
余秀璇---第一次个人编程作业
| 博客班级 | 课程 |
|---|---|
| 作业要求 | 作业要求 |
| 作业目标 | 进行数据采集与处理生成词云图,并用git上传至自己的代码库 |
| 作业源代码 | 云仓库地址 |
| 学号 | 211806139 |
1.时间分配及代码行数
| 总时间 | 两天 |
|---|---|
| 分析题目 | 0.5h |
| 查找资料 | 3h |
| 编写代码 | 4h |
| 与同学讨论 | 1h |
| 代码行数 | 130行 |
2.爬取评论
在看到题目时第一反应就是要用上学期的爬虫知识写代码,但因为掌握不好以及有段时间没接触了忘得很彻底。感谢在班级博客里发爬虫代码的大佬,顺藤摸瓜重新学习了一下ajax和正则。


通过规律发现source的值是每次增加1,因此在代码中爬取“加载更多评论”中的代码只需要改变source的值。
获取评论的方法则使用了正则表达式,因为评论是被放在content中,所以使用findall和compile可以实现。
再加上爬取的量很大,因此代理是一定要有的,否则会遭遇反爬,出现爬取出重复评论。增加代理的方案博客里有大佬分享就不再提了
3.jieba分词器
在提供的三种分词器中选择了jieba分词器,另外两个有点看不懂就没选。参考了很多个百度案例后也算略懂怎么使用这个分词器,不过在分词的时候发现‘逆’和‘行者’会被拆开,需要手动增加词库。
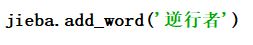
在分词之后发现会有很多单字,所以筛选是必要的

4.echarts词云图
一开始使用了wordcloud生成词云图,但群里通知需要使用echarts,就赶紧去找了一下这个js的用法。好在官网有代码可以下载,改一改数据之后就能使用。不过需要手动设置数据,有点麻烦。

5.上传github
上述全部做完就只差上传到自己的github了,跟着步骤一步步来就好了,没有难度。
遇到的困难
说实话,全都是困难。一开始爬虫不会,后面是分词器不会,最后又被echarts折磨,参考了很多代码之后才一一解决。唯一的心得就是不要急躁,问题早晚都会解决的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号