
通过字节码深入理解synchronized关键字
synchronized 解析
java中说到锁、不得不提的就是synchronized关键字、在jdk1.8中已经对该关键的实现方式做了很大的提升,具体看以下解析
- 说到synchronized加锁细节、就不得不谈到java的对象组成、说到这里很多人想、java对象不是jvm编译过后的字节码组成的嘛?拜托那是java的class文件是由字节码组成的、并且记录了class信息的字节码。而java对象不是、java对象一般由三部分组成、为什么说一般呢?因为有可能不是自然数据。
- 1、对象头信息
- 2、实例数据
- 3、对齐数据
- 4、如果该对象是数组还有一个数组的长度
对象头解析
对象头信息是什么呢?官方文档解释
object headerCommon structure at the beginning of every GC-managed heap object.
(Every oop points to an object header.) Includes fundamental information about the heap object’s layout, type, GC state, synchronization state, and identity hash >>>code.
Consists of two words. In arrays it is immediately followed by a length field.
Note that both Java objects and VM-internal objects have a common object header format.大致的意思就是每个对象开头的通用结构、其中包括对象的布局、类型、Gc状态、同步状态和标识hash码、有两个词组成。在数组中紧随其后的是长度字段。
那么是那两个字段呢?文档中也有描述
mark wordThe first word of every object header. Usually a set of bitfields including synchronization state and identity hash code. May also be a pointer (with characteristic >>>low bit encoding) to synchronization related information. During GC, may contain GC state bits.
大致的意思是、这是对象头的第一个单词、通常是一组位域、包括同步状态码、和省份散列码、也可以是一个用于同步相关的指针、在Gc期间、可能包含Gc状态位
klass pointerThe second word of every object header. Points to another object (a metaobject) which describes the layout and behavior of the original object. For Java objects, >>>the "klass" contains a C++ style "vtable".
class datameta address:大致的意思是每个对象头文件中的第二个单词它指向另一个对象(class对象)。就是一个指向class对象的一个指针。
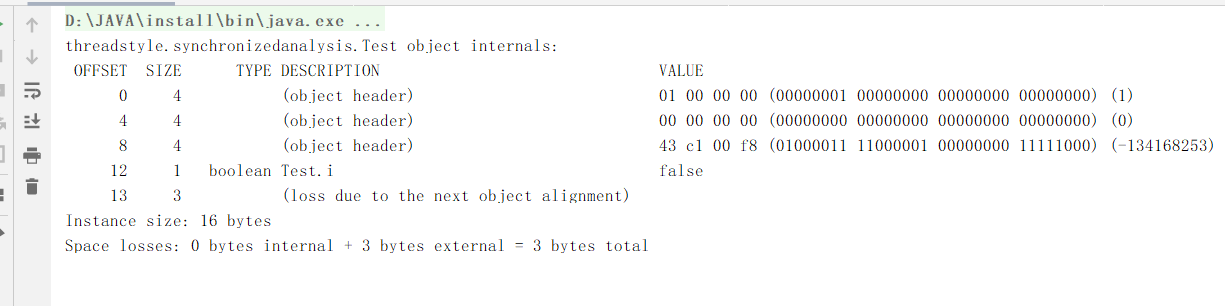
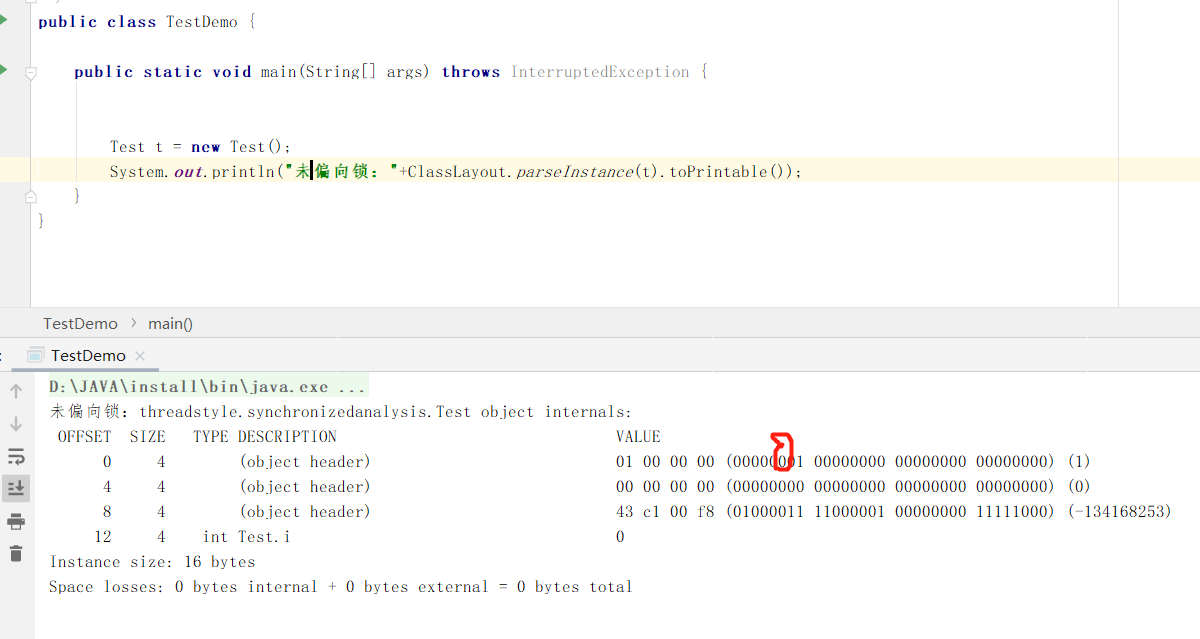
知道了这些我们想要知道一个对象有多大、可以使用jol工具来帮助我们<dependency> <groupId>org.openjdk.jol</groupId> <artifactId>jol-core</artifactId> <version>0.16</version> <scope>provided</scope> </dependency>新建一个Test对象、该对象只有一个i属性、是一个boolean类型
新建一个测试类、我们是由jol提供的方法、将对象信息打印出来
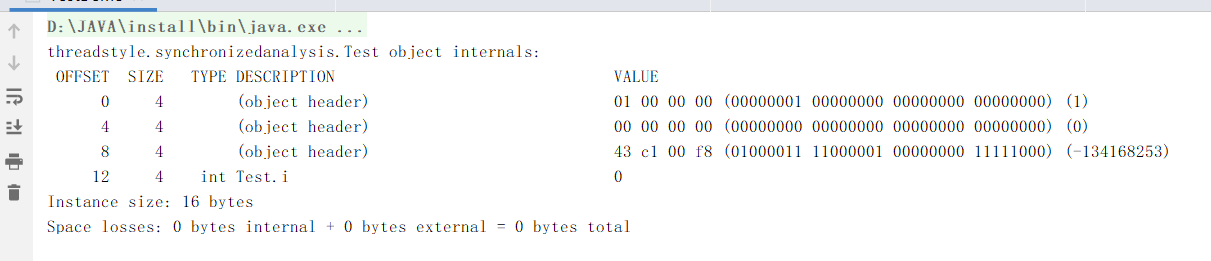
得到的输出
通过这个、我们大致可以看到刚才说的对象头的组成部分、对象头占了12byte(1byte=8位)、一个boolean类型的属性占了一个byte。还有3个byte的对齐数据。这个对齐数据是干嘛的呢?64位的jvm规定内存分配的字节必须是8的倍数、否则无法分配内存所以上面的情况对象头加上实例数据的大小菜13byte很明显不是8的倍数、所以会出现3byte的对齐数据。在举个例子。我们将Test中的属性i类型改变为int属性、在java中我们知道int占4个字节、我们在打出对象信息看看
得到的输出
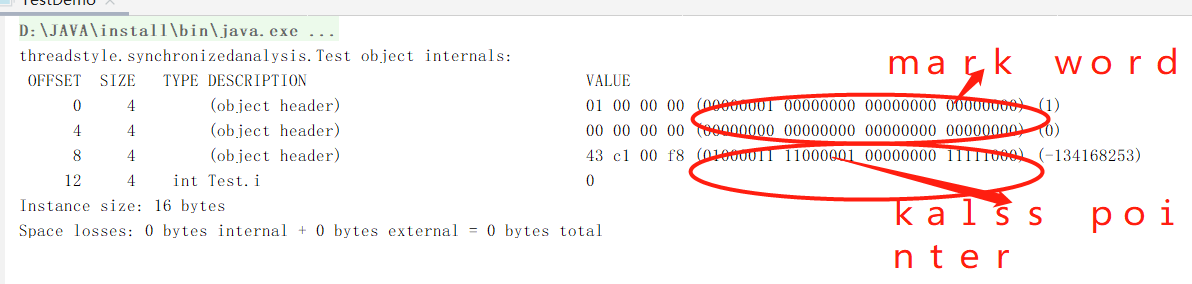
可以看到、这次就只有对象头信息、和实例数据信息、并且int类型占4个字节。整个对象头信息加起来是16byte是8的倍数、所以没有加对齐数据、至于为什么加对齐数据还和硬件层面的寻址有关系。具体不深究。这样我么知道了、对象确实由这些组成的。那么上面说的对象头信息包括的mark word 和klass pointer 在哪里呢?怎么去看?
我们知道jvm,jvm是什么?jvm只是一套规范。我们使用的jvm产品,当下使用普遍的jvm产品可能就是hotsprt这个是sun公司根据jvm规范开发出来的一个产品
hotsport是c++写的。其实很多大企业会有自己的jvm产品、所以要知道对象头里如何存储。我们在hotsport源码中找到了对mark word的如下描述
以64位为例、现在电脑以及服务器大多以64位、在64位虚拟机下、对象头中的mark word从前到后的顺序、25位未使用、31位表示hash码、一位未使用、4位表示分带年龄、1位表示偏向锁状态、两位表示锁状态。这加起来一共是62位(bit)是8个byte,刚才我们打印出的对象信息看到、对象头有12个byte、所以剩下的就是klass pointer 、占4个byte
有些资料上显示mark word占8个字节、klass pointer 也占八个字节、其实这个说法也是正确的、因为虚拟机默认开启了指针压缩。所以默认情况下klass pointer 占4个字节32(bit)



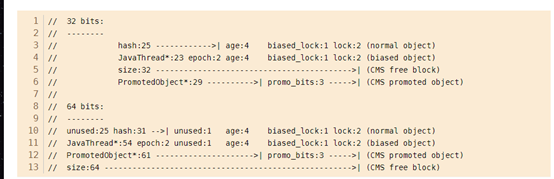
从上面我们已经看到mark word主要存放
- 1、哈希值
- 2、Gc分代年龄
- 3、偏向锁状态
- 4、线程可持有的锁状态
Mark word 会根据对象不同的状态、存放的也不相同
对象状态
- 1、无状态(刚被new出来)
- 2、偏向锁状态
- 3、轻量锁状态
- 4、重量锁状态
- 5、被垃圾回收标记的状态
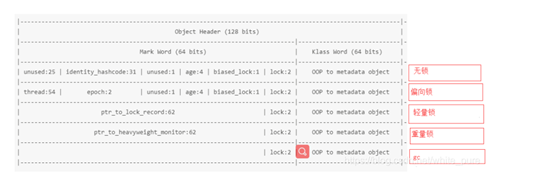
在mark word中有两位很关键、即表示锁状态的lock位
我们知道两位可以表示id状态无非就是00、01、10、11、而对象的状态有5种、那么另外一种如何表示?原来对象状态是由biased_locak和lock表示的 比如:
- biased_lock:0 lock:01 表示无状态
- biased_lock:1 lock:01 表示偏向锁
- biased_lock:0 lock:00 表示轻量锁
- biased_lock:0 lock:10 表示重量锁
- biased_lock:0 lock:11 表示被回收
以上只是看到的理论如此、那么到底、对象头中怎么存的?我们得看实际
刚才打印出的对象信息中看到这样的结果
可以看出mark word 应该是这一坨东西
这怎么和理论不一样呢?上面说有分代年龄、锁状态、哈希值什么的、这个怎么看起来全是0没有放什么数据。
注意:我们计算机大多使用大端存储、至于什么是大端存储这又得去看硬件的东西。至于什么是大端存储、就是将高位存在前面、理论描述的是25位未使用、31位hash值、1位未使用、4位分代年龄、1位偏向锁、2位锁状态。
而显示出来我们应该这么看、1位未使用、4位分代年龄、1位偏向锁、2位锁状态、31位hash值、25位未使用
然而这样看、依然有问题、hash值在哪呢?难道hash值不存在?怎么都是0?
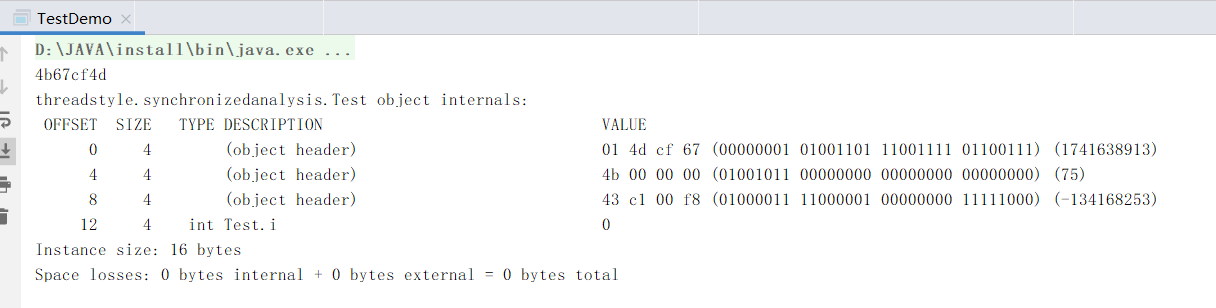
我们看到hashcode方法是一个本地方法、既是、这个也是由jvm虚拟机去实现的、当我们调用这个方法后、他才会将hash码计算出来、并写入对象头信息。接下来我们调用一下hashcode方法在打印对象信息
看起来好像有变化、那这个是我们的hash码值?
对应的数值是4b 67 cf 4d这是16进制、我们可以稍微装换一下
可以看到这里存放的确实是hash值!那么也就是说、第一个8位的最后两位存放的是锁状态。那么来看看、这两位如何变化





偏向锁
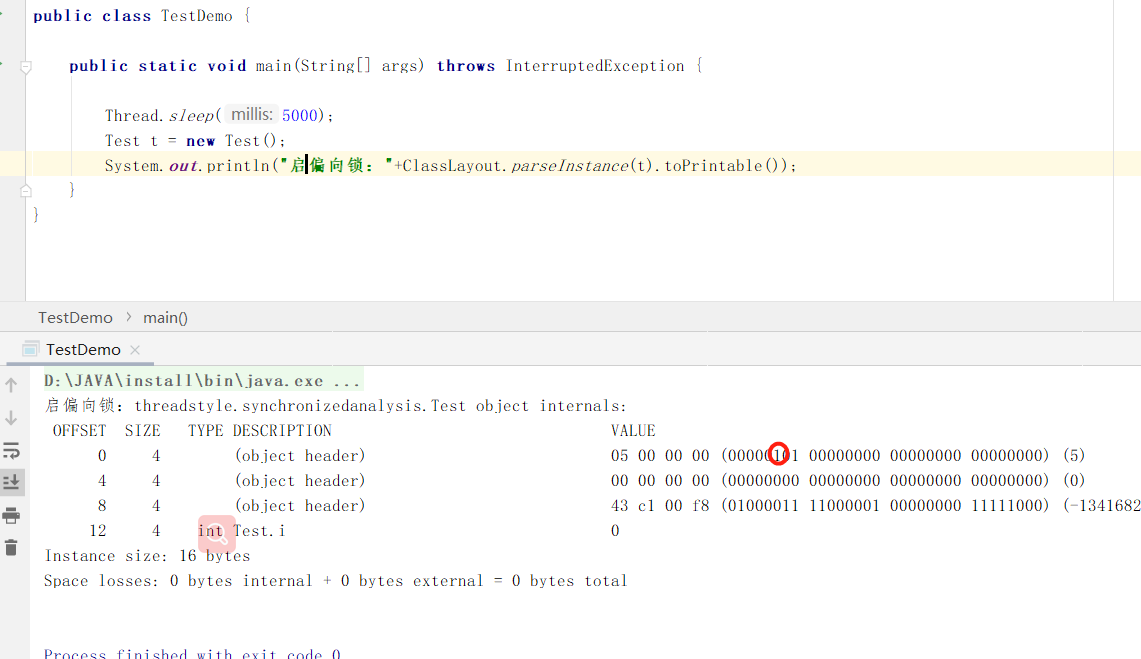
对象的偏向锁指的是、在大多情况下、锁不仅不存在多线程竞争、而且总是由一个线程多次获得。因此为了减少同一线程获取锁的代价而引入了偏向锁、偏向锁在获取资源的时候会在锁的对象的对象头上记录当前线程的id、偏向锁并不会自动释放 这样每次偏向锁进入的 时候都会判断对象头中线程id是否为自己。如果是则不需要进行额外的操作、直接进入同步代码块。这样就省区去了大量有关锁申请的操作、从而提供程序的性能,jvm默认延时4s开启偏向锁、也就是说jvm启动4s后、所有新建的对象才会开启偏向锁
未启用偏向锁
启用偏向锁
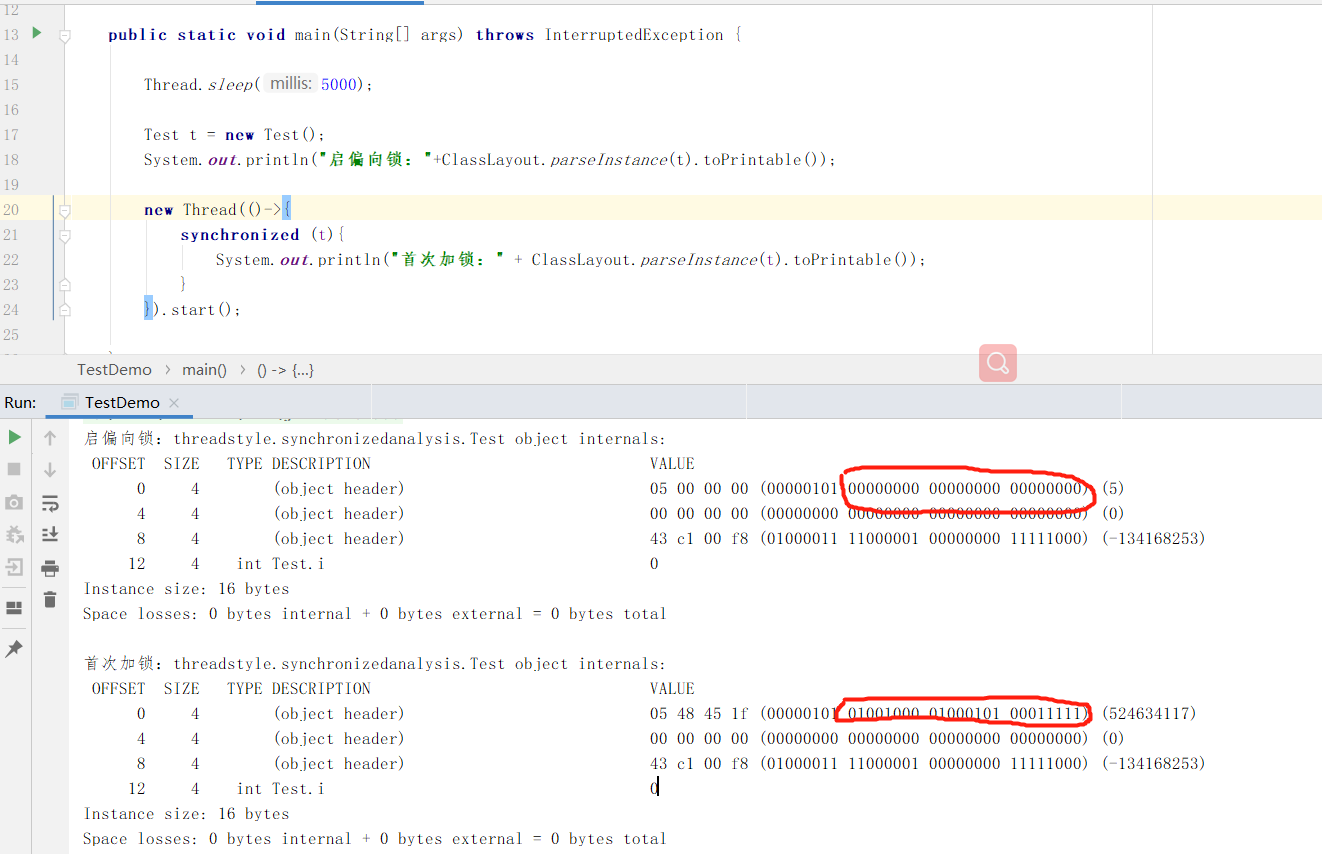
使线程休眠5s后创建对象、可以看到偏向锁位的值有变化。此时偏向锁已经开启。这时只是还没有写入线程id。当首次为该对象加锁时、就会将线程的id写入mark word。
偏向锁的获取过程:
当jvm开启偏向锁后、线程首先判断对象头中的线程id是不是当前线程、如果是直接进入同步代码块执行。如果不是需要通过cas操作讲mark word 中的线程id设置为当前线程id、然后执行同步代码。如果修改失败则表示有竞争、当达到safepoint时获得偏向锁的线程被挂起、偏向锁升级为轻量锁、然后阻塞在完全点的线程继续向下执行代码块
偏向锁的撤销过程:
偏向锁不会主动撤销(释放),只有遇到其他线程竞争时才会执行撤销、由于撤销需要知道当前持有该偏向锁的线程栈状态、因此要等到safepoint时执行、此时持有该偏向锁的线程有以下两种状态
- 1、撤销:线程已经退出同步代码块、或者已经不在存活、则直接撤销偏向锁、变成无锁状态--该状态达到阈值20则执行批量重偏向
- 2、升级:线程还在同步代码块中、则将线程的偏向锁升级为轻量级锁、当前线程执行轻量级锁状态下的锁获取步骤---该状态达到阈值40则执行批量撤销
批量重偏向/撤销
从偏向锁的撤销过程可以看到偏向锁需要等到safepoint才能进行锁升级/撤销。这种情况偏向锁不仅不能提高性能、反而会导致性能下降。思考一下。场面1:线程a创建了大量的对象、并进行初始的同步操作、这是这些对象的偏向锁都偏向线程a;之后线程b使用这些对象作为锁继续进行同步操作、则会存在大量的偏向锁撤销操作。场面2:存在明显多线程竞争时会存在大量偏向锁升级过程、为了解决这两个问题,jvm提供了批量重偏向/撤销机制
- 1、首先引入一个概念epoch,其本质是一个时间戳代表了偏向锁的有效性,epoch存储在可偏向对象的mark word 中,除了对象中的epoch ,对象所属类class信息中也会保存一个epoch值
- 2、每当遇到一个全局安全点、要对一个class C对象进行重偏向、则首先对class 类中保存的epoch进行增加、得到一个新的epoch_new
- 3、然后扫描所有持有class C实例的线程栈、根据线程栈的信息判断出该线程是否锁定了该对象、仅将epoch_new的值赋给被锁定的对象中、也就是说现在偏向锁还在被使用的对象才会被赋值epoch_new
- 4、退出安全点后、当有线程需要尝试获取偏向锁时、直接检查class c中存储的epoch值是否与目前线程的线程栈里的这个对象中存储的epoch值相等、如果不等、则说明该对象的偏向锁已经无效了、此时竞争线程可以尝试对此对象重新进行偏向操作、即通过cas操作将其Mark work的Thread id 改成当前线程id
- 5、当epoch达到重偏向阈值(默认20)时、jvm就认为该class的偏向锁偏向的线程有问题。因此会进行批量重偏向。当epoch达到批量撤销阈值(默认40)时、jvm就认为这个class不在适合偏向锁、就会批量撤销、并且之后的加锁过程中直接将该class的对象设置为轻量锁
轻量锁
轻量锁是相对于重量级锁需要阻塞/唤醒涉及上下文切换而言、主要针对多个线程在不同时间请求同一把锁的场景
Cas
cas是一种乐观锁认为任何操作都不会修改数据、只有在修改数据的时候才会上锁。大致流程、多线程访问到代码块时都可以获取到公共的临界变量的值。在修改的时候、首先记录获取的值、然后计算修改的值。在提交修改的时候、会将之前获取的值与磁盘的值作比较如果两个值相等、则表示当前变量没有做过修改、那么就将我么你计算的新值提交修改。如果两个值不等则在这个线程操作的时候有其他线程修改过这个值、那么就不会提交此次修改、这次操作被废弃、继续执行下一次操作。在这个流程中存在两个问题
- 操作是否保证原子性?
现在cas算法这种轻量锁、其实在jvm实现的时候在底层是由一把锁、来保证比较和修改的两个操作的原子性。也就是说jvm在实现cas算法的时候、比较和修改这两个操作中间不会被其他线程打断,所以原子性问题已经解决
- aba的问题
至于aba的问题、其实对最后的结果并没有什么影响、只是看自己的看法、如果非要解决的话、可以给数据加上一个version号、每次提交修改的版本号+1、每次修改不但比较值、还要比对版本号、如果两个一致才能提交修改
轻量锁的加锁过程
- 1、进行加锁操作时、jvm会判断是否已经是重量锁、如果不是、则会在当钱线程栈帧中画出一块空间作为该锁的锁记录、并将锁对象复制到该锁记录中。
- 2、复制成功后、jvm使用cas操作将对象头Mark word 更新为指向锁记录的指针并将锁记录里的owenr指针指向对象头的Mark word。更新成功后则当前线程持有锁、执行同步代码块!如果更新失败、jvm先检查对象的mark word 是否指向当前线程栈帧中的锁记录、如是是、表示锁重入、然后当前线程帧中增加一个锁记录第一部分(displaced Mark word)为null,并指向mark word的锁对象起到一个计数器的作用.如果不是当前线程栈帧中的锁记录、则表示该锁对象已被其他线程抢占、则进行自旋等待(默认10),等待次数到达阈值仍未获取到锁则升级为重量锁。
轻量锁的解锁过程
- 1、通过cas操作尝试把线程栈帧中复制的锁记录中的Displaced mark word 替换当前对象头的mark work(即还原对象头)。
- 2、如果替换成功则同步块执行顺利结束、。如果替换失败、则说明已经膨胀为重量级锁、则在执行完同步代码块释放锁的同时唤醒被挂起的线程。
重量级锁
重量级锁加锁过程
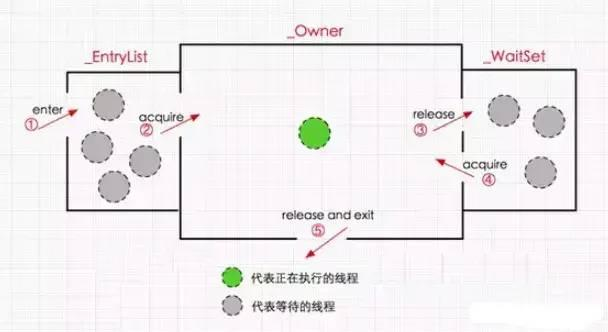
- 1、调用omalloc 分配一个ObjectMonitor 对象、修改mark word 锁状态的值、然后将mark word 存储指向Object Monitor 对象的指针。ObjectMonitor对象有两个队列和一个指针。每个需要获取锁的线程都包装成Object Waiter对象。
- 2、多个线程同时执行同一段同步代码时、ObjectWaiter先进入EntryList 队列、当某个线程获取到对象monitor以后进入owenr区域、并把monitor中的owenr变量设置为当前线程、同时monitor中的计数器count+1
重量锁的释放过程
- 1、若同步块中的线程调用wait方法、则释放持有的monitor、owenr遍历设置为null、count-1、同时线程进入Wairset等待被唤醒。
- 2、若当前同步代码块执行完毕、则也释放持有的monitor、owenr遍历设置为null、count -1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号