
bsdiff的基本原理
bsdiff是由Conlin Percival开源的一个优秀的差分算法,而且是跨平台的。在Android系统中所使用的imgdiff本质上就是bsdiff。
bsdiff的依据
在传统更新中,包含了复制和插入两种操作,复制指的是找到old文件中所匹配的部分,将其复制到新文件中。插入指的是将old文件中所没有的数据插入到新文件中。这种方式在二进制文件更新中并不适用,因为对源代码进行少量的修改就会导致二进制文件产生较大的差异,从而复制和插入指令增多,生成的更新包远大于理想状态。所以bsdiff并没有这样做,在一个新的二进制文件,往往会包含这样几部分:不受更新代码影响的部分,更新代码后直接影响的部分,更新代码后间接影响的部分。
不受更新代码影响的部分:这一区域变化非常稀疏,即使有变化也是部分指针或寄存器的地址进行了一两个字节的变动,这就导致字节差异几乎为0
更新代码后间接影响的部分:在更新了源代码后,有些代码和数据的地址会发生偏移,而且偏移值相同。
也就是说,在新旧两个文件中,源代码块相同的部分,字节差异为0或一个固定值,这个固定值就是地址变化的偏移量。由于这一特性,导致产生的数据将会是高度可压缩的。在bsdiff算法中会找到这两部分,求出字节差异,作为diff string并进行压缩保存。
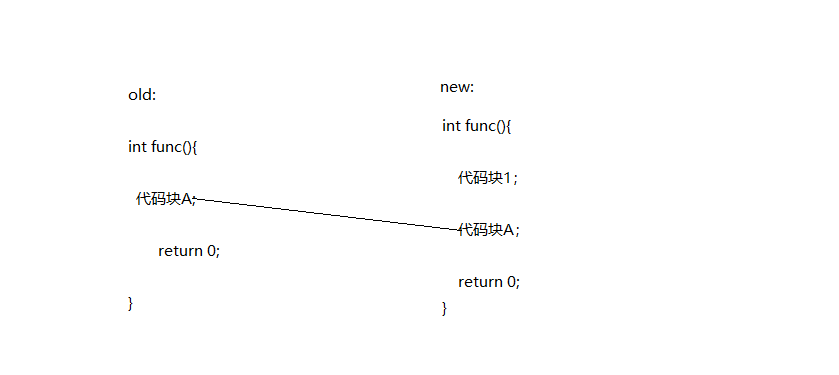
如图在old中添加代码块1(和代码块A不相关),在二进制文件中会导致代码块A的地址发生偏移,偏移值是相同的,这样old中的代码块A和new中的代码块A求字节差异时就会为一个固定值,具有高度可压缩性。
更新代码后直接影响的部分:如上图,当添加了代码块1后,会导致二进制文件产生新的数据,这部分数据在old中并不存在,bsdiff算法会将其作为extra string进行压缩保存。所以到这里我们能够得出bsdiff的更新数据=diff string+extra string。
bsdiff更新数据的基本结构
bsdiff更新数据由四部分组成:Header,ctrl block,diff block,extra block。
Header的结构:
| start/bytes | length/bytes | content |
| 0 | 8 | "BSDIFF40" |
| 8 | 8 | the length of ctrl block |
| 16 | 8 | the length of diff block |
| 24 | 8 | 新文件的大小 |
ctrl block:这部分内容是由(x,y,z)组成。x代表从old中读取x字节和diff block中读取x字节做字节加运算,y代表从extra block中读取y字节数据并且插入到新文件中,z代表在old中向前移动z字节。
diff block:记录了diff string,也就是字节的差值
extra block:记录了new文件中新生成的字节值
算法基本分析
bsdiff主要可以分为三部分:
1.通过排序技术对old文件的内容进行排序,形成字典序。这里的排序使用的是后缀排序时间复杂度nlogn,空间复杂度O(n),当然也可以使用hash技术进行排序。
2.通过二分法查找最长的匹配len,有了这个len,就可以计算出diff string,和extra string.
3.将diff string+extra string压缩到更新文件中。
关于后缀排序和二分法查找可以自行百度或google。下面边阅读代码边进行分析
off_t *I;
off_t scan,pos,len;
off_t lastscan,lastpos,lastoffset;
off_t oldscore,scsc;
off_t s,Sf,lenf,Sb,lenb;
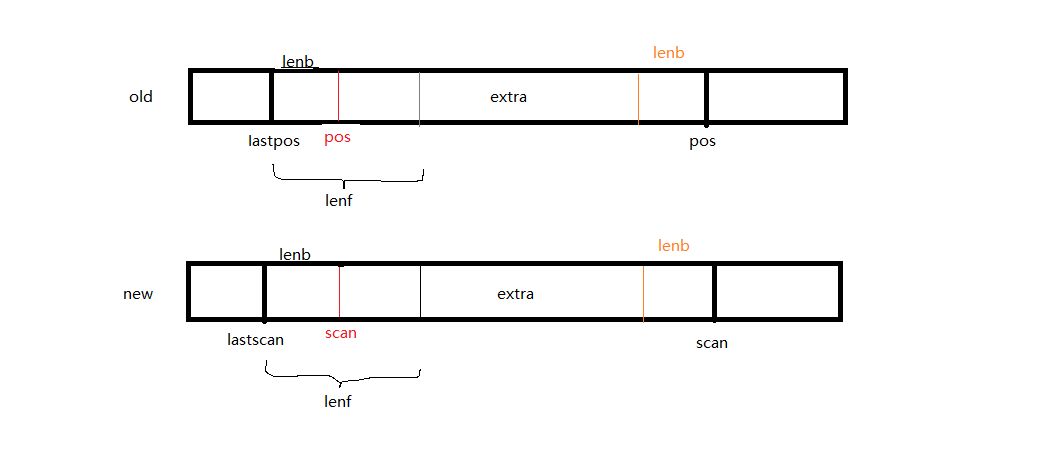
上面有几个变量代表的意义,对分析算法有着很重要的意义。I代表已经排好的字典序,scan代表new中要查询的字符,pos代表old中相匹配的字符,len代表匹配的长度,lastscan=scan-lenb,lastpos=pos-lenb。lastoffset=scan-pos。lastoffset为new和old的偏移量,如果在old中的内容A在new中可以找到,而且A+lastoffset=new中的A,则认为old和new中的A相同。oldscore代表相同内容的len,scsc代表new中开始和old中比较是否相同开始的位置,而old中开始的位置是scsc+lastoffset。lenf代表扩展前缀,lenb代表扩展后缀。
1 while(scan<newsize) {
2 oldscore=0;
3
4 for(scsc=scan+=len;scan<newsize;scan++) {
5 len=search(I,old,oldsize,new+scan,newsize-scan,
6 0,oldsize,&pos);
7 printf("len==%d\n",len);
8 for(;scsc<scan+len;scsc++)
9 if((scsc+lastoffset<oldsize) &&
10 (old[scsc+lastoffset] == new[scsc]))
11 oldscore++;
12
13 printf("oldscore+===%d\n",oldscore);
14
15 if(((len==oldscore) && (len!=0)) ||
16 (len>oldscore+8)) break;
17
18 if((scan+lastoffset<oldsize) &&
19 (old[scan+lastoffset] == new[scan]))
20 oldscore--;
21
22 printf("oldscore-====%d\n",oldscore);
23 };
24
25 if((len!=oldscore) || (scan==newsize)) {
26 printf("cal len=%d,scan=%d\n",len,scan);
27 s=0;Sf=0;lenf=0;
28 for(i=0;(lastscan+i<scan)&&(lastpos+i<oldsize);) {
29 if(old[lastpos+i]==new[lastscan+i]) s++;
30 i++;
31 if(s*2-i>Sf*2-lenf) { Sf=s; lenf=i; };
32 };
33 printf("Sf=%d,lenf=%d\n",Sf,lenf);
34 lenb=0;
35 if(scan<newsize) {
36 s=0;Sb=0;
37 for(i=1;(scan>=lastscan+i)&&(pos>=i);i++) {
38 if(old[pos-i]==new[scan-i]) s++;
39 if(s*2-i>Sb*2-lenb) { Sb=s; lenb=i; };
40 };
41 printf("Sb=%d,lenb=%d\n",Sb,lenb);
42 };
43
44 if(lastscan+lenf>scan-lenb) {
45 overlap=(lastscan+lenf)-(scan-lenb);
46 s=0;Ss=0;lens=0;
47 for(i=0;i<overlap;i++) {
48 if(new[lastscan+lenf-overlap+i]==
49 old[lastpos+lenf-overlap+i]) s++;
50 if(new[scan-lenb+i]==
51 old[pos-lenb+i]) s--;
52 if(s>Ss) { Ss=s; lens=i+1; };
53 };
54
55 lenf+=lens-overlap;
56 lenb-=lens;
57 };
58
59 for(i=0;i<lenf;i++)
60 db[dblen+i]=new[lastscan+i]-old[lastpos+i];
61 for(i=0;i<(scan-lenb)-(lastscan+lenf);i++)
62 eb[eblen+i]=new[lastscan+lenf+i];
63
64 dblen+=lenf;
65 eblen+=(scan-lenb)-(lastscan+lenf);
66
67 offtout(lenf,buf);
68 BZ2_bzWrite(&bz2err, pfbz2, buf, 8);
69 if (bz2err != BZ_OK)
70 errx(1, "BZ2_bzWrite, bz2err = %d", bz2err);
71
72 offtout((scan-lenb)-(lastscan+lenf),buf);
73 BZ2_bzWrite(&bz2err, pfbz2, buf, 8);
74 if (bz2err != BZ_OK)
75 errx(1, "BZ2_bzWrite, bz2err = %d", bz2err);
76
77 offtout((pos-lenb)-(lastpos+lenf),buf);
78 BZ2_bzWrite(&bz2err, pfbz2, buf, 8);
79 if (bz2err != BZ_OK)
80 errx(1, "BZ2_bzWrite, bz2err = %d", bz2err);
81
82 lastscan=scan-lenb;
83 lastpos=pos-lenb;
84 lastoffset=pos-scan;
85 };
86 };
这一部分是bsdiff的核心,主要的工作就是查询到len,比较new和old中的内容是否相同,如果len范围内都相同则直接进行下一次循环。如果不相同的字节数大于8或scan达到了最大则跳出对应的循环,开始生成lenf,lenb,extra数据等。lenf其实就是diff string,可以看到diff string就是由lastscan到scan与lastpos到pos这个区间得到的,这个区间会被划分为lenf,代表diff string,而剩下的部分即为extra string。lenf代表的扩展前缀,其实也就是diff string. lenb代表的是扩展后缀,会在下次生成diff string时包含进去。那么为什么要这样做呢?因为在匹配到最长的len后,bsdiff并不是直接将匹配到的内容打包,而是从lastscan到scan开始前向延伸进行后缀扩展,得到lenf,称为扩展前缀。在lastscan也包含了扩展后缀,扩展前缀和扩展后缀必须至少有50%与old相同。如图所示:
算法实例
下面以一个例子解释bsdiff运行过程:
old:abcdfghilklmnopqrstuvwxyz1234567890abcd
new:abcdffhijkluvaxyz123456789zxcvbnm
1.首先获取到字典序


1 qsufsort:I[0]==40,0, 2 qsufsort:I[1]==39,10, 3 4 qsufsort:I[2]==34,48,0abcd 5 6 qsufsort:I[3]==25,49,1234567890abcd 7 8 qsufsort:I[4]==26,50,234567890abcd 9 10 qsufsort:I[5]==27,51,34567890abcd 11 12 qsufsort:I[6]==28,52,4567890abcd 13 14 qsufsort:I[7]==29,53,567890abcd 15 16 qsufsort:I[8]==30,54,67890abcd 17 18 qsufsort:I[9]==31,55,7890abcd 19 20 qsufsort:I[10]==32,56,890abcd 21 22 qsufsort:I[11]==33,57,90abcd 23 24 qsufsort:I[12]==35,97,abcd 25 26 qsufsort:I[13]==0,97,abcdfghilklmnopqrstuvwxyz1234567890abcd 27 28 qsufsort:I[14]==36,98,bcd 29 30 qsufsort:I[15]==1,98,bcdfghilklmnopqrstuvwxyz1234567890abcd 31 32 qsufsort:I[16]==37,99,cd 33 34 qsufsort:I[17]==2,99,cdfghilklmnopqrstuvwxyz1234567890abcd 35 36 qsufsort:I[18]==38,100,d 37 38 qsufsort:I[19]==3,100,dfghilklmnopqrstuvwxyz1234567890abcd 39 40 qsufsort:I[20]==4,102,fghilklmnopqrstuvwxyz1234567890abcd 41 42 qsufsort:I[21]==5,103,ghilklmnopqrstuvwxyz1234567890abcd 43 44 qsufsort:I[22]==6,104,hilklmnopqrstuvwxyz1234567890abcd 45 46 qsufsort:I[23]==7,105,ilklmnopqrstuvwxyz1234567890abcd 47 48 qsufsort:I[24]==9,107,klmnopqrstuvwxyz1234567890abcd 49 50 qsufsort:I[25]==8,108,lklmnopqrstuvwxyz1234567890abcd 51 52 qsufsort:I[26]==10,108,lmnopqrstuvwxyz1234567890abcd 53 54 qsufsort:I[27]==11,109,mnopqrstuvwxyz1234567890abcd 55 56 qsufsort:I[28]==12,110,nopqrstuvwxyz1234567890abcd 57 58 qsufsort:I[29]==13,111,opqrstuvwxyz1234567890abcd 59 60 qsufsort:I[30]==14,112,pqrstuvwxyz1234567890abcd 61 62 qsufsort:I[31]==15,113,qrstuvwxyz1234567890abcd 63 64 qsufsort:I[32]==16,114,rstuvwxyz1234567890abcd 65 66 qsufsort:I[33]==17,115,stuvwxyz1234567890abcd 67 68 qsufsort:I[34]==18,116,tuvwxyz1234567890abcd 69 70 qsufsort:I[35]==19,117,uvwxyz1234567890abcd 71 72 qsufsort:I[36]==20,118,vwxyz1234567890abcd 73 74 qsufsort:I[37]==21,119,wxyz1234567890abcd 75 76 qsufsort:I[38]==22,120,xyz1234567890abcd 77 78 qsufsort:I[39]==23,121,yz1234567890abcd 79 80 qsufsort:I[40]==24,122,z1234567890abcd
2.new:abcdffhijkl-old:abcdfghilkl 字节值相减获得diffstring
3.new:uvaxyz123456789-old:uvwxyz123456789 字节值相减获得diff string
4.zxcvbnm作为extra string进行打包
5.通过bzip2压缩生成升级文件。bzip2具有高度可压缩性,非常适合bsdiff
参考链接:
bsdiff官方网站
http://www.daemonology.net/bsdiff/
bsdiff介绍
http://www.daemonology.net/papers/bsdiff.pdf
bsdiff理解
https://cloud.tencent.com/developer/article/1008518
bsdiff理解
https://blog.csdn.net/darling757267/article/details/80652267
编译bsdiff所遇到问题的解决方法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号