1. Redis 和 memcache 的区别
1. memcache 多线程,需要依赖libevent这样的系统类 ,redis 单线程,Redis不需要依赖于操作系统中的类库
2. redis 支持5种数据类型,memcache只支持一种字符串类型
3. redis 支持两种持久化功能,rdb 和 aof , memcache 不支持持久化功能
4. redis 支持主从复制, memcache 不支持,但可以通过客户端实现
5. redis支持哨兵模式和集群模式实现故障自动迁移, memcache 分布式本身没有,需要通过客户端实现
6. redis和memcache内存管理的区别
redis :
redis使用malloc和free来进行内存分配,会导致内存碎片,加重操作系统内存管理器的负担,但是在4.0之后增加了自动回收内存碎片的功能,activedefrag
过期key:惰性删除 + 定期删除
- 惰性删除,当使用get命令获取key的时候,再进行判断是否过期,过期则删除key,并且不返回value。
- 定期删除: hz 参数控制,表示执行后台任务的频率,默认为10,此值越大表示redis对"间歇性task"的执行次数越频繁(次数/秒)。"间歇性task"包括"过期集合"检测、关闭"空闲超时"的连接等,不是全部设置了过期时间的键都检查,只是抽样检查
达到maxmemory时的处理:配合maxmemory-policy 和 maxmemory-samples
maxmemory-policy:
volatile-lru ## 利用LRU算法移除设置过过期时间的key。
volatile-random ## 随机移除设置过过期时间的key。
volatile-ttl ## 移除即将过期的key,根据最近过期时间来删除(辅以TTL)
allkeys-lru ## 利用LRU算法移除任何key。
allkeys-random ## 随机移除任何key。
noeviction ## 不移除任何key,只是返回一个写错误
举个栗子:
REDIS的LRU:按策略采样 N 个 key(max-memory-samples) ,淘汰访问时间离现在最久的一个 ---volatile从设置了过期时间的key中抽样,allkeys从所有key中抽样
memcache:
Memcached默认情况下采用了名为Slab Allocator的机制分配、管理内存,在该机制出现以前,内存的分配是通过对所有记录简单地进行malloc和free来进行的。但是,这种方式会导致内存碎片,加重操作系统内存管理器的负担,最坏的情况下,会导致操作系统比memcached进程本身还慢。Slab Allocator就是为解决该问题而诞生的。
过期key:惰性删除
- 跟redis 不太一样,同样是get key时判断是否过期,但是过期只是把key标志为过期,并不会真的去删除,当有新key 进来的时候,替换过期的key
先说memcache的几个概念:
Page为内存分配的单位
Memcached的内存分配以page为单位,默认情况下一个page是1M,可以通过-I参数修改,最小1K,最大128M。如果需要申请内存时,memcached会划分出一个新的page并分配给需要的slab区域。page一旦被分配在memcached重启前不会被回收或者重新分配
Slabs划分数据空间
Memcached并不是将所有大小的数据都放在一起的,而是预先将数据空间划分为一系列大小的slabs,每个slab只负责一定大小范围内的数据存储。每个slab只存储大于其上一个slab的size并小于或者等于自己最大size的数据。例如:slab 3只存储大小介于137 到 224 bytes的数据。如果一个数据大小为230byte的数据进行存储,它将被分配到slab 4中。每个slab负责的空间其实是不等的,memcached默认情况下下一个slab的最大值为前一个的1.25倍,这个可以通过修改-f参数来修改增长比例
Chunk才是存放缓存数据的单位
Chunk是一系列固定的内存空间,这个大小就是管理它的slab的最大存放大小。例如:slab 1的所有chunk都是104byte,而slab 4的所有chunk都是280byte。chunk是memcached实际存放缓存数据的地方,因为chunk的大小固定为slab能够存放的最大值,所以所有分配给当前slab的数据都可以被chunk存下。如果实际的数据大小小于chunk的大小,空余的空间将会被闲置,这个是为了防止内存碎片而设计的。举例来说,如果chunk size是224byte,而存储的数据只有200byte,剩下的24byte将被闲置。此外,memcached允许配置的最小的chunk空间为48个字节(key+value+flags),通过-n参数可以调节这个数值
达到maxmemory: memcache有三种LRU,Hot LRU , Warm LRU, COLD LRU
Hot LRU , Warm LRU都有特定的长度,当新数据访问,会放到Hot lru,然后末尾的元素插入到Warm LRU, warm lru末尾的元素插入到cold lru
当达到max memory 时,会从cold lru中剔除最久没有被访问的数据
内存驱逐策略LRU不是全局的,当不能为某个slab再分配页的时候,就会触发LRU机制,清除这个slab中最不经常使用的数据
Memcached在启动时通过-m指定最大使用内存,但是这个不会一启动就占用,是随着需要逐步分配给各slab的。 如果一个新的缓存数据要被存放,memcached首先选择一个合适的slab,然后查看该slab是否还有空闲的chunk,如果有则直接存放进去;或者替换已经标记为过期的键,如果没有则要进行申请。当没有内存页能够分配的时候(就是已经分配的内存达到启动时的-m参数),就会去驱逐策略去驱逐键
- 可以通过查看stats items 配置中的 evicted (没过期就被驱逐的次数),如果很多,表示这类slab要存的数据非常多,但是分配的页不够多
- 可以通过对比used_chunks,total_chunks, 三个参数,如果total chunks很多,但是used_chunks很少,差距是几个页的数量级,就证明以前这类slab有很多数据但现在没怎么用了,然后过期了。
根据以上情况,memcached 加入了页面重分配机制
- 自动重分配:启动配置 -o slab_reassign, slab_automove 若某个slab在10秒内出现3次eviction,则从过去30秒内没有出现eviction的slab里挪取一个内存页使用
- 手动重分配,启动配置 -o slab_reassign,在mc运行时输入echo "slabs reassign 1 4" | nc localhost 11211 把slab1 的一个页面移动到 slab4 中,有数据也能移动,剩一页就不能再移动
2. memcached 的LRU内存驱逐 和 page move 页移动
memcached的LRU就是靠item连接成的双向链表
但是新版本做了一些改变,将LRU分段了(Segmented LRU):将LRU分成了:HOT, WARM, COLD, TEMP
为什么要分段?主要是为了降低锁竞争,提升效率。
每个 item 有一个 flag,存储在其元数据中,标识其活跃程度:
- FETCHED:如果一个 item 有请求操作,其 flag 等于 FETCHED。
- ACTIVE:如果一个 item 第二次被请求则会标记为 ACTIVE;当一个 item 发生 bump 或被删除了,flag 会被清空。
- INACTIVE:不活跃状态。
item在他们之间的变化规则是这样的:
- 新来的item都加到HOT中
- 一个item被访问两次就标记为active状态
- (随着新item不断的加入),如果item移动到了链表的bottom。
- 如果是在HOT LRU中且为active状态,则把这个item直接移入WARM,否则加入COLD;
- 如果是在WARM中,且是active状态那么把这个item提到WARM链表的开头,否则移动到COLD中;
- COLD中的item是最惨的,他们都是inactive状态。当内存满了的时候就要开始淘汰他们中的一些
- COLD中的item如果变成了active状态后,会被放入队列,然后异步(注意是异步的哦)移动到WARM中
- HOT和WARM的大小是受限的,占该slab class内存量的N%, COLD 大小是不受限的
测试page move 和键驱逐的情况
代码1:
from pymemcache.client.hash import HashClient
server = [('localhost', 11211), ('localhost', 11212)]
server = server[:1]
if __name__ == '__main__':
print(server)
mc = HashClient(server)
count = 150000
while (count > 0):
key = "eee%.5d" % count
mc.set(key, "a", 30)
# mc.get(key)
print(key)
count -= 1
代码2:
from pymemcache.client.hash import HashClient
import uuid
server = [('localhost', 11211), ('localhost', 11212)]
server = server[:1]
if __name__ == '__main__':
print(server)
mc = HashClient(server)
count = 30000
while (count > 0):
key = "cccc%.5d" % count
value = str(uuid.uuid4()) + str(uuid.uuid4()) + str(uuid.uuid4())
mc.set(key, value)
# mc.get(key)
print(key)
count -= 1
执行代码1
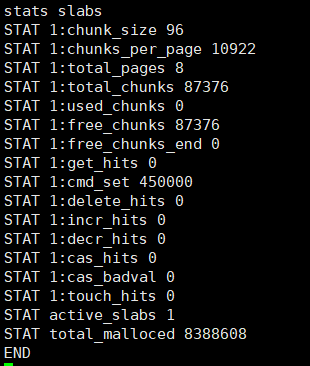
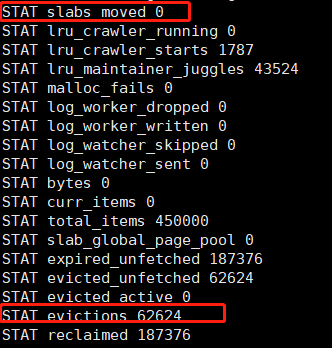
等slab1的item都过期,现在slab1中都是空的,执行代码2
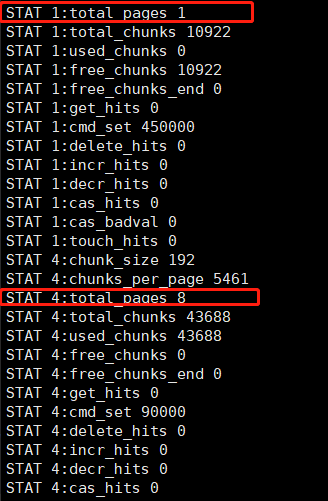
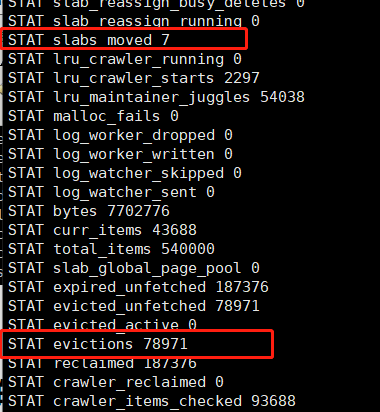
若某个slab在10秒内出现3次eviction,则从过去30秒内没有出现eviction的slab里挪取一个内存页使用
所以是现有key 的驱逐 再有page move
3.redis的LRU内存驱逐
redis并没有实现LRU策略
为什么redis不实现LRU策略?
维护一个lru 双向队列太占内存,改用以下方案:
Redis并不是直接基于字符串、链表、字典等数据结构来实现KV数据库,而是在这些数据结构上创建了一个对象系统Redis Object。在redisObject结构体中定义了一个长度24bit的unsigned类型的字段,用来存储对象最后一次被命令程序访问的时间
最初Redis是这样实现的:
- 随机选三个Key,把idle time最大的那个Key移除。后来,把3改成可配置的一个参数,默认为N=5:
maxmemory-samples 5 - 它还是有缺点的:每次随机选择的时候,并没有利用历史信息。在每一轮移除(evict)一个Key时,随机从N个里面选一个Key,移除idle time最大的那个Key;下一轮又是随机从N个里面选一个Key...有没有想过:在上一轮移除Key的过程中,其实是知道了N个Key的idle time的情况的,那我能不能在下一轮移除Key时,利用好上一轮知晓的一些信息?
- 当每一轮移除Key时,拿到了这个N个Key的idle time,如果它的idle time比 pool 里面的 Key的idle time还要大,就把它添加到pool里面去。这样一来,每次移除的Key并不仅仅是随机选择的N个Key里面最大的,而且还是pool里面idle time最大的,并且:pool 里面的Key是经过多轮比较筛选的,它的idle time 在概率上比随机获取的Key的idle time要大,可以这么理解:pool 里面的Key 保留了"历史经验信息"
- 采用"pool",把一个全局排序问题 转化成为了 局部的比较问题。(尽管排序本质上也是比较,囧)。要想知道idle time 最大的key,精确的LRU需要对全局的key的idle time排序,然后就能找出idle time最大的key了。但是可以采用一种近似的思想,即随机采样(samping)若干个key,这若干个key就代表着全局的key,把samping得到的key放到pool里面,每次采样之后更新pool,使得pool里面总是保存着随机选择过的key的idle time最大的那些key。需要evict key时,直接从pool里面取出idle time最大的key,将之evict掉。这种思想是很值得借鉴的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号