redis的每种数据类型都有起码两种底层编码
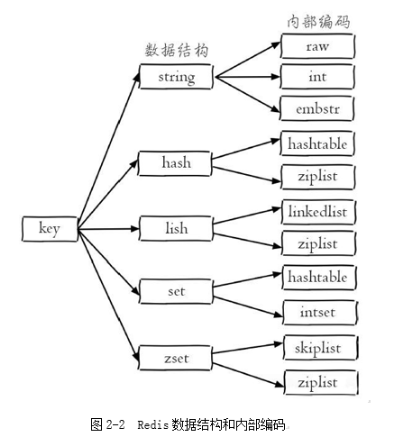
Redis 并没有直接使用这些数据结构来实现键值对的数据库,而是在这些数据结构之上又包装了一层 RedisObject(对象),每种数据类型对应一种redisObject对象
下面以Sting数据类型,来说明一下String数据类型创建的过程
typedef struct redisObject { unsigned type:4; unsigned encoding:4; unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or * LFU data (least significant 8 bits frequency * and most significant 16 bits access time). */
## 这里lru属性要不保存 LRU的信息 ,要不保存LFU的信息
## 最大24位无法保存完整的时间戳信息
## 所以,当保存LRU信息的时候,保存时间戳的低24位,最多能几多194天
## 当保存LFU信息的时候,高16位保存时间戳的低16位信息, 低8位保存访问频率,简称counter
## 但是由什么来决定呢?
## 请看下图
int refcount; void *ptr; } robj;
robj *createObject(int type, void *ptr) { robj *o = zmalloc(sizeof(*o)); o->type = type; ## 数据类型 o->encoding = OBJ_ENCODING_RAW; ## redis每种数据类型的内部编码,默认使用RAW的内部编码 o->ptr = ptr; ## 实际值的指针 o->refcount = 1; ## 引用计数 /* Set the LRU to the current lruclock (minutes resolution), or * alternatively the LFU counter. */ if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) { o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL; } else { o->lru = LRU_CLOCK(); }
## 可以看到,
## redisObject类中的lru属性是根据启动配置文件的内存驱逐策略来决定保存lru的信息还是lfu的新
## 但是问题来了,当切换内存驱逐策略的时候,例如当LRU 切换成 LFU的时候,redis是怎么操作的呢,这篇文章主要解决这个问题 return o; }
#define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44
robj *createStringObject(const char *ptr, size_t len) { if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT) return createEmbeddedStringObject(ptr,len); else return createRawStringObject(ptr,len); }
## 就是说 当String类型的value的大小小于等于44的时候,就会使用emb编码,大于则使用RAW
## 但是为什么是44呢,这是因为redis从2.8开始使用jemalloc内存分配器。这个比glibc的malloc要好不少,还省内存。
## 在这里可以简单理解,jemalloc会分配8,16,32,64等字节的内存。
## redis存储 为key和value,key对象最大16Byte,value由sdshdr存储,sdshdr请看下图 robj *createRawStringObject(const char *ptr, size_t len) { return createObject(OBJ_STRING, sdsnewlen(ptr,len)); } /* Create a string object with encoding OBJ_ENCODING_EMBSTR, that is * an object where the sds string is actually an unmodifiable string * allocated in the same chunk as the object itself. */ robj *createEmbeddedStringObject(const char *ptr, size_t len) { robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr8)+len+1); ## 使用sdshdr8 struct sdshdr8 *sh = (void*)(o+1); o->type = OBJ_STRING; o->encoding = OBJ_ENCODING_EMBSTR; o->ptr = sh+1; o->refcount = 1; if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) { o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL; } else { o->lru = LRU_CLOCK(); } sh->len = len; sh->alloc = len; sh->flags = SDS_TYPE_8; if (ptr == SDS_NOINIT) sh->buf[len] = '\0'; else if (ptr) { memcpy(sh->buf,ptr,len); sh->buf[len] = '\0'; } else { memset(sh->buf,0,len+1); } return o; }
struct __attribute__ ((__packed__)) sdshdr5 { unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
## sdshdr5 flags 低3位用来存类型,高5位用来存value长度,2的5次方=32 ,最大只能表示32,
## String的raw 和emb 以value长度为44为分界,所以sdshdr5 表示不了44
char buf[]; }; struct __attribute__ ((__packed__)) sdshdr8 { uint8_t len; /* used */ uint8_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[];
## sdshdr8 用8位表示长度value长度
## 用8位表示空闲空间
## flags占8位
## redisObject对象16个字节,value 结构3个字节, 加value值44个字节 加 空格符 1个字节 = 64个字节
## jemalloc 可以一次分配完 }; struct __attribute__ ((__packed__)) sdshdr16 { uint16_t len; /* used */ uint16_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[]; }; struct __attribute__ ((__packed__)) sdshdr32 { uint32_t len; /* used */ uint32_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[]; }; struct __attribute__ ((__packed__)) sdshdr64 { uint64_t len; /* used */ uint64_t alloc; /* excluding the header and null terminator */ unsigned char flags; /* 3 lsb of type, 5 unused bits */ char buf[]; };
LRU:
POOL: evict.c
#define EVPOOL_SIZE 16
struct evictionPoolEntry { unsigned long long idle; /* Object idle time (inverse frequency for LFU) */ sds key; /* Key name. */ sds cached; /* Cached SDS object for key name. */ int dbid; /* Key DB number. */ };
void evictionPoolPopulate(int dbid, dict *sampledict, dict *keydict, struct evictionPoolEntry *pool) { int j, k, count; dictEntry *samples[server.maxmemory_samples]; count = dictGetSomeKeys(sampledict,samples,server.maxmemory_samples);
## 根据maxmemory_samples获取keys
for (j = 0; j < count; j++) { unsigned long long idle; sds key; robj *o; dictEntry *de; de = samples[j]; key = dictGetKey(de); /* If the dictionary we are sampling from is not the main * dictionary (but the expires one) we need to lookup the key * again in the key dictionary to obtain the value object. */ if (server.maxmemory_policy != MAXMEMORY_VOLATILE_TTL) { if (sampledict != keydict) de = dictFind(keydict, key); o = dictGetVal(de); } /* Calculate the idle time according to the policy. This is called * idle just because the code initially handled LRU, but is in fact * just a score where an higher score means better candidate. */ if (server.maxmemory_policy & MAXMEMORY_FLAG_LRU) { idle = estimateObjectIdleTime(o);
## policy为lru时,计算idle Time } else if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) { /* When we use an LRU policy, we sort the keys by idle time * so that we expire keys starting from greater idle time. * However when the policy is an LFU one, we have a frequency * estimation, and we want to evict keys with lower frequency * first. So inside the pool we put objects using the inverted * frequency subtracting the actual frequency to the maximum * frequency of 255. */ idle = 255-LFUDecrAndReturn(o); } else if (server.maxmemory_policy == MAXMEMORY_VOLATILE_TTL) { /* In this case the sooner the expire the better. */ idle = ULLONG_MAX - (long)dictGetVal(de); } else { serverPanic("Unknown eviction policy in evictionPoolPopulate()"); } /* Insert the element inside the pool. * First, find the first empty bucket or the first populated * bucket that has an idle time smaller than our idle time. */ k = 0; while (k < EVPOOL_SIZE && pool[k].key && pool[k].idle < idle) k++; if (k == 0 && pool[EVPOOL_SIZE-1].key != NULL) { /* Can't insert if the element is < the worst element we have * and there are no empty buckets. */ continue; } else if (k < EVPOOL_SIZE && pool[k].key == NULL) { /* Inserting into empty position. No setup needed before insert. */ } else { /* Inserting in the middle. Now k points to the first element * greater than the element to insert. */ if (pool[EVPOOL_SIZE-1].key == NULL) { /* Free space on the right? Insert at k shifting * all the elements from k to end to the right. */ /* Save SDS before overwriting. */ sds cached = pool[EVPOOL_SIZE-1].cached; memmove(pool+k+1,pool+k, sizeof(pool[0])*(EVPOOL_SIZE-k-1)); pool[k].cached = cached; } else { /* No free space on right? Insert at k-1 */ k--; /* Shift all elements on the left of k (included) to the * left, so we discard the element with smaller idle time. */ sds cached = pool[0].cached; /* Save SDS before overwriting. */ if (pool[0].key != pool[0].cached) sdsfree(pool[0].key); memmove(pool,pool+1,sizeof(pool[0])*k); pool[k].cached = cached; } } /* Try to reuse the cached SDS string allocated in the pool entry, * because allocating and deallocating this object is costly * (according to the profiler, not my fantasy. Remember: * premature optimizbla bla bla bla. */ int klen = sdslen(key); if (klen > EVPOOL_CACHED_SDS_SIZE) { pool[k].key = sdsdup(key); } else { memcpy(pool[k].cached,key,klen+1); sdssetlen(pool[k].cached,klen); pool[k].key = pool[k].cached; } pool[k].idle = idle; pool[k].dbid = dbid; } }
int freeMemoryIfNeeded(void) { int keys_freed = 0; /* By default replicas should ignore maxmemory * and just be masters exact copies. */ if (server.masterhost && server.repl_slave_ignore_maxmemory) return C_OK; size_t mem_reported, mem_tofree, mem_freed; mstime_t latency, eviction_latency, lazyfree_latency; long long delta; int slaves = listLength(server.slaves); int result = C_ERR; /* When clients are paused the dataset should be static not just from the * POV of clients not being able to write, but also from the POV of * expires and evictions of keys not being performed. */ if (clientsArePaused()) return C_OK; if (getMaxmemoryState(&mem_reported,NULL,&mem_tofree,NULL) == C_OK) return C_OK; mem_freed = 0; latencyStartMonitor(latency); if (server.maxmemory_policy == MAXMEMORY_NO_EVICTION) goto cant_free; /* We need to free memory, but policy forbids. */ while (mem_freed < mem_tofree) { int j, k, i; static unsigned int next_db = 0; sds bestkey = NULL; int bestdbid; redisDb *db; dict *dict; dictEntry *de; if (server.maxmemory_policy & (MAXMEMORY_FLAG_LRU|MAXMEMORY_FLAG_LFU) || server.maxmemory_policy == MAXMEMORY_VOLATILE_TTL) { struct evictionPoolEntry *pool = EvictionPoolLRU; while(bestkey == NULL) { unsigned long total_keys = 0, keys; /* We don't want to make local-db choices when expiring keys, * so to start populate the eviction pool sampling keys from * every DB. */ for (i = 0; i < server.dbnum; i++) { db = server.db+i; dict = (server.maxmemory_policy & MAXMEMORY_FLAG_ALLKEYS) ? db->dict : db->expires; if ((keys = dictSize(dict)) != 0) { evictionPoolPopulate(i, dict, db->dict, pool); total_keys += keys; } } if (!total_keys) break; /* No keys to evict. */ /* Go backward from best to worst element to evict. */ for (k = EVPOOL_SIZE-1; k >= 0; k--) { if (pool[k].key == NULL) continue; bestdbid = pool[k].dbid; if (server.maxmemory_policy & MAXMEMORY_FLAG_ALLKEYS) { de = dictFind(server.db[pool[k].dbid].dict, pool[k].key); } else { de = dictFind(server.db[pool[k].dbid].expires, pool[k].key); } /* Remove the entry from the pool. */ if (pool[k].key != pool[k].cached) sdsfree(pool[k].key); pool[k].key = NULL; pool[k].idle = 0; /* If the key exists, is our pick. Otherwise it is * a ghost and we need to try the next element. */ if (de) { bestkey = dictGetKey(de); break; } else { /* Ghost... Iterate again. */ } } } }
server.c processCommand
if (server.maxmemory && !server.lua_timedout) { int out_of_memory = freeMemoryIfNeededAndSafe() == C_ERR;
unsigned long LFUDecrAndReturn(robj *o) {
unsigned long ldt = o->lru >> 8;//原来保存的时间戳
unsigned long counter = o->lru & 255; //原来保存的counter
unsigned long num_periods = server.lfu_decay_time ? LFUTimeElapsed(ldt) / server.lfu_decay_time : 0;
//server.lfu_decay_time默认为1,每经过一分钟counter衰减1
if (num_periods)
counter = (num_periods > counter) ? 0 : counter - num_periods;//如果需要衰减,则计算衰减后的值
return counter;
}
void updateLFU(robj *val) { unsigned long counter = LFUDecrAndReturn(val); counter = LFULogIncr(counter); val->lru = (LFUGetTimeInMinutes()<<8) | counter; } /* Low level key lookup API, not actually called directly from commands * implementations that should instead rely on lookupKeyRead(), * lookupKeyWrite() and lookupKeyReadWithFlags(). */ robj *lookupKey(redisDb *db, robj *key, int flags) { dictEntry *de = dictFind(db->dict,key->ptr); if (de) { robj *val = dictGetVal(de); /* Update the access time for the ageing algorithm. * Don't do it if we have a saving child, as this will trigger * a copy on write madness. */ if (!hasActiveChildProcess() && !(flags & LOOKUP_NOTOUCH)){ if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) { updateLFU(val); } else { val->lru = LRU_CLOCK(); } } return val; } else { return NULL; } }
unsigned long LFUDecrAndReturn(robj *o) { unsigned long ldt = o->lru >> 8; unsigned long counter = o->lru & 255; unsigned long num_periods = server.lfu_decay_time ? LFUTimeElapsed(ldt) / server.lfu_decay_time : 0; if (num_periods) counter = (num_periods > counter) ? 0 : counter - num_periods; return counter; }
struct redisCommand *lookupCommand(sds name) { return dictFetchValue(server.commands, name); }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号