ElasticSearch使用(从入门到放弃)
概述
什么是ElasticSearch? 也可简称为ES,顾名思义,可伸缩搜索,主要用来做检索的,再看看官网解释。
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎。作为 Elastic Stack 的核心,Elasticsearch 会集中存储您的数据,让您飞快完成搜索,微调相关性,进行强大的分析,并轻松缩放规模。
提取关键词,分布式、REST API、搜索引擎、数据分析。ElasticSearch可以用来进行海量数据的存储、检索、分析。关键是还能实时的进行数据操作。可以在笔记本电脑运行,也可以承载PB级别的数据,可以组建支持成百上千台服务器的高可用集群。
ElasticSearch的底层通过Lucene来实现,Lucene是由Apache开源的一套使用Java语言开发的搜索引擎。Lucene是一个开放源代码的全文检索引擎工具包,它不是一个完整的全文检索引擎,使用Lucene必须使用Java集成到系统中,使用繁琐,配置复杂。而ES则规避了这个问题,屏蔽的复杂对接,暴露易用的REST接口,可以与任何语言类型的服务配合使用。
通过对ElasticSearch的基本认识,接下来会围绕其安装、基本概念和原理、使用、最佳实践几个部分进行阐述。
安装
关于ES的安装不做重点讲解,这里提供一个k8s基于sts创建以及ingress访问的模板文件。
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app: elasticsearch
component: master
release: elasticsearch
name: elasticsearch-master
namespace: es
spec:
podManagementPolicy: OrderedReady
replicas: 3
revisionHistoryLimit: 10
selector:
matchLabels:
app: elasticsearch
serviceName: elasticsearch-master
template:
metadata:
labels:
app: elasticsearch
component: master
release: elasticsearch
spec:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchLabels:
app: elasticsearch
component: master
release: elasticsearch
topologyKey: kubernetes.io/hostname
weight: 1
containers:
- env:
- name: NODE_DATA
value: 'true'
- name: NODE_MASTER
value: 'true'
- name: NODE_INGREST
value: 'true'
- name: DISCOVERY_SERVICE
value: elasticsearch-discovery
- name: PROCESSORS
valueFrom:
resourceFieldRef:
divisor: '0'
resource: limits.cpu
- name: ELASTICSEARCH_USERNAME
value: elastic
- name: ELASTIC_PASSWORD
value: your_password
- name: ES_JAVA_OPTS
value: '-Djava.net.preferIPv4Stack=true -Xms512m -Xmx512m '
- name: MINIMUM_MASTER_NODES
value: '2'
image: 'your_image'
imagePullPolicy: IfNotPresent
name: elasticsearch
ports:
- containerPort: 9300
name: transport
protocol: TCP
- containerPort: 9200
name: http
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /_cluster/health?local=true
port: 9200
scheme: HTTP
initialDelaySeconds: 5
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
resources:
limits:
cpu: '1'
requests:
cpu: 25m
memory: 512Mi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /usr/share/elasticsearch/data
name: data
- mountPath: /usr/share/elasticsearch/config/elasticsearch.yml
name: config
subPath: elasticsearch.yml
dnsPolicy: ClusterFirst
imagePullSecrets:
- name: registry-secret
initContainers:
- command:
- sysctl
- '-w'
- vm.max_map_count=262144
image: 'your_image'
imagePullPolicy: IfNotPresent
name: sysctl
securityContext:
privileged: true
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
- command:
- /bin/bash
- '-c'
- >-
chown -R elasticsearch:elasticsearch /usr/share/elasticsearch/data
&& chown -R elasticsearch:elasticsearch
/usr/share/elasticsearch/logs
image: 'your_image'
imagePullPolicy: IfNotPresent
name: chown
securityContext:
runAsUser: 0
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /usr/share/elasticsearch/data
name: data
restartPolicy: Always
schedulerName: default-scheduler
securityContext:
fsGroup: 1000
serviceAccount: elasticsearch-master
serviceAccountName: elasticsearch-master
terminationGracePeriodSeconds: 30
volumes:
- configMap:
defaultMode: 420
name: elasticsearch
name: config
updateStrategy:
type: RollingUpdate
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi
volumeMode: Filesystem
---
apiVersion: v1
kind: Service
metadata:
labels:
app: elasticsearch
component: master
release: elasticsearch
name: elasticsearch
namespace: es
spec:
ports:
- name: http
port: 9200
protocol: TCP
targetPort: http
selector:
app: elasticsearch
component: master
release: elasticsearch
type: ClusterIP
---
apiVersion: v1
kind: Service
metadata:
labels:
app: elasticsearch
component: master
release: elasticsearch
name: elasticsearch-discovery
namespace: es
spec:
clusterIP: None
ports:
- port: 9300
protocol: TCP
targetPort: transport
selector:
app: elasticsearch
component: master
release: elasticsearch
type: ClusterIP
---
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: es
namespace: es
spec:
rules:
- host: your_domain
http:
paths:
- backend:
serviceName: elasticsearch
servicePort: 9200
path: /
基本概念
索引
Index : 索引是Elasticsearch中存储、搜索和分析数据的逻辑容器。它类似于关系型数据库中的数据库。一个索引通常包含具有相似结构的一组文档。
类型
Type : 类型是索引中的逻辑分组,用于对具有相似特征的文档进行分类。type,是一个index中用来区分类似的数据的,在底层的Lucene中建立索引的时候,全部是opaque bytes类型,不区分类型的。
Lucene是没有type的概念的,在document中,实际上将type作为一个document的field来存储,即type,es通过type来进行type的过滤和筛选。
在较新的Elasticsearch版本中,类型已被弃用,推荐将所有文档存储在单个索引中。因此,在最新的版本中,索引只包含文档,不再包含类型。
文档
Document : 文档是Elasticsearch中的基本数据单元。它以JSON格式表示,并存储在索引中。文档可以是任何结构化的数据,如用户信息、产品数据等。每个文档都有一个唯一的ID,用于在索引中进行引用和检索。
映射
Mapping : 映射定义了文档中每个字段的数据类型、索引方式和其他属性。它描述了文档结构中字段的基本元数据。例如,一个字段可以被映射为字符串类型、日期类型、数字类型等。字段映射还可以指定字段是否需要被索引、是否存储原始值以及是否启用特定的分析器等。
映射可以在索引创建时通过参数直接创建,也可以对现有索引进行映射信息修改,这就可能需要重建索引。
关于修改Mapping和ReIndex的内容,可以自行深入了解。
字段
Field : 可以类比关系型数据库中Column,关于字段的定义信息描述,可以在Mapping中进行指定。
集群
Cluster : 集群就意味着分布式,ElasticSearch可以运行在多台机器节点组成的集群中。节点的角色可以分为Master、Data、Coordinate三种角色,每个节点可以只分配一种角色也可以分配多种角色,集群和分片的概念也正是ElasticSearch相对于Lucene最主要区别的地方,Lucene本身只是提供了搜索引擎的功能,但是并不能满足分布式和高可用等特性,而Es则是在其上层进行分布式架构的设计,满足海量数据处理的场景。
分片
Shard : 分片概念也是Es中重要的一个概念,参考AKF原则,当水平扩展不足以满足海量数据的处理,就需要进行其他维度的处理,当ES中单个节点不足以处理单个Index的数据量时,Es支持将单个Index的数据存储在多个分片上,同样分片也在一定程度上保障了集群的高可用性。Es中的分片分为主分片和副本分片。一个索引被分成多个分片,每个分片可以有一个主分片和多个副本分片,每个分片副本都是一个具有完整功能的Lucene实例。分片可以分配在不同的服务器上,同一个分片的不同副本不能分配在相同的服务器上。
关于集群和分片的更多内容,在后续进一步描述。
DSL
Domain Specific Language,领域特定语言):
在Elasticsearch中,DSL用于构建查询和聚合操作。它是一种以JSON格式编写的查询语言,用于与Elasticsearch进行交互。DSL提供了丰富的查询语法和聚合功能,使用户能够根据各种条件和聚合规则搜索和分析数据。
使用
在了解完ES的使用场景和基本概念后,接下来开发进行一些准备工作,进入到ES的基本使用环节。
客户端工具
ES的服务端安装完成后,以及对基本概念有一定的了解,进一步使用肯定要借助一些客户端,由于ES的使用都是基于REST风格的API,因此可以使用支持HTTP请求的REST API调用工具都可以进行服务端操作,例如PostMan,这里推荐几个常用的工具如Kibana,或者Edge浏览器中可以使用的扩展插件Elasticvue、ES-client等。
基础语法
类比于关系型数据库查询的SQL语言,在ES中使用DSL语言与服务器进行交互。ES中关于数据的操作交互可以分为两大类,索引(index)操作和文档(document)操作。接下来关于REST API的调用使用Elasticvue工具进行演示。使用REST请求,因此查用的请求类型也分别对应POST、PUT、GET、DELETE。
操作索引
创建索引(映射)
索引和映射可以同时创建,也可以先创建索引,再进行映射的创建。
{
"mappings": {
"message": {
"properties": {
"messageId": {
"type": "keyword"
},
"msgContent": {
"type": "text"
},
"msgTitle": {
"type": "text"
},
"receiveDate": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss || yyyy-MM-dd || yyyy-MM-dd HH:mm"
},
"subject": {
"type": "text"
},
"userId": {
"type": "keyword"
},
"userUrl": {
"type": "keyword"
}
}
}
}
}
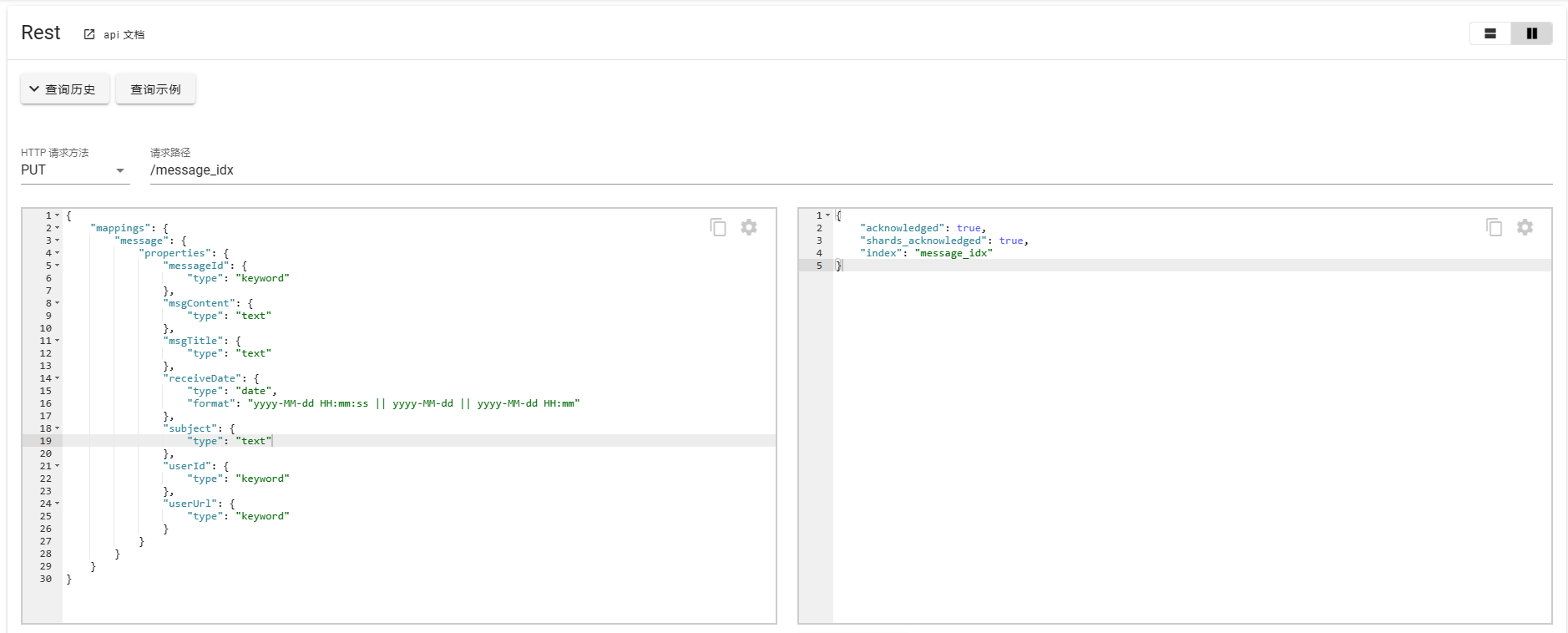
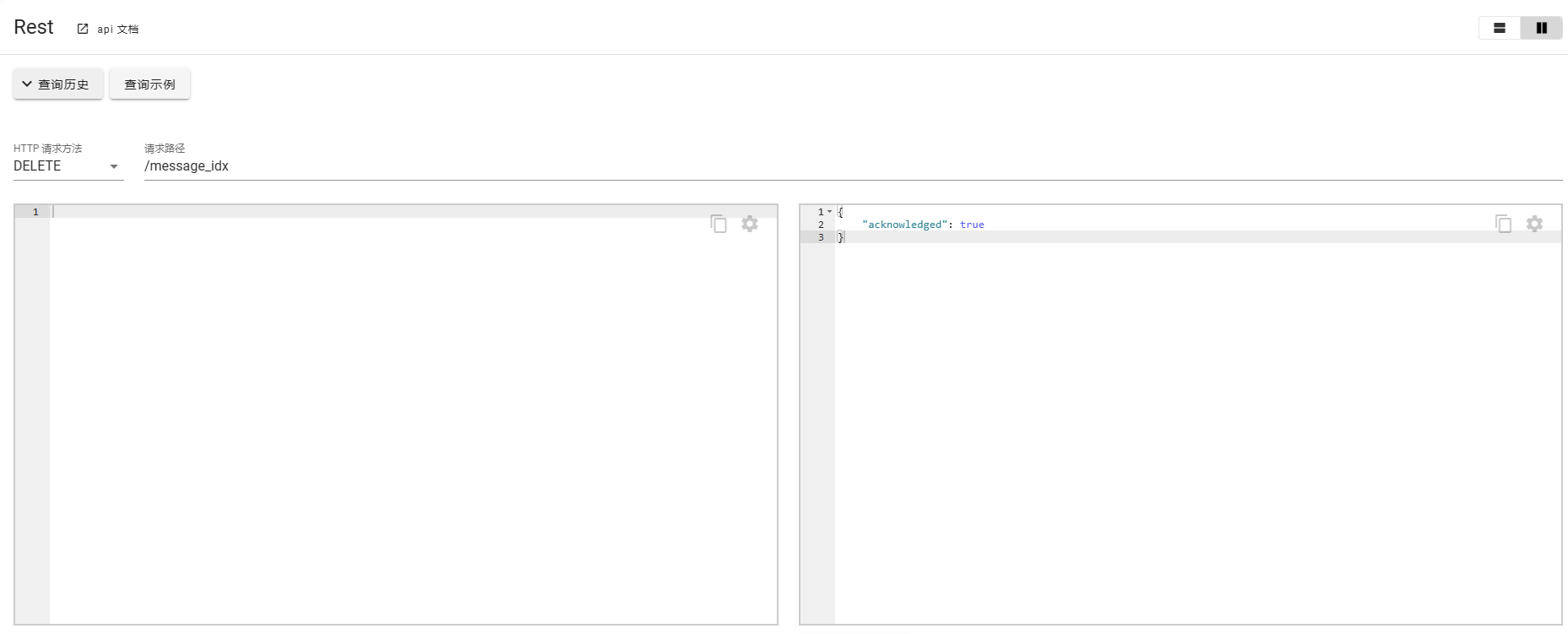
删除索引
DELETE message_idx
重建索引
一般创建索引时也就意味着数据结构已经确定,如果需要修改mapping信息时,那就需要对索引进行重建。
POST _reindex
{
"source": {
"index": "test_index"
},
"dest": {
"index": "test_index_new"
}
}
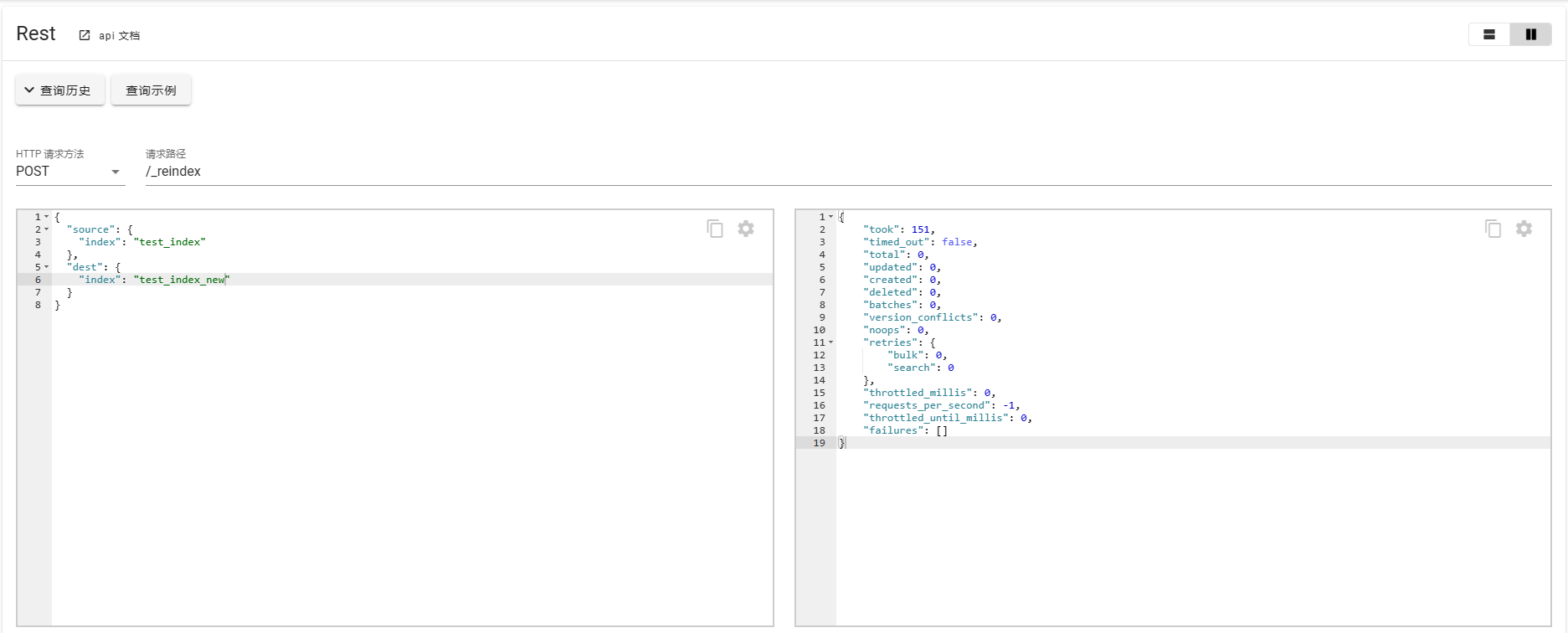
如果重建时间可能太长,可以添加参数?wait_for_completion=false直接返回taskId。
别名
索引别名是用于引用一个或多个现有索引的辅助名称。简单来说就是,一个索引可以通过别名进行调用,也可以使用本身的名称进行调用。一个索引可以绑定多个别名,一个别名也可以绑定多个索引。使用别名的好处主要有以下几点:
-
索引切换:通过使用别名,可以将一个别名绑定到一个或多个索引上。这样,在索引切换或滚动升级时,可以更新别名的绑定,而不需要修改应用程序中对索引的引用。这使得索引维护和数据迁移更加灵活和无缝。
-
查询分发:别名可以作为查询的目标,将查询请求分发到多个索引上。这对于在多个索引上执行相同的查询非常有用,尤其是当索引按时间进行分割或分片时。通过使用别名,可以将查询发送到所有相关的索引,而不需要显式指定每个索引的名称。
-
索引别名过滤:别名还可以与过滤器结合使用,以将查询限制为特定的索引或索引模式。通过为别名定义过滤条件,可以创建只包含满足特定条件的文档的虚拟索引视图。这对于数据分区、安全性和权限控制非常有用。
-
索引重命名:通过修改别名的绑定,可以实现索引的重命名操作。这在需要更改索引名称或将索引从一个集群迁移到另一个集群时非常有用。
通过使用别名,可以提供更灵活、更抽象的索引命名和查询操作,使得索引的管理和使用更加方便和可靠。
别名的操作使用POST _aliases,使用如下所示:
绑定/解绑别名
- 绑定
POST _aliases
{
"actions" : [
{ "add" : { "index" : "test_index", "alias" : "test_index_aliases" } }
]
}
- 解绑
POST /_aliases
{
"actions" : [
{ "remove" : { "index" : "test_index", "alias" : "test_index_aliases" } }
]
}
更换别名
POST /_aliases
{
"actions" : [
{ "remove" : { "index" : "test_index", "alias" : "test_index_aliases" } },
{ "add" : { "index" : "test_index", "alias" : "test" } }
]
}
绑定多个别名
POST /_aliases
{
"actions" : [
{ "add" : { "index" : "test_index_1", "alias" : "test" } },
{ "add" : { "index" : "test_index_2", "alias" : "test" } }
]
}
操作文档
文档操作可以说是ES中使用最多的操作类型了,通常也是使用相应的REST请求。这里主要介绍以下几种常用操作。
基本操作
文档的基本操作,相对于传统数据库无非也是CRUD,使用最多的就是PUT和POST操作了,关于二者的区别如下:
在 Elasticsearch 中,"PUT" 和 "POST" 是两种不同的 HTTP 方法,用于向 Elasticsearch 发送请求。
-
PUT 方法:PUT 方法用于创建或更新文档。如果指定了文档的 ID,它将尝试将提供的文档内容放置在该 ID 对应的位置。如果该 ID 不存在,它将创建一个新的文档。如果没有指定 ID,Elasticsearch 将自动生成一个唯一的 ID,并创建一个新文档。PUT 方法是幂等的,这意味着多次执行相同的 PUT 请求会产生相同的结果。
-
POST 方法:POST 方法用于在 Elasticsearch 中执行各种操作,包括创建文档、更新文档、搜索等。与 PUT 方法不同,POST 方法不要求指定文档的 ID。如果指定了 ID,它将尝试将提供的文档内容放置在该 ID 对应的位置。如果没有指定 ID,Elasticsearch 将自动生成一个唯一的 ID,并创建一个新文档。POST 方法不是幂等的,这意味着多次执行相同的 POST 请求可能会产生不同的结果。
总结:
- PUT 方法用于创建或更新文档,需要指定文档的 ID,是幂等的。
- POST 方法用于执行各种操作,包括创建或更新文档,可以不指定文档的 ID,不是幂等的。
创建文档
- 使用PUT
请求路径携带id,如果id不存在会自动创建数据,如果id存在会进行替换。
PUT /message_idx/message/1
{
"messageId": "4585499",
"msgContent": "您有一条审批消息请注意查收",
"msgTitle": "审批提醒",
"receiveDate": "2023-10-31 10:00:01",
"subject": "消息提醒",
"userId": "12356",
"userUrl": ""
}
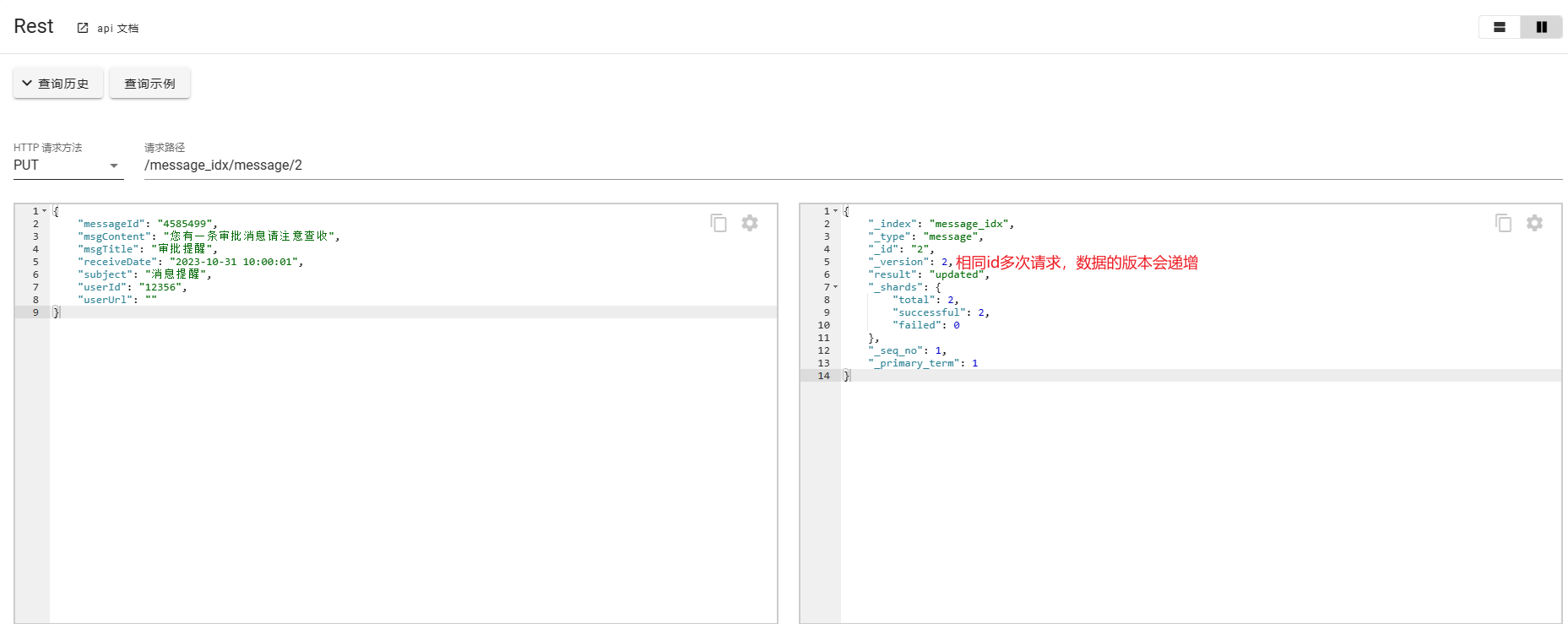
请求路径无id,可以看到服务端返回提示这种场景下应该使用POST请求。
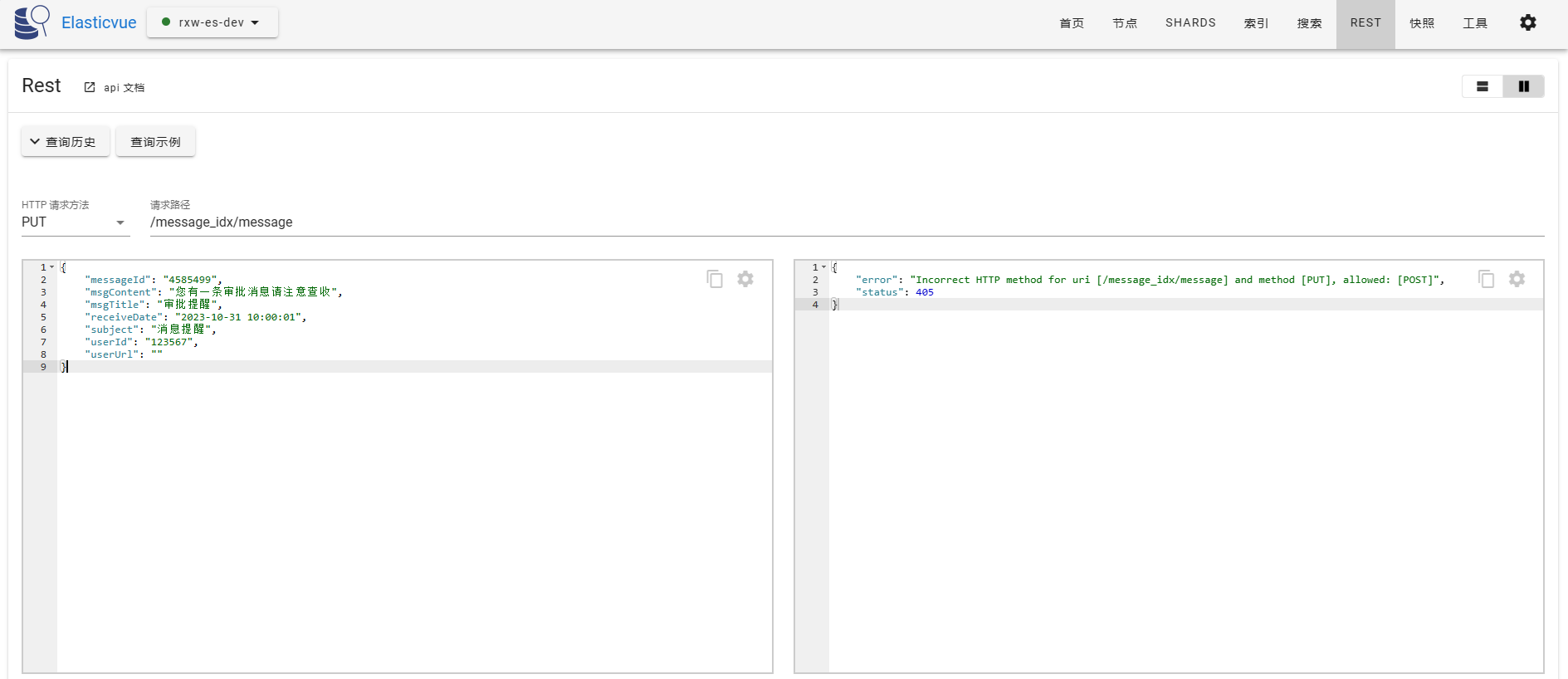
- 使用POST
POST /message_idx/message
{
"messageId": "4585499",
"msgContent": "您有一条审批消息请注意查收",
"msgTitle": "审批提醒",
"receiveDate": "2023-10-31 10:00:01",
"subject": "消息提醒",
"userId": "123567",
"userUrl": ""
}
使用POST可以不携带id,会自定生成id并创建数据。
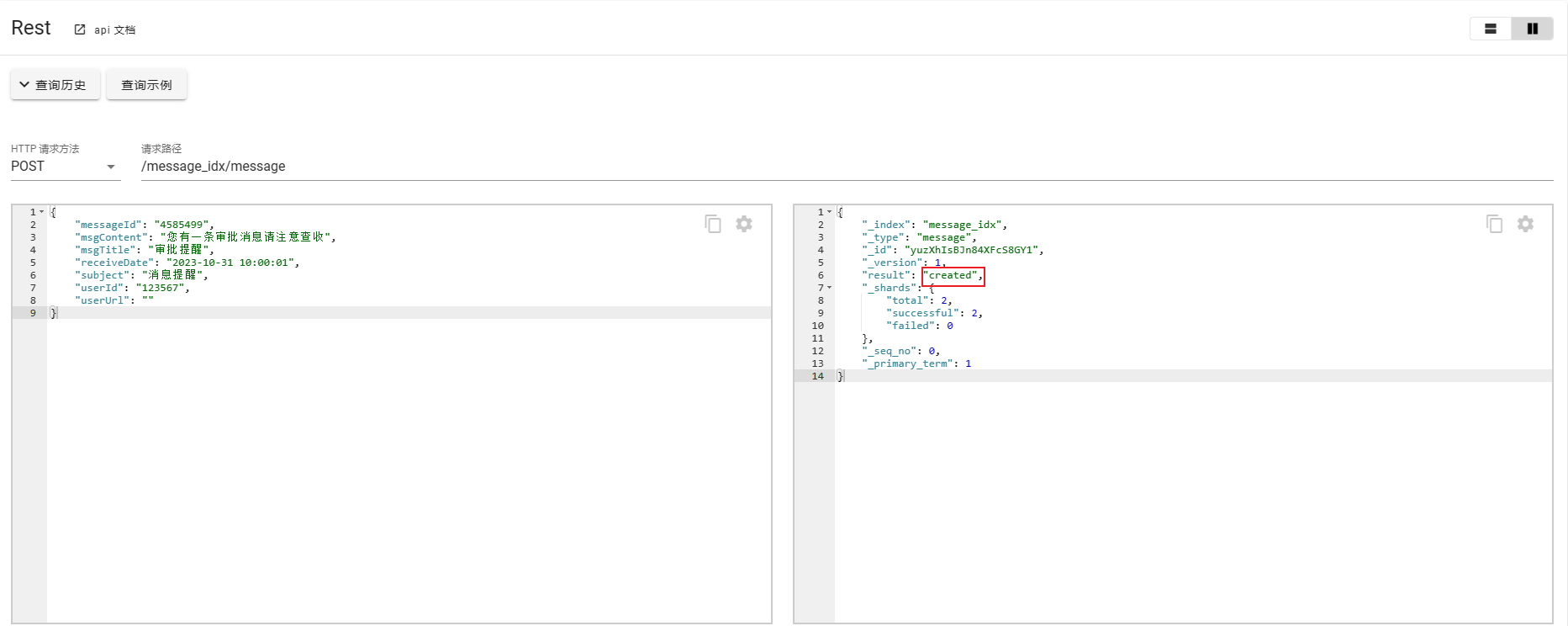
通过以上的案例可以说明PUT侧重数据的更新,POST更侧重于数据的创建,如果请求携带了id的时候POST和PUT的处理方式基本一致,区别在于请求没有携带id的场景。
另外需要注意的是:
对于请求路径格式为 POST/PUT /index_name/_doc/document_id,有以下说明
- index_name: 索引名称
- _doc: type类型
- document_id: 文档id
关于_doc(type)引用官方文档有以下说明:
Elasticsearch 是一个开源的分布式搜索和分析引擎,它是基于 Apache Lucene 构建的。在 Elasticsearch 的早期版本中,它使用了一种叫做 "types" 的概念来组织文档。然而,自从 Elasticsearch 6.0 版本发布以来,types 的概念已经被弃用,并且在 Elasticsearch 7.0 版本中完全移除了。
下面是 Elasticsearch 中 type 发展历史的简要概述:
- Elasticsearch 1.x:在 Elasticsearch 1.x 版本中,文档被组织在索引(index)之中,并且可以在索引级别下定义多个 types。每个 type 有自己的映射(mapping),它定义了文档的字段和数据类型。这种类型的组织结构使得索引可以存储多种相关但具有不同结构的文档。
- Elasticsearch 2.x:随着 Elasticsearch 2.x 版本的发布,Elastic 团队开始逐渐弃用 type 的概念。虽然仍然可以在索引中定义多个 types,但 Elastic 官方建议将所有文档放在单个 type 中。这是为了减少混淆,因为很多用户都误解了 types 的含义和使用方式。
- Elasticsearch 6.x:在 Elasticsearch 6.0 版本中,types 被宣布为即将被移除的功能。Elastic 团队鼓励用户在升级到 Elasticsearch 6.x 时移除所有 types,并将所有文档放在单个 type 中。
- Elasticsearch 7.x:在 Elasticsearch 7.0 版本中,types 被完全移除。现在,文档只能被组织在一个索引中,而不是在多个 types 中。这意味着每个索引只有一个默认的 type
_doc,用于存储所有文档。
总结起来,随着 Elasticsearch 的发展,type 的概念逐渐被弃用并移除。Elasticsearch 7.x 版本及更高版本中,文档被组织在索引中,而不再使用 types。这种变化简化了数据模型,并提高了 Elasticsearch 的性能和可维护性。在使用ES时也要注意版本不同导致API调用的差异,尤其是系统框架升级时更应注意升级带来的影响。
删除文档
DELETE /message_idx/message/1
注意查看返回结果。
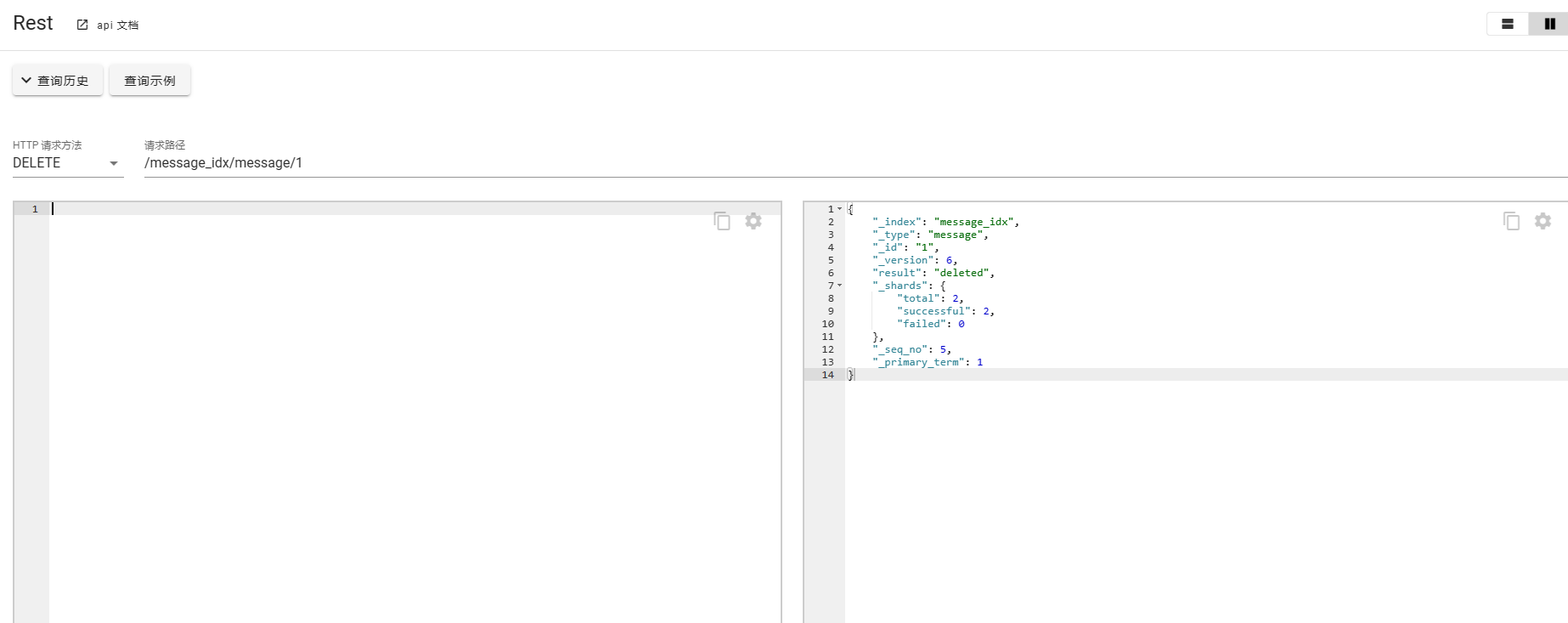
更新文档
POST /message_idx/message/1
{
"doc": {
"msgContent": "您有一条审批消息请注意查收!"
}
}
这里也可以使用PUT请求。
获取文档
这里说获取文档指的是根据id进行查询的方式,关于复杂查询,后续会进行详细介绍。
根据id获取单个文档
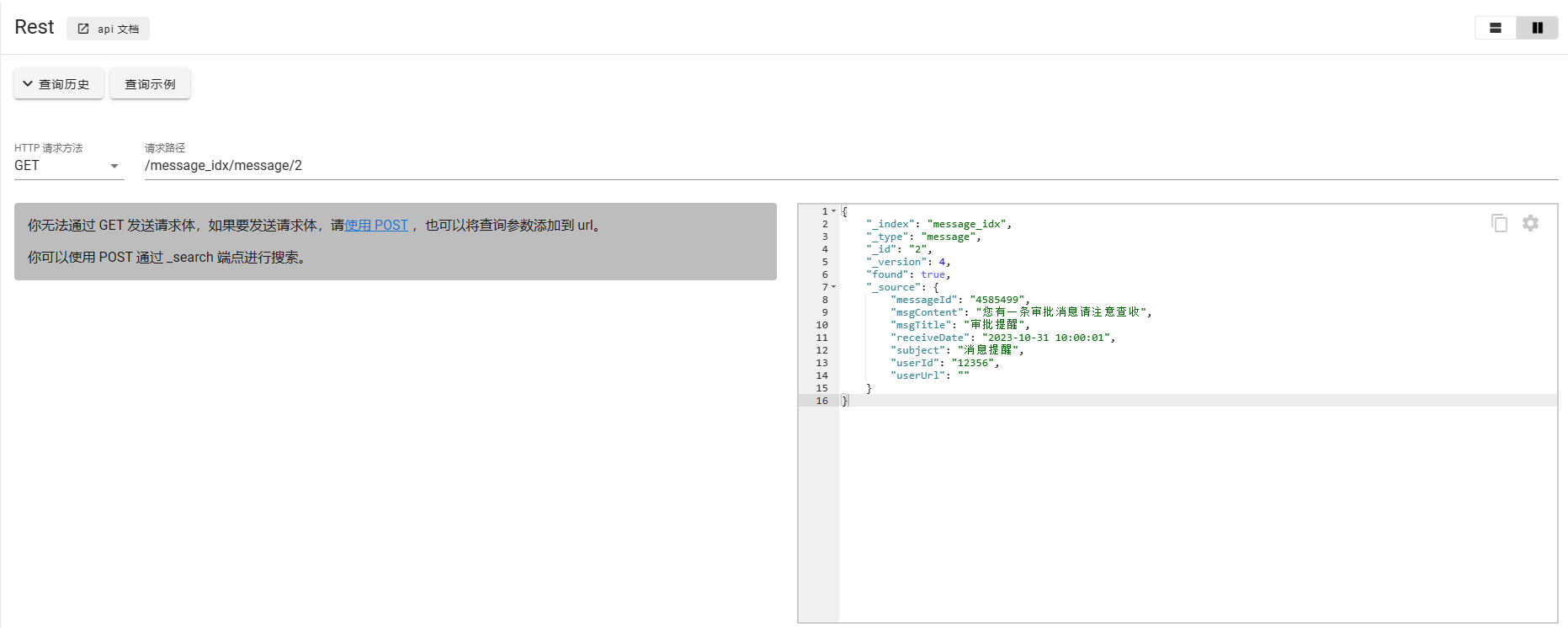
使用POST请求批量获取
POST /message_idx/message/_mget
{
"ids": ["2","3"]
}
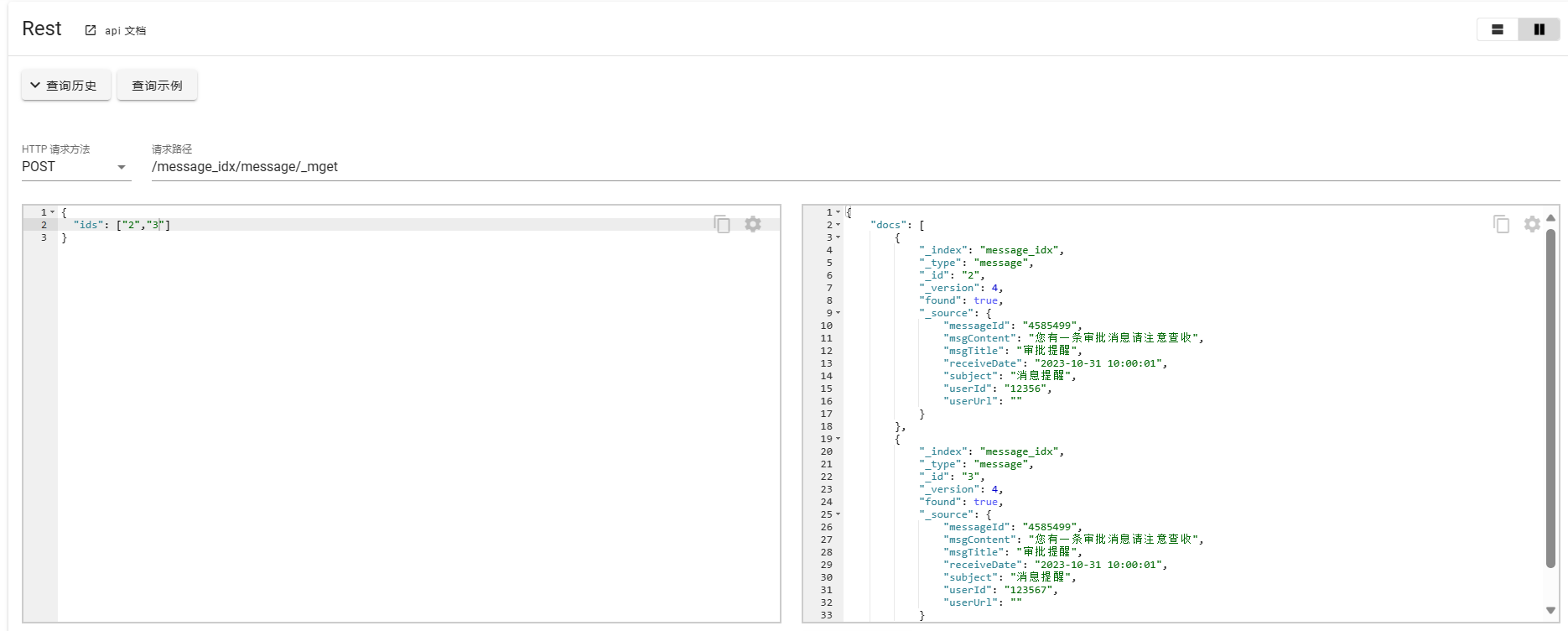
关于文档的创建、更新、删除操作主要做以上演示,在实际使用中需要注意PUT、POST在创建和更新时的细节差别,以及ES版本不同,导致请求REST API在请求路径结构商的不同。
查询操作
查询操作是ES使用中最重要的一部分内容。
Match查询
Match查询用来做基本的模糊查询,会对查询内容做分词,然后根据倒排索引去匹配文档。
- match_all
match_all没有查询条件会查询所有数据,
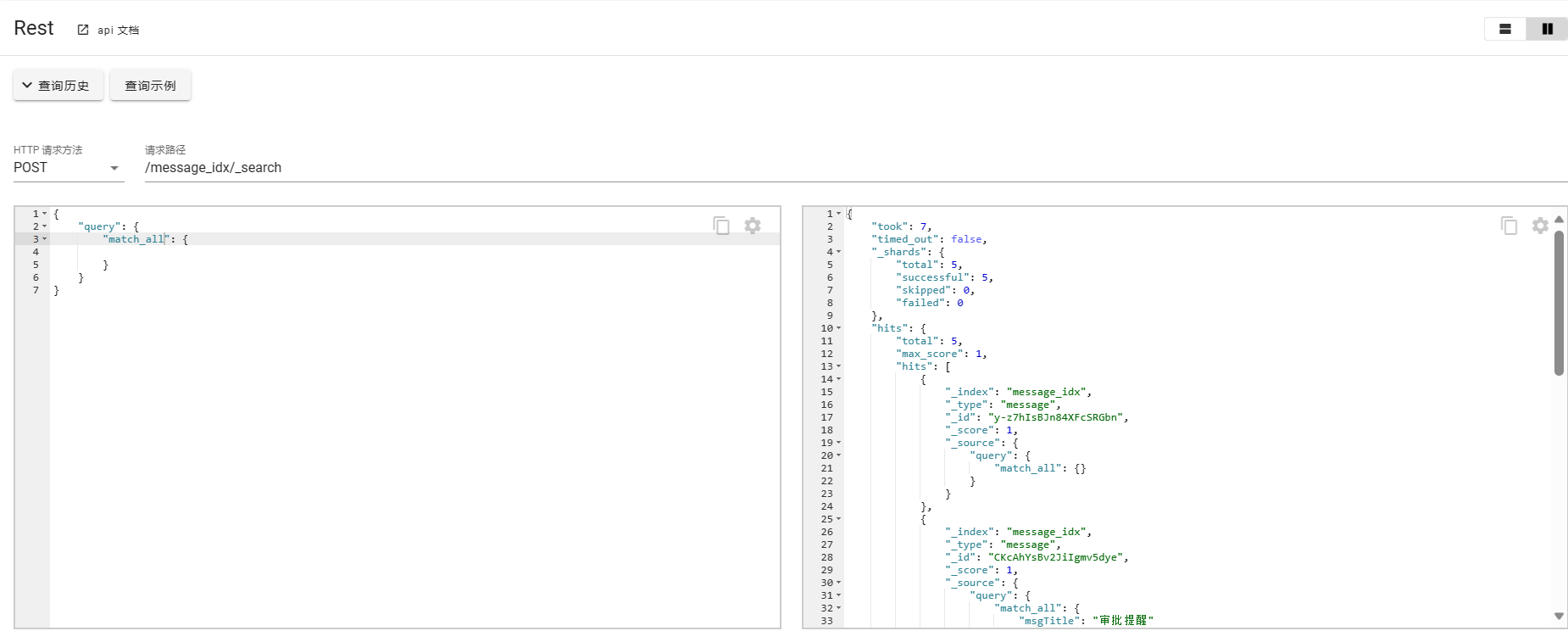
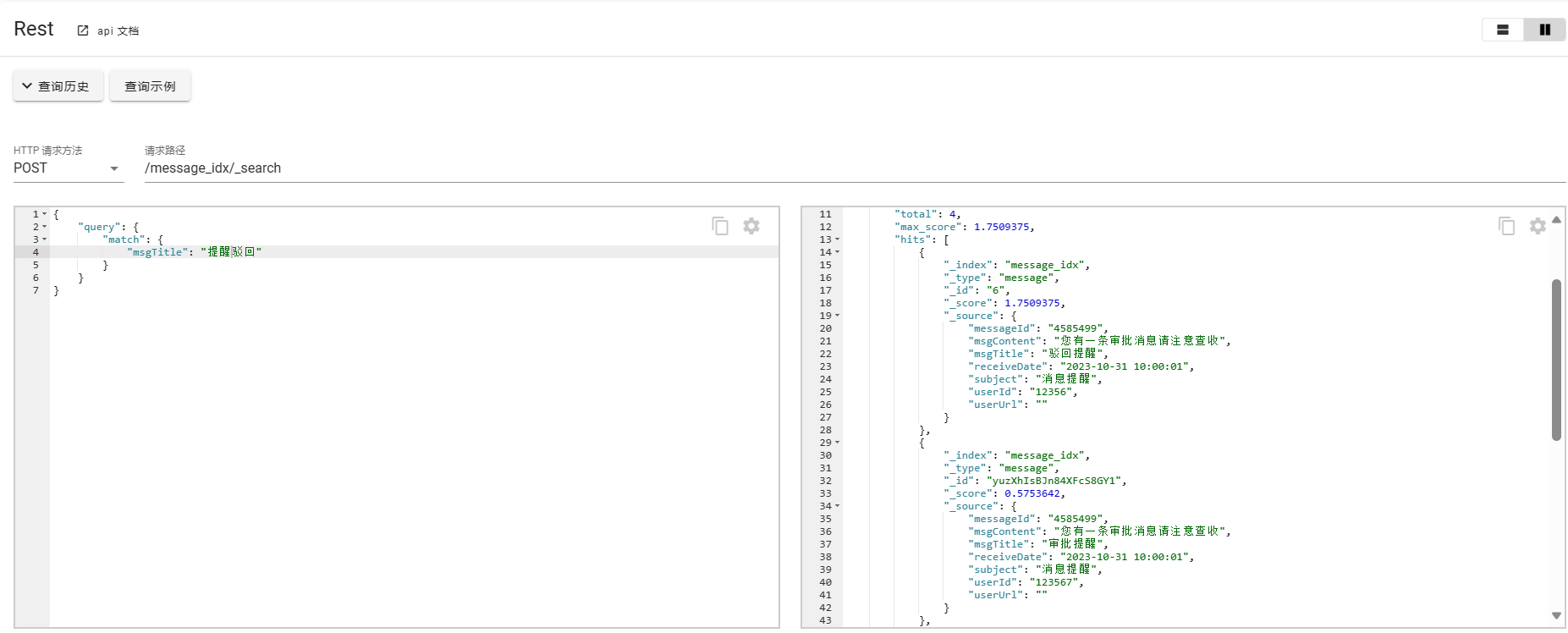
- match
基本的匹配查询,对于分词结果只要匹配的内容即可命中。
POST /message_idx/_search
{
"query": {
"match": {
"msgTitle": "提醒驳回"
}
}
}
对于输入内容提醒驳回进行分词,提醒、驳回,只要匹配这两个词都可以被命中返回数据。
3. match_phrase
match_phrase的匹配条件较为严苛一点,需要严格匹配,会对输入的短语进行分词,并且要包含所有的分词结果并且顺序一致。
如下案例所示:
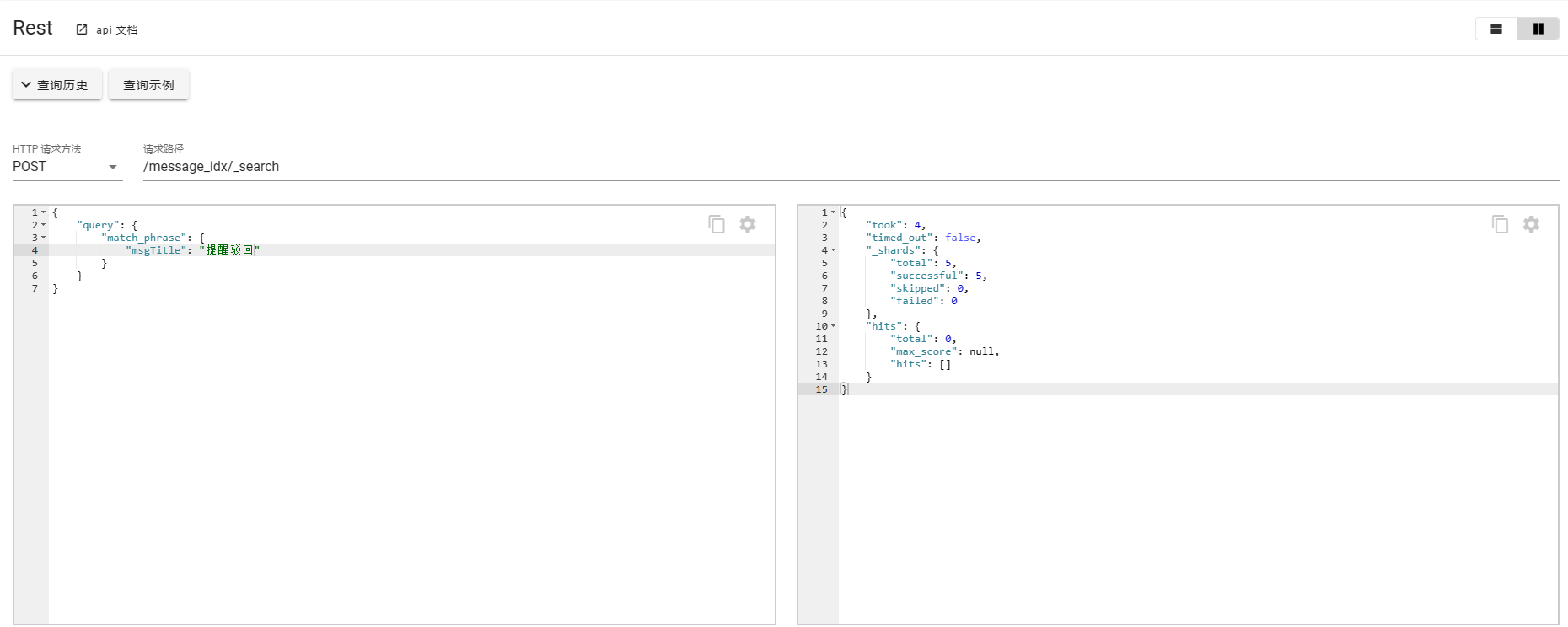
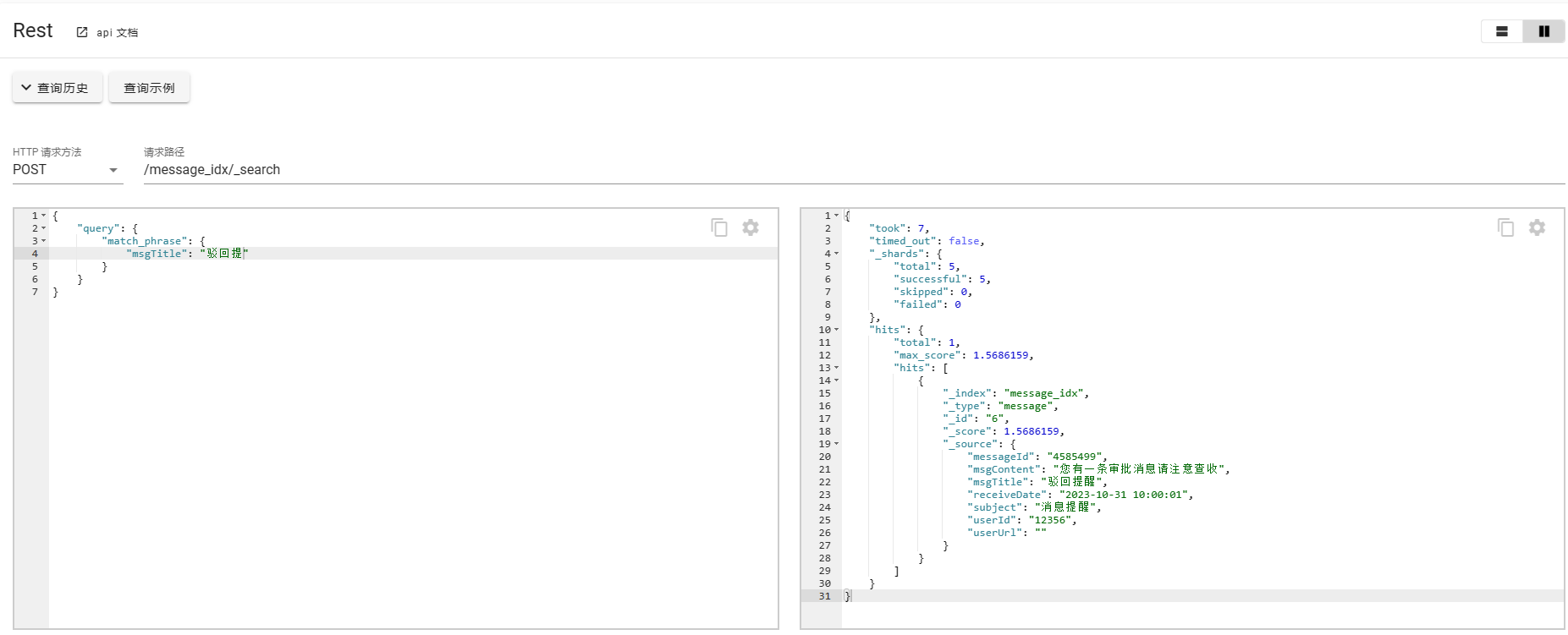
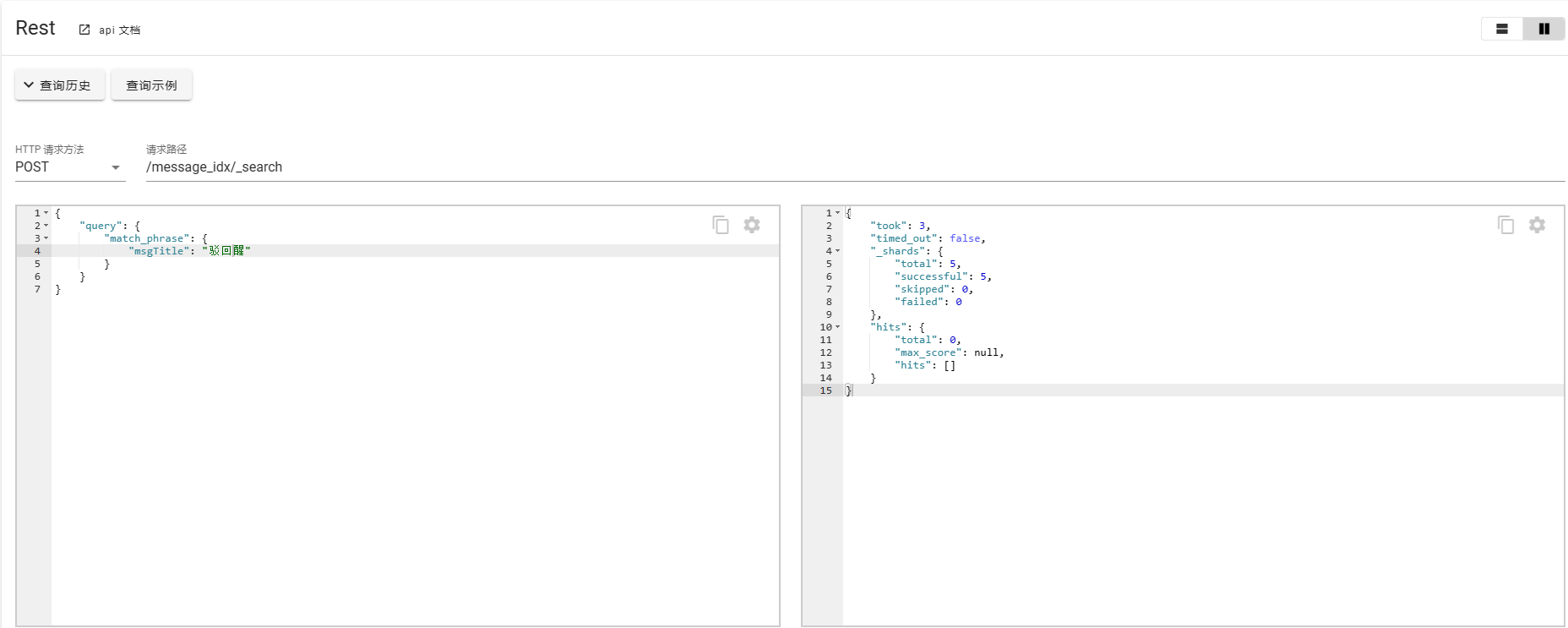
如果对于这种场景有特殊需求,刚好输入错误了单词或者字,ES也给出了相应的补救措施,使用slop进行修正
POST /message_idx/_search
{
"query": {
"match_phrase": {
"msgTitle": {
"query": "驳回醒",
"slop": 1
}
}
}
}
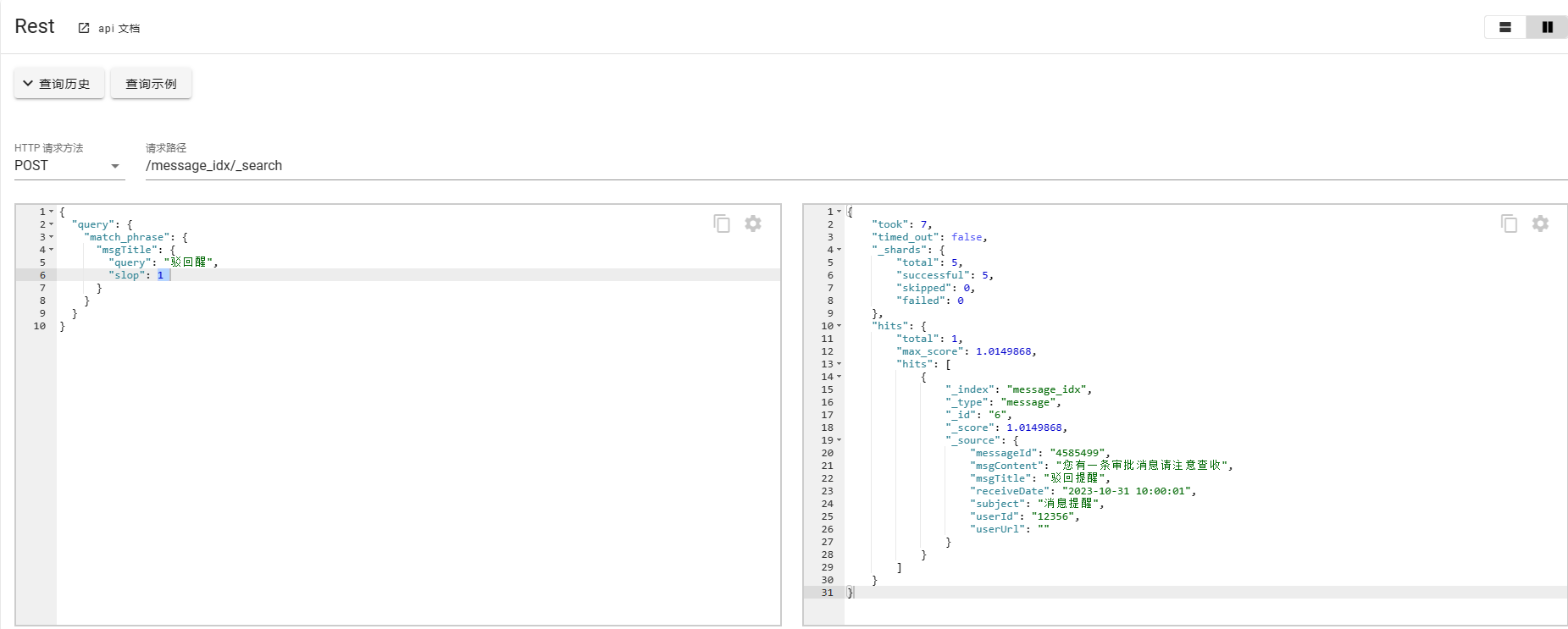
对比场景
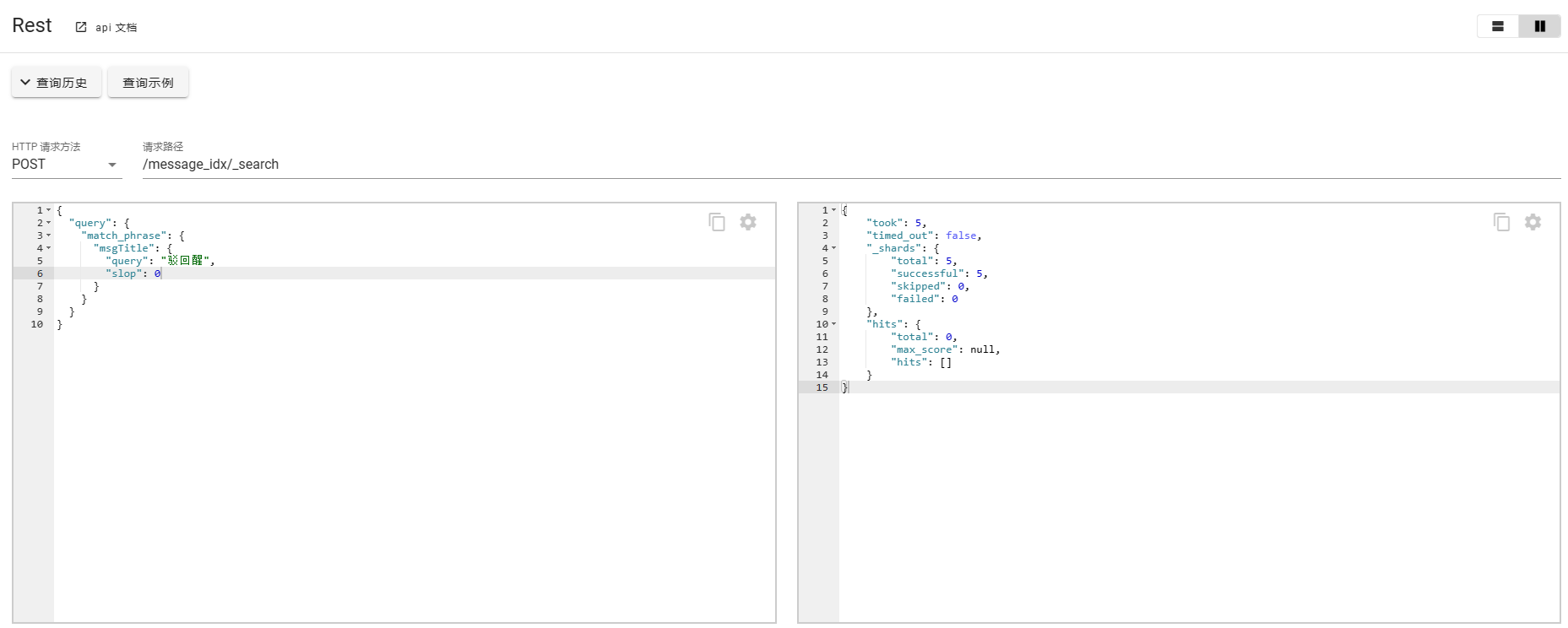
此外也可以使用match_phrase_prefix进行查询匹配。可以看做match_phrase的一个扩展,他会把query的查询条件进行分词,然后把最后一个单词看做是一个前缀,匹配索引中所有以这个单词为前缀的单词,然后进行返回。
关于更多的查询场景需要,可以去关注multi_match这种match类型的检索。
Term查询
Term查询对查询内容不做分词,直接去倒排索引里去匹配文档。
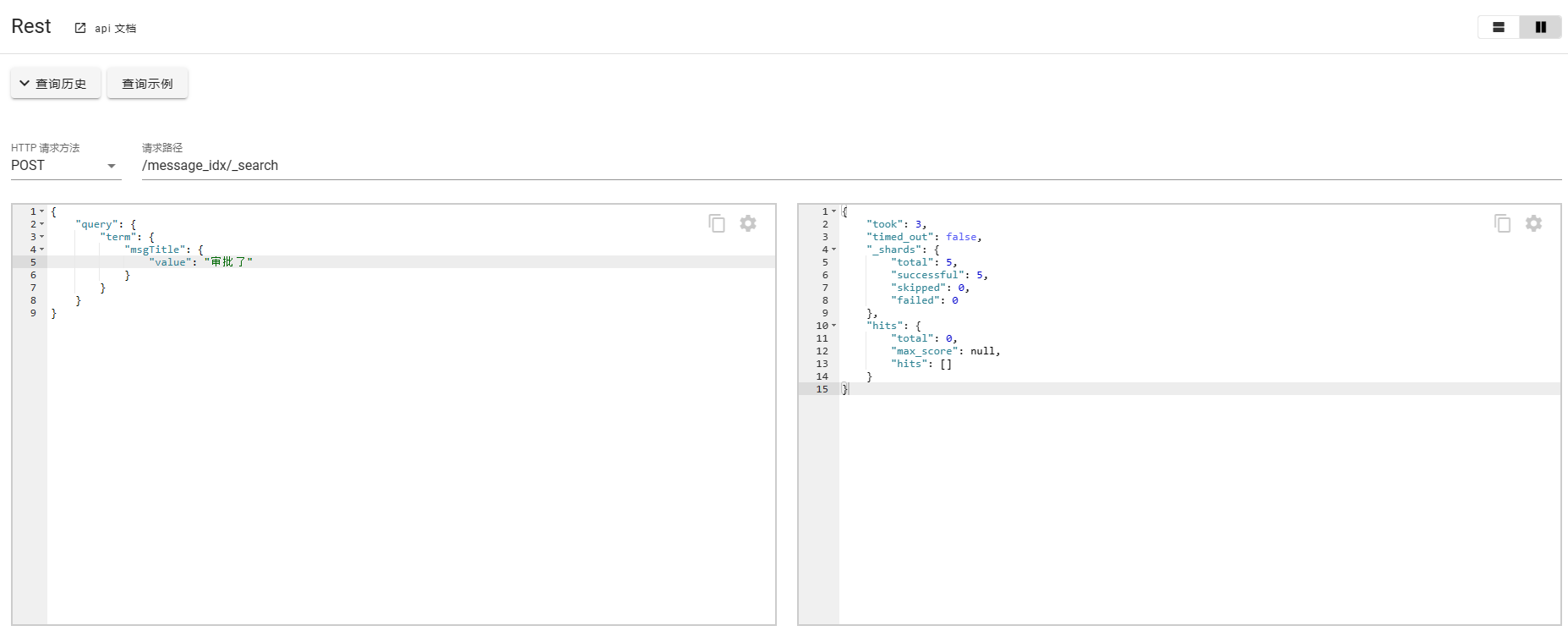
POST message_idx/_search
{
"query": {
"term": {
"msgTitle": {
"value": "审批"
}
}
}
}
# 匹配多个term
POST message_idx/_search
{
"query": {
"terms": {
"msgTitle": [
"审批",
"驳回"
]
}
}
}
组合查询
在传统关系型数据库中支持复杂组合条件,如AND、OR、NOT等,同样在ES中也可以实现类似的复杂查询,可以使用bool查询,在bool中可以嵌套should、must、must_not,它们分别SQL中的OR、AND、NOT条件。
另外,在组合查询时还支持使用filter的概念,filter的原理类似于Redis中BitMap的概念,在使用filter查询的时候,会使用一个二进制数组bitset保存倒排索引中的document list,符合条件的document置为1,不符合的document对应的位置为0,并且会将filter的bitset缓存起来,相同的filter条件进来的话会直接读取之前的bitset缓存,当document有新增或者修改的时候,Elasticsearch会维护对应的bitset。filter是仅仅过滤需要的数据,不会使用TF/IDF进行分数计算。filter会在普通的query之前执行,因此filter的效率更快,可以先过滤掉一些数据。
接下来是一些使用案例:
分页查询
Es中也支持类似于关系型数据库的分页查询。
- from + size
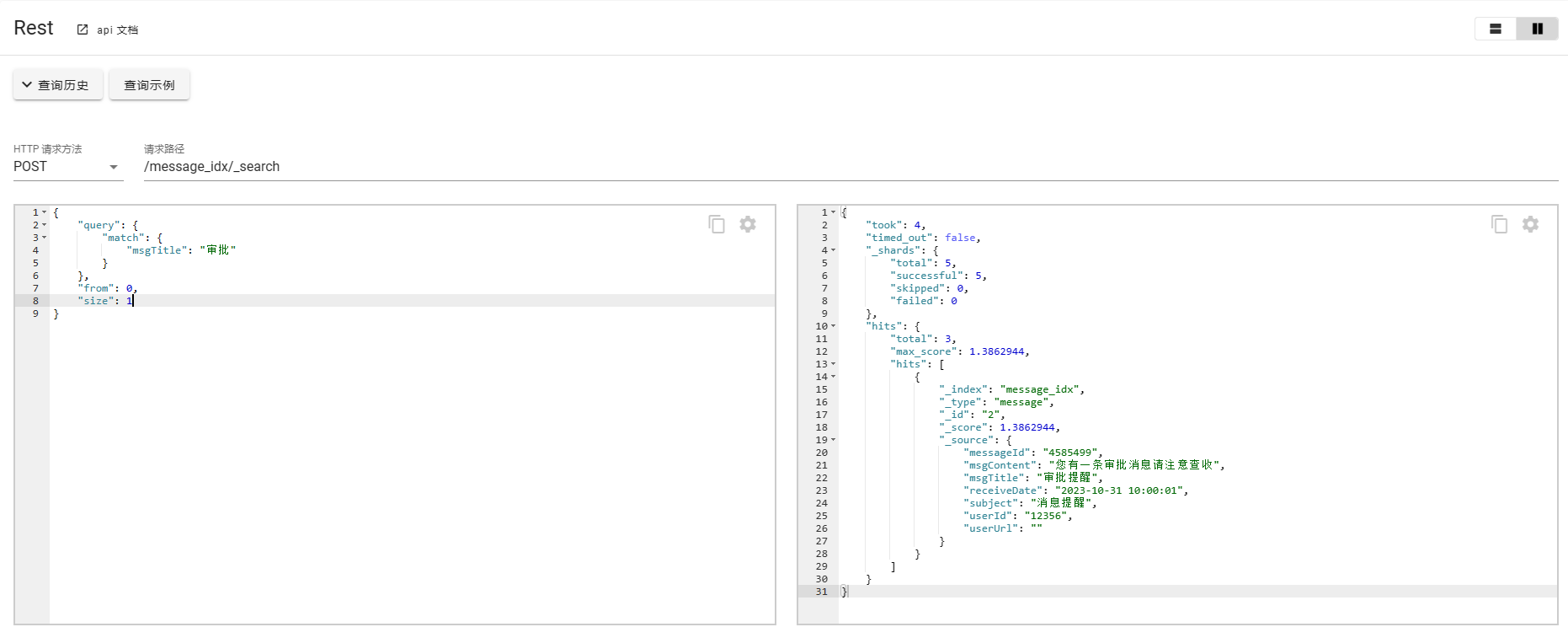
这种分页方式又被称为浅分页,from表示偏移量,size表示数据量。from+size的分页查询模式受制于Es分片的影响和index.max_result_window(默认为10000)参数的影响,查询的偏移量越靠后,查询效率会越低,因此在依赖分页查询较多并且数据量较大的场景下,应该考虑其他分页方式。 - scoll
scorll的使用类似于关系型数据库中的cursor,使用scroll,每次只能获取一页的内容,然后会返回一个scroll_id,根据返回的这个scroll_id可以不断地获取下一页的内容,所以scroll并不适用于跳页的场景。
POST /message_idx/_search?scroll=2m
{
"query": {
"match": {
"msgTitle": "审批"
}
},
"from": 0,
"size": 1
}
scroll=2m表示scrollId保留的时间为2分钟,在超出保留时间后,查询的上下文会被删除掉。这里的from必须从0开始,size表示返回数据的量。
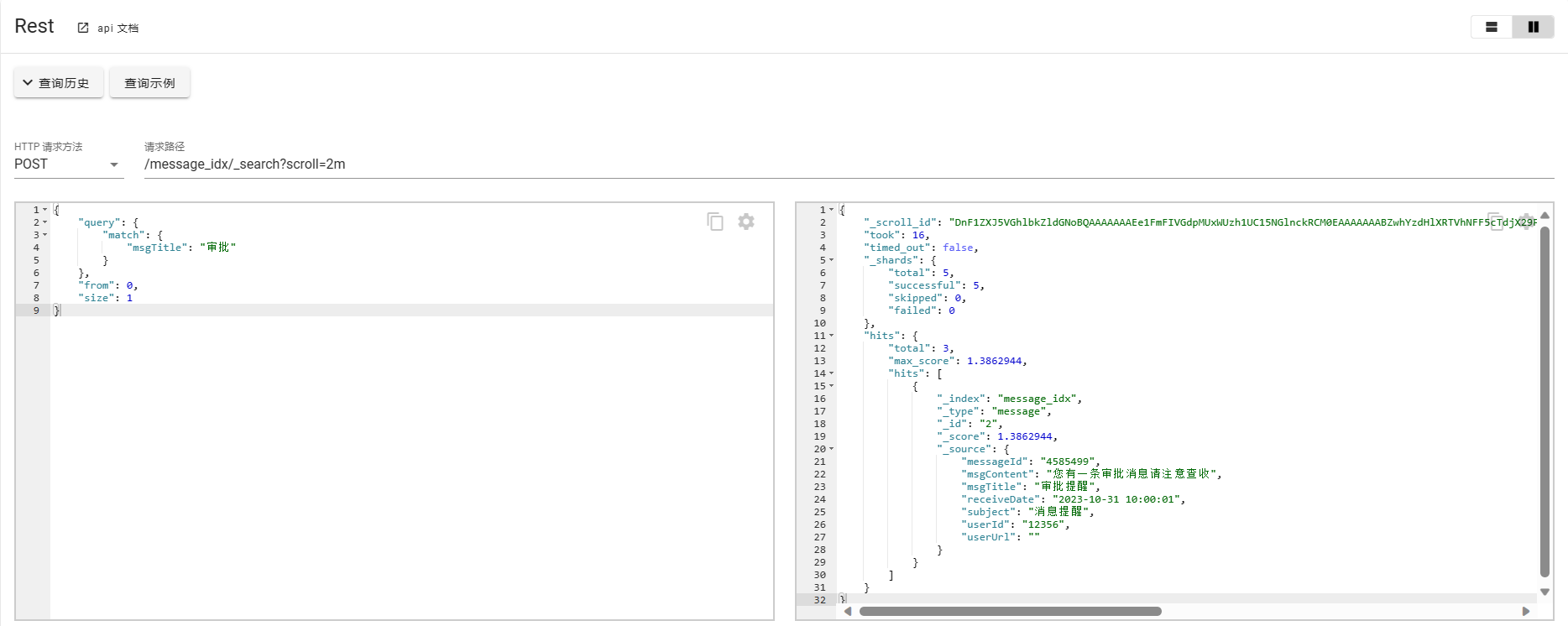
POST /_search/scorll
{
"scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAFOpFnFzb1kydkI5VHFXNmZlWTVOcEowWlEAAAAAAABHtBZhSFRnaTFMVlM4dVAteTRpZ3JEQjNBAAAAAAAAU6gWcXNvWTJ2QjlUcVc2ZmVZNU5wSjBaUQAAAAAAAFnBFjN0eVdFNWE0UXlxN2Nfb08xQjhPYkEAAAAAAABHsxZhSFRnaTFMVlM4dVAteTRpZ3JEQjNB",
"scroll": "5m"
}
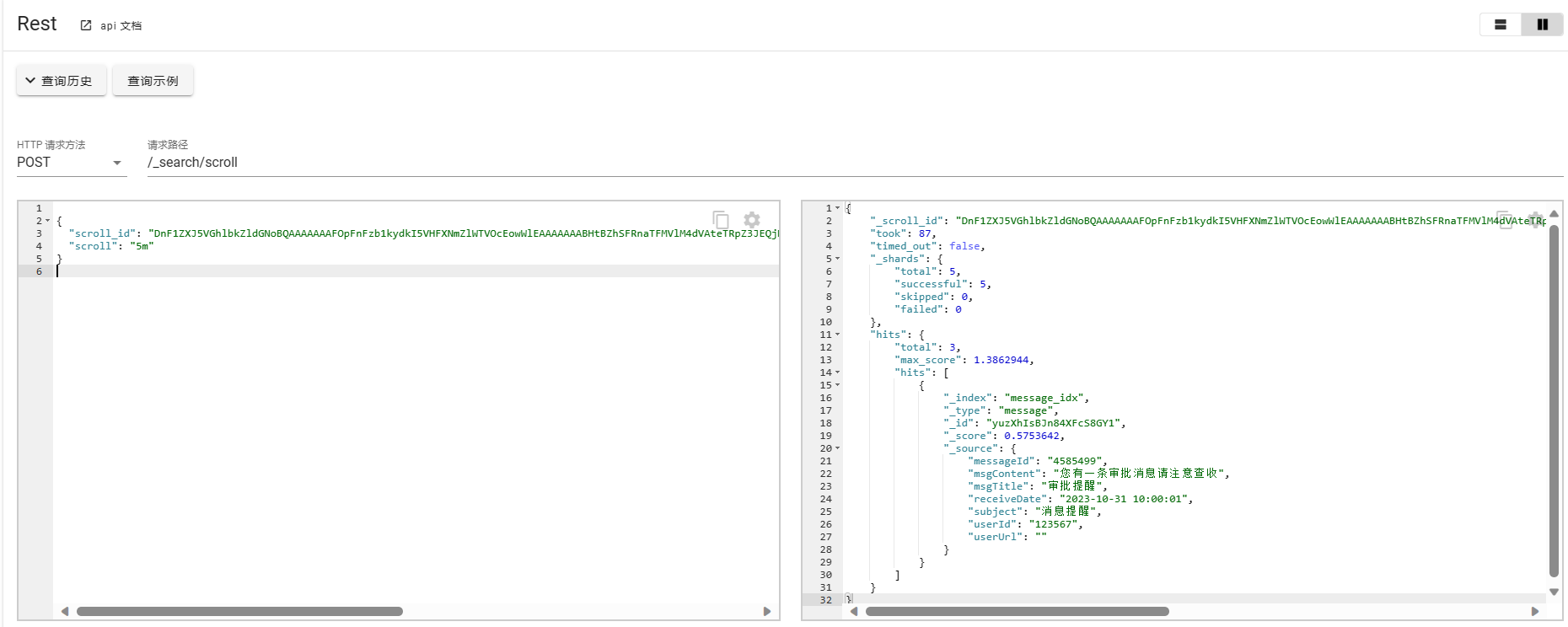
由于使用scorll查询是比较耗费资源的操作,即便在超出scroll的保留时间后,服务器端会自动删除查询的上下文,但是最好可以在不使用时进行手动清除。手动清除可以使用DELETE请求。
// 清除单个Id
DELETE _search/scroll/DnF1ZXJ5VGhlbkZldGNoxxx
// 清除所有scroll查询
DELETE _search/scroll/_all
- search_after
scroll在官方中并不建议用来实时查询,由于会消耗较高的资源,因此在接近实时查询的场景中尽可能的推荐使用search_after进行查询。
search_after 分页的方式是根据上一页的最后一条数据来确定下一页的位置,同时在分页请求的过程中,如果有索引数据的增删改查,这些变更也会实时的反映到游标上。由于每一页的数据依赖于上一页最后一条数据,所以这种方式也无法跳页请求。为了找到每一页最后一条数据,每个文档必须有一个全局唯一值,官方推荐使用 _uid 作为全局唯一值,也可以使用业务层的 id 作为唯一 id。
POST /message_idx/_search
{
"query": {
"match": {
"msgTitle": "审批"
}
},
"from": 0,
"size": 1,
"sort": [
{
"receiveDate": {
"order": "desc"
},
"_id": {
"order": "desc"
}
}
]
}
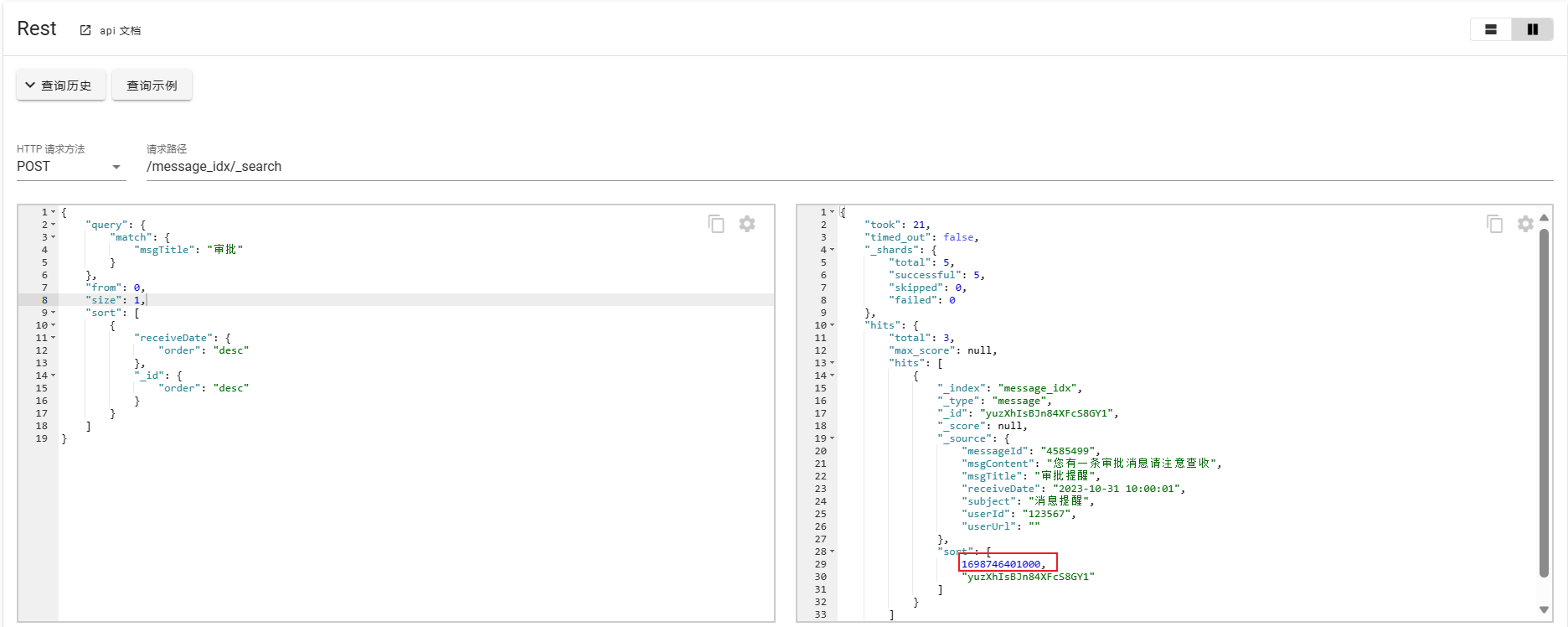
这里from和size同样与scroll一样。这里使用receiveDate和_id作为唯一值进行查询,可能不严谨,在现有数据是满足的,这里仅作示例。然后使用sort的返回值进行下一步的查询。
POST /message_idx/_search
{
"query": {
"match": {
"msgTitle": "审批"
}
},
"from": 0,
"size": 1,
"search_after": [
1698746401000,
"yuzXhIsBJn84XFcS8GY1"
],
"sort": [
{
"receiveDate": {
"order": "desc"
},
"_id": {
"order": "desc"
}
}
]
}
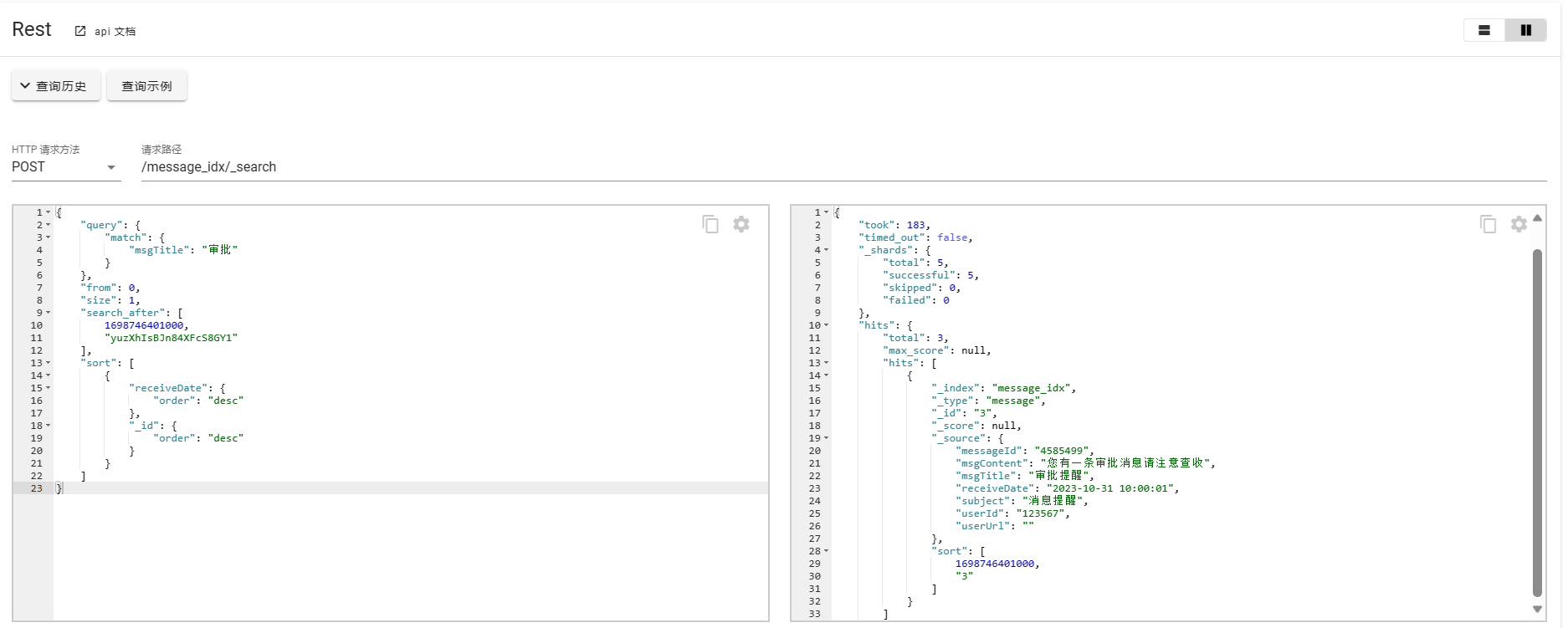
这里对Es中几种分页的方式进行简单的示例,实际使用中需要根据实际情况进行选择。from+size满足跳页但是不适合大量数据场景的查询,scroll和search_after都适合大数据量场景,且都不支持跳页查询。scroll耗费资源较高更适合导出等场景,而search_after更支持近乎实时的查询,要求有唯一的id用于分页,实现复杂。
范围查询
Es支持多种范围类型的查询,如数字、日期、IP地址等。范围查询会包含边界问题,例如大于、小于、大于等于、小于等于,在Es中需要借助表达式进行实现。
- gt: > 大于(greater than)
- lt: < 小于(less than)
- gte: >= 大于或等于(greater than or equal to)
- lte: <= 小于或等于(less than or equal to)
接下来对范围查询进行简单示例,范围查询使用range配合Es的filter实现,由于filter无法单独使用,遇到这种场景时,需要对请求参数使用constant_score封装。
POST /message_idx/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"messageId": {
"gte": 4585499,
"lte": 4585499
}
}
}
}
}
}
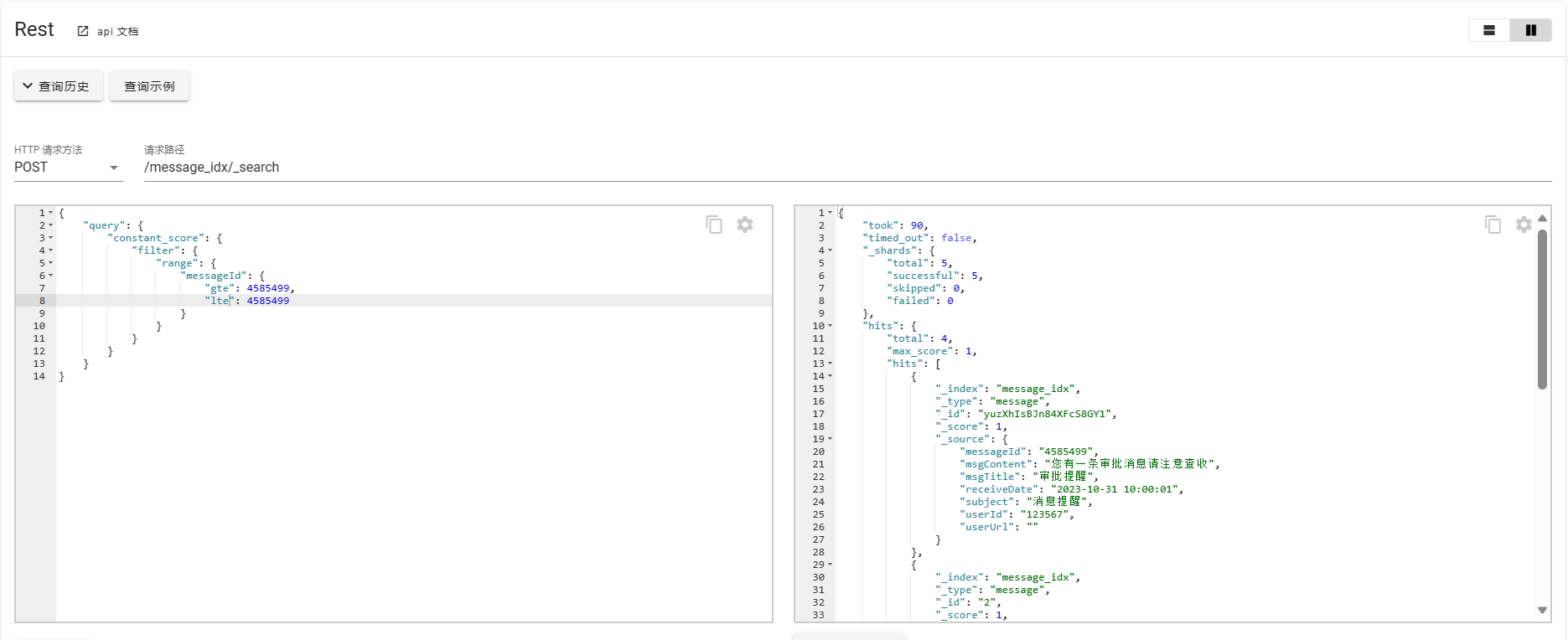
针对不同数据类型,Es查询时使用API的形式一致,但是对于不同的字段类型,使用的算法不同,Elasticsearch 从 2016 年引入了 BKD 树算法,在创建索引时会依据字段类型设置不同的算法实现:
• 若是字符类型的,基于 Inverted Index 构建索引,即倒排索引。
• 若是数值类型,基于 BKD-Tree 构建索引(Bkd-Tree 作为一种基于 K-D-B-tree 的索引结构,用来对多维度的点数据 (multi-dimensional point data) 集进行索引)。
因此设置合适的Mapping信息,会提高Es的查询能力,也能更精确的使用索引。
高亮查询
在百度等某些搜索网站,查询内容时,返回结果会对查询内容关键字进行高亮、加粗等提示,这种效果就可以借助ES进行实现。
POST /message_idx/_search
{
"query": {
"match": {
"msgContent": "审批"
}
},
"from": 0,
"size": 1,
"sort": [
{
"receiveDate": {
"order": "desc"
},
"_id": {
"order": "desc"
}
}
],
"highlight": {
"boundary_scanner_locale": "zh_CN",
"fields": {
"msgContent": {
"pre_tags": [
"<em>"
],
"post_tags": [
"</em>"
]
}
}
}
}
查看返回结果,会对查询内容进行处理:
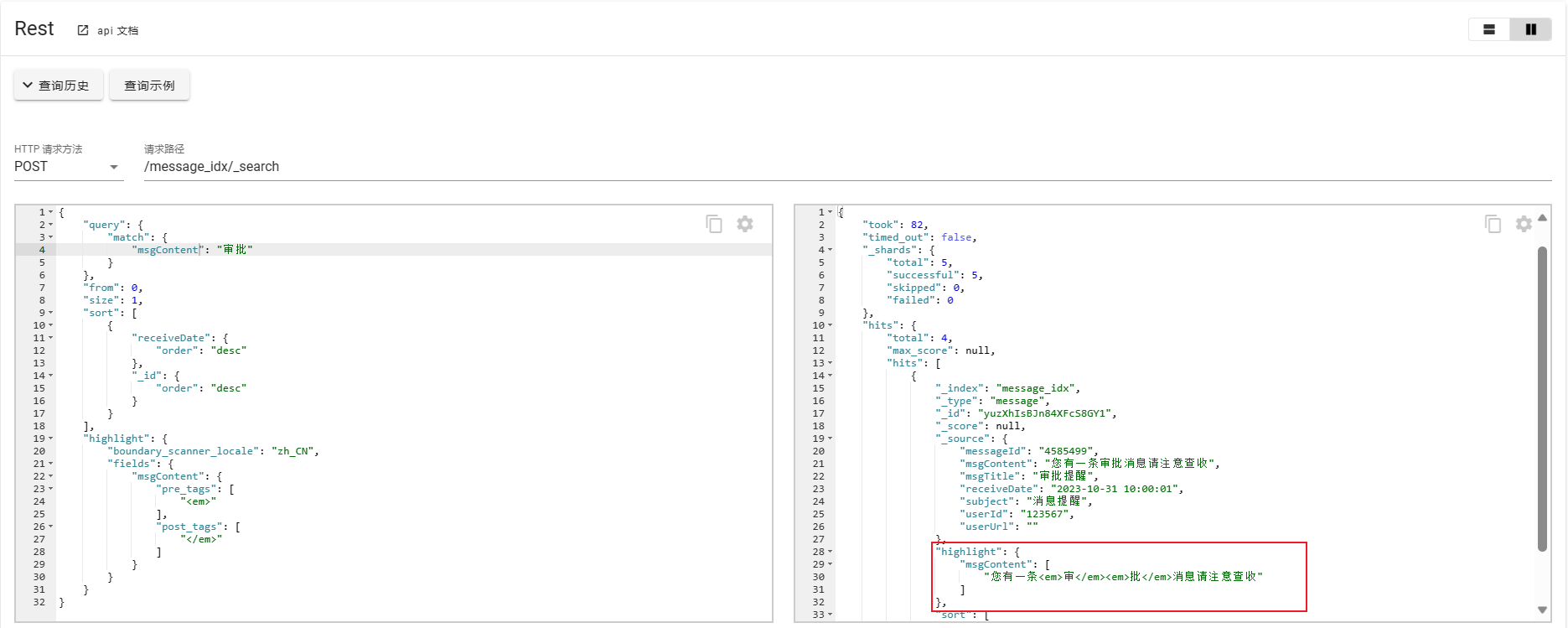
关于高亮还有很多其他相关参数,参考如下:
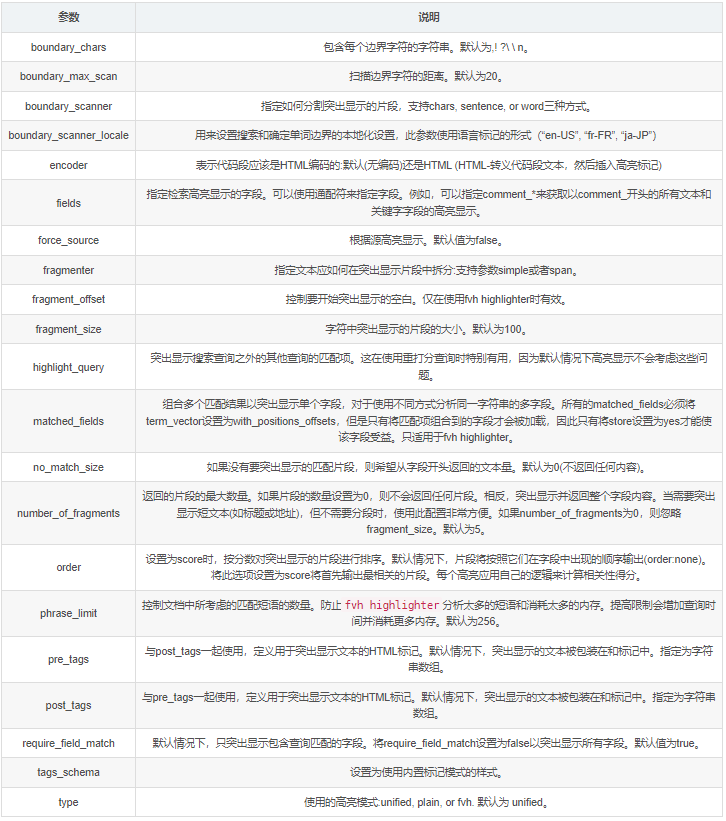
分词
ES模糊查询的强大之处在于其可以进行分词并且维护成倒排索引,分词功能的实现需要借助于一次分词插件,对于中文支持比较好的分词插件就是IK分词器。基本使用如下所示:
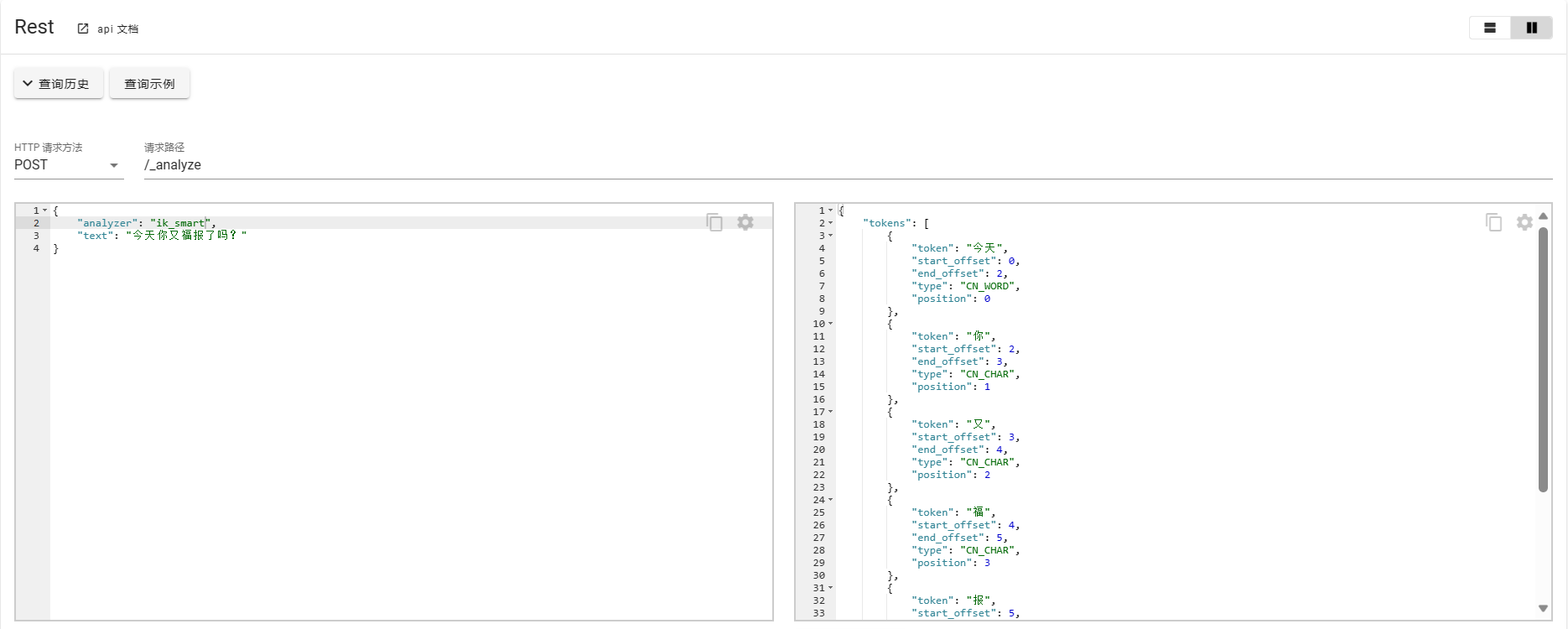
对于IK分词器常用的模式有以下几种:
POST _analyze
{
"analyzer": "ik_smart",
"text": "中华人民共和国国歌"
}
POST _analyze
{
"analyzer": "ik_max_word",
"text": "中华人民共和国国歌"
}
最佳实践
SpringBoot整合ES版本选择
上述介绍的基于REST API调用的客户端,在实际项目应用中是不能整合到系统集成的,只适合用来检索查看数据使用,Spring提供了一套关于ES的整合方案,并从属于SpringDataElasticsearch模块,针对不同版本的ES,SpringDataElasticsearch也提供了不同的适配方案,并且每个版本支持的客户端也不尽相同。
在使用的时候如果不提前选型或者做足够的了解,会遇到各种各样的坑,这里会对常用的客户端进行简介,并提供整合案例以供参考。
接下来所介绍的内容,主要参考官方文档。
客户端简介
简单来说,客户端存在的意义就是为了更好的使用ES,对服务端的数据进行操作。参考上文所提到的官方文档,目前为止,ES支持的客户端共有,Jest client、Rest client、Transport client、Node client几种,其中Jest和Rest是使用的HTTP协议,Transport client和Node client使用的是Native Elasticsearch binary协议。
在ES5.0之前官方提供的客户端只有Transport client、Node client协议,Jest为非官方支持客户端,ES5.0之后官方主推荐的为Rest客户端。

参考官方提醒,以及综上所述,在使用ES时尽可能的使用Rest Client。
关于Spring、SpringBoot、SpringDataElasticsearch版本的选择,可以参考如下官方提供的信息:
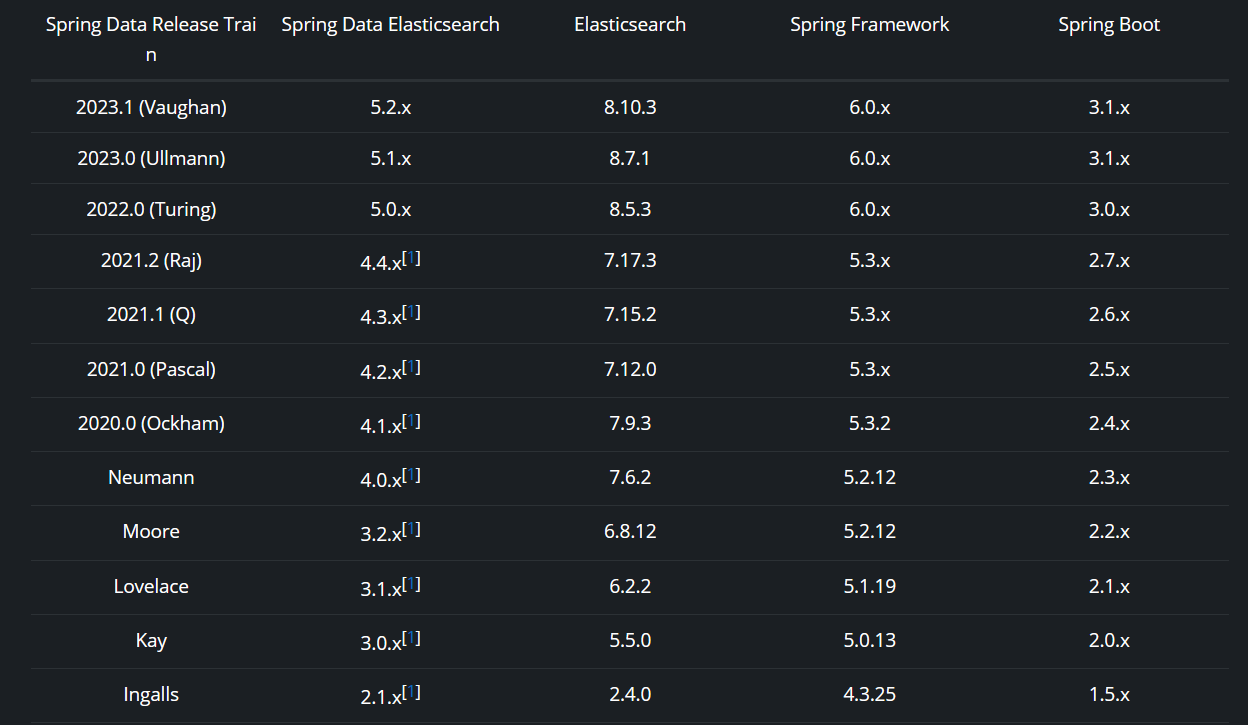
https://docs.spring.io/spring-data/elasticsearch/reference/index.html
整合案例
接下来使用SpringBoot 2.3.7.RELEASE、High Level REST Client及ES 7.8.0进行整合演示。Java High Level REST Client 是基于Java Low Level REST Client的,每个方法都可以是同步或者异步的。同步方法返回响应对象,而异步方法名以“async”结尾,并需要传入一个监听参数,来确保提醒是否有错误发生。
- 首先引入整合依赖。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
- 整合客户端
官方文档提供了两种整合方式,命令式和响应式客户端。
- 命令式
import org.springframework.data.elasticsearch.client.elc.ElasticsearchConfiguration;
@Configuration
public class MyClientConfig extends ElasticsearchConfiguration {
@Override
public ClientConfiguration clientConfiguration() {
return ClientConfiguration.builder()
.connectedTo("localhost:9200")
.build();
}
}
- 响应式
import org.springframework.data.elasticsearch.client.elc.ReactiveElasticsearchConfiguration;
@Configuration
public class MyClientConfig extends ReactiveElasticsearchConfiguration {
@Override
public ClientConfiguration clientConfiguration() {
return ClientConfiguration.builder()
.connectedTo("localhost:9200")
.build();
}
}
如果有其他特殊配置参数需要,可以设置
import org.springframework.data.elasticsearch.client.ClientConfiguration;
import org.springframework.data.elasticsearch.support.HttpHeaders;
import static org.springframework.data.elasticsearch.client.elc.ElasticsearchClients.*;
HttpHeaders httpHeaders = new HttpHeaders();
httpHeaders.add("some-header", "on every request")
ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo("localhost:9200", "localhost:9291")
.usingSsl()
.withProxy("localhost:8888")
.withPathPrefix("ela")
.withConnectTimeout(Duration.ofSeconds(5))
.withSocketTimeout(Duration.ofSeconds(3))
.withDefaultHeaders(defaultHeaders)
.withBasicAuth(username, password)
.withHeaders(() -> {
HttpHeaders headers = new HttpHeaders();
headers.add("currentTime", LocalDateTime.now().format(DateTimeFormatter.ISO_LOCAL_DATE_TIME));
return headers;
})
.withClientConfigurer(
ElasticsearchClientConfigurationCallback.from(clientBuilder -> {
// ...
return clientBuilder;
}))
. // ... other options
.build();
SpringDataElasticsearch中提供了一个高级API并且整合了客户端配置,也可以呃直接使用High Level REST Client完成整合,更加快速高效。
/**
* ES客户端配置
* @author starsray
* @date 2023/11/01
*/
@Configuration
public class RestClientConfig extends AbstractElasticsearchConfiguration {
@Override
@Bean
public RestHighLevelClient elasticsearchClient() {
final ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo("localhost:9200")
.build();
return RestClients.create(clientConfiguration).rest();
}
}
使用ES的数据一致性问题
在复杂系统架构中,引入的组件越多,对应要解决的协同问题也越多,比如数据库和缓存数据一致性的解决,如果引入Es,同样也要考虑数据库和Es的数据一致性问题。
如何保证Es与数据库数据的一致性有多种方案,并没有一种万能的方式来解决所有场景中的问题,使用中需要根据对数据一致性的容忍性,以及成本高低等具体业务场景来保证一致性。这里提供一些解决思路,大概有一下几种方式。
-
双写模式(Dual Write):
- 在这种模式下,每当数据库中的数据发生变化时,同时将相应的更改操作发送到ES中。
- 应用程序在执行数据库写操作后,再执行ES的写操作,确保两个存储系统中的数据保持一致。
- 这种方法可以通过使用消息队列、异步任务或数据库触发器来实现。
-
变更数据捕获(Change Data Capture,CDC):
- CDC是一种技术,用于捕获数据库中发生的数据变更操作,并将其作为事件流发送给其他系统。
- 数据库中的变更操作可以被捕获并转发到ES,以便同步更新ES中的数据。
- CDC可以通过数据库日志、触发器或专门的CDC工具来实现。
- 当然也可以检测Es中数据的变更,通过Es往数据库中同步数据。
-
定期同步(Periodic Sync):
- 定期同步是指定期将数据库中的数据与ES进行同步。
- 可以使用定时任务或调度程序,定期将数据库中的数据导入ES中,保持数据的一致性。
- 这种方法可能会导致ES中的数据与数据库中的数据之间存在一定的延迟。
需要注意的是,ES和数据库之间的一致性无法做到实时的完全一致,因为ES是一个分布式系统,具有自己的数据复制和分发机制。在某些情况下,可能会发生ES中的数据与数据库中的数据之间的短暂不一致。以上同步思路无非是在写入前进行同步或者异步双写,在写入后进行数据库侧或者Es侧向另一侧的数据同步,亦或是定时任务去同步。对应以上同步思路,也对应相关的工具实现,相应的同步策略。如下所示:
- 使用JDBC Sink插件:JDBC Sink插件可以将数据从Elasticsearch实时地写入到数据库中,从而实现数据的同步。该插件会自动处理数据冲突和重试,确保数据的一致性。
- 使用Logstash:Logstash可以作为数据的中间件,通过配置管道将数据从Elasticsearch同步到数据库中。Logstash提供了许多插件,可以处理各种数据源和目标,包括数据库。通过使用Logstash,可以实现数据的实时同步,并且可以添加自定义的转换和过滤器来处理数据。
- 使用Kafka Connect:Kafka Connect是Apache Kafka的一部分,可以将数据从Elasticsearch同步到数据库中。Kafka Connect提供了许多连接器,可以将数据写入到各种类型的数据库中。通过使用Kafka Connect,可以实现高可靠的数据同步,并且可以配置数据转换和过滤器来满足特定的业务需求。
- 手动编写数据同步脚本:如果以上工具不适合特定的场景,可以手动编写数据同步脚本来实现数据的一致性。例如,可以使用Java或Python编写一个程序,从Elasticsearch中读取数据,并将其写入到数据库中。在编写脚本时,需要注意处理数据冲突和重试的情况,以确保数据的一致性。
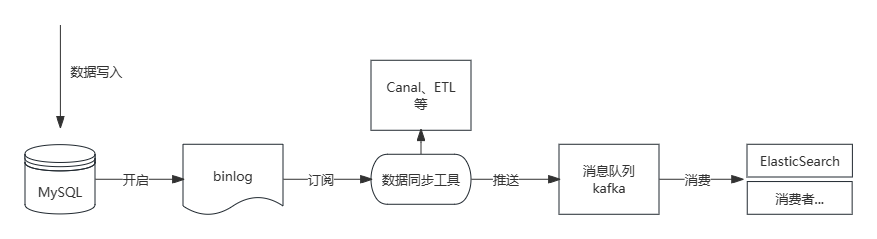
- 利用MySQL主从复制机制,使用Canal进行Slave伪装,订阅binlog,推送到消息队列,既保证了近乎实时的一致性,也能实现业务系统之间的解耦,也是实际中较为常用的一种方式。如下图所示:
总之,保证数据库和Elasticsearch的数据一致性需要根据具体的业务需求和数据同步场景选择合适的方法。无论使用哪种方法,都需要注意处理数据冲突和重试的情况,以确保数据的一致性。
原理简析
通过Es基本使用,以及实际应用中常见问题的解决,这里对Es的基本原理进行简单介绍以加深对Es的理解。接下来主要围绕集群、分片、倒排索引、文档操作等内容进行展开。
集群和分片
Elasticsearch(ES)是一个分布式搜索和分析引擎,它使用集群和分片的概念来实现数据的分布式存储和处理。下面是对ES集群和分片的详细描述:
集群
- 集群(Cluster):
- ES集群由一个或多个节点(Node)组成,这些节点协同工作以实现数据的分布式存储和处理。集群的主要优势是提供高可用性和横向扩展能力。当一个节点故障时,集群可以继续正常运行,并且可以通过添加更多节点来增加处理能力。
- 集群中的每个节点都有一个唯一的名称,在同一网络中具有相同集群名称的节点组成集群,默认的集群名称为elasticsearch,如果只有一个节点,则组成一个单节点集群。
- 集群状态:
- Green: 所有的主分片和副本分片准备就绪,集群中即使某个节点的服务突然不能使用也不会造成数据丢失,但集群状态会变为Yello状态。
- Yello: 所有的主分片准备就绪,但存在至少一个主分片(假设p0)对应的副本分片(r0)未就绪,如果刚好r0的主分片p0挂掉,会导致查询数据丢失,此时集群进入到Red状态。
- Red: 至少有一个主分片未就绪,Es中的副本分片可以转换为主分片,主分片未就绪的直接原因是未找到对应的副本分片成为新的主分片,此时查询结果会出现数据丢失,因为Es中单个索引的数据是分布在多个主分片中的。
节点
- 节点(Node):
- 节点是ES集群中的一个成员,一个ES节点对应一个运行的ES实例,可以是独立的物理服务器或虚拟机。
- 每个节点都有一个唯一的名称,如果没有指定名称默认使用uuid,并且具有自己的角色和职责。
- 节点类型:
- 主节点(Master Node):集群中的一个节点会被选择为Master节点,主节点负责管理集群的整体状态,包括索引的创建、分配和删除,以及节点的加入和移除,主节点不参与文档层面的变更和检索,不会成为海量请求的瓶颈,通过elasticsearch.yml中的node.master=true设置。
- 数据节点(Data Node):数据节点存储实际的索引数据和执行搜索操作。它们负责数据的分片和复制,以实现数据的高可用性和负载均衡,通过elasticsearch.yml中的node.data=true设置,默认情况下集群中的每个节点都是数据节点,如果在节点管理较多的场景下,需要专门的master节点可以设置node.master=true和node.data=false实现。
- 协调节点(Coordinating Node):协调节点负责将客户端的请求路由到适当的数据节点,并将结果汇总返回给客户端,通过elasticsearch.yml中的node.master=flase和node.data=false设置实现,此时该节点扮演的更多的是一个负载均衡器的角色。
分片
- 分片(Shard):
- 分片是ES中数据的最小单位,由于单个集群节点物理资源的限制,每个节点存储的文档数量是有限的,因此ES中通过引入分片的概念,将一个索引的数据分成多个分片,分布在不同的节点上,每个索引都由一个或多个分片组成。
- 每个分片的数据是独立的,每个分片底层都对应一个完整的Lucene服务,并且每个分片中只包含了一个Index的部分数据,对于一个Search Request,每一个分片中的Lucene都会执行,并将执行结果合并返回。
- 此外,ES相比于Lucene所具备的分布式场景下还有以下优势:
- 水平扩展性:通过将数据分布在多个分片上,可以将数据存储和处理的负载平均分布到集群中的多个节点上,从而实现横向扩展。
- 高可用性:每个分片可以有多个副本(Replica),副本用于提供数据的冗余和故障恢复。如果某个分片不可用,副本可以接管工作。
- 并行处理:分片允许多个分片同时处理查询请求,从而提高搜索和聚合操作的性能。
- 分片类型:
- ES中的分片被区分为主分片和副本分片,主分片会尽可能的分散在不同的节点上,Es会自动感知节点数目的改变并重新改变分片分散,这个过程也叫做relocation,默认情况下一个索引会自动创建5个主分片,由于每个主分片会对应一个副本分片,因此一个索引默认会存在10个分片,当一个集群中只有单个节点时,由于无法创建副本分片,此时集群索引的状态为Yellow。
- 对于一个已经创建的索引,除非进行reindex,否则不能调整主分片的数量,但是可以随时调整副本分片的数量,因此在创建索引时,需要提前规划。
- 主分片(Primary Shard):每个索引的主分片负责数据的写入和索引操作。一个索引通常有多个主分片,每个主分片都是一个完整的、独立的索引。
- 副本分片(Replica Shard):每个主分片可以有零个或多个副本分片。副本分片只是主分片的复制,用于提供数据的冗余和故障恢复。副本分片可以分布在不同的节点上,从而提高查询的并行性和可用性。副本分片的作用主要由以下几点:
- 高可用:当主分片下线后,对应的副本分片会自动转换为主分片,同时为主分片生成新的副本分片。
- 提高性能:主分片和副本分片拥有的数据总量是一致的,对于查询操作,类似于MySQL的读写分离,可以直接在副本分片进行,需要注意的时Index Request只能在主分片进行。
如下所示,使用k8s对Es集群进行伸缩,其对应的分片也在动态调整,Es集群的node由3调整到5,10个分片也均匀的分布在各个节点上。
调整前:

调整后:

通过使用集群和分片的机制,Elasticsearch能够实现数据的分布式存储、高可用性和横向扩展,以满足大规模数据处理和高性能搜索的需求。
倒排索引
概念引入
在说起倒排索引之前,先来再回顾一下传统的数据库索引是如何使用的?
通常在关系型数据库中,索引的创建至关重要,选择合适的字段去创建索引,可以快速的帮助我们去查询到想要的数据。而且再创建索引时,也会选择一些有规律的、有顺序的字段去充当索引,目的都是为了利用索引的原理特性。以MySQL为例,使用B+Tree作为索引,索引的非叶子节点存储数据,叶子节点存储指针,指向真实数据记录,如果查询的条件(自增ID)为主键索引,则可以直接命中数据,无需回表。这种根据ID列查询整条数据的使用方式我们称之为正排索引,当然也有其局限性,如果我们想通过文本关键字去查询数据内容的时候,即便like可以实现模糊搜索,但是在大量数据的场景下,其性能会大大下降,这种场景下,实现海量数据的检索,就需要用到倒排索引了。
倒排索引(Inverted Index)是一种数据结构,用于在大规模文档集合中快速定位包含特定关键词的文档。相对于正排索引,倒排索引以关键词为中心,将每个关键词映射到包含该关键词的文档列表。这种颠倒的结构使得搜索引擎能够高效地响应用户的查询,快速返回相关的文档。
再简单来说,正排索引是根据ID去查询数据,倒排索引是根据关键词查询数据ID,进而取出整条数据,因此可以理解为倒排,接下来对ES中倒排索引的使用进一步分析。
工作原理
在进行原理演示前,继续使用MySQL数据库,正排索引为例,进行引入。例如在MySQL中存储示例数据。
create table itsm_service.language_info
(
id int auto_increment
primary key,
language_name varchar(50) null,
language_desc varchar(255) null
);
INSERT INTO language_info (id, language_name, language_desc) VALUES (1, 'Java', 'Java is the most widely used backend language');
INSERT INTO language_info (id, language_name, language_desc) VALUES (2, 'PHP', 'PHP is the best language in the world');
INSERT INTO language_info (id, language_name, language_desc) VALUES (3, 'JavaScript', 'JavaScript is the most widely used front-end language');
| id | language_name | language_desc |
|---|---|---|
| 1 | Java | Java is the most widely used backend language |
| 2 | PHP | PHP is the best language in the world |
| 3 | JavaScript | JavaScript is the most widely used front-end language |
在MySQL中,默认情况下会根据主键id列创建索引,如果想查看Java就可以使用id=1进行匹配查询数据,以此类推其他数据。或者是根据language_name列创建索引,根据该列来查询,但是使用此列的索引性能就不如使用id列,会利用到覆盖索引的特性,这里就不再过多扩展。
这些数据如果存储在Es中,会如何创建索引,并进行检索呢?
前面提到在倒排索引中,会以关键词为核心,因此会对存储的内容进行一个内容转换,以及创建索引的过程。构建倒排索引的过程可以概括为文档预处理和生成倒排索引两个阶段。
对每一个阶段又可以进行如下划分:
- 文档预处理阶段
- 分词(Tokenization): 将文档内容拆分,在Es中创建Index时可以在Mapping中指定字段的分词器,将文档拆分成单词形成一个词汇列表。
- 去停用词(Stopword Removal): 移除在搜索中没有实际意义的词语,如语气词,助词等,这有助于提高倒排索引的效率和准确性。
- 词干提取(Stemming): 将词语还原为其词干形式,去除词尾,将相关的词汇映射到同一词根,减少索引的大小,可以理解为一个相似去重,如广泛的,广泛。
- 倒排生成阶段
- 建立词汇表: 将预处理后的文档中的所有词汇构建成一个唯一词汇表,即每个词汇都有一个唯一的标识符。
- 映射关键词到文档ID: 遍历文档,对于文档中的出现的关键词,将其映射到文档的唯一标识符(文档ID),类似于字典的使用形式。
- 生成倒排列表: 对于每个关键词,创建一个倒排列表,其中包含映射到该关键词的所有文档ID。倒排列表实际上是一个映射,将关键词与包含该关键词的文档关联起来。
上述Doc,根据Es处理的结果,最后会生成一个倒排文件,如下所示:
| 单词ID(WordID) | 单词(Word) | 倒排列表(DocID;TF; |
|---|---|---|
| 1 | Java | (1,1,[0]) |
| 2 | is | (1,1,[1]);(2,1,[1]);(3,1,[1]) |
| 3 | the | (1,1,[2]);(2,1,[2]);(3,1,[2]) |
| 4 | most | (1,1,[3]);(3,1,[3]) |
| 5 | widely | (1,1,[3]) |
| 6 | used | (1,1,[5]);(3,1,[5]) |
| 7 | backend | (1,1,[6]) |
| 8 | language | (1,1,[7]);(2,1,[4]);(3,1,[7]) |
| 9 | PHP | (1,1,[0]) |
| ... | ... | ... |
(DocID;TF;
相比于传统数据库的检索方式(根据ID列或者索引列查询出整条数据),倒排索引(Inverted Index):倒排索引是实现“单词-文档矩阵”的一种具体存储形式,通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。倒排索引主要由两个部分组成:“单词词典”和“倒排文件”。
数据操作过程
关于数据的操作,需要明白Es和底层支持Lucene的区别点。Lucene具有以下特点:
- Lucene只是一个搜索引擎库,本身并不支持分布式架构部署及海量数据的处理,Es在其基础上进行上层设计,引入分片的概念,主分片和副本分片,每一个分片都包含一个完整的Lucene功能。
- Lucene不具备实时检索的能力,数据被写入后并不能立即检索,需要生成完整的Segment才可以用来数据检索,另外Lucene在更新时不支持部分数据更新,需要对全量文档进行更新。
- Lucene存储数据并不会被立即持久化到磁盘,如果服务器宕机,内存中存储的数据有可能全部丢失。
了解了Lucene的一些特性后,应该理解了Es并不是简单的依托Lucene进行实现搜索引擎,在其基础上做了大量的适配改造工作,才使得Es具备了海量数据实时检索以及分布式能力。
查询过程
Elasticsearch(ES)的检索过程涉及多个步骤,包括查询解析、倒排索引的使用和评分计算。下面是ES检索的详细过程:
-
查询解析:首先,ES会解析你发送的查询请求。查询可以使用Elasticsearch提供的查询语法(如Query DSL),或者使用简单的字符串查询。ES会解析查询语句,并理解查询的类型、条件和参数。
-
倒排索引的使用:ES使用倒排索引来加速数据的检索。倒排索引是一种数据结构,它记录了每个词项(term)在哪些文档中出现。ES会根据查询条件中的词项,快速定位到包含这些词项的文档。
-
查询执行:根据查询条件和倒排索引,ES开始执行查询。它会在索引的分片(shard)上并行执行查询操作。每个分片是索引的一个子集,包含部分文档和对应的倒排索引。查询结果会从各个分片返回给协调节点(coordinating node)。
-
结果合并:协调节点收集来自各个分片的查询结果,并进行结果的合并和排序。它会对结果进行聚合、分页、排序等操作,以生成最终的查询结果集。
-
评分计算:ES会为每个查询结果计算一个分数(score),用于表示文档与查询的相关性。分数基于TF-IDF(词频-逆文档频率)算法和其他相关性算法,考虑了词项的频率、文档的长度等因素。
-
结果返回:最后,ES将查询结果返回给客户端。结果可以包括匹配的文档、聚合结果、分页信息和其他相关信息。客户端可以根据需要对结果进行处理和展示。
需要注意的是,ES的检索过程是分布式的,查询会在多个节点上并行执行,并将结果汇总返回。这种分布式的架构使得ES能够处理大规模数据并提供高性能的检索能力。
写入过程
Es中的节点分为三种类型,主节点、数据节点、协调节点;协调节点在接收到写请求之后会进行如下操作,根据传入的_routing参数(或mapping中设置的_routing, 如果参数和设置中都没有则默认使用_id), 按照公式shard_num = hash(\routing) % num_primary_shards计算出文档要分配的副本分片,然后在将请求路由到主分片(primary shard)进行写操作。
当 primary shard 完成写入后,将写入并发发送给各replica, raplica执行写入操作后返回结果给primary shard, primary shard再将请求返回给协调节点。大致流程如下图:
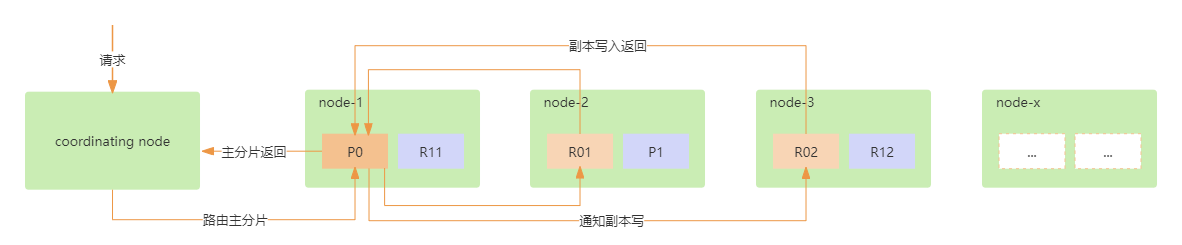
在整个写入过程中,Es中的各部分组件各司其职,主要由协调节点、主分片、副本分片协同参与。在写入过程中还需要注意以下几个概念。
-
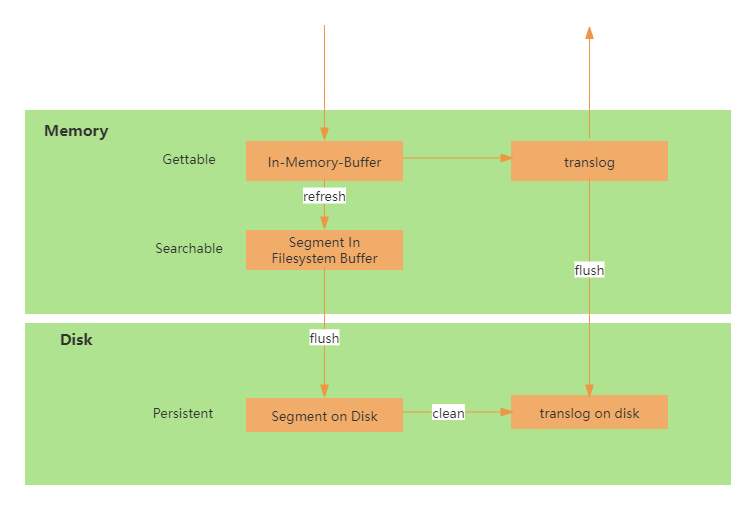
refresh
Elasticsearch提供了一个refresh操作,用来解决Lucene写入非实时性的问题,定时地调用lucene的reopen(新版本为openIfChanged)为内存中新写入的数据生成一个新的segment用于检索。refresh操作的时间间隔由refresh_interval参数控制,默认为1s, 也可以在写入请求中带上refresh表示写入后立即refresh,还可以调用API显式refresh。refresh后数据仍然存储在内存中。 -
translog
为了防止数据在异常情况如服务器宕机的场景下,内存数据丢失,Es引入了translog,类似于MySQL中的redo、undo日志,使得MySQL拥有了Crash-Safe机制。
translog的作用是,当进行写操作时会先将文档写入Lucene,然后写入一份到translog,写入translog是落盘的(如果对可靠性要求不是很高,也可以设置异步落盘,可以提高性能,通过配置index.translog.durability和index.translog.sync_interval控制),这样就可以防止服务器宕机后数据的丢失。由于translog是追加写入,因此性能比较好。为了减少写入失败回滚的复杂度,这里是先写入Lucene再写入translog,原因是写入Lucene可能会失败。translog的写入过程如下图所示:
-
flush
该操作用于将数据写入磁盘,每30分钟或当translog达到一定大小(由index.translog.flush_threshold_size控制,默认512mb), Es会触发一次flush操作。先执行refresh操作将buffer中的数据生成segment,然后调用lucene的commit方法将所有内存中的segment fsync到磁盘,完成lucene中数据的持久化。 -
merge
该操作用于数据碎片的合并。由于refresh默认间隔为1s中,因此会产生大量的小segment,为此Es会运行一个任务检测当前磁盘中的segment,对符合条件的segment进行合并操作,减少lucene中的segment个数,提高查询速度,降低负载。不仅如此,merge过程也是文档删除和更新操作后,旧的doc真正被删除的时候。用户还可以手动调用_forcemerge API来主动触发merge,以减少集群的segment个数和清理已删除或更新的文档。
参考资料
作者:starsray
出处:https://www.cnblogs.com/starsray/p/17800343.html
版权:本作品采用「署」许可协议进行许可。
须知少日拏云志,曾许人间第一流
本文来自博客园,作者:星光Starsray,转载请注明原文链接:https://www.cnblogs.com/starsray/p/17800343.html





【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具