spark-defaults.conf
执行vim spark-defaults.conf命令在文件中添加如下内容
spark.eventLog.enabled true
spark.eventLog.dir hdfs://spark:9000/spark
spark.eventLog.compress true
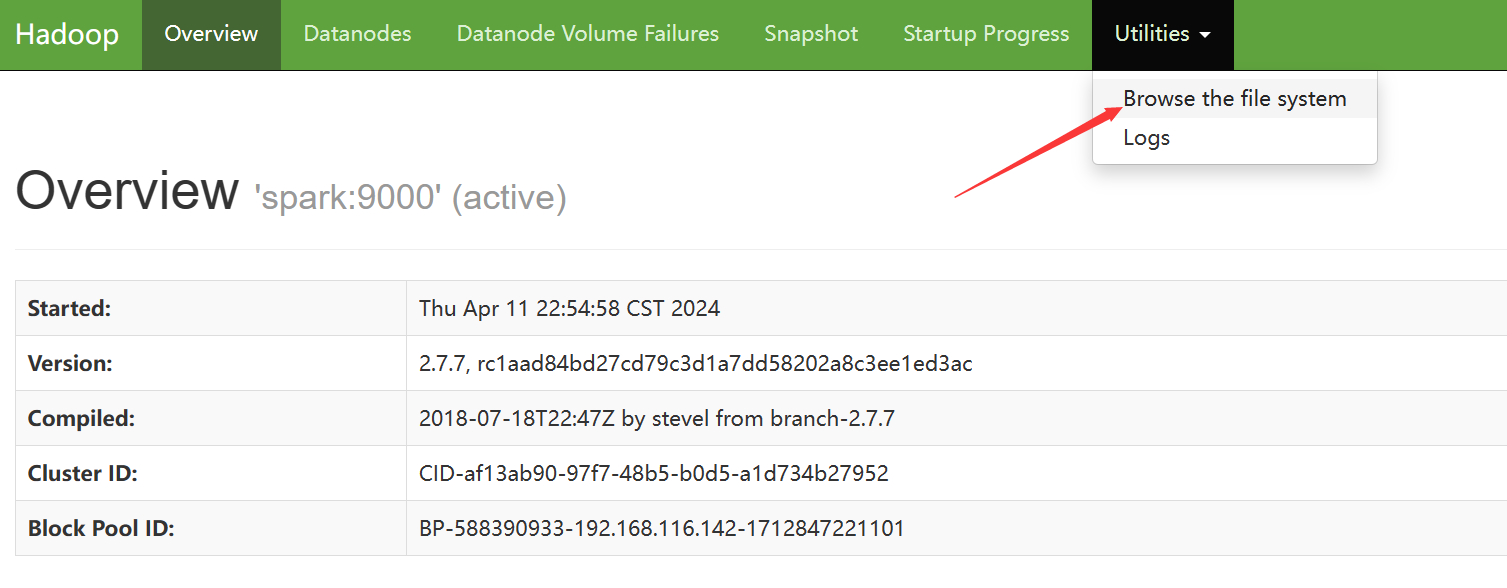
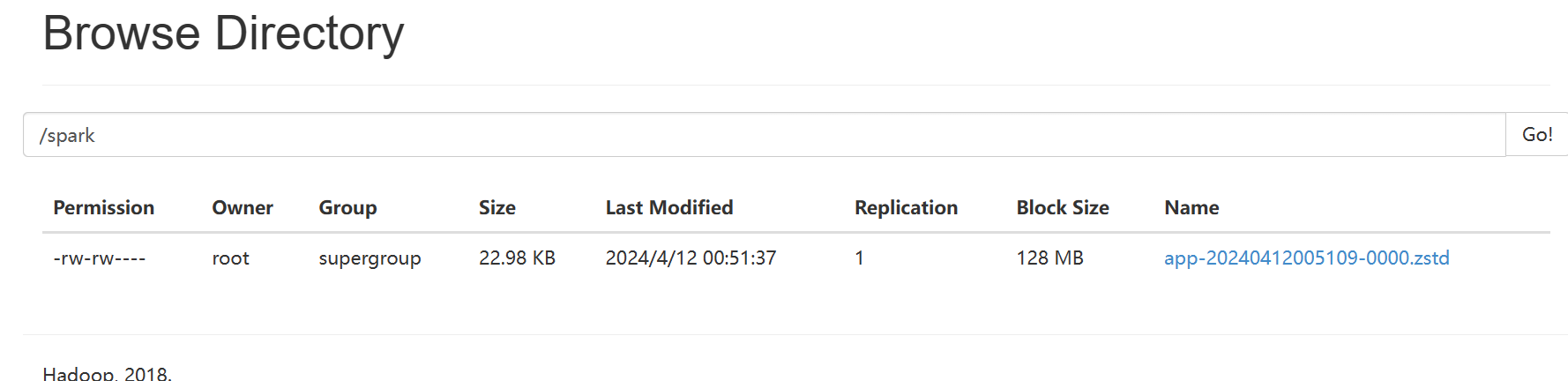
在HDFS中创建spark.eventLog.dir指定的目录
hdfs dfs -mkdir /spark
hdfs dfs -ls /

也可以在webUI里查看
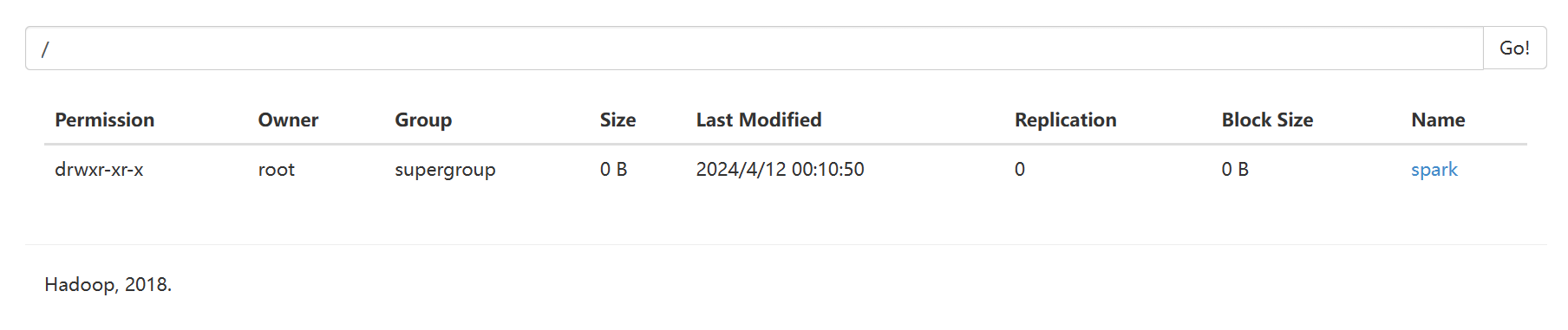
启动spark和historyServer
由于Hadoop里也有start-all.sh,所以这里给它改个名start-spark.sh

mv start-all.sh start-spark.sh
mv stop-all.sh stop-spark.sh

分别执行start-spark.sh和start-history-server.sh命令

测试Spark安装情况
通过jps命令查看相关进程,如果有Master、Worker和HistoryServer三个进程则集群环境部署成功。
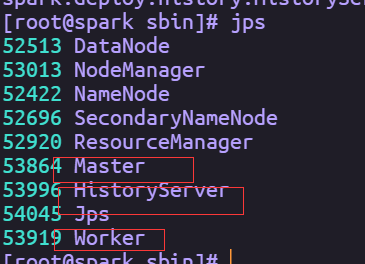
通过Web UI查看Spark集群(在浏览器输入ip:8080和ip:18080)
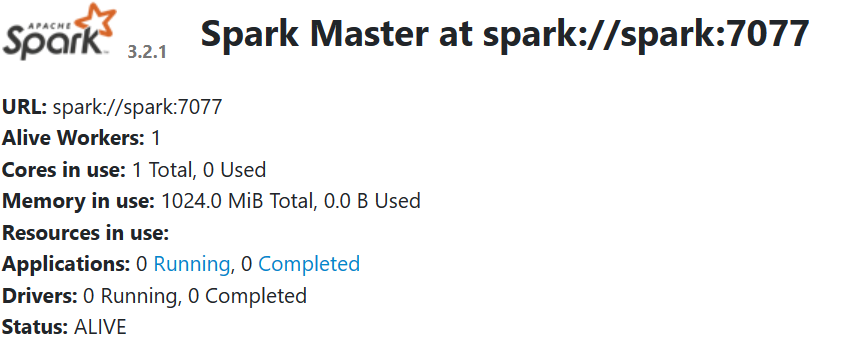
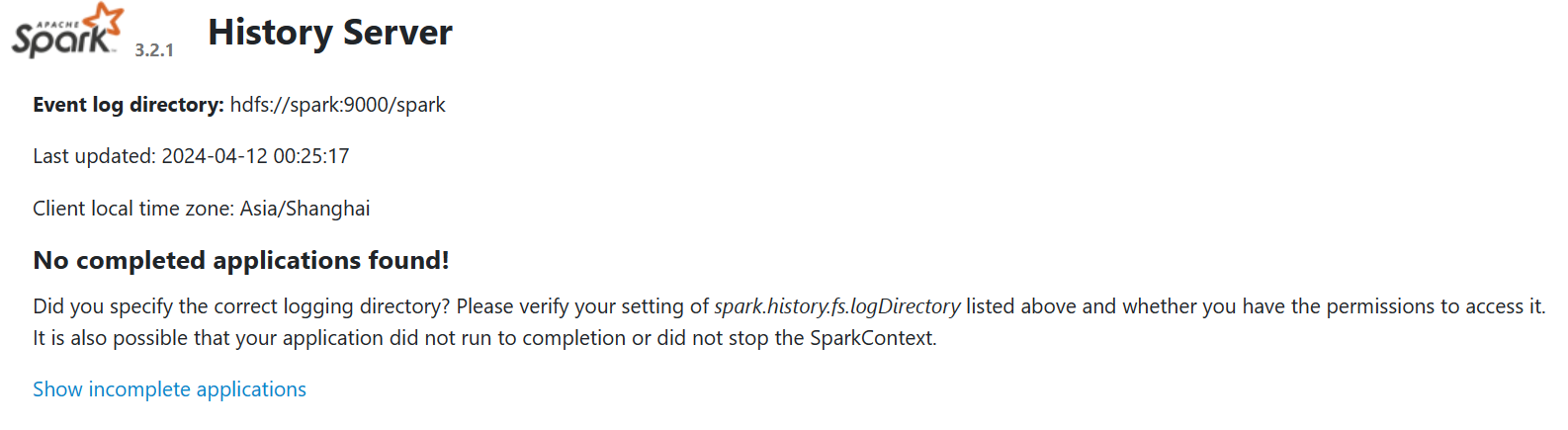
提交一个程序
项目结构,其中用到了Scala语言,关于它的配置,请自行查阅
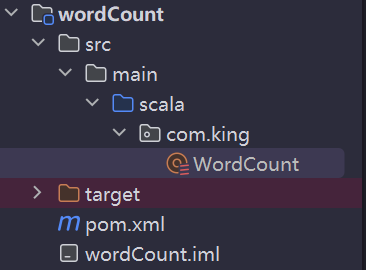
maven的pom文件,编译插件时必须的,不然打包不进去
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>com.king</groupId>
<artifactId>Spark</artifactId>
<version>1.0-SNAPSHOT</version>
</parent>
<artifactId>wordCount</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.5.1</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
单词计数代码
package com.king
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
val context = new SparkContext(conf)
val value = context.textFile(args(0))
val value1 = value.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
value1.saveAsTextFile(args(1))
context.stop()
}
}
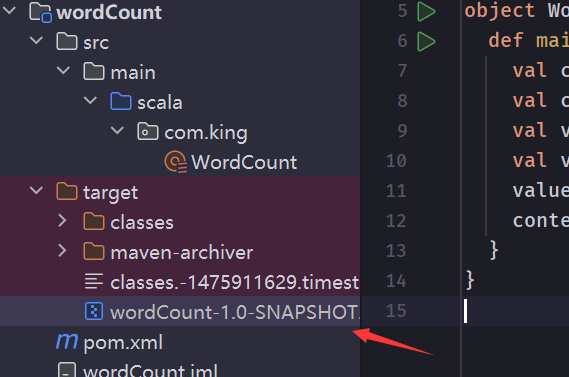
上传到虚拟机

创建一个word.txt文件vim word.txt,内容如下
java python c c++ c# javascript
mysql java c hadoop c mtsql python
Hbash java scala hadoop spark
spark spark scala
上传到hdfs
hdfs dfs -put ./word.txt /
hdfs dfs -ls /

提交程序到spark
spark-submit --master spark://spark:7077 --deploy-mode client --class com.king.WordCount ./wordCount-1.0-SNAPSHOT.jar hdfs://spark:9000/word.txt hdfs://spark:9000/result
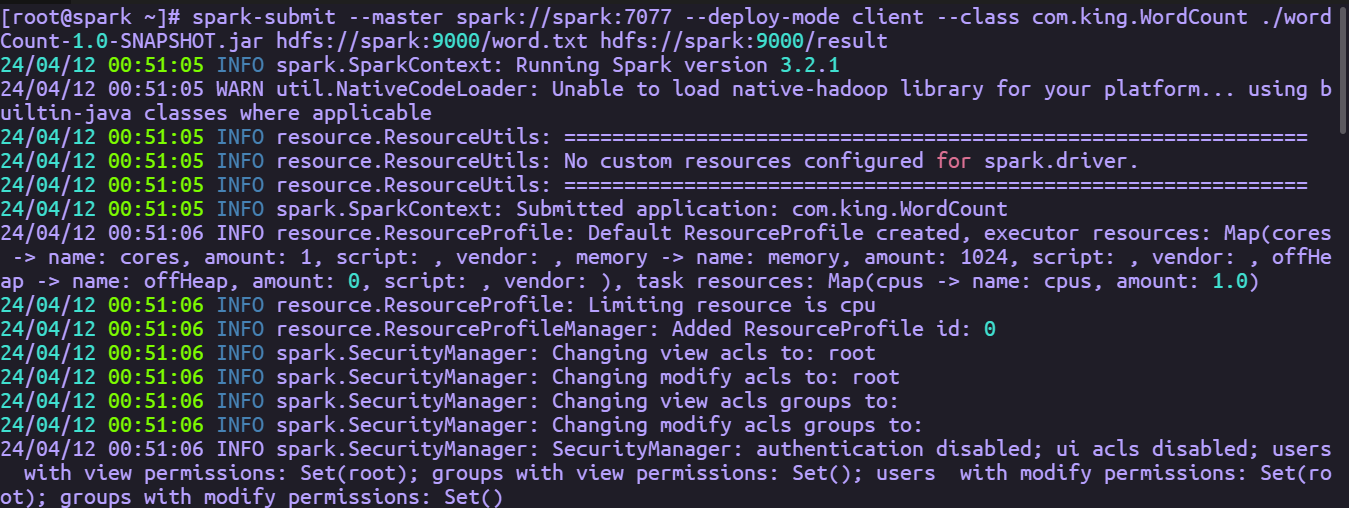
可以看到结果已经出来了,只展示了一部分
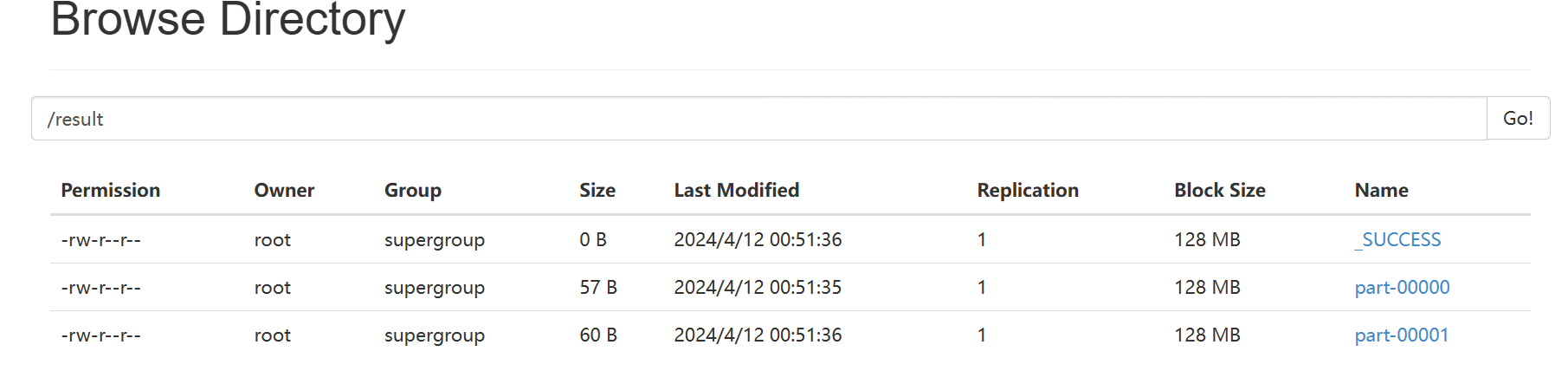

spark这边也有记录
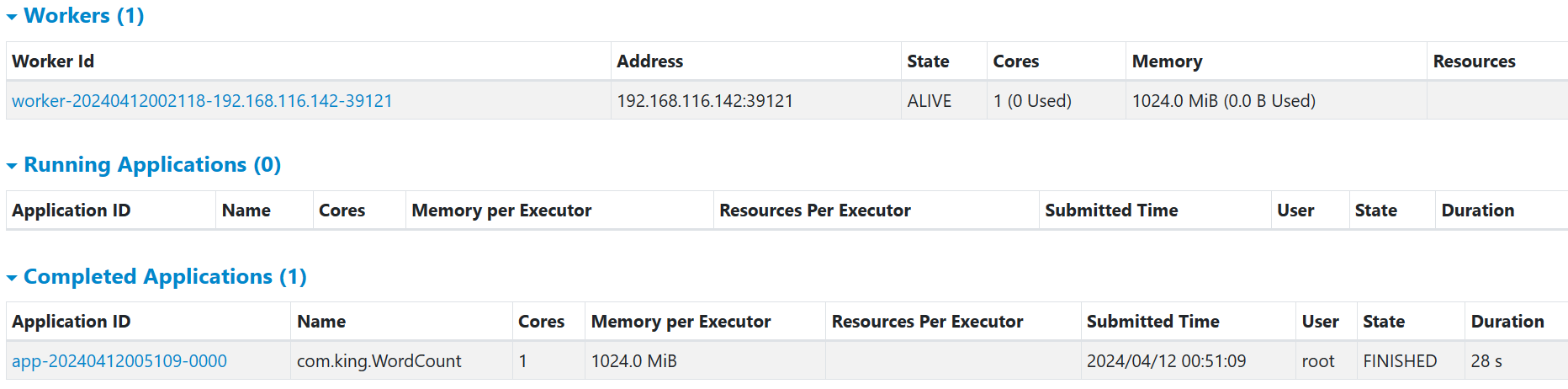
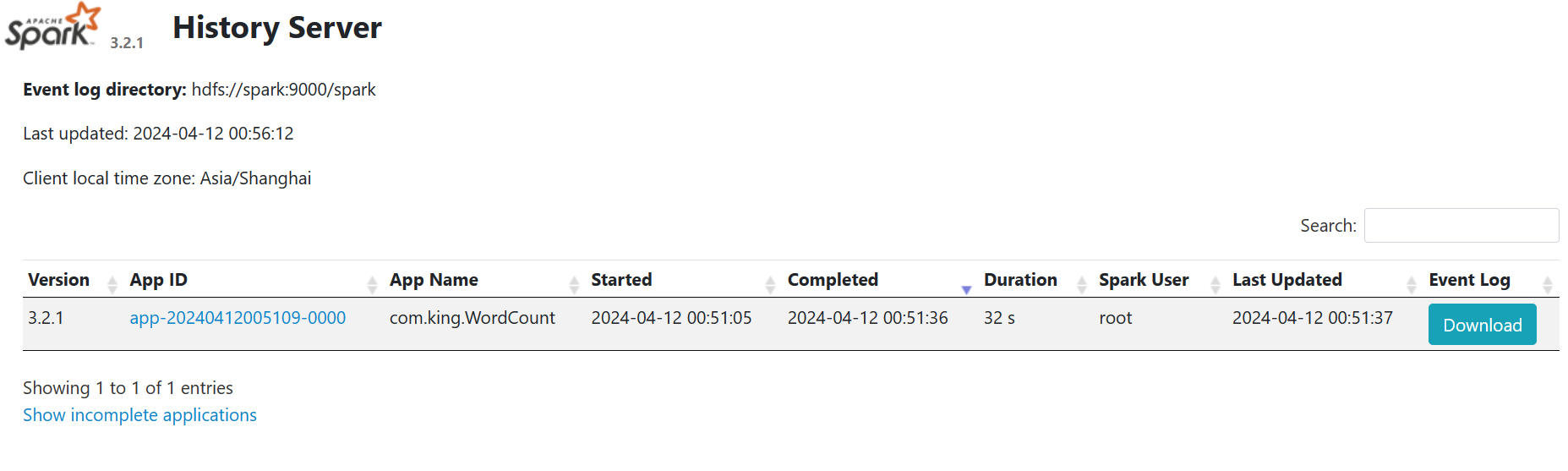
历史也有
结束语
终于结束了,啊啊啊啊啊啊啊啊啊啊啊啊😫
累计花费四个小时,太难了


 浙公网安备 33010602011771号
浙公网安备 33010602011771号