
RDD编程练习
一、filter,map,flatmap练习:
1.读文本文件生成RDD lines
代码:lines = sc.textFile('file:///home/hadoop/word.txt')

2.将一行一行的文本分割成单词 words
代码:words=lines.flatMap(lambda line:line.split())
words.collect()

3.全部转换为小写
代码:#lines.flatMap(lambda line:line.lower().split()).collect()
words=lines.flatMap(lambda line:line.lower().split()).collect()

4.去掉长度小于3的单词

5.去掉停用词
准备停用词文本
代码:
1.准备停用词文本:
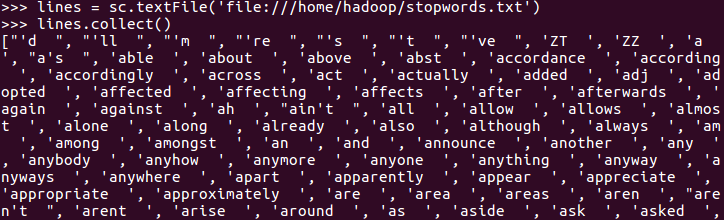
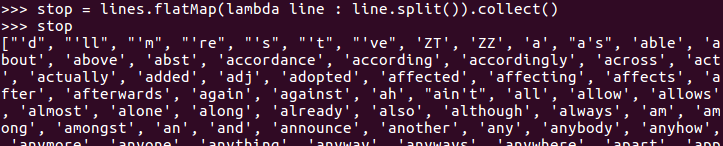
lines = sc.textFile('file:///home/hadoop/stopwords.txt')
stop = lines.flatMap(lambda line : line.split()).collect()
2.去除停用词:
words=lines.flatMap(lambda line:line.lower().split()).filter(lambda word : word not in stopword.txt)
words.collect()

二、groupByKey练习
6.练习一的生成单词键值对
代码:words.map(lambda word : (word,1))

7.对单词进行分组
代码:words.map(lambda word : (word,1)).groupByKey()

8.查看分组结果
代码:
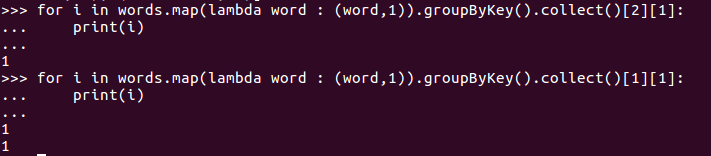
for i in words.map(lambda word : (word,1)).groupByKey().collect()[1][1]:
print (i)
学生科目成绩文件练习:
0.数据文件上传
1.读大学计算机系的成绩数据集生成RDD
代码:
lines = sc.textFile('file:///home/hadoop/chapter4-data01.txt')
lines.take(5)

2.按学生汇总全部科目的成绩
代码:
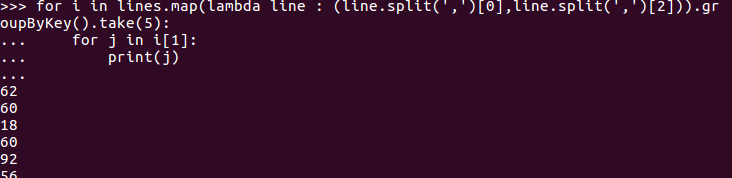
lines.map(lambda line : (line.split(',')[0],line.split(',')[2])).groupByKey()
for i in lines.map(lambda line : (line.split(',')[0],line.split(',')[2])).groupByKey().take(5):
... for j in i[1]:
... print(j)
...

3.按科目汇总学生的成绩
