2024数据采集与融合技术实践-作业3
一、中国气象网单线程与多线程爬取图片
(一)步骤
爬取网站:https://p.weather.com.cn/tqxc/index.shtml
1.1 单线程方式爬取
step1:设置为单线程方式爬取,settings.py中注设置最大并发请求数量CONCURRENT_REQUESTS=1

step2:找到图片对应的网站,发送请求
# 方法:生成初始请求并发送到目标网址
def start_requests(self):
# 循环遍历目标网站的前 5 页
for page in range(1, 6):
# 第一页的 URL 结构不同,需要单独处理
if page == 1:
url = "https://p.weather.com.cn/tqxc/index.shtml"
else:
url = f"https://p.weather.com.cn/tqxc/index_{page}.shtml"
# 使用 scrapy.Request 发送请求,获取页面内容
# 该请求的响应将由 'parse' 方法处理
yield scrapy.Request(url=url, callback=self.parse)
step3:对请求得到的网页进行解析,使用img_urls = selector.xpath('//img/@src')获取该页的所有图片url,使用yield scrapy.Request(url=img_src, callback=self.download)逐个url调用download图片下载函数
# 方法:解析天气页面的 HTML 响应
def parse(self, response, *args, **kwargs):
data = response.body.decode('utf-8') # 将响应的字节数据解码为 UTF-8 字符串
# 使用 Scrapy 的 Selector 类来解析解码后的 HTML 数据
selector = scrapy.Selector(text=data)
# 提取页面中的所有图像 URL
img_urls = selector.xpath('//img/@src')
# 遍历所有提取的图像 URL
for img_url in img_urls:
img_src = img_url.extract() # 获取每个图像 URL 的字符串形式
print(img_src) # 打印图像 URL(用于调试)
if img_src: # 检查图像 URL 是否有效
# 发送请求下载图像,下载完成后调用 'download' 方法
yield scrapy.Request(url=img_src, callback=self.download)
step4:处理图片的下载请求,创建WeatherItem实例,存储图像二进制数据,将获取到的二进制数据传给item
# 方法:处理图像下载请求
def download(self, response):
item = WeatherItem() # 创建一个 WeatherItem 实例,用于存储图像二进制数据
# 从响应中提取图像的二进制内容
img_binary = response.body
# 将图像的二进制数据存入 item
item["img_binary"] = img_binary
# 使用 yield 传递 item,将数据传递给数据管道或输出
yield item
step5:WeatherItem这只用接收图片的二进制数据,传给pipelines
class WeatherItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
img_binary = scrapy.Field()
step6:二进制数据传到pipelines,对数据进行保存,保存为JPG格式的图片
# 定义一个处理爬取数据的管道类
class WeatherPipeline:
count = 0 # 定义一个类变量,用于记录下载的图像数量
# 处理每个传入的 item 对象
def process_item(self, item, spider):
# 每当处理一个 item 时,将计数器加 1
WeatherPipeline.count += 1
# 构造保存图像的路径
# 每张图像使用递增的数字作为文件名,并保存在 "imgs" 文件夹中
downloadPath = f"imgs/{WeatherPipeline.count}.jpg"
# 以二进制写模式打开文件
fobj = open(downloadPath, "wb")
# 将图像的二进制数据写入文件
fobj.write(item["img_binary"])
# 关闭文件对象,确保数据被正确保存
fobj.close()
# 打印下载完成的信息,包括图像的字节数
print("下载完毕:", len(item["img_binary"]), "字节")
# 返回 item 对象,以便在 Scrapy 框架中继续处理
return item
step7:scrapy crawl wea -s LOG_ENABLED=False运行项目
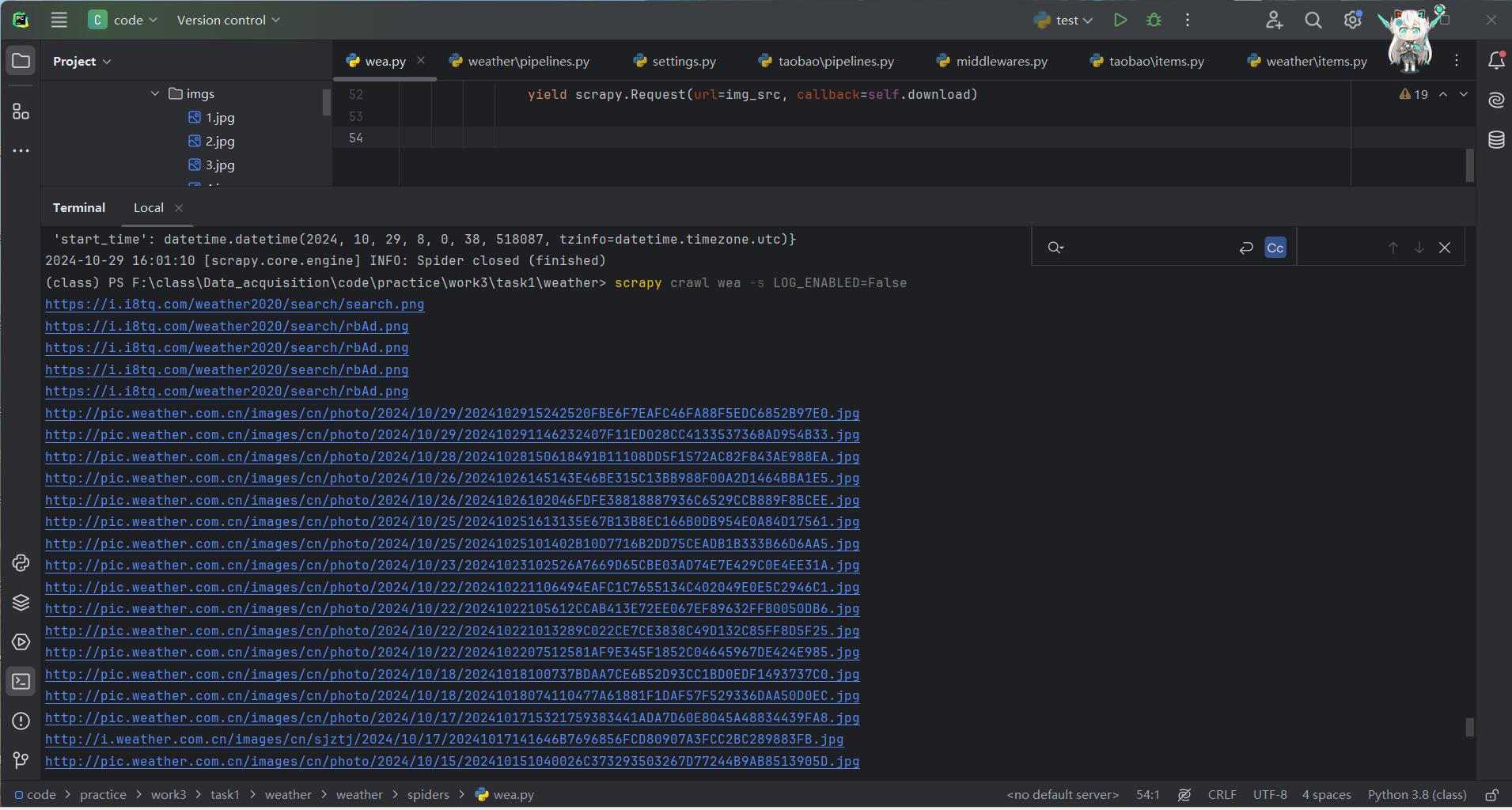
step8:得到单线程爬取的结果
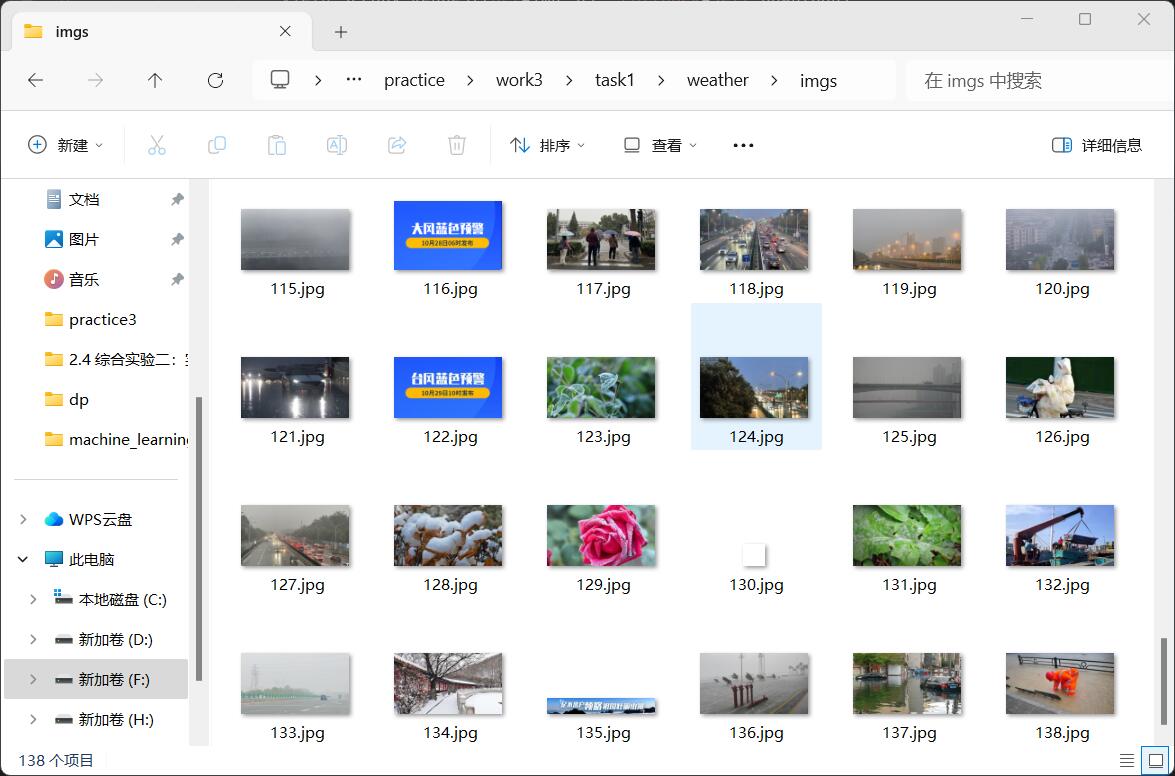
1.2 多线程方式爬取
step9:设置为多线程方式爬取,settings.py中设置最大并发请求数量CONCURRENT_REQUESTS=32(其它数字也行)

step10:scrapy crawl wea -s LOG_ENABLED=False运行项目
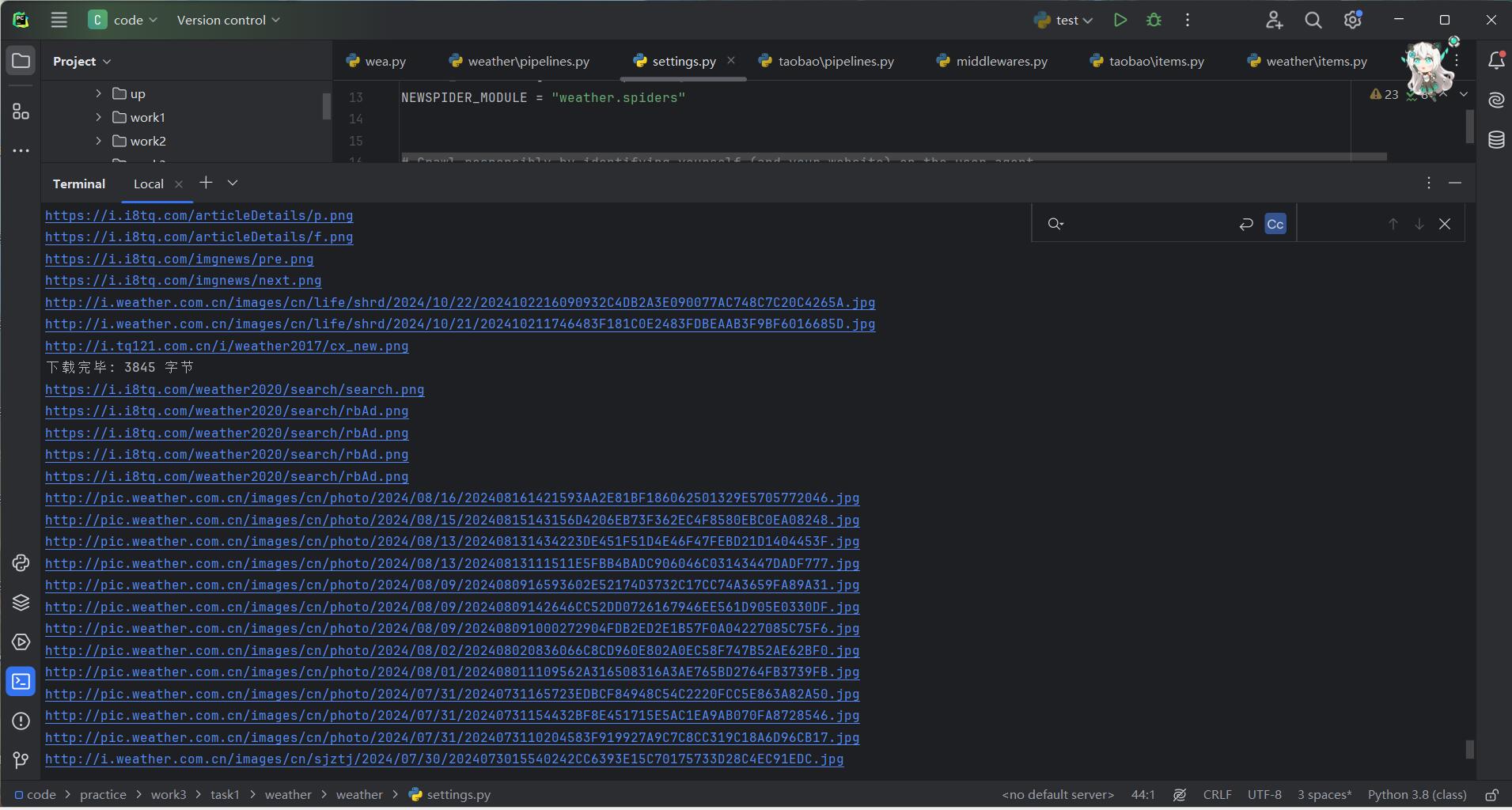
step11:得到多线程爬取的结果
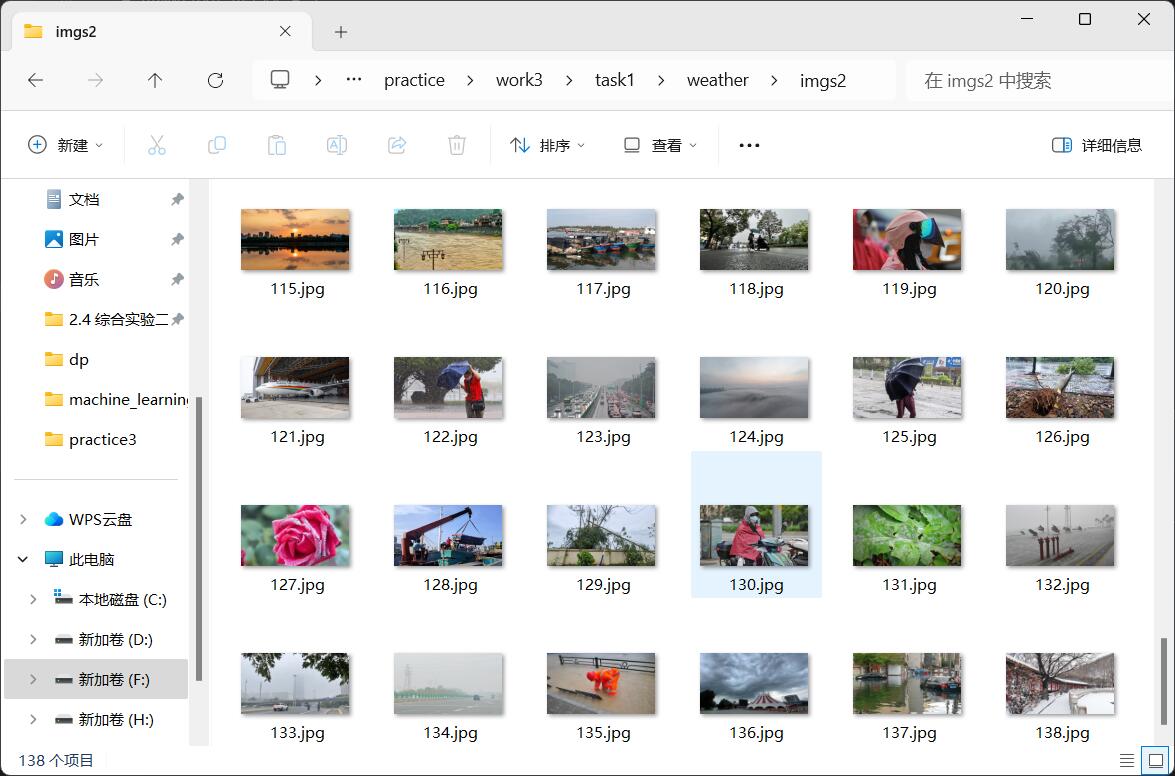
(二)心得
在这次使用 Scrapy 进行中国气象网单线程与多线程爬取图片爬取的实验中,通过单线程和多线程两种方式分别爬取了天气网站的图片,积累了很多经验和心得。
首先,在单线程方式下,设置了 CONCURRENT_REQUESTS=1,保证每次只发送一个请求,逐一处理每个页面的图像。这种方式的优势在于操作简单、易于调试,可以清晰地控制每一步的执行过程。通过 scrapy.Request 发送请求并解析网页,获取图片 URL 后,再逐个请求下载图片。在下载过程中,我利用 Scrapy 的 WeatherItem 存储图片的二进制数据,并通过管道保存为 JPG 格式的图片。这种方法确保了图片能够按顺序保存,便于后期的管理。
然而,单线程的效率较低,特别是当网页图片较多时,下载速度会变得较慢。为了解决这个问题,我尝试了多线程方式。在 settings.py 中将 CONCURRENT_REQUESTS 设置为 32,这样 Scrapy 就能同时处理多个请求,大大提高了抓取和下载的效率。多线程方式虽然能加速爬取过程,但也增加了资源占用,可能会导致服务器负载过高,需要合理设置并发数。
总结来说,单线程适合小规模爬取或需要严格控制爬取速度的场景,而多线程则适合大规模爬取,可以显著提高效率。通过这次实验,我不仅加深了对 Scrapy 框架的理解,也对如何根据爬取任务的需求选择合适的并发策略有了更清晰的认识。
二、股票相关信息爬取
(一)步骤
step1:找到对应网站的url(https://quote.eastmoney.com/center/gridlist.html#hs_a_board),发送请求
# 定义初始请求的方法
def start_requests(self):
# 遍历 start_urls 列表中的每个 URL
for url in self.start_urls:
# 生成 Scrapy 请求,并指定回调函数 parse 处理响应
yield scrapy.Request(url=url, callback=self.parse)
step2:直接解析网页可以看到,输出的data没有我们想要的信息,说明这个网站是js动态渲染的,这个时候就需要加入selenium
step3:在middlewares.py中设置中间件,在StockDownloaderMiddleware中添加我们的配置
为什么选择下载器中间件
- 处理动态内容:Selenium 是一个浏览器自动化工具,适合用来加载和处理由 JavaScript 渲染的动态网页内容。通过在下载器中间件中使用 Selenium,你可以在请求发送到目标网站之前或之后加载页面并提取数据,然后再将处理后的响应交给 Scrapy 引擎或 Spider。
- 灵活性:将 Selenium 集成到下载器中间件中,可以灵活地控制哪些请求需要用 Selenium 处理,比如对一些特定的动态网页,其他的普通网页则仍然用 Scrapy 的默认下载器来处理。
class StockDownloaderMiddleware:
# Scrapy 中的下载中间件类,用于自定义处理请求和响应
def __init__(self):
# 初始化方法,配置并启动一个无头(headless)Chrome 浏览器
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless') # 运行无头模式,不打开浏览器窗口
chrome_options.add_argument('--disable-gpu') # 禁用 GPU(适用于某些无头模式的情况)
self.driver = webdriver.Chrome(options=chrome_options) # 创建一个 Chrome 浏览器实例
@classmethod
def from_crawler(cls, crawler):
# 用于创建中间件实例,并连接 spider_opened 信号
s = cls() # 创建中间件实例
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) # 连接爬虫打开时的信号
return s # 返回中间件实例
def process_request(self, request, spider):
# 处理每个请求的方法
self.driver.implicitly_wait(10) # 设置隐式等待时间为 10 秒
self.driver.get(request.url) # 使用 Selenium 加载网页
body = self.driver.page_source # 获取网页加载后的 HTML 源代码
# 创建并返回一个 HtmlResponse 对象,以提供给 Scrapy 进行后续解析
return HtmlResponse(
url=request.url,
body=body,
encoding='utf-8',
request=request
)
def process_response(self, request, response, spider):
# 处理响应的方法,返回处理后的响应对象
return response # 返回原始响应,未进行任何修改
def process_exception(self, request, exception, spider):
# 处理请求或下载过程中的异常
pass # 未处理异常,继续异常链的处理
def spider_opened(self, spider):
# 当爬虫被打开时调用的方法
spider.logger.info("Spider opened: %s" % spider.name) # 记录日志,指示爬虫已打开
def spider_closed(self, spider):
# 当爬虫关闭时调用的方法
self.driver.quit() # 关闭浏览器以释放资源
spider.logger.info("Browser closed for spider: %s" % spider.name) # 记录日志,指示浏览器已关闭
settings.py中配置:

step4:然后我们就可以顺利的获取到网页的动态数据了,观察html结构
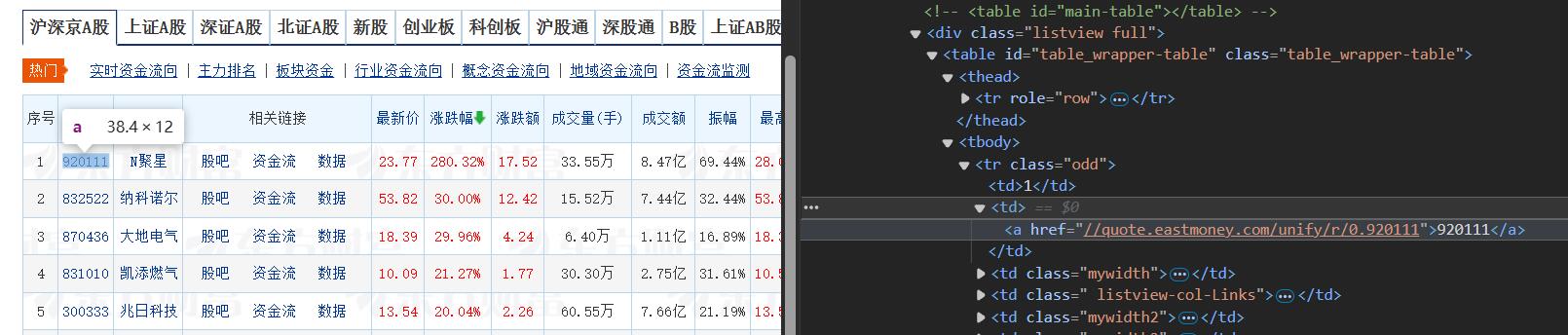
step5:在parse中对数据进行解析
def parse(self, response):
# 将响应的字节数据解码为 UTF-8 字符串
data = response.body.decode('utf-8')
# 使用 Scrapy 的 Selector 类解析 HTML 数据
selector = scrapy.Selector(text=data)
# 使用 XPath 定位包含股票数据的表格
body = selector.xpath("//table[@id='table_wrapper-table']")
# 提取表格中的所有行(<tr> 元素),忽略第一个没用的
trs = body.xpath("//tr")[1:]
# 遍历每个表格行,提取所需数据
for tr in trs:
# 创建一个 StockItem 实例,用于存储提取的数据
item = StockItem()
# 提取每一列的数据,并使用 XPath 获取相应的文本内容
xuHao = tr.xpath("./td[1]/text()").get() # 序号
guPiaoDaiMa = tr.xpath("./td[2]//text()").get() # 股票代码
guPiaoNingCheng = tr.xpath("./td[3]//text()").get() # 股票名称
zuiXingBaoJia = tr.xpath("./td[5]//text()").get() # 最新报价
zhangDieFu = tr.xpath("./td[6]//text()").get() # 涨跌幅
zhangDieE = tr.xpath("./td[7]//text()").get() # 涨跌额
chengJiaoLiang = tr.xpath("./td[8]//text()").get() # 成交量
zhenFu = tr.xpath("./td[10]//text()").get() # 振幅
zuiGao = tr.xpath("./td[11]//text()").get() # 最高价
zuiDi = tr.xpath("./td[12]//text()").get() # 最低价
jinKai = tr.xpath("./td[13]//text()").get() # 今开价
zuoShou = tr.xpath("./td[14]//text()").get() # 昨收价
# 将提取的数据存入 item 对象的相应字段
item['xuHao'] = xuHao
item['guPiaoDaiMa'] = guPiaoDaiMa
item['guPiaoNingCheng'] = guPiaoNingCheng
item['zuiXingBaoJia'] = zuiXingBaoJia
item['zhangDieFu'] = zhangDieFu
item['zhangDieE'] = zhangDieE
item['chengJiaoLiang'] = chengJiaoLiang
item['zhenFu'] = zhenFu
item['zuiGao'] = zuiGao
item['zuiDi'] = zuiDi
item['jinKai'] = jinKai
item['zuoShou'] = zuoShou
# 使用 yield 语句将 item 传递到管道进行进一步处理
yield item
step6:定义StockItem类
class StockItem(scrapy.Item):
# Scrapy 的 Item 类用于定义数据结构,所有要提取的字段都在这里定义
xuHao = scrapy.Field() # 序号,表示股票在页面中的排列顺序
guPiaoDaiMa = scrapy.Field() # 股票代码,用于唯一标识每只股票
guPiaoNingCheng = scrapy.Field() # 股票名称,显示股票的名称
zuiXingBaoJia = scrapy.Field() # 最新报价,表示股票的当前价格
zhangDieFu = scrapy.Field() # 涨跌幅,显示股票价格变化的百分比
zhangDieE = scrapy.Field() # 涨跌额,表示股票价格上涨或下跌的金额
chengJiaoLiang = scrapy.Field() # 成交量,表示该股票在当前时段的交易量
zhenFu = scrapy.Field() # 振幅,表示股票价格波动的幅度
zuiGao = scrapy.Field() # 最高价,表示该股票在当前时段的最高交易价格
zuiDi = scrapy.Field() # 最低价,表示该股票在当前时段的最低交易价格
jinKai = scrapy.Field() # 今开,表示当天股票的开盘价
zuoShou = scrapy.Field() # 昨收,表示前一天股票的收盘价
step7:pipeline中,将数据存入mysql中
import mysql.connector # 导入 MySQL 连接器,用于连接和操作数据库
from itemadapter import ItemAdapter # 导入 Scrapy 的 ItemAdapter 类,方便操作爬取的 item 数据
class StockPipeline:
count = 0 # 计数器,用于跟踪数据处理的次数,确保只在第一次处理时创建数据库表
def open_spider(self, spider):
"""
在爬虫启动时自动执行,负责连接数据库和创建表。
- 连接 MySQL 数据库
- 检查是否是第一次运行爬虫,如果是,则创建数据库表
"""
try:
# 连接到 MySQL 数据库
self.con = mysql.connector.connect(
host="localhost", # MySQL 数据库的主机地址
user="root", # MySQL 数据库的用户名
password="123456", # MySQL 数据库的密码
database="DataAcquisition" # 使用的数据库名
)
# 创建一个数据库游标,用于执行 SQL 语句
self.cursor = self.con.cursor()
# 如果是第一次运行爬虫(StockPipeline.count == 0),创建数据库表
if StockPipeline.count == 0:
try:
# 如果已存在旧的表,删除它(避免表重复)
self.cursor.execute("DROP TABLE IF EXISTS stock")
# 创建一个新的表结构
sql = """
CREATE TABLE IF NOT EXISTS stock (
xuHao VARCHAR(32) PRIMARY KEY, # 股票编号,作为主键
guPiaoDaiMa VARCHAR(32), # 股票代码
guPiaoNingCheng VARCHAR(32), # 股票名称
zuiXingBaoJia DECIMAL(10, 2), # 最新报价,使用 DECIMAL 类型存储带小数的数值
zhangDieFu VARCHAR(32), # 涨跌幅
zhangDieE DECIMAL(10, 2), # 涨跌额,使用 DECIMAL 类型
chengJiaoLiang INT, # 成交量,使用 INT 类型
zhenFu VARCHAR(32), # 震幅
zuiGao DECIMAL(10, 2), # 最高价,使用 DECIMAL 类型
zuiDi DECIMAL(10, 2), # 最低价,使用 DECIMAL 类型
jinKai DECIMAL(10, 2), # 今开,使用 DECIMAL 类型
zuoShou DECIMAL(10, 2) # 昨收,使用 DECIMAL 类型
)
"""
# 执行 SQL 语句创建表
self.cursor.execute(sql)
except Exception as e:
# 如果表创建失败,记录错误信息
spider.logger.error("Error creating table: %s", e)
except Exception as err:
# 如果数据库连接失败,记录错误信息
spider.logger.error("Error connecting to MySQL: %s", err)
def process_item(self, item, spider):
"""
处理每个爬取的 item,负责将数据插入数据库。
- 从 item 中提取数据
- 使用 SQL 插入数据到数据库
"""
try:
# 准备插入数据的 SQL 语句
sql = """
INSERT INTO stock (xuHao, guPiaoDaiMa, guPiaoNingCheng, zuiXingBaoJia, zhangDieFu, zhangDieE,
chengJiaoLiang, zhenFu, zuiGao, zuiDi, jinKai, zuoShou)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
# 从 item 中提取字段值
xuHao = item.get('xuHao', None)
guPiaoDaiMa = item.get('guPiaoDaiMa', None)
guPiaoNingCheng = item.get('guPiaoNingCheng', None)
zuiXingBaoJia = item.get('zuiXingBaoJia', None)
zhangDieFu = item.get('zhangDieFu', None)
zhangDieE = item.get('zhangDieE', None)
chengJiaoLiang = item.get('chengJiaoLiang', None)
zhenFu = item.get('zhenFu', None)
zuiGao = item.get('zuiGao', None)
zuiDi = item.get('zuiDi', None)
jinKai = item.get('jinKai', None)
zuoShou = item.get('zuoShou', None)
# 执行插入数据的 SQL 语句
self.cursor.execute(sql, (
xuHao, guPiaoDaiMa, guPiaoNingCheng, zuiXingBaoJia, zhangDieFu, zhangDieE,
chengJiaoLiang, zhenFu, zuiGao, zuiDi, jinKai, zuoShou
))
# 提交事务,保存数据到数据库
self.con.commit()
except Exception as err:
# 如果插入数据失败,记录错误信息
spider.logger.error("Error inserting data: %s", err)
# 返回 item,以便 Scrapy 继续处理
return item
def close_spider(self, spider):
"""
在爬虫结束时关闭数据库连接
"""
try:
# 关闭数据库连接
self.con.close()
except Exception as err:
# 如果关闭数据库连接时出错,记录错误信息
spider.logger.error("Error closing MySQL connection: %s", err)
step8:运行代码
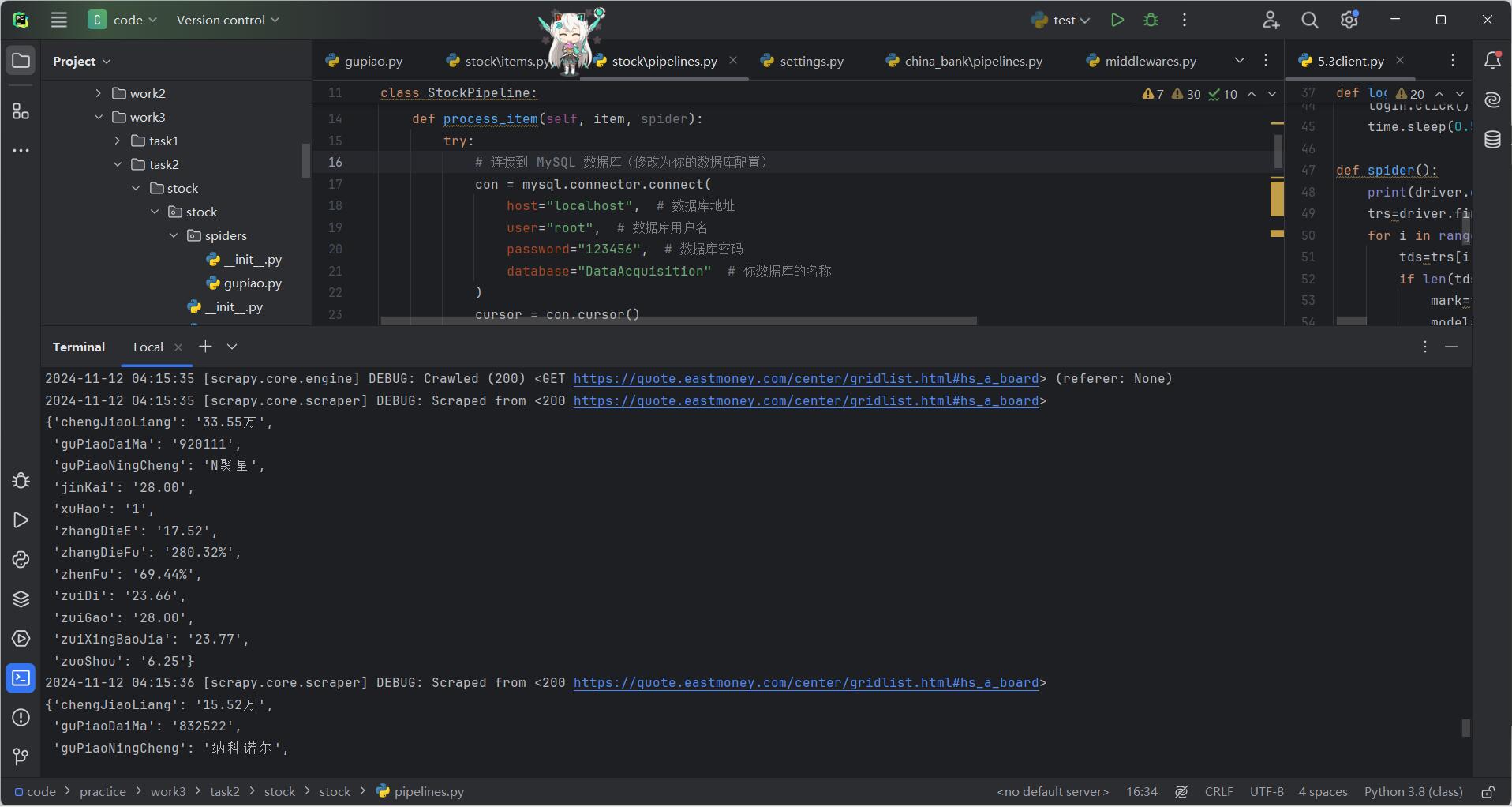
step9:得到结果

(二)心得
提升:做完后发现,好像还可以做一个翻页的数据抓取,但是没有时间做了,这个翻页是ajax请求的,后面有空可以再继续完善
本次股票数据爬取的难点主要是网页的动态数据抓取,选择好中间件,在middlewares.py中做相应的修改。在完成作业的过程中,逐渐掌握了 Scrapy 框架在处理动态网页数据时的基本操作。从请求 URL 的构造、页面解析到数据存储,每一步都需要仔细思考和调试。在 start_requests 方法中,针对不同页面的 URL 进行请求时,我深刻理解了动态请求构建的重要性,尤其是在涉及 JavaScript 渲染内容时,如何有效地获取页面数据。
在数据解析部分,遇到了许多由于 JavaScript 渲染导致的数据缺失问题,这使我意识到传统的 Scrapy 下载器无法满足需求,因此我引入了 Selenium 作为中间件来处理动态页面加载。这一步骤让我学会了如何结合 Selenium 和 Scrapy 来获取和处理动态网页,尤其是如何利用 implicitly_wait 确保页面完全加载。
在 parse 方法中,我进一步加深了对 XPath 的理解,能够灵活地从网页的复杂 HTML 结构中提取出准确的股票数据。定义 StockItem 类并将数据结构化,方便后续存储时的使用。在数据存储环节,通过使用 MySQL 连接器,我学会了如何将爬取的数据存储到数据库中,并在爬虫开始时创建表格结构,确保数据能够持久化保存。
整个项目让我深刻体会到数据爬取过程中的挑战,尤其是在面对动态网页时的技术细节。通过解决爬取过程中的空值处理、动态页面加载等问题,我积累了宝贵的经验,也加深了对爬虫技术的理解。
三、外汇网站数据爬取
(一)步骤
step1:找到对应的网站页面,对不同页面的url进行处理
# start_requests 方法用于生成初始请求并发送到目标网站
def start_requests(self):
pageNum = 2 # 设置要爬取的页数
# 循环遍历页面,构造每个页面的 URL
for page in range(0, pageNum):
if page == 0:
# 第一页的 URL 结构不同,需要单独处理
url = "https://www.boc.cn/sourcedb/whpj/index.html"
else:
# 其他页面的 URL 结构
url = f"https://www.boc.cn/sourcedb/whpj/index_{page}.html"
# 使用 scrapy.Request 发送请求,并指定回调函数 parse 来处理响应
yield scrapy.Request(url=url, callback=self.parse)
step2:注意到网页中有空值,后面要进行相应的处理
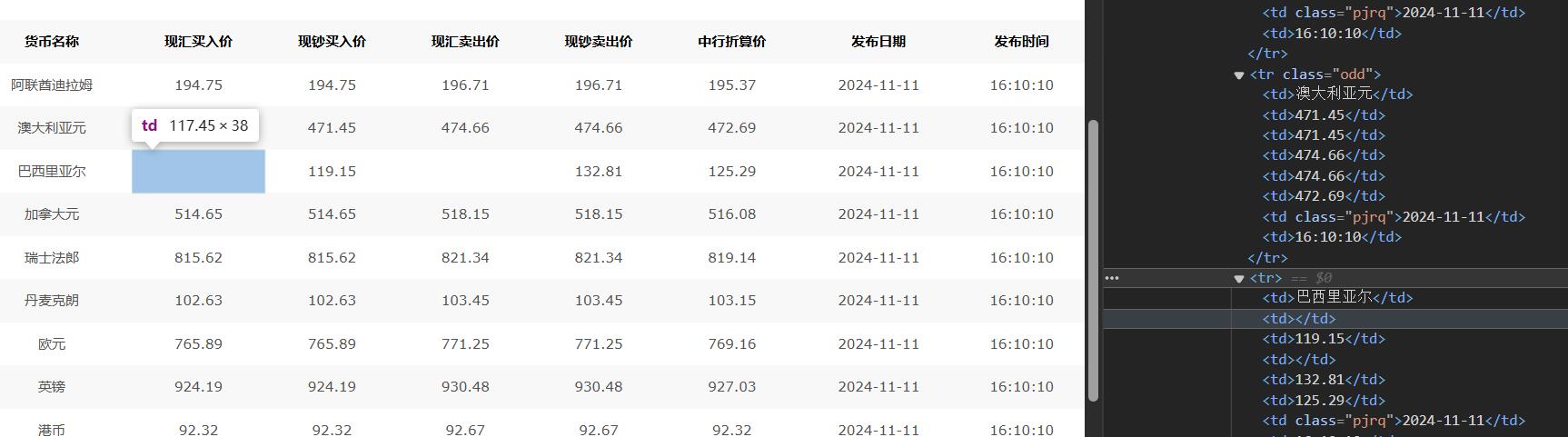
step3:解析页面并提取数据
parse 方法解析网页响应并提取外汇牌价数据。首先将响应字节数据解码为 UTF-8 字符串,然后用 Scrapy 的 Selector 类解析 HTML 内容,定位到包含数据的表格。提取表格行,跳过表头,从第三行开始逐行遍历。对于每行,创建 ChinaBankItem 实例,使用 XPath 提取各列的数据:包括货币名称、现汇买入价、现钞买入价、现汇卖出价、现钞卖出价和更新时间,将其存入 item 对象。最终,通过 yield 将 item 传递到管道进行进一步处理。
# parse 方法用于解析页面响应并提取数据
def parse(self, response):
data = response.body.decode('utf-8') # 将响应的字节数据解码为 UTF-8 字符串
# 使用 Scrapy 的 Selector 类解析解码后的 HTML 数据
selector = scrapy.Selector(text=data)
# 定位包含外汇牌价数据的表格,使用 XPath 表达式查找
body = selector.xpath("//div[@class='publish']//table")
# 提取表格中的所有行(<tr> 元素)
trs = body.xpath(".//tr")
# 提取表头信息(第二行),并打印表头内容用于调试
info_th = trs[1].xpath('.//th/text()').extract()
print(info_th)
# 遍历所有行,从第三行开始(忽略表头),提取每行的数据
for info in trs[2:]:
item = ChinaBankItem() # 创建一个 ChinaBankItem 实例,用于存储提取的数据
# 使用 XPath 表达式提取每列的数据,并存储到 item 对应的字段中
item["Currency"] = info.xpath("./td[1]/text()").get() # 提取货币名称
item["TBP"] = info.xpath("./td[2]/text()").get() # 提取现汇买入价
item["CBP"] = info.xpath("./td[3]/text()").get() # 提取现钞买入价
item["TSP"] = info.xpath("./td[4]/text()").get() # 提取现汇卖出价
item["CSP"] = info.xpath("./td[5]/text()").get() # 提取现钞卖出价
item["Time"] = info.xpath("./td[7]/text()").get() # 提取更新时间
# 将提取的数据传递到 item 管道(pipelines)进行处理
yield item
注:如果直接使用.extract(),就没有办法获取空值,故这里采用get
step4:定义 ChinaBankItem 类
# 定义一个 ChinaBankItem 类,用于存储从网页中提取的数据
class ChinaBankItem(scrapy.Item):
# 定义用于存储货币名称的字段
Currency = scrapy.Field()
# 定义用于存储“现汇买入价”的字段
TBP = scrapy.Field()
# 定义用于存储“现钞买入价”的字段
CBP = scrapy.Field()
# 定义用于存储“现汇卖出价”的字段
TSP = scrapy.Field()
# 定义用于存储“现钞卖出价”的字段
CSP = scrapy.Field()
# 定义用于存储“更新时间”的字段
Time = scrapy.Field()
step5:mysql中创建数据库

step6:在mysql数据库创建bank表,并将爬取到的数据存储到表中
# 定义一个处理从 Scrapy 爬虫中提取数据的管道类
class ChinaBankPipeline:
count = 0 # 定义一个类变量 count,用于跟踪处理的数据项数
# 处理每个传入的 item 对象
def process_item(self, item, spider):
try:
# 连接到 MySQL 数据库(请根据实际情况修改为你的数据库配置)
con = mysql.connector.connect(
host="localhost", # 数据库主机地址
user="root", # 数据库用户名
password="123456", # 数据库密码
database="DataAcquisition" # 目标数据库名称
)
cursor = con.cursor() # 创建一个游标对象,用于执行 SQL 语句
# 如果这是第一个被处理的 item,则创建表结构
if ChinaBankPipeline.count == 0:
try:
# 删除旧表(如果已存在)以避免冲突
cursor.execute("DROP TABLE IF EXISTS bank")
# 创建新的表结构
sql = """
CREATE TABLE IF NOT EXISTS bank (
Currency VARCHAR(64) PRIMARY KEY, # 货币信息,作为主键
TBP FLOAT, # 现汇买入价
CBP FLOAT, # 现钞买入价
TSP FLOAT, # 现汇卖出价
CSP FLOAT, # 现钞卖出价
Time VARCHAR(64) # 更新时间
)
"""
cursor.execute(sql) # 执行 SQL 语句创建表
except Exception as e:
print("Error creating table:", e) # 如果出错,打印错误信息
# 准备插入数据的 SQL 语句
sql = """
INSERT INTO bank (Currency, TBP, CBP, TSP, CSP, Time)
VALUES (%s, %s, %s, %s, %s, %s)
"""
try:
# 从 item 对象中提取数据
currency = item.get('Currency') # 获取货币信息
tbp = item.get('TBP') # 获取现汇买入价
cbp = item.get('CBP') # 获取现钞买入价
tsp = item.get('TSP') # 获取现汇卖出价
csp = item.get('CSP') # 获取现钞卖出价
time = item.get('Time') # 获取更新时间
# 执行 SQL 插入语句,将数据插入数据库
cursor.execute(sql, (currency, tbp, cbp, tsp, csp, time))
except Exception as err:
print("Error inserting data:", err) # 如果插入数据时出错,打印错误信息
# 提交事务,保存数据更改
con.commit()
# 关闭数据库连接
con.close()
except Exception as err:
print("Error:", err) # 如果连接数据库或其他操作失败,打印错误信息
# 增加计数器,表示已处理的数据项数
ChinaBankPipeline.count += 1
# 返回处理后的 item 对象
return item
step7:scrapy crawl wea -s LOG_ENABLED=False运行项目
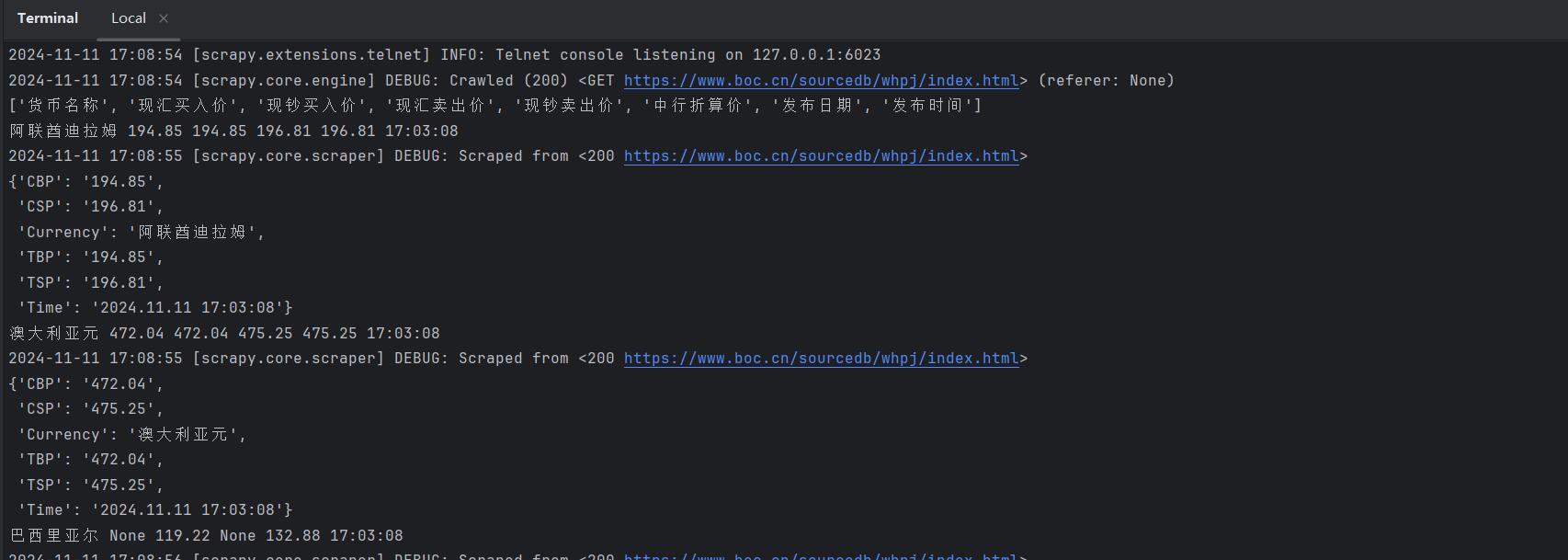
step8:mysql中查看结果

(二)心得
在完成这次外汇网站数据爬取的过程中,逐渐掌握了使用 Scrapy 框架获取网页数据的基本流程。从构造 URL 请求、解析网页到将数据存储在数据库中,每一步都需要细心和耐心。在 start_requests 方法中,处理不同页面的 URL 让我意识到构建动态请求的重要性。解析数据时,我注意到网页中可能会有空值,因此学习并应用了 .get() 方法来避免数据缺失问题,这显著提高了代码的稳定性和健壮性。
在提取数据的 parse 方法中,进一步加深了对 XPath 语法的理解,能高效地从复杂的 HTML 结构中定位和提取信息。定义 ChinaBankItem 类明确了数据结构,为后续的存储提供了便利。在存储数据环节,学会了使用 MySQL 连接和操作,理解了如何在管道中处理数据,创建表结构,并插入爬取的数据。
整个项目让我体会到数据爬取和处理的过程,项目中遇到的空值处理、数据库连接等问题,逐步慢慢的都解决了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号