银河护胃队-冲刺总结
| 作业所属课程 | https://edu.cnblogs.com/campus/fzu/SE2024/ |
|---|---|
| 作业要求 | https://edu.cnblogs.com/campus/fzu/SE2024/homework/13305 |
| 作业的目标 | 总结这次alpha冲刺 |
| 团队名称 | 银河护胃队 |
| 团队成员学号-名字 | 072208130-曹星才(组长) 052205144-张诗悦 102201120-陈康培 102201342-潘宇晴 102202108-王露洁 102202111-刘哲睿 102202128-林子豪 102202142-黄悦佳 102202149-詹镇壕 102202153-来再提·叶鲁别克 |
一、项目
1.1 项目进展
前端页面和后端接口基本完成,后端已部署到云服务器上,接下来一周进行前后端对接。
1.2 项目亮点
1.2.1 选题对于开源信息的学习
对于学习开源技术:
项目涉及多个技术栈,如人工智能、数据库、API集成、前端开发、后端额集成、原型设计、ui设计等,这些都可以借助开源框架和工具。例如,推荐算法可以使用开源的机器学习库(如TensorFlow、PyTorch),前端开发可以基于Vue.js、React等开源框架进行开发,原型设计与ui美化可以利用墨刀、figma原型设计工具等。
通过项目,团队成员能够在实际场景中学习和应用这些开源工具。
对于利用开源数据库和资源:
食物营养数据库和外卖商品信息数据库依赖于开源或公共的数据源。可以使用一些开源的营养数据库,或者通过开源API获取食品成分和营养信息,这有助于提升项目效率,对现有开源资源的高效利用。
对于信息的获取与拓展:
开源项目通常有丰富的文档和社区支持,帮助开发者快速学习和解决问题。通过项目,团队可以接触到各种开源信息的获取方法,包括GitHub上的项目、社区论坛、开源API文档等。这不仅可以解决当前项目中的技术问题,还能开拓视野,学习到更多的开源实践。
1.2.2 选题创新性
AI个性化饮食计划制定
与AI对话,表明自己的身体状况,然后AI助手会根据所收到的身体数据进行分析,相应的给用户制定个性化饮食计划,是用户更加健康的、合理的饮食。
更加全面的食物介绍
该项目除了商家上传食物数据外,还采用线上与线下方式收集食物的数据,包括食物的名称、食物的价格、食物的营养成分以及分布位置等,用户可自行搜索根据个性化饮食推荐的食物种类分布的餐厅,到店享用。
更精确的食物搜索
利用AI对食物名字或者根据食物的特征对数据库进行检索,找到与输入特征值最相关的食物,相应的推荐食物。
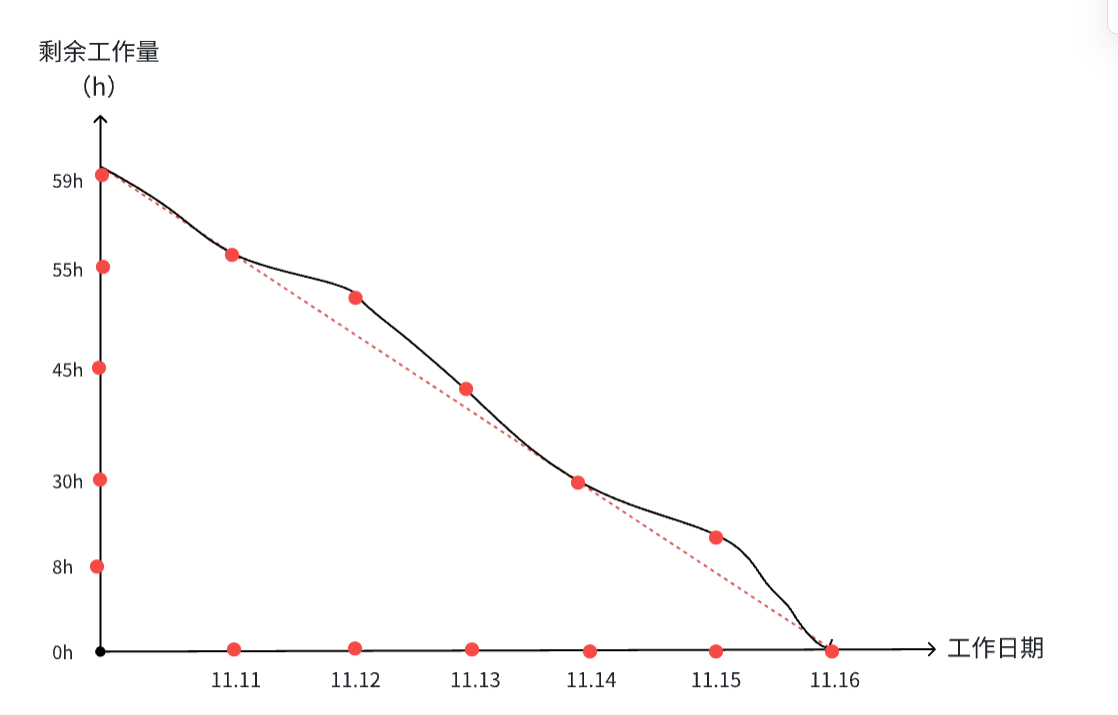
1.3 实际进度曲线与燃尽图
实际进度曲线图:

燃尽图:
二、成员过程体会以及遇到的问题
🍕王露洁
遇到的问题及解决方法
1.问题:我一开始使用HBuilder X开发小程序时,进行编译预览总是需要再打开微信开发者工具,这样子十分不方便。
解决:后来跟组员们交流之后,发现可以直接运行在内置浏览器,这样效率就高多了。
2.问题:在页面设计时,明明有添加页面跳转的逻辑,但是页面总是不能跳转。
解决:多次询问AI后无果,就直接上报给组长解决了。
3.问题:作为前端设计的分组长,在分配任务时会遇到组员时间冲突的问题。
解决:我会尽量为大家考虑,减轻大家烦恼的同时不减工作的质量。
过程体会
很愉快!也很神奇!我目前也加入了很多其他的小组进行一些工作,但是不知道软工有什么魔力能让我把它放在第一位,一天到晚别的事儿不做就净调我的那些界面。虽然一做就好几个小时但是却没有觉得特别累,我想应该是因为上面有温和耐心的好组长,下面有积极配合的好组员,一个团结的队伍真的很能调动工作的积极性。
🍟詹镇壕
遇到的问题及解决方法
问题1:即使一开始规定了api接口开发使用的语言和代码规范,但由于每个人的代码风格的不同,在整合代码时,会遇到各种bug,需要不断去调试。
解决:花费时间去不断的去调试代码,和测试接口。
问题2:在测试接口时,由于没有数据库暂时没有数据,会出现各种关于数据库的报错,包括外键的约束和主键的唯一性等。
解决:手动设置几个测试数据。
问题3:由于没有多少后端经验,在整个过程会不断的碰壁,然后就去查阅资料,不断往复,花费许多时间
解决:熬几天夜就老实了。
过程体会
在这个过程中,虽然不断的去碰壁,去试错,但也因此收获到了许多后端的相关知识。同时,作为后端的小组长,分配工作与和组员的沟通都让我收获许多。此外,熬夜的时候喝点茶确实比较精神(-_-)
🍔陈康培
在前端部分模块编写中,针对图片无法显示的问题检查了图片路径,确保使用了正确的相对或绝对路径。
针对前后端数据同步问题,在对照整理了接口返回值文档,确保前端传递的数据格式与后端要求一致。
项目测试将使用 Apifox 根据功能需求设计测试用例,重点验证前端各项功能的实现及前后端交互,确保页面的可靠性与性能。通过全面的测试,将确保项目在上线前的质量可控。
在与团队成员的分工合作中,我学会了如何沟通与协调,携手共进。与团队一起制定进度计划也提高了自我管理和工作效率。
🌭林子豪
在开发过程中,我遇到了以下问题,并找到了相应的解决方法:
- 文件路径错误导致页面无法加载
问题描述:
在开发过程中,我遇到了 pages/benzhoushipipu/benzhoushipipu not found 的错误,提示 HBuilderX 无法找到 benzhoushipipu.vue 文件。
类似的问题还出现在其他页面,例如 pages/test/test/test not found。
解决方法:
检查文件路径:确认 benzhoushipipu.vue 文件是否存在于 pages/benzhoushipipu/ 目录下。
调整 pages.json 配置:如果文件不存在,删除 pages.json 中对该页面的引用。
确保 pages.json 中所有页面的路径和文件名与实际文件一致。
清理缓存:有时候,HBuilderX 的缓存会导致文件识别问题。尝试清理缓存并重启 HBuilderX。
重启开发服务器:重启 HBuilderX 或 Vite 的开发服务器,确保所有文件路径被重新扫描。 - Vite 连接频繁断开和重连
问题描述:
在开发过程中,Vite 的连接日志频繁出现 [vite] connecting... 和 [vite] connected.,这表明开发服务器与客户端的连接不稳定。
解决方法:
检查网络连接:确保网络连接稳定,避免因为网络问题导致 Vite 频繁断开和重连。
避免频繁保存文件:在开发过程中,避免频繁保存文件,尤其是在进行大规模修改时。可以批量修改后统一保存,减少 HMR 的触发频率。
配置 Vite:检查 vite.config.js 文件,确保开发服务器配置正确。例如,确保 host 和 port 设置正确,并且没有其他服务占用相同的端口。
重启开发服务器:如果问题持续存在,尝试重启 HBuilderX 或 Vite 的开发服务器。 - 团队协作与沟通
体会:
团队协作是项目成功的关键。在开发过程中,我们定期举行会议,分享各自的工作进展和遇到的问题。通过有效的沟通,我们能够及时解决问题,避免了重复劳动和资源浪费。
使用项目管理工具(如 Jira、Trello)帮助我们跟踪任务进度,确保每个成员都清楚自己的职责和项目的整体进展。
收获:
学会了如何更有效地与团队成员沟通,明确表达自己的想法和需求。
理解了团队协作的重要性,学会了如何在团队中发挥自己的优势,同时支持其他成员的工作。
🍿黄悦佳
遇到的问题
1.mysql数据库搭建完成后,因为设置的密码过于简单,导致其被入侵,全部的数据信息被删除并被攻击者留下交易地址索要比特币来恢复数据信息。
解决:第一时间重新配置数据库,将本地备份测试数据重新导入,并修改更为复杂的密码,确保数据库安全。
2.数据库锁死。短时间时间内进行大量数据库操作,导致数据库资源被占用,两个事物相互等待,出现死锁。
解决:先是按照网络上的教程采取回滚方式处理死锁问题,无法解决。后直接查询等待运行的进程并kill,解决死锁问题。并反思原因,避免后端小组成员同时对同一段数据进行操作,减少死锁发送的可能性。
3.Api接口编写过程中出现各种bug,及整合不同组员编写代码测试遇到问题。
解决:添加详细的报错反馈,便于检测问题出现的位置。同时同一编写代码的风格,方便不同组员代码阅读和整合。
过程体会
遇到不懂的技术问题,和同伴一起探讨解决,大大提高的工作效率和对代码编写的热情动力。
虽然熬夜赶进度和源源不断的修改bug让人身心俱疲,怀疑人生,但是当程序完成并且成功运行,还是很有成就感的。
🍳刘哲睿
遇到的问题和解决办法
问题 1:API 访问需要有效的 Access Token,而 Token 的有效期较短如果在有效期内未刷新,会导致接口调用失败
解决办法:开发一个单独的 get_access_token 方法,在每次程序启动时获取新的 Token
问题 2:难以实现上下文对话延续性,请求失败或响应缓慢
解决办法:限制上下文长度,截取最近的对话历史进行传递,并在每次请求前裁剪多余的内容
问题 3:在API接口开发过程中,经常遇到Bug以及代码整合测试问题。
解决办法:为关键代码加异常捕获和日志记录,精确定位问题。
过程体会
在开发 AI 的 API接口的过程中,我通过沟通和适应统一的代码规范,提高了协作效率和全局视角。为赶进度常常熬夜,与Bug的“拉锯战”让我磨炼了耐心和抗压能力,尽管疲惫,但每次解决问题后的成就感都激励我坚持下去。在这一过程中,我对API设计、错误处理和代码优化有了更深入的理解,调试能力也得到显著提升。尽管充满挑战,但每个突破都让我感受到成长和充实,也让我更加期待未来的表现。
🍞来再提
遇到的问题
遇到的问题1: 页面跳转不成功,点击事件或其他交互事件没有实现预期的效果。
解决方法: 需要检查 pages.json 中的路径配置是否与实际文件路径一致,确保所有路径都是正确的。发现几个页面的路径拼写有误。同时还检查了绑定的事件里的methods方法,发现事件处理的定义有错误。修改了这两点就能点击事件成功跳转页面了。
遇到的问题2: 元素总是不按照预期显示或布局不符合设计。
解决方法:在style那里进行样式调整,需要一直调整宽度、高度、边距、对齐方式等属性。使用内置浏览器的实时预览功能可以帮助快速定位和调整。
过程体会
在这次任务中,我深刻体会到了时间管理的重要性。我学会了如何优先安排任务,合理分配时间,以确保项目的顺利进行。此外,我还掌握了许多新技能,包括使用新的框架和工具,这些都是这次任务中宝贵的经验。我更加熟练地运用了开发工具,并意识到细节对于项目成功的重要性。同时,这次任务也极大地考验了我的耐心和毅力,尤其是在遇到问题时,我学会了保持冷静,耐心地寻找解决方案。
更重要的是,我学会了如何更有效地与小组成员沟通和协作。在项目进展中,我们不可避免地遇到挑战,但通过沟通交流我们总能找到最佳的解决方案。这个过程不仅提升了我的沟通技巧,也加深了我对团队合作价值的理解。
🌮潘宇晴
问题1:对页面布局进行修改但预览的结果总是不尽人意。
解决方案:确保布局是响应性,使用浏览器的开发者工具进行调试,检查元素的盒模型、定位和布局属性,确保布局在不同屏幕尺寸下都能正常工作。如果布局问题是嵌套导致的,要重构CSS代码。
问题2:对于一些页面的构造和相互之间的交互总是不知道怎么处理更好
解决方案:采用组件化开发的思想,将页面分解为独立的、可复用的组件。遵循单向数据流原则,确保数据从父组件流向子组件,并通过事件向上传递。避免复杂的数据绑定和难以追踪的数据流。继续学习前端有关知识进行优化。
过程体会:
在这次合作中,我深刻体会到了团队合作的力量和重要性。小组长明确分工和合理安排时间的方式,确保了项目的高效推进。团队成员间的互帮互助和努力让我感受到了集体的温暖。我的技术并没有很好,总是遇到解决不了的问题,我就网上搜索解决方案,或者求助自己擅长前端的朋友,这个过程虽然很困难,但是解决问题并且做出成果后还是觉得很值得。
🍗张诗悦
遇到的问题
问题1:在将小助手的回答导入数据库过程中,遇到数据格式不兼容的情况。
解决方案:首先确认导入的数据格式与数据库结构匹配,使用适当的序列化工具(如JSON或XML)将数据转换为合适格式。通过增加异常捕获机制来处理导入过程中可能出现的错误。对数据库的表结构进行优化,确保能够高效存储和查询大数据量。
问题2:在开发用户健康、身体维度信息和饮食习惯的API时,接口返回的数据量过大导致性能问题。
解决方案:针对接口返回数据量过大的问题,优化查询逻辑和数据返回格式。可以通过分页、延迟加载等技术减少一次性返回的数据量,使用缓存机制来提高接口响应速度。对数据库查询进行索引优化,避免全表扫描。
过程体会
在这个任务的开发过程中,我深刻体会到 API 性能优化和数据库设计的重要性。虽然在实现功能时遇到了一些挑战,但通过查阅相关资料并与团队成员讨论,我逐步掌握了如何提高接口的响应效率。遇到技术难题时,能够依赖团队成员的帮助和自己动手实践的态度,问题最终都能迎刃而解。通过这一过程,我不仅提升了自己的技术能力,还更加深刻理解了协作的重要性,尤其是在项目中需要关注性能优化的细节。
三、各成员在整个阶段的工作量比例
比例计算公式为:比例=六天总贡献度/6
| 成员 | 比例 |
|---|---|
| 王露洁 | 78/6=13 |
| 詹镇壕 | 73.5/6=12.25 |
| 黄悦佳 | 71.5/6≈11.9 |
| 刘哲睿 | 68/6≈=11.3 |
| 张诗悦 | 65.5/6≈10.9 |
| 来再提 | 62.75/6≈10.46 |
| 林子豪 | 58.5/6≈9.75 |
| 陈康培 | 60/6=10 |
| 潘宇晴 | 61.25/6≈10.2 |
四、链接
| 链接名称 | 链接 |
|---|---|
| 冲刺计划链接 | https://www.cnblogs.com/starryship/p/18548506 |
| 冲刺集合链接 | https://www.cnblogs.com/starryship/p/18553358 |
| github仓库链接 | healthyFZU/alpha |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号