常见IO模型
任何技术的发展都是经过不断的演变迭代的,同样IO模型的演变代表着人们在计算机世界对效率的追求,对不同场景的解决方案,从某种方面来说IO模型的演变也一定程度见证着互联网的发展,随着学习的不断深入,也需要对底层实现原理不断加强。
接下来主要针对计算机网络、网络分层模型、网络协议以及重点的IO模型进行探讨,理解从网络通信到IO的发展演变。
计算网络
计算机网络也称计算机通信网。其定义是:一些相互连接的、以共享资源为目的的、自治的计算机的集合。按照这个定义,早期的面向终端的网络都不能算是计算机网络,而只能称为联机系统。
通信方式
随着计算机的发展以及计算机网络体系的复杂化,慢慢的对于计算机网络分层的必要性也就日趋明显,计算机之间的通信方式经历了演变发展,这影响的是后面对于复杂网络体系的分层关系,已经随之衍生的各种层面的网络协议。常见的计算之间通信的方式有如下几种:
- 联机

- 以太网
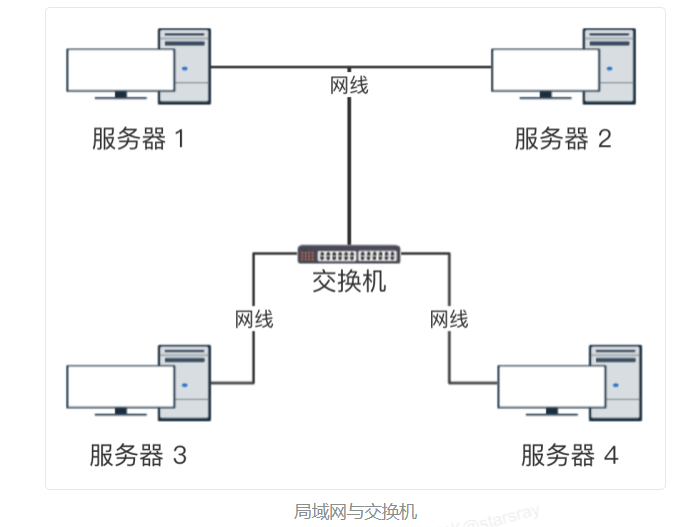
- 广播
主机之间“一对所有”的通讯模式,网络对其中每一台主机发出的信号都进行无条件复制并转发,所有主机都可以接收到所有信息(不管你是否需要)。
网络分层模型
计算机中,通常复杂的设计模型,都需要进行分层,分层的好处在于可以扩展、解耦,网络传输,可以理解为一块有格式的数据包(buffer或内存空间)在网络中流转,需要各个硬件以及软件协议间协调合作,封包、分包等。
常见的网络分层模型有OSI七层网络参考模型、TCP/IP四层、五层模型。如下图所示:
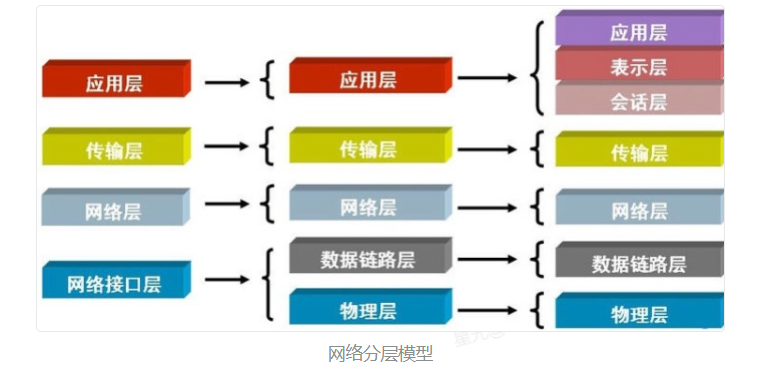
- 应用层
应用层协议定义的是应用进程间的通信和交互的规则,对于不同的网络应用需要不同的应用层协议。
- 表示层
对来自应用层的命令和数据进行解释,对各种语法赋予相应的含义,并按照一定的格式传送给会话层。其主要功能是处理用户信息的表示问题,如编码、数据格式转换和加密解密等。
- 会话层
向两个实体的表示层提供建立和使用连接的方法。将不同实体之间的表示层 的连接称为会话。因此会话层的任务就是组织和协调两个会话进程之间的通信,并对数据交换进行管理。 用户可以按照半双工、单工和全双工的方式建立会话。
- 传输层
向用户提供可靠的端到端的差错和流量控制,保证报文的正确传输。传输层的作用是向高层屏蔽下层数据通信的细节,即向用户透明地传送报文。传输层提供会话层和网络层之间的传输服务,这种服务从会话层获得数据,并在必要时,对数据进行分割。然后,传输层将数据传递到网络层,并确保数据能正确无误地传送到网络层。因此,传输层负责提供两节点之间数据的可靠传送,当两节点的联系确定之后,传输层则负责监督工作。综上,传输层的主要功能如下:监控服务质量
- 网络层
在发送数据时,网络层把运输层产生的报文段或用户数据报封装成分组和包进行传送。网络层的另一个任务就是选择合适的路由,使源主机传输层所传下来的分组,能通过网络层中的路由器找到目的主机。一般地,数据链路层是解决同一网络内节点之间的通信,而网络层主要解决不同子网间的通信。例如在广域网之间通信时,必然会遇到路由(即两节点间可能有多条路径)选择问题
- 数据链路层
该层的主要功能是:通过各种控制协议,将有差错的物理信道变为无差错的、能可靠传输数据帧的数据链路。在两个相邻节点之间传送数据时,数据链路层将网络层交下来的 IP 数据报组装程帧,在两个相邻节点间的链路上传送帧。每一帧包括数据和必要的控制信息(如同步信息,地址信息,差错控制等)。在计算机网络中由于各种干扰的存在,物理链路是不可靠的。因此,这一层的主要功能是在物理层提供的比特流的基础上,通过差错控制、流量控制方法,使有差错的物理线路变为无差错的数据链路,即提供可靠的通过物理介质传输数据的方法。数据链路层的具体工作是接收来自物理层的位流形式的数据,并封装成帧,传送到上一层;同样,也将来自上层的数据帧,拆装为位流形式的数据转发到物理层;并且,还负责处理接收端发回的确认帧的信息,以便提供可靠的数据传输
- 物理层
物理层上所传送的数据单位是比特。物理层的作用是实现相邻计算机节点之间比特流的透明传送,尽可能屏蔽掉具体传输介质和物理设备的差异。使其上面的数据链路层不必考虑网络的具体传输介质是什么。“透明传送比特流” 表示经实际电路传送后的比特流没有发生变化,对传送的比特流来说,这个电路好像是看不见的。
数据包在传送时会按照一定的格式进行封包,每经过一层都会进行对应的头部封装,接收时按照头部进行拆包,一个设备工作在哪一层,关键看它工作时利用哪一层的数据头部信息。网桥工作时,是以 MAC 头部来决定转发端口的,因此是数据链路层的设备。
每层运行常见的物理设备:
- 物理层:网卡、网线、集线器、中继器、调制解调器
- 数据链路层:网桥、交换机、网卡
- 网络层:路由器、三层交换机
- 传输层:网关、四层交换机、四层路由器
每层运行常见的协议:
- 应用层:应用自定义等,如HTTP协议
- 传输层:TCP与UDP协议
- 网络层:IP协议
- 数据链路层:arp协议
常见网络协议
在不同的网络分层中,运行的终端设备也不相同,同样使用的网络协议也各有差异,每种协议也是尽可能的发挥出硬件的效率。每种协议所工作的分层区域,如下图所示:
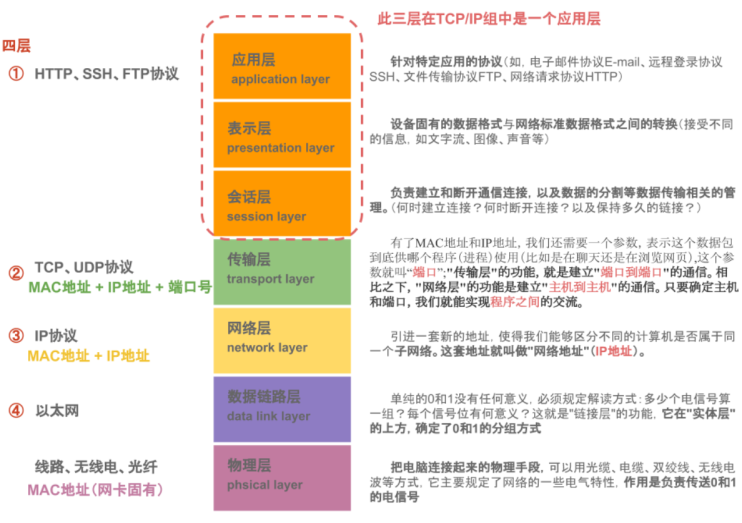
上面只是列举了在不同分层中常见协议,TCP/IP是一个协议簇,TCP协议和IP协议是其中最具有代表性的两个协议,因此以他们进行命名,如下图所示,可以看到更多的TCP/IP的实现细节,每一种协议都不是独立运行的或者是没有具体的意义,需要共同组合构建互联网的强大体系。
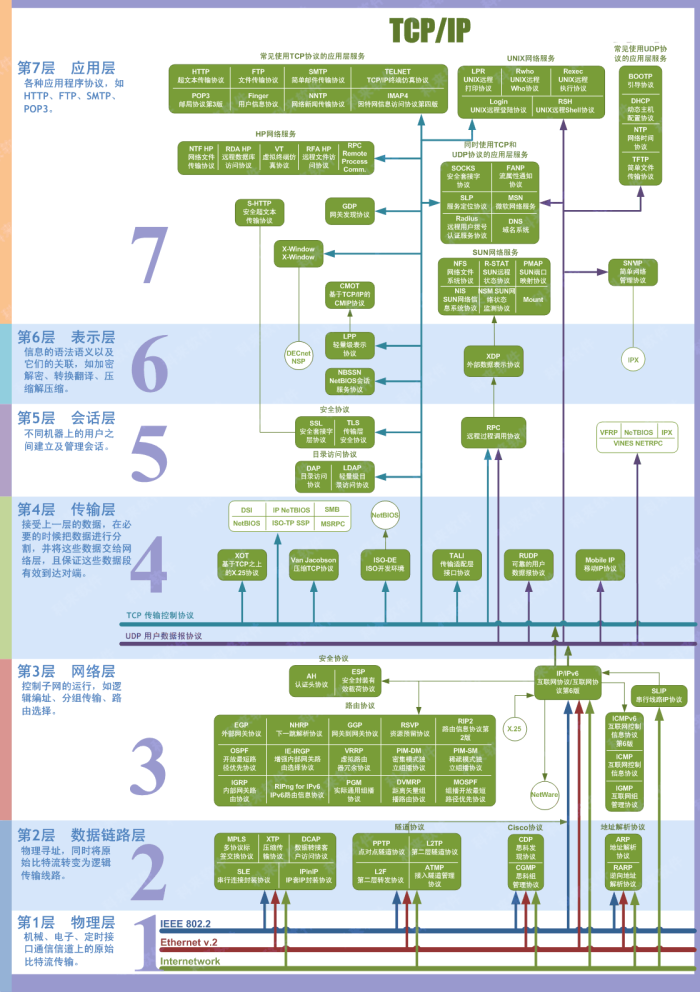
TCP/IP
- IP协议
简单来说,IP协议是工作在OSI七层参考模型中的网络层,用来进行主机与主机之间的通信,每一台主机在同一网络范围内都一个一个唯一的IP地址。
- mac地址
接入互联网的每一个主机除了拥有IP之外,都需要有网卡设备,网卡是每台设备接入互联网的必须硬件模块,每块网卡出厂时都被烧制上一个世界唯一的mac地址,长度为48位2进制,通常由12位16进制数表示(前六位是厂商编号,后六位是流水线号)。
- ARP协议
ARP协议,即地址解析协议(Address Resolution Protocol),可以根据IP地址获取物理地址,是TCP/IP协议簇中的重要组成。
关于IP协议的详细内容:https://www.cnblogs.com/red-code/p/7132023.html
- TCP协议
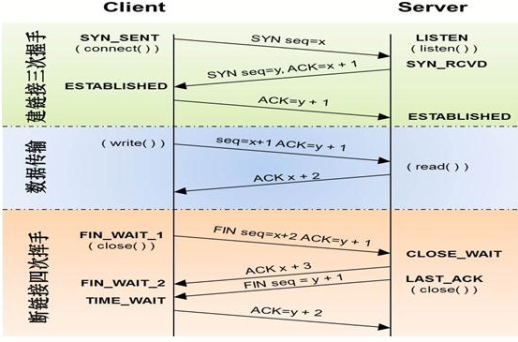
TCP协议是在传输层工作的协议,是一个面向连接的可靠的传输协议。其存在的意义在于构建可靠的稳定的传输链接。基于TCP的协议有很多,如FTP、Telnet、SMTP、HTTP、POP3等。可靠性的实现依赖于三次握手和四次挥手,如下示意图所示:
先使用tcpdump命令进行网卡和端口的监听
tcpdump -nn -i eth0 port 443
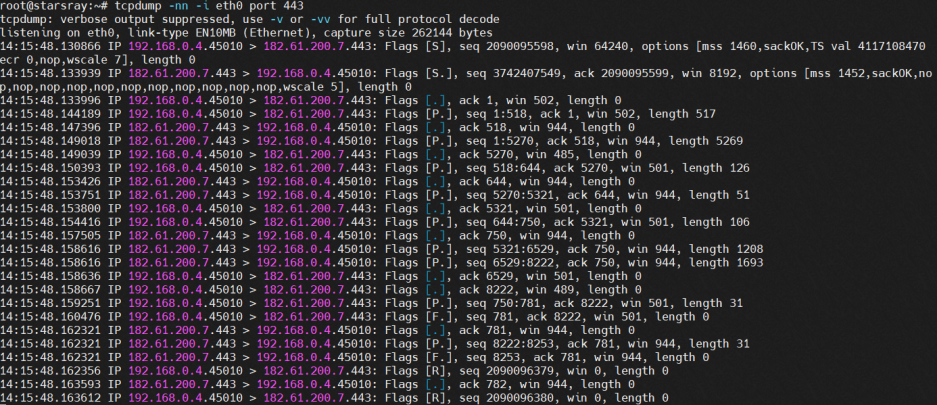
关于输出内容的解读,可以使用man tcpdump命令,然后搜索关键词进行指令解释查看。
The general format of a TCP protocol line is:
src > dst: Flags [tcpflags], seq data-seqno, ack ackno, win window, urg urgent, options [opts], length len. Src and dst are the source and destination IP addresses and ports.
Tcpflags are some combination of S (SYN), F (FIN), P (PUSH), R (RST), U (URG), W (ECN CWR), E (ECN-Echo) or.' (ACK), ornone' if no flags are set. Data-seqno describes the portion of sequence space covered by the data in this packet (see example below). Ackno is sequence number of the next data expected the other direction on this connection. Window is the number of bytes of receive buffer space available the other direction on this connection. Urg indicates there is `urgent' data in the packet. Opts are TCP options (e.g., mss 1024). Len is the length of payload data.
其中对应标志含义分别如下:
● > : 表示数据传递方向
● S. : SYN + ACK,以此类推
以下命令为使用curl进行一个完整的连接,从发起及结束
curl https://www.baidu.com
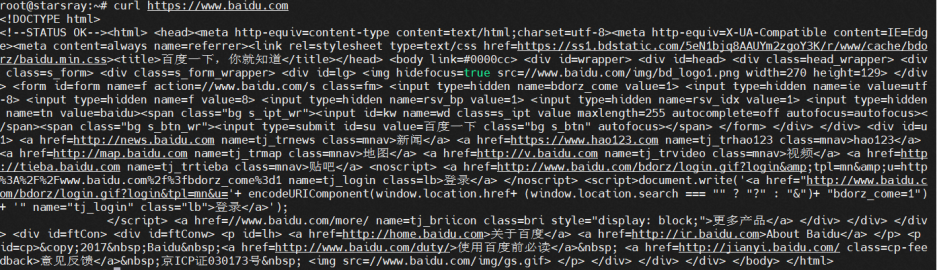
需要注意的是TCP在数据传输中会出现粘包现象,TCP粘包就是指发送方发送的若干包数据到达接收方时粘成了一包,从接收缓冲区来看,后一包数据的头紧接着前一包数据的尾,出现粘包的原因是多方面的,可能是来自发送方,也可能是来自接收方。从上面的tcpdump命令执行的结果中也可以看到数据被拆分的现象,当发送端缓冲区的长度大于网卡的MTU时,TCP会将这次发送的数据拆成几个数据包发送出去。 MTU是网卡上传送的最大数据包,单位是字节。 大部分网络设备的MTU都是1500。如果本机的MTU比网关的MTU大,大的数据包就会被拆开来传送,这样会产生很多数据包碎片,增加丢包率,降低网络速度。
UDP
UDP用户数据报协议,是一个无连接的简单的面向数据报文的传输层协议。UDP不提供可靠性,它只是把应用程序传给IP层的数据报发送出去,但是并不能保证它们能到达目的地。由于UDP在传输数据报前不用在客户和服务器之间建立一个连接,且没有超时重发等机制,故而传输速度很快。
TCP和UDP协议最明显的区别类似于打电话和写信两种传统的通信方式,TCP需要交互双方实时阻塞参与,是有状态的,而UDP则不关心接收结果,只关心数据发送。基于UDP的应用也很多,如DNS、SNMP等。
Socket
Socket是对TCP或者UDP协议的封装和实现,Socket并不是协议,差不多每一种语言都实现了对TCP和UDP封装和实现的Socket代码库,方便开发程序员使用。
Java中提供了对Socket的封装,ServerSocket服务端类,Socket为客户端类,接下来进行简单的双向通信模拟:
- 服务端
package socket;
import java.io.*;
import java.net.ServerSocket;
import java.net.Socket;
import java.util.Scanner;
public class Server {
public static void main(String[] args) {
serverInit();
}
private static void serverInit() {
BufferedReader br;
PrintWriter pw;
try {
System.out.println("服务已启动...");
ServerSocket server = new ServerSocket(8888);
Socket socket = server.accept();
InputStreamReader isr = new InputStreamReader(socket.getInputStream());
br = new BufferedReader(isr);
pw = new PrintWriter(socket.getOutputStream());
} catch (IOException e) {
throw new RuntimeException("服务启动异常!");
}
Runnable r1 = () -> {
while (true) {
String str = null;
try {
str = br.readLine();
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("接收消息:" + str);
}
};
Runnable r2 = () -> {
// 返回信息
while (true) {
Scanner scan = new Scanner(System.in);
String msg = scan.nextLine();
pw.println(msg);
pw.flush();
}
};
Thread t1 = new Thread(r1);
Thread t2 = new Thread(r2);
t1.start();
t2.start();
}
}
- 客户端
package socket;
import java.io.*;
import java.net.Socket;
import java.util.Scanner;
public class Client {
public static void main(String[] args) {
init();
}
private static void init() {
BufferedReader br;
PrintWriter pw;
try {
Socket socket = new Socket("127.0.0.1", 8888);
InputStreamReader isr = new InputStreamReader(socket.getInputStream());
br = new BufferedReader(isr);
pw = new PrintWriter(socket.getOutputStream());
} catch (IOException e) {
throw new RuntimeException("IO异常!");
}
Runnable r = () -> {
while (true) {
Scanner scan = new Scanner(System.in);
String msg = scan.nextLine();
pw.println(msg);
pw.flush();
}
};
Runnable r2 = () -> {
while (true) {
String str;
try {
str = br.readLine();
System.out.println("接收信息:" + str);
} catch (IOException e) {
e.printStackTrace();
}
}
};
Thread t1 = new Thread(r);
Thread t2 = new Thread(r2);
t1.start();
t2.start();
}
}
在Linux中Socket对应的是文件描述符(fd),一个Socket接入的时候会对应一个fd,通过下面例子查看,将上面的Server端的代码打包为可执行jar,在Linux端启动,等待客户端接入
root@starsray:/opt/develop/test# java -jar server-test.jar
Server Start...
使用命令jps查看对应的进程pid,查看该进程中所占用的fd,如下所示
root@starsray:~# jps
453543 nacos-server.jar
3095158 Jps
3095140 jar
root@starsray:~# cd /proc/3095140/fd
root@starsray:/proc/3095140/fd# ll
total 0
dr-x------ 2 root root 0 Sep 14 14:22 ./
dr-xr-xr-x 9 root root 0 Sep 14 14:21 ../
lrwx------ 1 root root 64 Sep 14 14:22 0 -> /dev/pts/0
lrwx------ 1 root root 64 Sep 14 14:22 1 -> /dev/pts/0
lrwx------ 1 root root 64 Sep 14 14:22 2 -> /dev/pts/0
lr-x------ 1 root root 64 Sep 14 14:22 3 -> /opt/develop/jdk1.8.0_301/jre/lib/rt.jar*
lr-x------ 1 root root 64 Sep 14 14:22 4 -> /opt/develop/test/server-test.jar
lrwx------ 1 root root 64 Sep 14 14:22 5 -> 'socket:[69053961]'
lrwx------ 1 root root 64 Sep 14 14:22 6 -> 'socket:[69053963]'
当有客户端接入时,在fd中会新增socket连接,使用命令nc localhost 8888连接,如下输出所示:
root@starsray:~# cd /proc/3095140/fd
root@starsray:/proc/3095140/fd# ll
total 0
dr-x------ 2 root root 0 Sep 14 14:22 ./
dr-xr-xr-x 9 root root 0 Sep 14 14:21 ../
lrwx------ 1 root root 64 Sep 14 14:22 0 -> /dev/pts/0
lrwx------ 1 root root 64 Sep 14 14:22 1 -> /dev/pts/0
lrwx------ 1 root root 64 Sep 14 14:22 2 -> /dev/pts/0
lr-x------ 1 root root 64 Sep 14 14:22 3 -> /opt/develop/jdk1.8.0_301/jre/lib/rt.jar*
lr-x------ 1 root root 64 Sep 14 14:22 4 -> /opt/develop/test/server-test.jar
lrwx------ 1 root root 64 Sep 14 14:22 5 -> 'socket:[69053961]'
lrwx------ 1 root root 64 Sep 14 14:22 6 -> 'socket:[69053963]'
lrwx------ 1 root root 64 Sep 14 14:27 7 -> 'socket:[69056140]'
也可以使用strace来跟踪执行使用了哪些系统调用
strace -t -e trace=all -ff -o out java -jar server-test.jar
查看目录中的日志文件
root@starsray:/opt/develop/test# ll
total 580
drwxr-xr-x 2 root root 4096 Sep 14 15:38 ./
drwxr-xr-x 5 root root 4096 Sep 14 11:23 ../
-rw-r--r-- 1 root root 15681 Sep 14 15:37 out
-rw-r--r-- 1 root root 15186 Sep 14 15:38 out.3103687
-rw-r--r-- 1 root root 209627 Sep 14 15:38 out.3103688
-rw-r--r-- 1 root root 1989 Sep 14 11:09 server-test.jar
在日志文件中可以看到,服务启动时会执行bind、listen等系统调用。
15:38:10 bind(6, {sa_family=AF_INET6, sin6_port=htons(8888), inet_pton(AF_INET6, "::", &sin6_addr), sin6_flowinfo=htonl(0), sin6_scope_id=0}, 28) = 0
15:38:10 listen(6, 50) = 0
15:38:10 read(3, "\312\376\272\276\0\0\0004\1\367\n\0\6\1\37\t\0\237\1 \t\0\237\1!\t\0\237\1\"\t\0"..., 14425) = 14425
15:38:10 poll([{fd=6, events=POLLIN|POLLERR}], 1, -1
通过server发送消息到client时会触发read、sendto等系统调用,然后read进入阻塞状态,等待数据准备。
15:43:48 read(0, "hello client\n", 8192) = 13
15:44:05 sendto(7, "hello client\n", 13, 0, NULL, 0) = 13
15:44:05 read(0, # 阻塞
其实到这里也可以说明了不管是Java中的Socket对象,还是Netty都是基于Linux中的系统调用进行上层封装,同样Redis、Nginx等也是基于不同的IO模型进行系统调用,下面对常见网络IO中的IO模型进行简单介绍。
IO模型
网络编程中通常所说的IO模型,一般指的是基于Socket的网络IO。在Linux环境下,对IO模型进行了如下分类:
- Blocking IO:阻塞IO
- non-BlockingIO:非阻塞IO
- IO multiplexing:IO多路复用
- Signal Driven IO:信号驱动IO
- asynchronous IO:异步IO
IO一般包含读写两个过程,网络IO同样如此,一般网络I0中我们只关心read操作,不关心send操作,因为send操作的时候,数据是从用户进程缓冲区复制到内核缓冲区,属于内存操作,比较快,而数据到了内核缓冲区,是由操作系统负责往网络上发送,无需用户进程关心。
网络IO中进行read操作时,会涉及到两个系统对象,一个是调用这个IO的process (or thread),另一个就是系统内核(kernel)。当一个read操作发生时,该操作会经历两个阶段:
- 等待数据准备 (Waiting for the data to be ready)
- 将数据从内核拷贝到进程中(Copying the data from the kernel to the process)
这五种IO模型会进行相应的系统调用,需要关注的阻塞状态的调用包含
recv、recvfrom、accept等。
阻塞IO
阻塞式IO是最简单的一种IO模型,也是Linux中在默认状态下的IO模型。这种模型下应用进程会被阻塞,包括第一阶段等待数据准备阶段和将数据从内核拷贝到应用进程空间阶段都会阻塞。如下图所示:
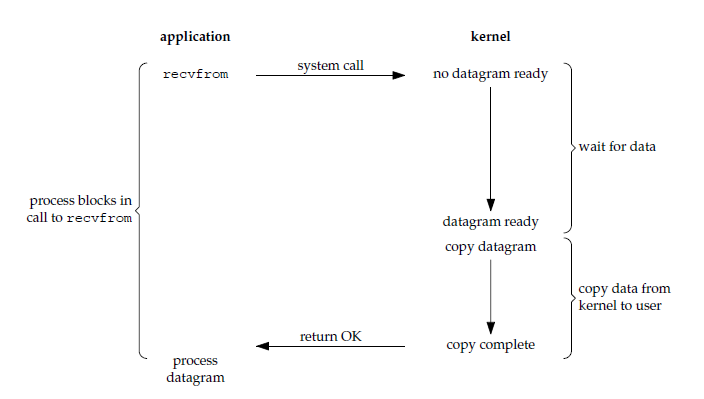
用户空间触发一个recvfrom系统调用时,会先等待数据准备,然后等待操作系统缓冲区数据复制到用户空间缓冲区,才完成一个IO返回结果,整个过程两个阶段均处于阻塞状态。
需要注意的是,这个阻塞只限于当前应用进程并不会影响其他进程的执行,CPU还可以继续处理其他进程,因此CPU的使用率较高。
非阻塞IO
非阻塞式IO是对阻塞式的一种优化,但是需要注意,这里的非阻塞指的是第一阶段,在等待数据准备的过程不会阻塞,需要用户进程空间不断的执行recvfrom系统调用进行轮询,获取准备阶段的结果,如果未完成返回一个错误码EWOULDBLOCK。如下图所示:
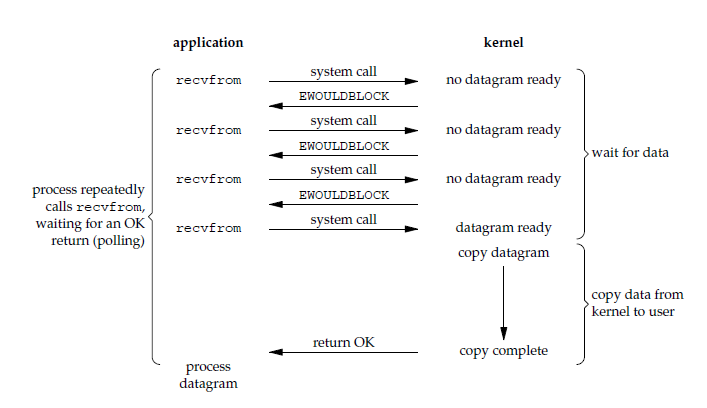
用户进程可以一直轮询(polling)recvfrom的执行结果,但是这种模型需要频繁的触发操作系统用户态和内核态的切换,另外在处理轮询的过程中,CPU会一直被占用,这种模型下的CPU效率低下,会在较长的时间片都在处理无效结果,这种模型很少使用。
多路复用IO
IO多路复用是在非阻塞模型上的又一次优化,在传统的网络服务器IO处理中,每新到达一个用户请求,都会触发一个线程进行处理,建立一个Socket连接,这种模型不适合大规模的用户并发场景,极度消耗服务器资源,因此出现了一种新的IO模型即IO的多路复用,多路是指多个Socket连接,复用是指线程复用,一个线程就可以处理上千个请求连接。如下图所示:
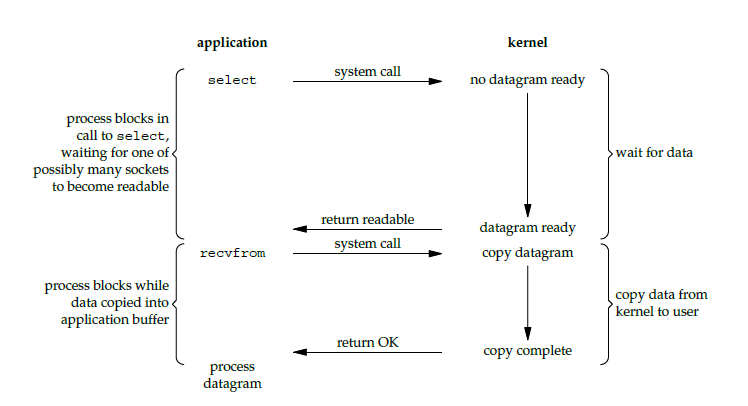
用户进程空间可以通过select系统调用一次传递多个socket连接给内核空间,这样避免了由用户空间触发的多次轮询引发的状态切换,然后由内核来返回哪一个Socket对应的fd为准备就绪状态,再由用户进程发起recvfrom系统调用,阻塞等待数据拷贝阶段完成,返回结果,这个过程select阶段会阻塞,与BIO最明显的区别也在于第一阶段。
Linux中IO多路复用有select、poll、epoll三种实现,这三种实现是按照发展顺序迭代出现的,各自使用的场景也不一致。每一次网络IO会在Linux中的用户进程创建一个Socket连接,体现在应用中对应的就是fd,关于连接fd的数量可以在/proc/pid/fd中查看。在select、poll、epoll中对应的入参也是对fd相应的集合。
select
select 允许应用程序监视一组文件描述符,等待一个或者多个描述符成为就绪状态,从而完成 I/O 操作。fd_set 使用数组实现,数组大小使用 FD_SETSIZE 定义,默认为1024,大多数平台都支持,移植性好,支持微秒级延时控制,对于时效性要求高的场景更适合,成功调用返回结果大于 0,出错返回结果为 -1,超时返回结果为 0。
入参timeout 为超时参数,调用 select 会一直阻塞直到有描述符的事件到达或者等待的时间超过 timeout。因此在第一阶段虽然不会阻塞,但是select执行的过程中会进行轮询阻塞,直到在时间内返回结果。
int select(int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
poll
poll 的功能与 select 类似,也是等待一组描述符中的一个成为就绪状态,没有fd数量的限制。poll 提供了更多的事件类型,并且对描述符的重复利用上比 select 高。select 和 poll 速度都比较慢,每次调用都需要将全部描述符从应用进程缓冲区复制到内核缓冲区,因此过多的fd处理同样有性能瓶颈,在这一点来说poll不见得比select更有优势。
int poll(struct pollfd *fds, unsigned int nfds, int timeout);
epoll
epoll是Linux内核在2.6之后出现的一个新的系统调用。目的在于解决随着处理的文件描述符的增长,降低时间复杂度,在高并发场景下有着相当好的优势,相比于前两种系统调用:
- select 和 poll 监听文件描述符list,进行一个线性的查找 O(n)
- epoll: 使用了内核文件级别的回调机制O(1)
关于select、poll、epoll随着fd增长的CPU调用耗时如下所示:
| fds | select | poll | epoll |
|---|---|---|---|
| 10 | 0.73 | 0.61 | 0.41 |
| 100 | 3 | 2.9 | 0.42 |
| 1000 | 35 | 35 | 0.53 |
| 10000 | 930 | 990 | 0.66 |
通过参数/proc/sys/fs/epoll/max_user_watches,表示用户能注册到epoll实例中的最大文件描述符的数量限制。
epoll包含了三个系统调用,分别是epoll_create、epoll_ctl、epoll_wait。epoll 只需要将描述符从进程缓冲区向内核缓冲区拷贝一次,并且进程不需要通过轮询来获得事件完成的描述符。
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
- epoll_create:用于创建一个epoll实例,这里的size大于0即可,没有实际意义
- epoll_ctl:用于向内核注册新的描述符或者是改变某个文件描述符的状态。已注册的描述符在内核中会被维护在一棵红黑树上,通过回调函数内核会将 I/O 准备好的描述符加入到一个链表中管理。
- epoll_wait:等待epoll事件从epoll实例中发生, 并返回事件以及对应文件描述符,进程调用 epoll_wait() 便可以得到事件完成的描述符。
epoll适用于Linux平台上,有大量的描述符需要同时轮询,且连接最好是长连接,当需要同时监控小于 1000个描述符时,这个应用场景下并不能体现 epoll 的优势。
需要监控的描述符状态变化多,而且都是非常短暂的,也没有必要使用epoll,因为epoll中的所有描述符都存储在内核中,造成每次需要对描述符的状态改变都需要通过epoll_ctl进行系统调用,频繁系统调用降低效率。且epoll的描述符存储在内核,不容易调试。
信号驱动IO
用户进程使用 sigaction 系统调用,内核立即返回,应用进程可以继续执行,也就是说等待数据阶段应用进程是非阻塞的。内核在数据到达时向应用进程发送 SIGIO 信号,应用进程收到之后在信号处理程序中调用 recvfrom 将数据从内核复制到应用进程中,如下图所示:
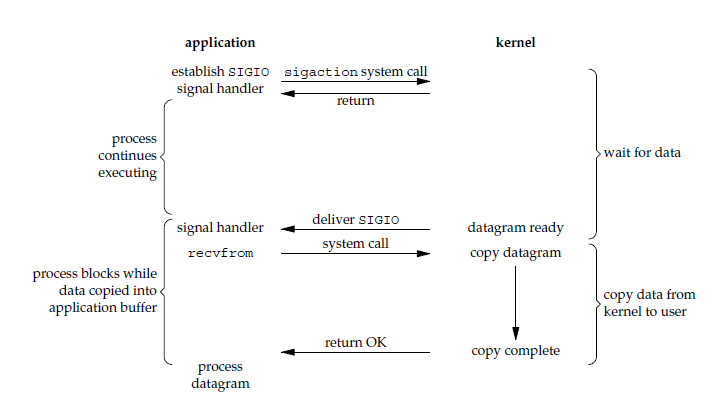
在第二阶段调用recvfrom会阻塞,从这个角度来说信号驱动IO也是同步IO的一种。
异步IO
用户进程发起aio_read系统调用后不会阻塞,会立即响应,不影响用户进程的操作,等待操作系统执行完数据拷贝后会发送信号通知用户进程,数据拷贝阶段发生在内核空间,不存在阻塞情况。如下图所示:
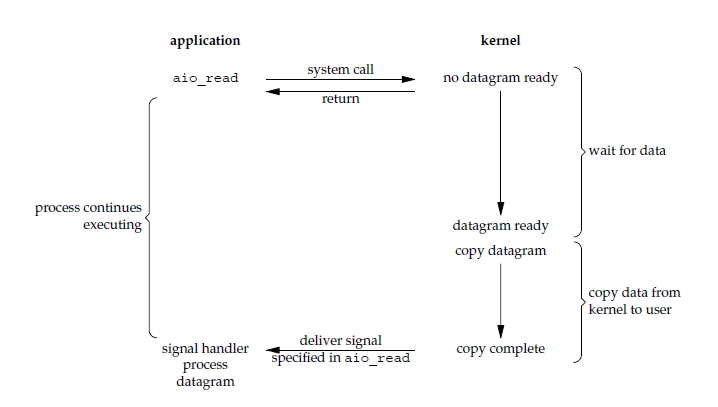
异步 I/O 与信号驱动 I/O 的区别在于,异步 I/O 的信号是通知应用进程 I/O 完成,而信号驱动 I/O 的信号是通知应用进程可以开始 I/O。异步IO两个阶段都不存在阻塞,从用户进程发起请求到响应是异步进行的,需要注意,Linux上内核没有真正的AIO实现。Windows上的IOCP可以认为是真正意义的异步IO模型。
同步IO/异步IO
IO模型中除了阻塞、非阻塞,还有同步异步的概念。这两组概念并不是对等概念,例如同步IO可以分为同步阻塞、同步非阻塞,包括多路复用本质也是一种同步IO,阻塞必然同步,异步一定不阻塞。
此外,阻塞、非阻塞, 同步、异步的概念要注意讨论的上下文:
- 在进程通信层面, 阻塞/非阻塞, 同步/异步基本是同义词, 但是需要注意区分讨论的对象是发送方还是接收方。
- 发送方阻塞/非阻塞(同步/异步)和接收方的阻塞/非阻塞(同步/异步) 是互不影响的。
- 在 IO 系统调用层面( IO system call )层面, 非阻塞 IO 系统调用 和 异步 IO 系统调用存在着一定的差别, 它们都不会阻塞进程, 但是返回结果的方式和内容有所差别, 但是都属于非阻塞系统调用( non-blocing system call )
非阻塞系统调用(non-blocking I/O system call 与 asynchronous I/O system call) 的存在可以用来实现线程级别的 I/O 并发, 与通过多进程实现的 I/O 并发相比可以减少内存消耗以及进程切换的开销。
IO模型比较分析
常见的五种IO模型,有自己的特点,各自有自己的适用场景,其对比如下图所示:
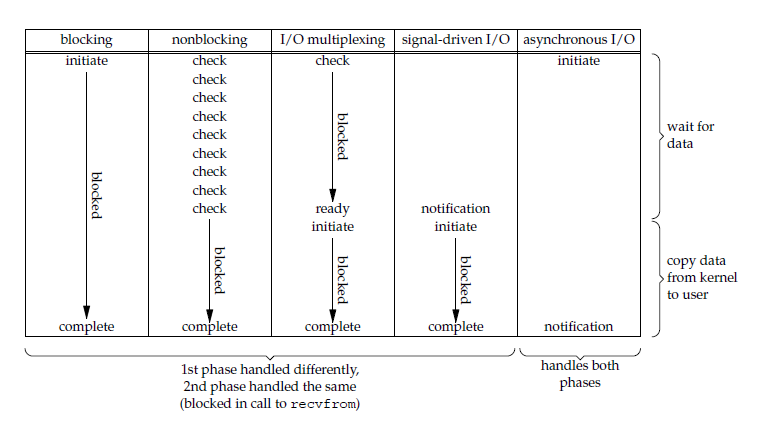
IO模型中的两个阶段,具体实现细节体现了不同IO模型的差异,而同步、异步、阻塞、非阻塞的概念也重点体现在两个阶段的差别。
同步IO包括阻塞式IO、非阻塞 IO、IO多路复用和信号驱动IO ,它们的主要区别在第一个阶段,存在阻塞和非阻塞的状态,主要对比如下:
- 阻塞:阻塞IO第一阶段会阻塞
- 非阻塞:非阻塞IO 、信号驱动IO和异步IO在第一阶段不会阻塞
同步IO和异步IO明显的区别在于第二阶段
- 同步IO:在第二阶段,将数据从内核缓冲区复制到应用进程缓冲区的阶段,应用进程会阻塞
- 异步IO:第二阶段应用进程不会阻塞
参考文档:
- https://www.jianshu.com/p/34d39692b78d
- https://zhuanlan.zhihu.com/p/260450151
- https://blog.csdn.net/qq_40276626/article/details/120171326
- https://www.runoob.com/w3cnote/summary-of-network.html
- https://www.xuxueli.com/blog
- https://www.cnblogs.com/cangqinglang/p/11503057.html
- https://www.cnblogs.com/ggjucheng/archive/2012/01/08/2316692.html
- https://zhuanlan.zhihu.com/p/115912936
- https://www.zhihu.com/question/19732473/answer/241673170
本文来自博客园,作者:星光Starsray,转载请注明原文链接:https://www.cnblogs.com/starsray/p/18027657





【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具