网站用户行为分析
- 操作过程
2.1 数据准备
A.1sudo mkdir usr/local/bigdatacase
A.2sudo chown -R hadoop:hadoop ./bigdatacase
A.3mkdir usr/local/bigdatacase/dataset
A.4
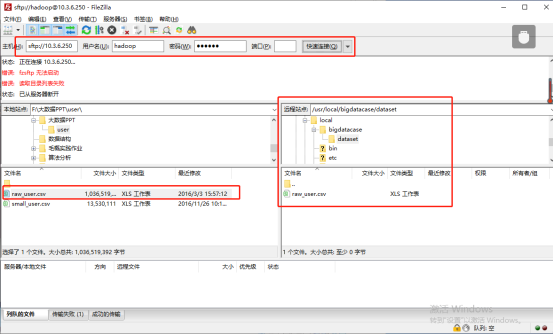
A.5
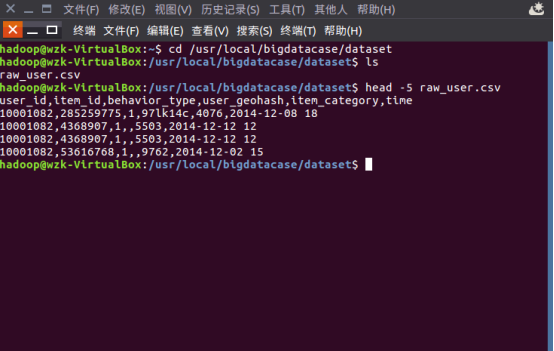
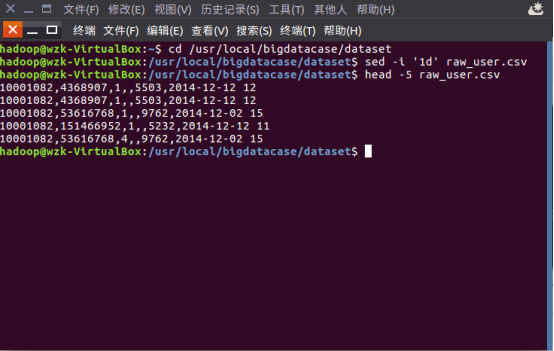
B.1sed -i '1d' raw_user
B.2
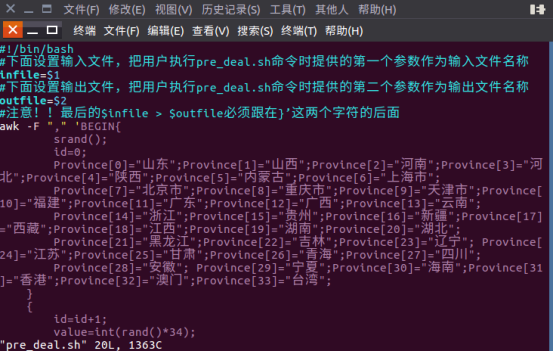
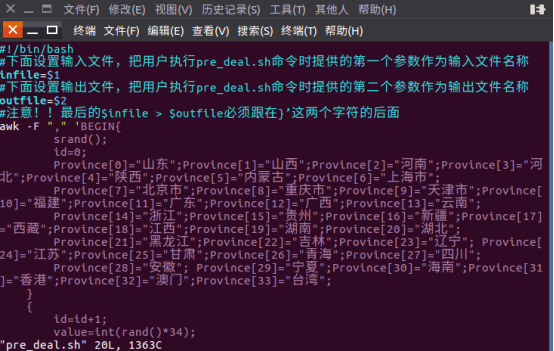
B.3vim pre_deal.sh
B.4
C.1start-all.sh
C.2hdfs dfs -mkdir -p /bigdatacase/dataset
C.3
C.4hdfs dfs -put /usr/local/bigdatacase/dataset/user_table.txt /bigdatacase/dataset
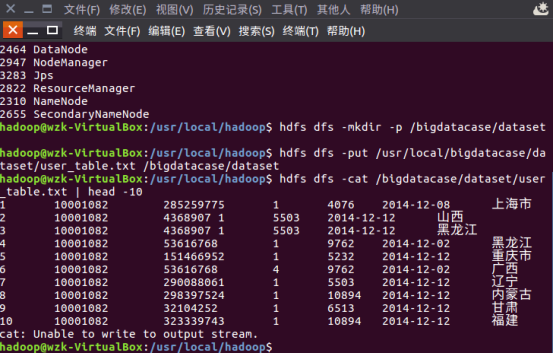
C.5hdfs dfs -cat /bigdatacase/dataset/user_table.txt | head -10
D.1
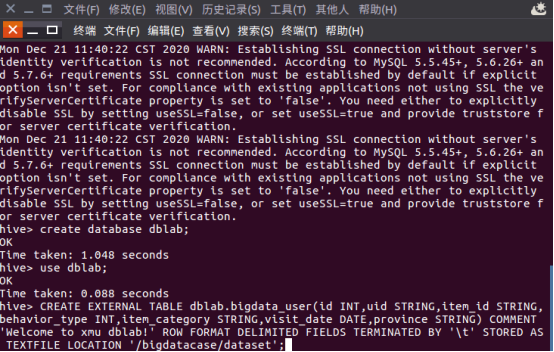
D.2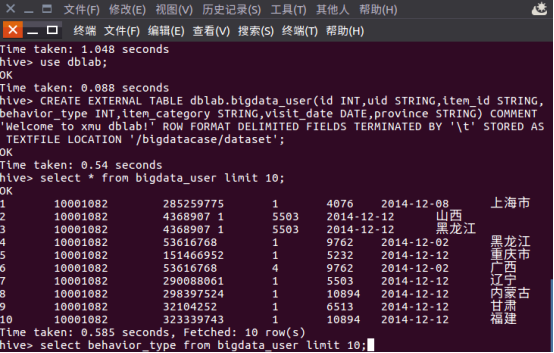
D.3
2.2 Hive数据分析
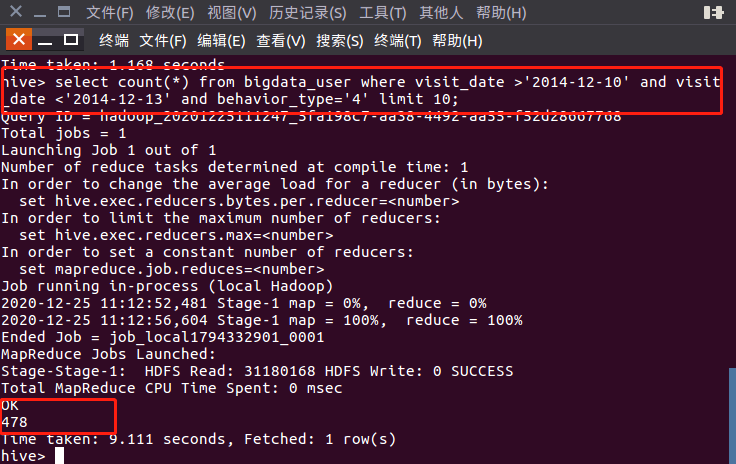
(1)用户行为分析需求:2014-12-11~12号有多少条购买商品的记录
分析步骤
- 语句:select count(*) from bigdata_user where visit_date >'2014-12-10' and visit_date <'2014-12-13' and behavior_type='4' limit 10;
- 结果截图:运行或存为表格后的查询显示
![]()
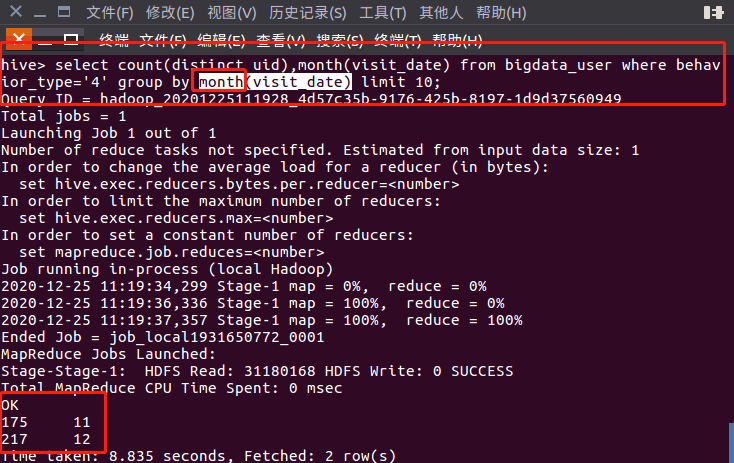
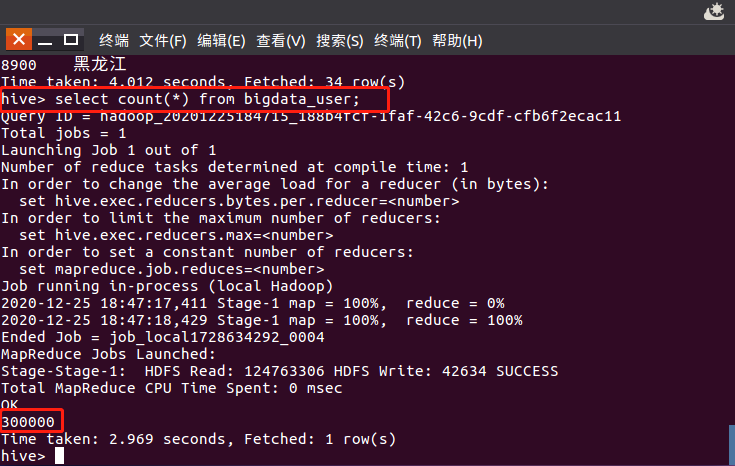
(2)用户行为分析需求:分析每月1-31号购买情况
代码:select count(distinct uid),month(visit_date) from bigdata_user where behavior_type='4' group by month(visit_date) limit 10;
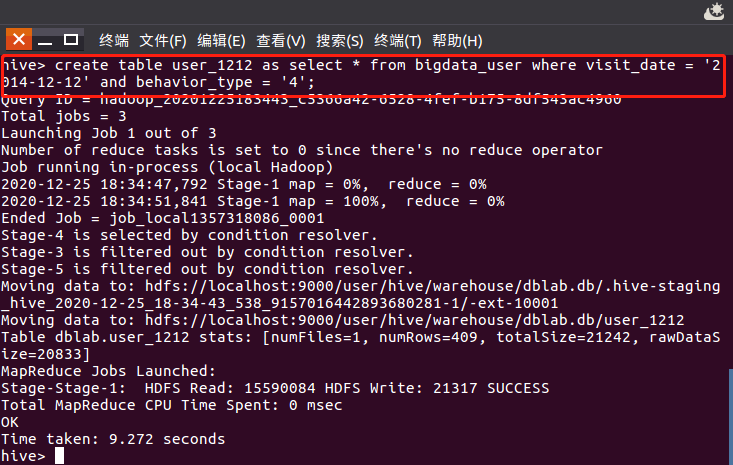
2014-12-12当天购买记录表:
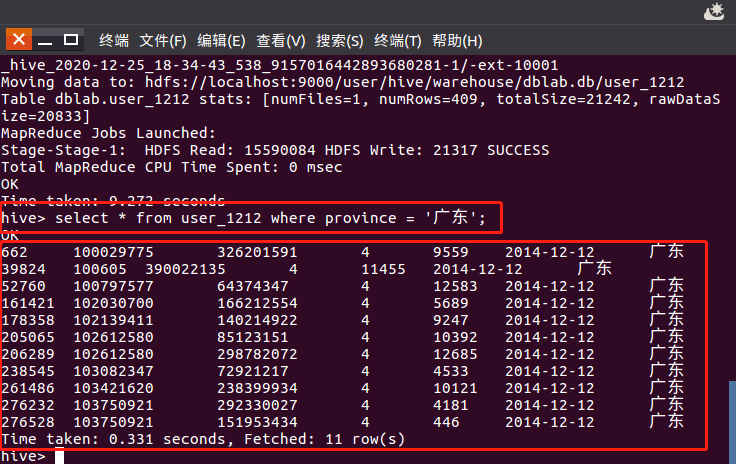
2014-12-12号当天广东购买商品数:
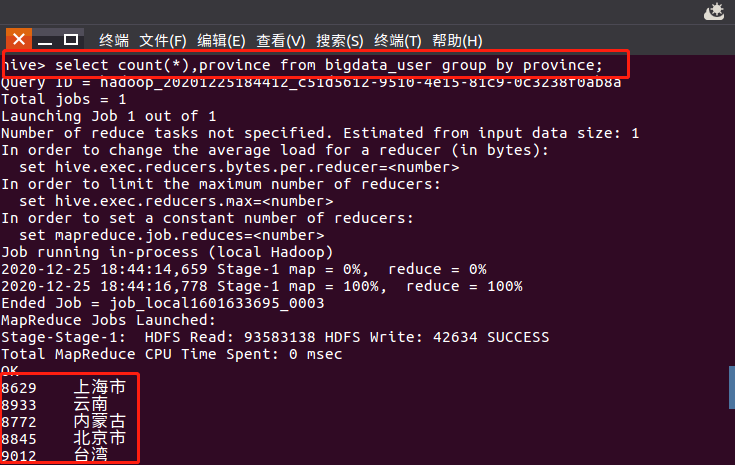
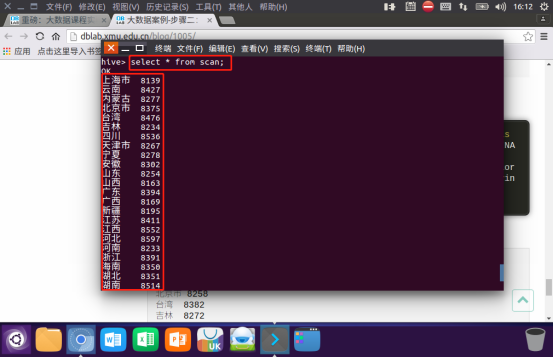
按省份统计购买数量:
2014-12-12号当天的商品购买与浏览比例:
购买数:
浏览数:
购买比例为:购买数/点击数
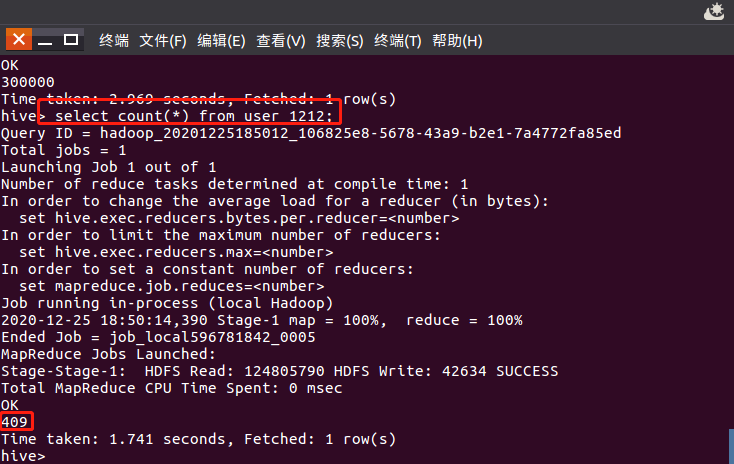
用户10001082在2014-12-12号当天活跃度:该用户点击行为占该天所有点击行为的比例:
用户10001082点击数:
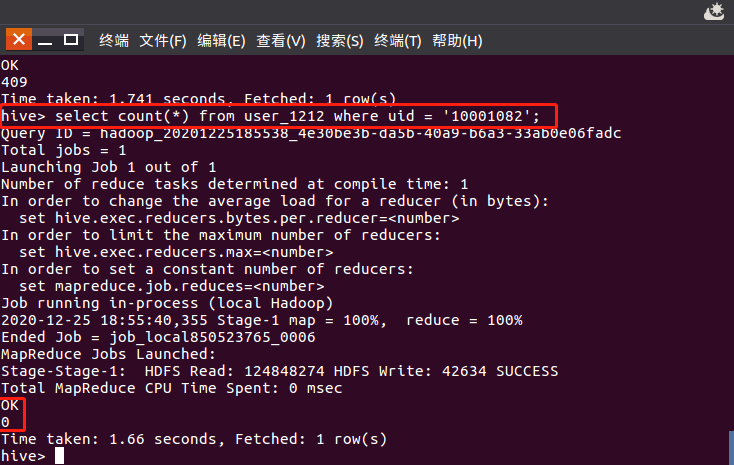
全部用户点击数:
用户10001082点击数/全部用户点击数=该用户点击行为占该天所有点击行为的比例
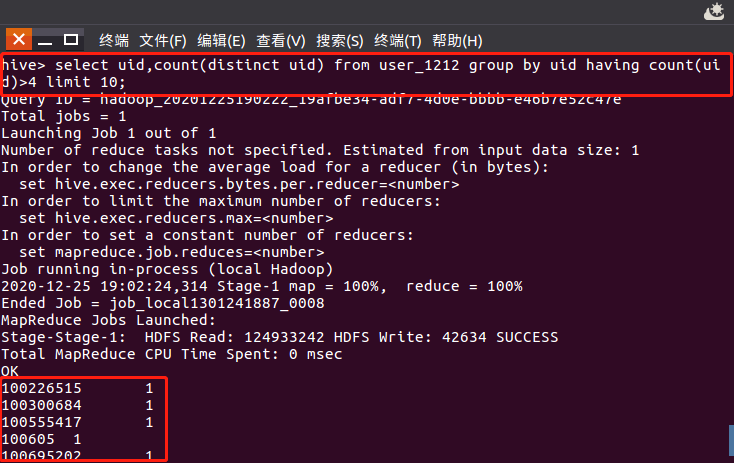
2014-12-12号当天购买4件商品以上的用户:
(3)自定义需求:
简单指令:
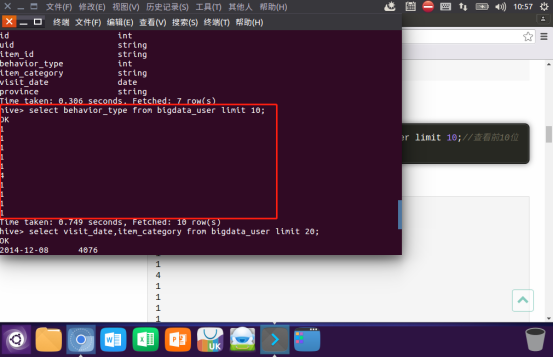
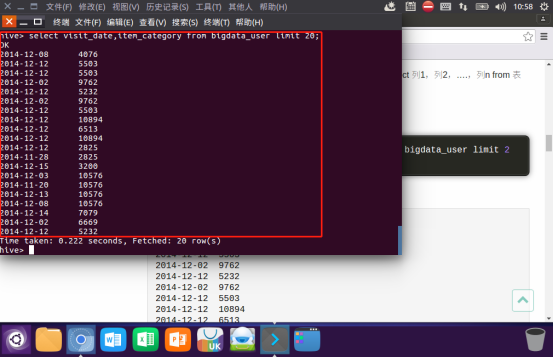
查询前20位用户购买商品时的时间和商品的种类:
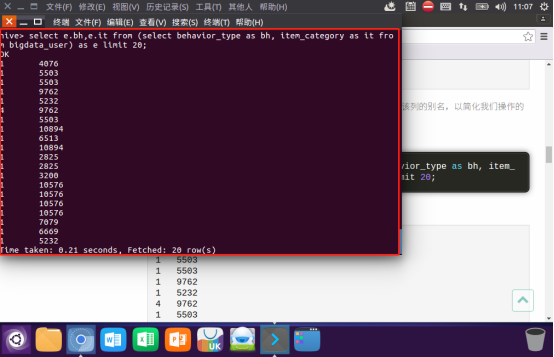
查询利用嵌套语句,设置该列的别名,简化语句:
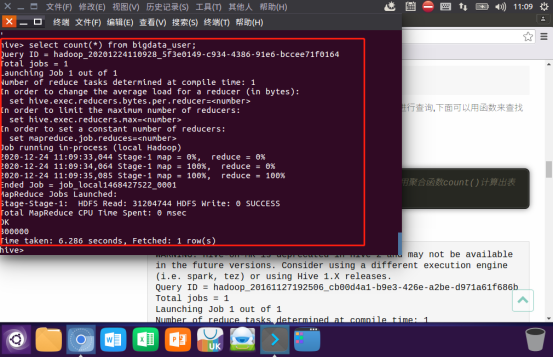
聚合函数count()计算出表内有多少条行数据:
函数内部加上distinct,查出uid不重复的数据有多少条:
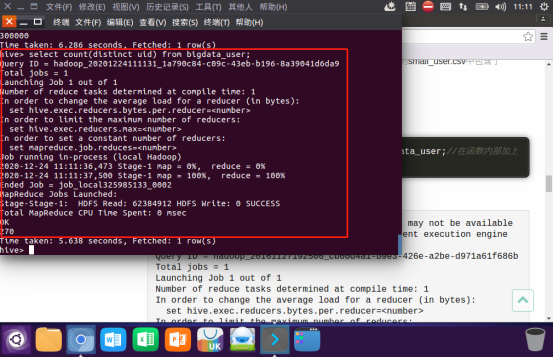
查询不重复的数据有多少条(为了排除客户刷单情况):
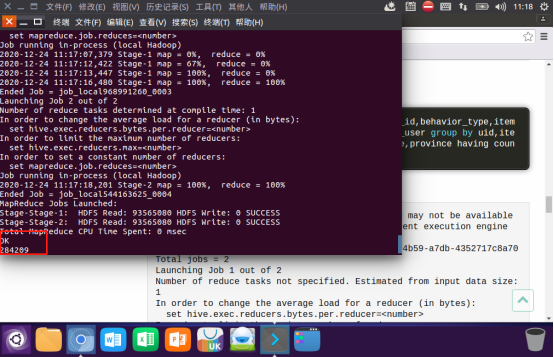
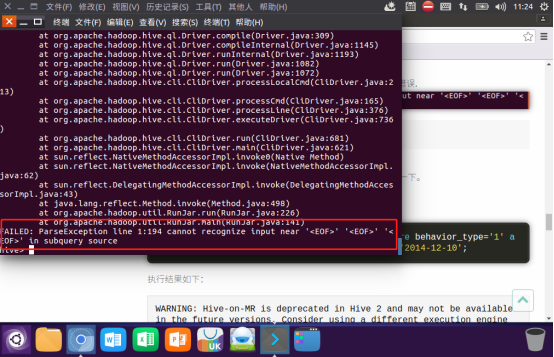
嵌套语句最好取别名,就是上面的a,否则很容易出现如下错误:
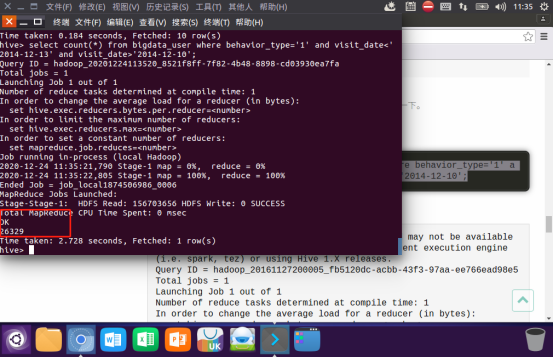
查询2014年12月10日到2014年12月13日有多少人浏览了商品:
以月的第n天为统计单位,依次显示第n天网站卖出去的商品的个数:
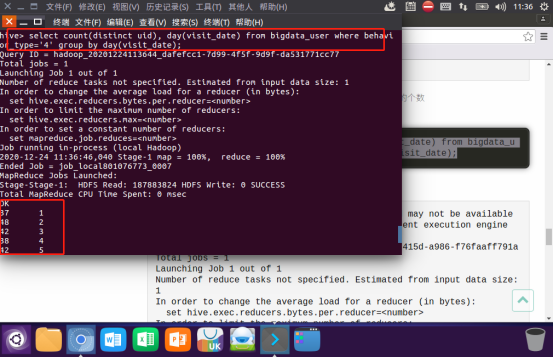
关键字赋予给定值为条件,对其他数据进行分析
取给定时间和给定地点,求当天发出到该地点的货物的数量:
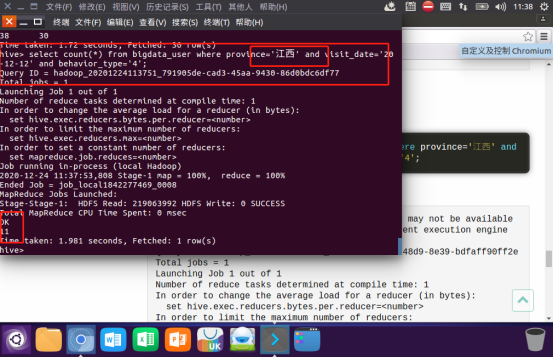
查询一件商品在某天的购买比例或浏览比例:
1.查询有多少用户在2014-12-11购买了商品
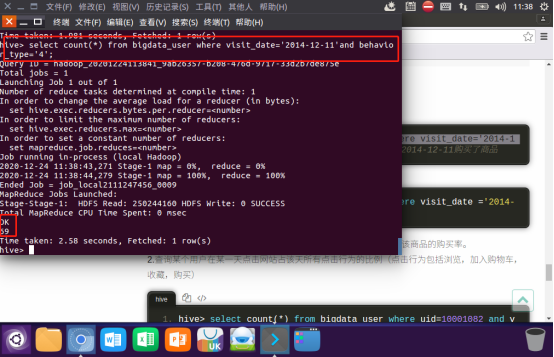
2.查询有多少用户在2014-12-11点击了该店
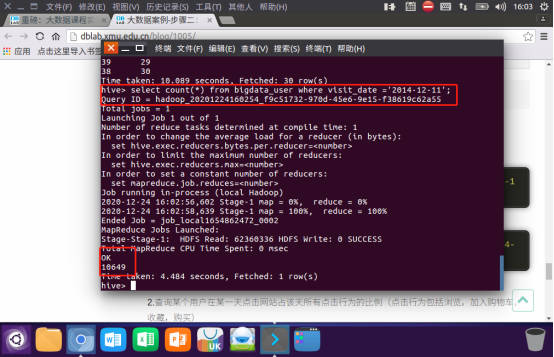
查询某个用户在某一天点击网站占该天所有点击行为的比例(点击行为包括浏览,加入购物车,收藏,购买):
1.查询用户10001082在2014-12-12点击网站的次数
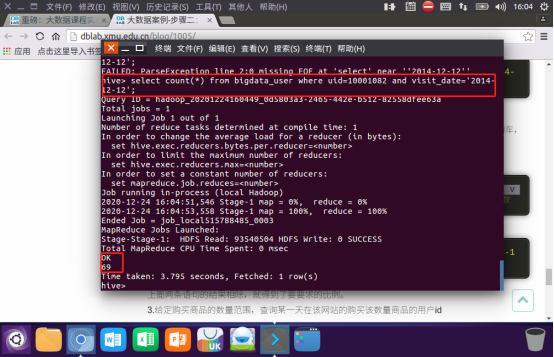
2.查询所有用户在这一天点击该网站的次数
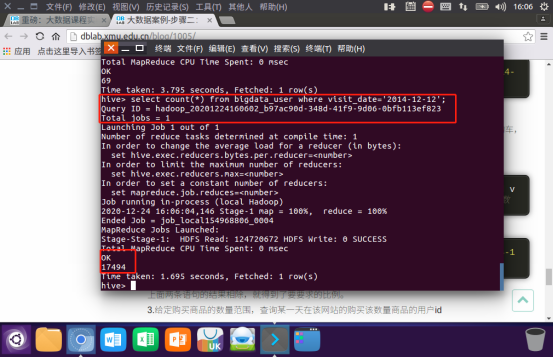
给定购买商品的数量范围,查询某一天在该网站的购买该数量商品的用户id:
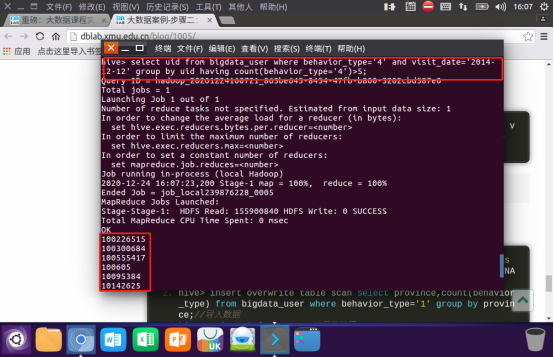
某个地区的用户当天浏览网站的次数:
1.创建新的数据表进行存储
create table scan(province STRING,scan INT) COMMENT 'This is the search of bigdataday' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE;
2.导入数据
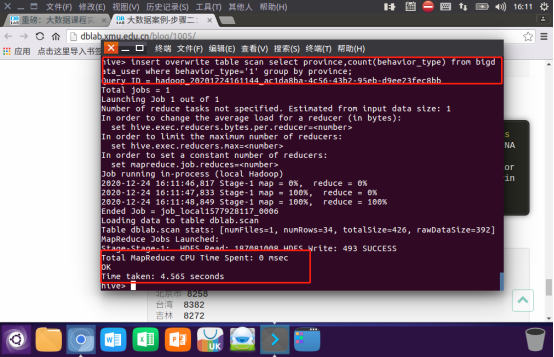
3.显示结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号