2024数据采集与融合技术实践-作业2
作业①
要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
(一)步骤及代码
1.1步骤
step1:获取各城市对应的编号,定义在类WeatherProcess中
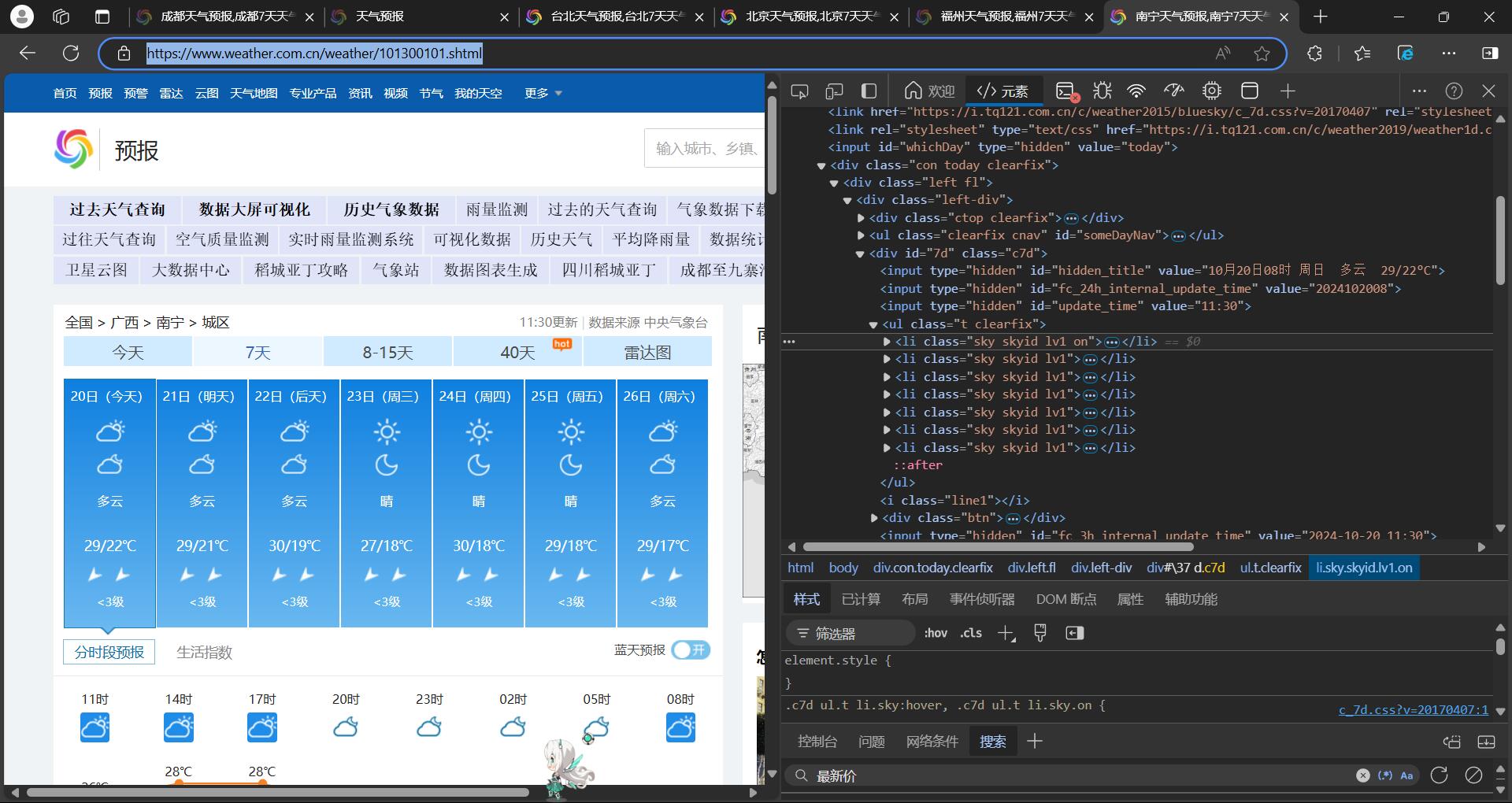
# 存储各个城市对应的天气页面代码
self.cityCode = {"北京": "101010100", "南宁": "101300101", "福州": "101230101", "台北": "101340101"}
# 初始化一个字典,用来存储爬取到的城市、日期、天气和温度信息
self.all = {"城市": [], "日期": [], "天气": [], "温度": []}
step2:解析网页,获取到所需要的数据
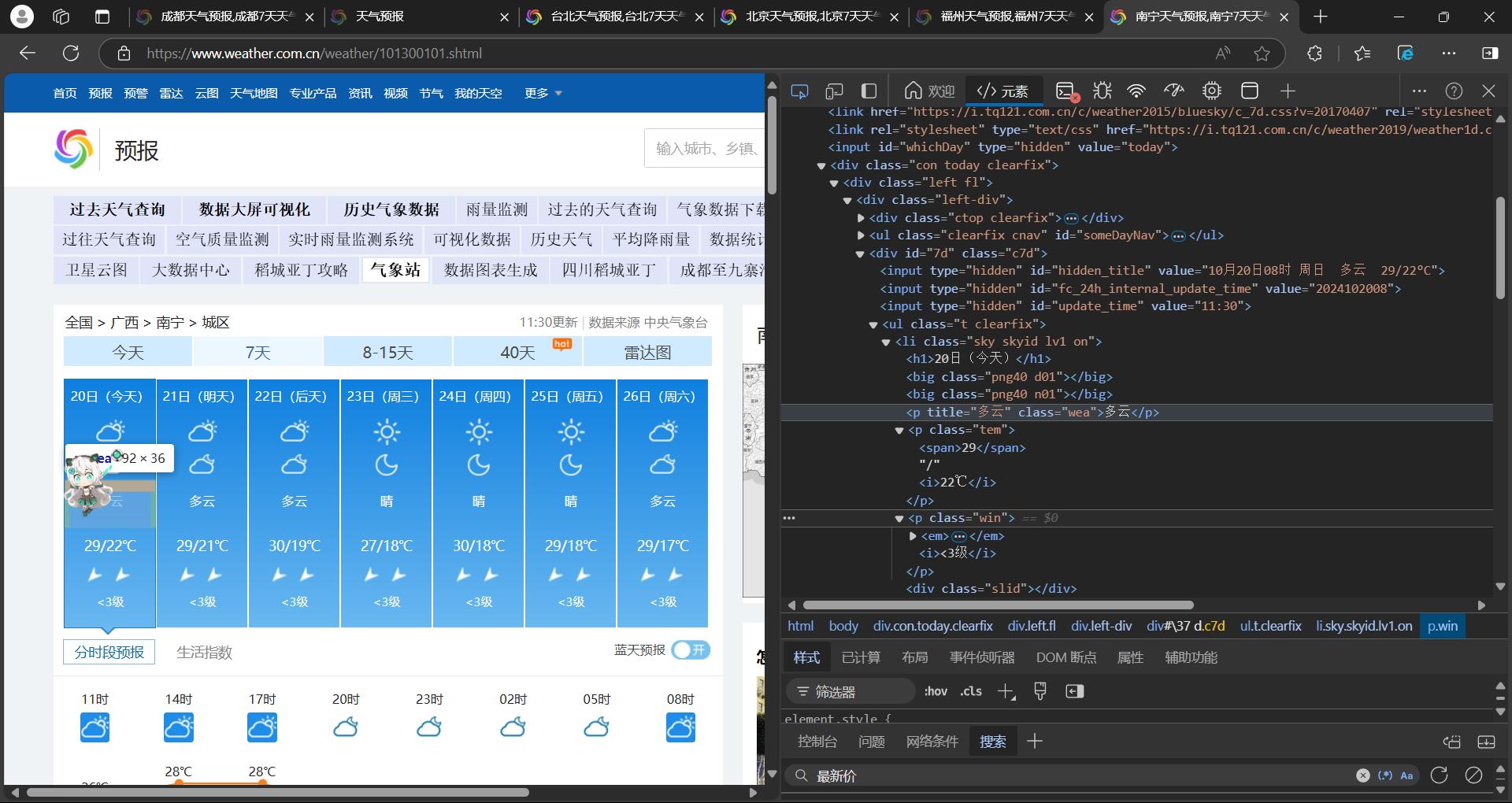
# 找到包含天气信息的 ul 标签
body = soup.select_one("ul[class='t clearfix']")
# 提取日期信息,h1 标签包含日期
date = body.select("h1")
# 提取天气信息,p 标签的 class 为 'wea' 的标签包含天气描述
weather = body.select("p[class='wea']")
# 提取温度信息,p 标签的 class 为 'tem',i 标签包含温度数值
tem = body.select("p[class='tem'] i")
step3:对获取到带标签的内容进行解析,获取相应的文本值
# 定义列表来存储解析后的信息
da = []
we = []
te = []
# 将提取到的内容逐条存入各自的列表
for d, w, t in zip(date, weather, tem):
da.append(d.text.strip()) # 去掉多余的空白字符
we.append(w.text.strip())
te.append(t.text.strip())
step4:对返回值进行存储
for date, weather, tem in zip(*self.parse(html)): # 假设 self.parse(html) 返回三个列表
self.all["城市"].append(city) # 追加城市名称
self.all["日期"].append(date) # 追加日期
self.all["天气"].append(weather) # 追加天气状况
self.all["温度"].append(tem) # 追加温度信息
step5:运行代码得到最终结果
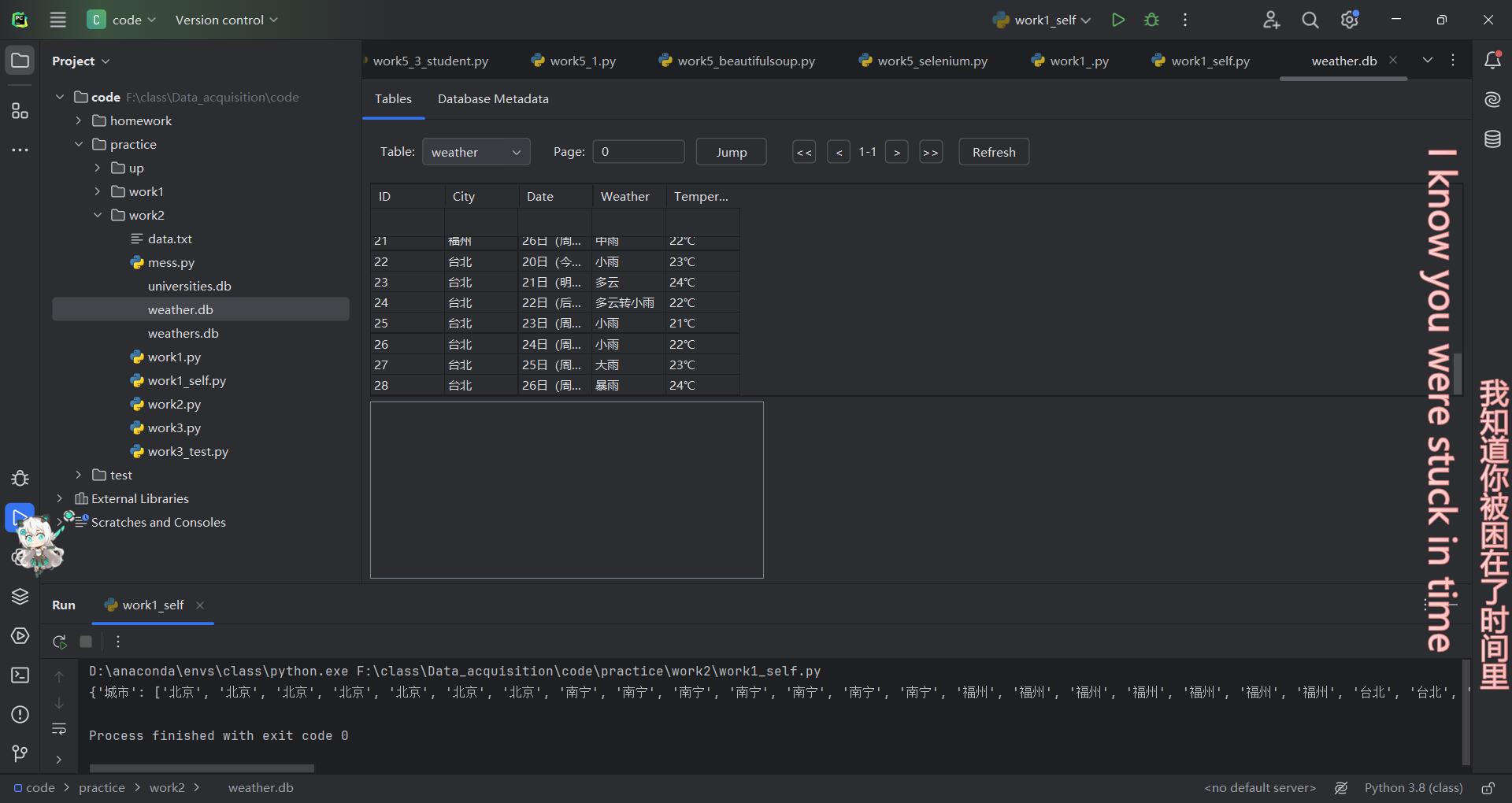
1.2完整代码Gitee链接
作业2/1.py · 曹星才/2022级数据采集与融合技术 - 码云 - 开源中国
(二)心得体会
本次的网页解析部分不算是很难,主要是存储部分,使用整个类进行数据处理部分,并使用字典对数据进行存储,最后解析返回值即可。最后可以选择是否存储到数据库。
作业②
要求:用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。
(一)步骤及代码
1.1步骤
step1:爬取东方财富网股票信息http://quote.eastmoney.com/center/gridlist.html#hs_a_board
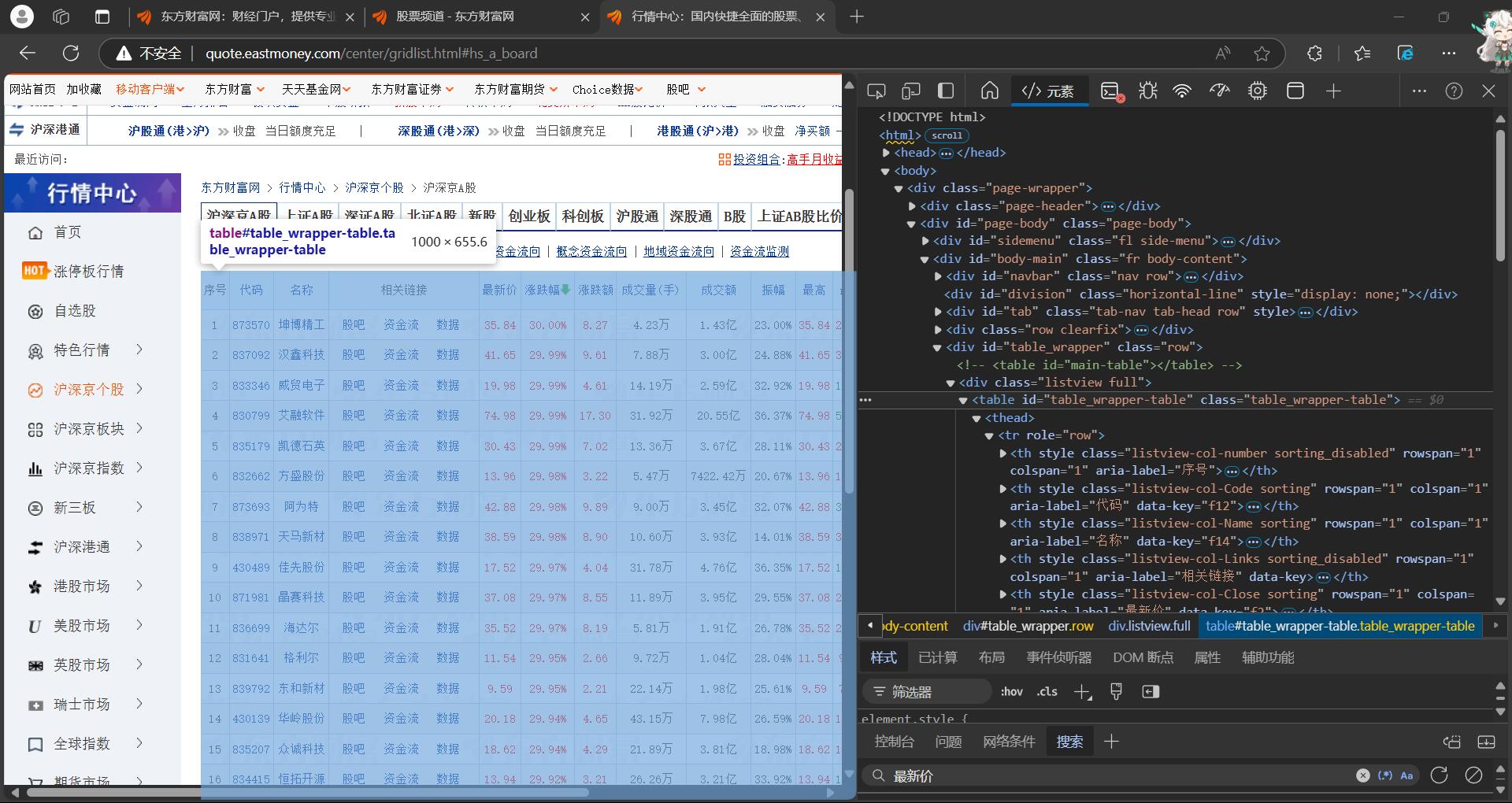
step2:在网络中搜索名称,如“坤博精工”,抓到数据包
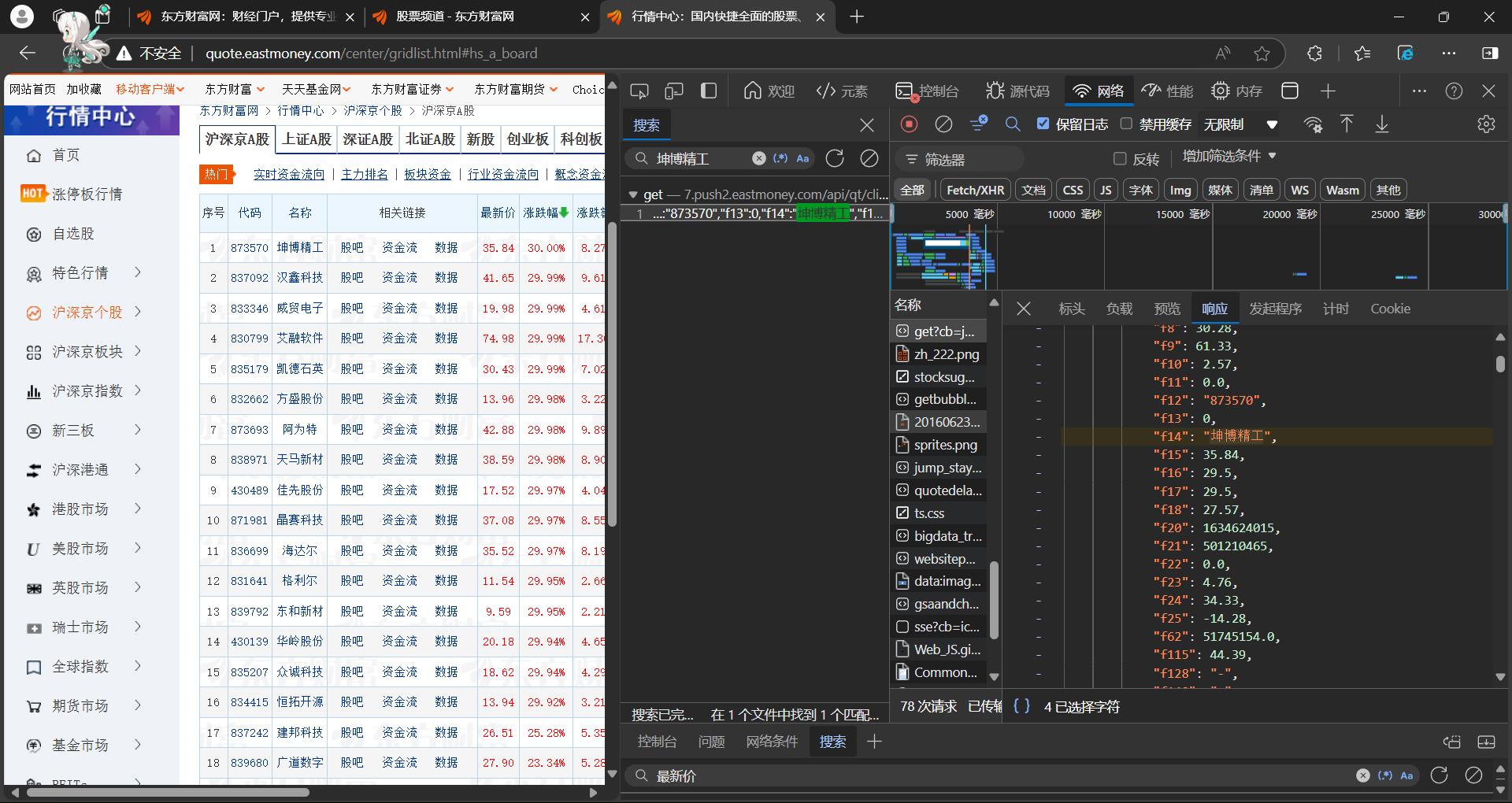
step3:注意对比,找到”f+数字“对应的含义
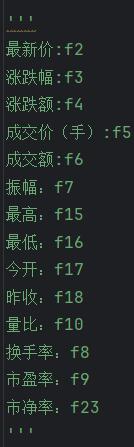
step4:因为返回的数据为json格式,不能使用beautifulsoup解析数据,故使用re对想要的数据进行获取
regs=["f14","f2","f3","f4","f5","f6","f7","f15","f16","f17","f18","f10","f8","f9","f23"]
all=[]
count=0
for reg in regs:
reg_=f'"{reg}":(.*?),'
match=re.findall(reg_,html)
all.append(match)
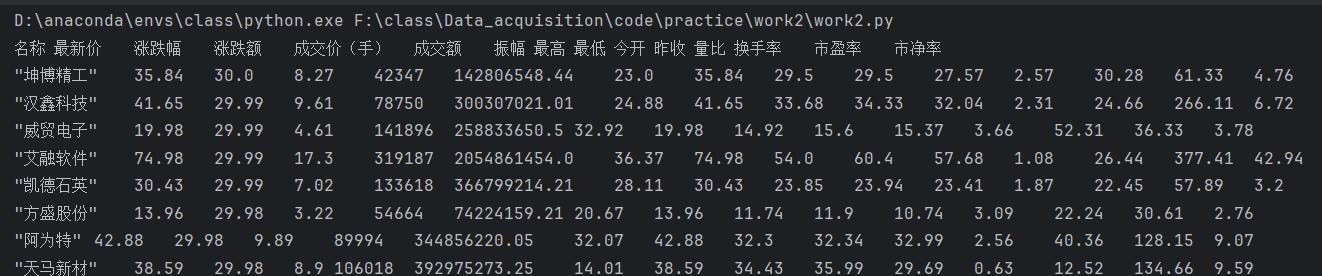
step5:得到结果
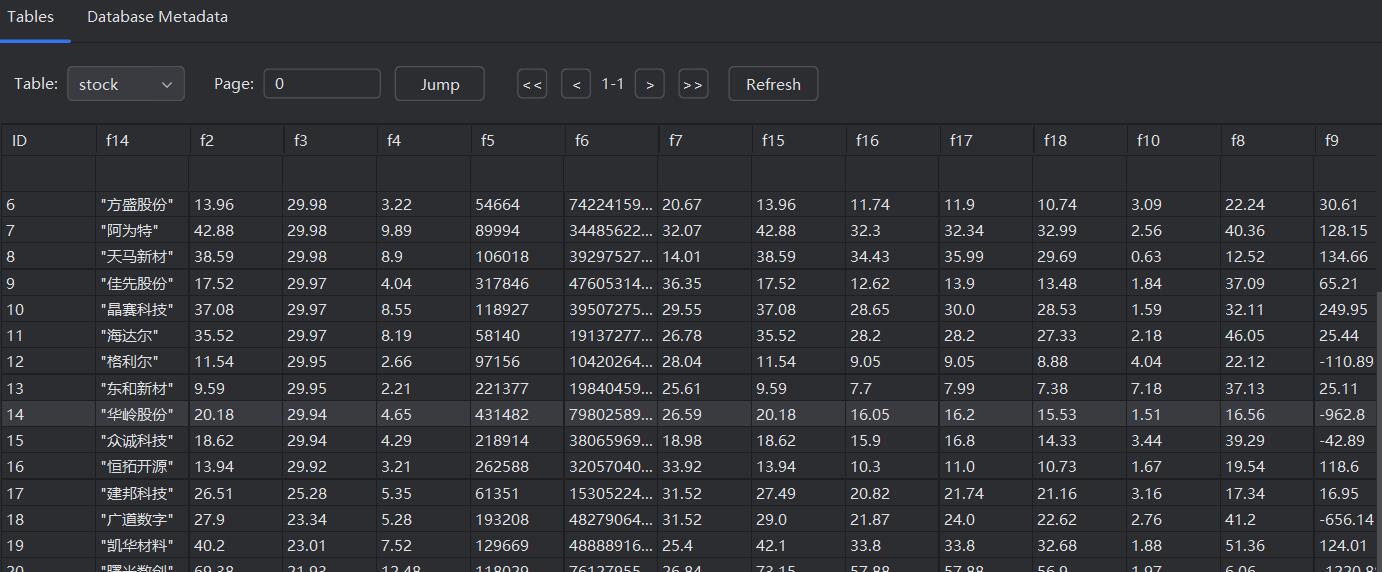
step6:保存到数据库
1.2完整代码Gitee链接
作业2/2.py · 曹星才/2022级数据采集与融合技术 - 码云 - 开源中国
(二)心得体会
因为股票的信息的js动态渲染的,没有办法通过url直接获取页面的真实数据,就只能通过抓包方式获取。对于数据包中的信息,因为数据是以json形式储存的,没有办法使用json解析数据,所以用另外的一种方法——re库解析(也可以使用json解析),找到对应的每一部分“f+数字”进行存储即可。
作业③
要求:爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
(一)步骤及代码
1.1步骤
step1:抓包
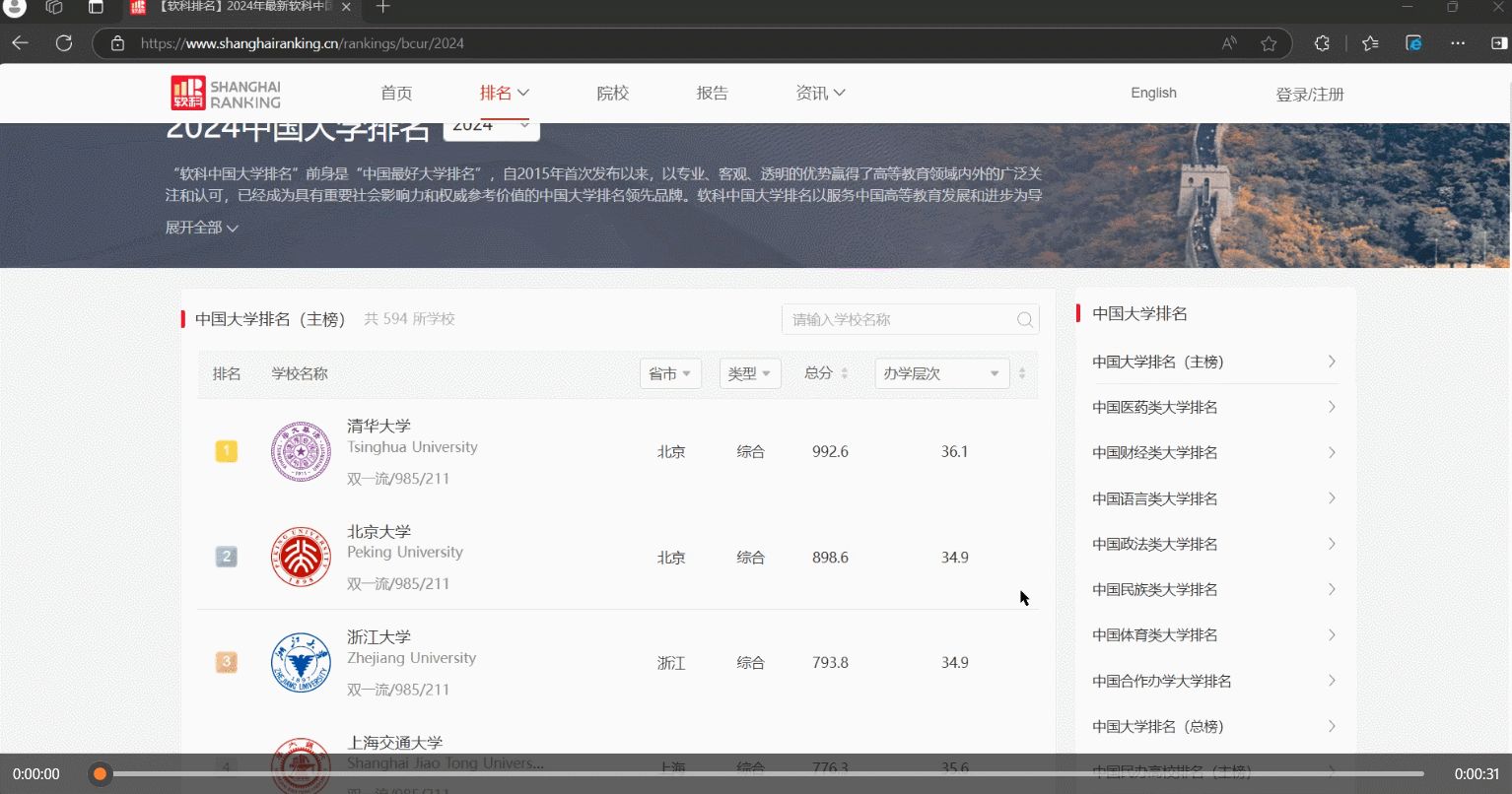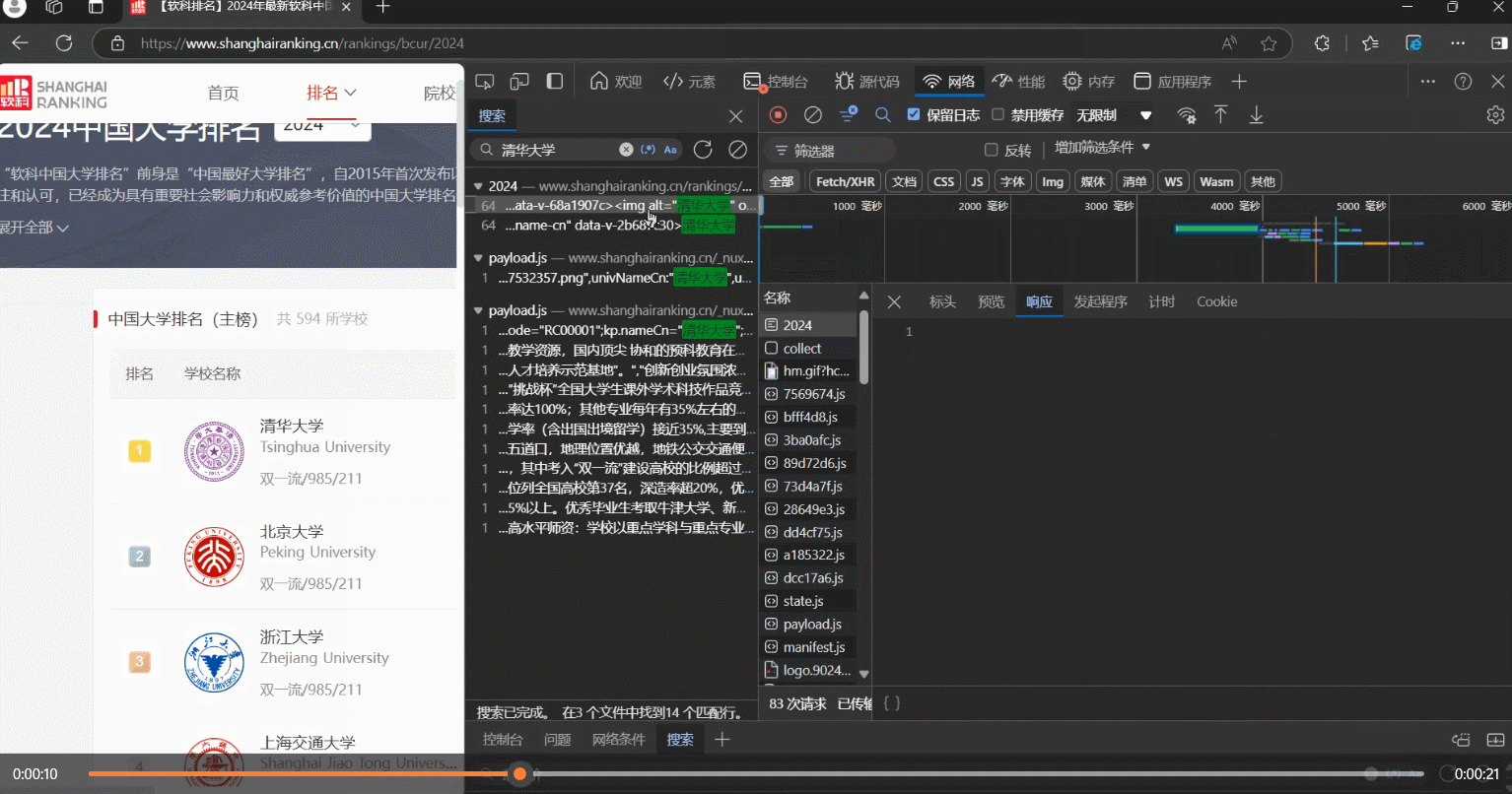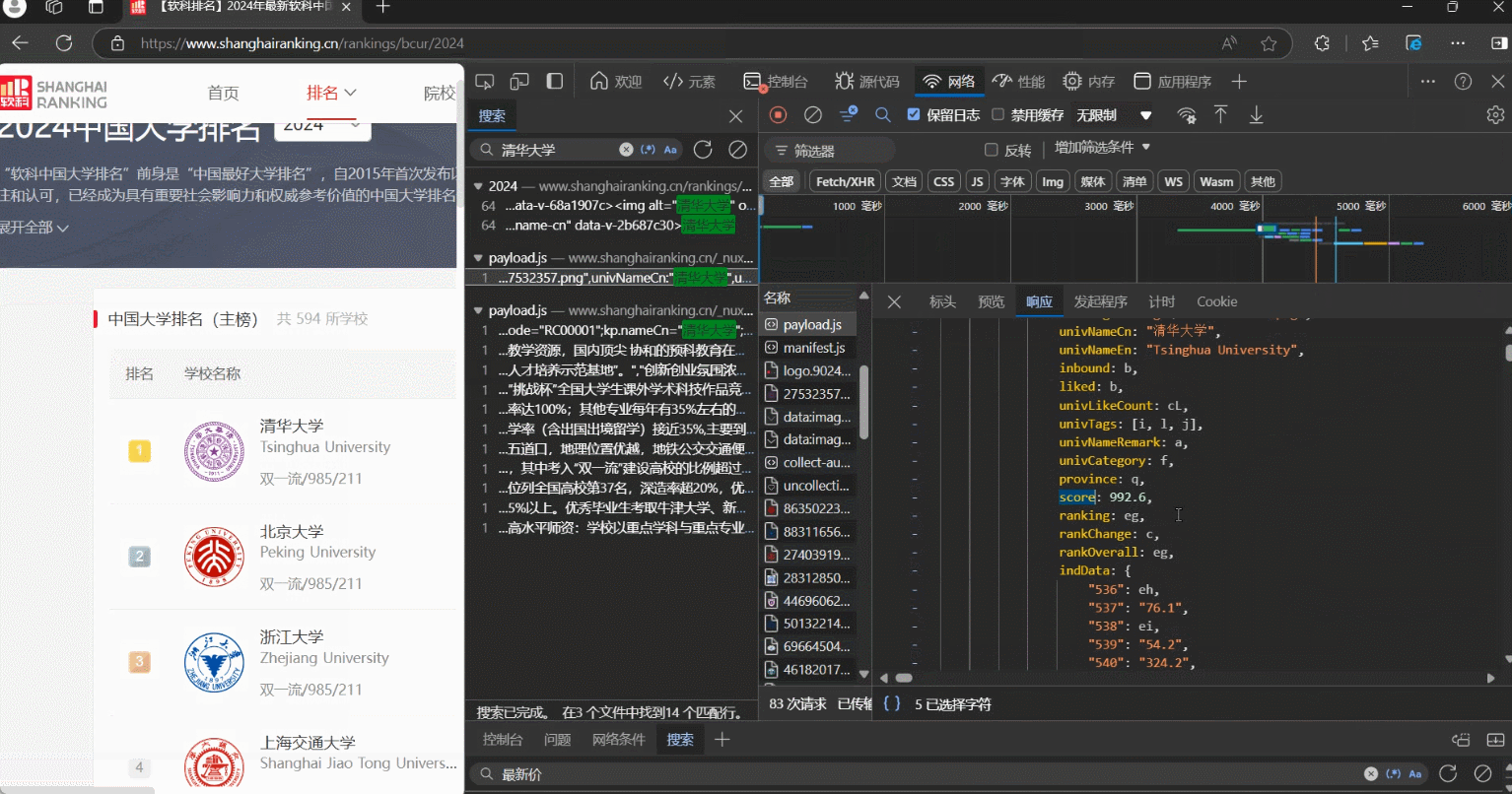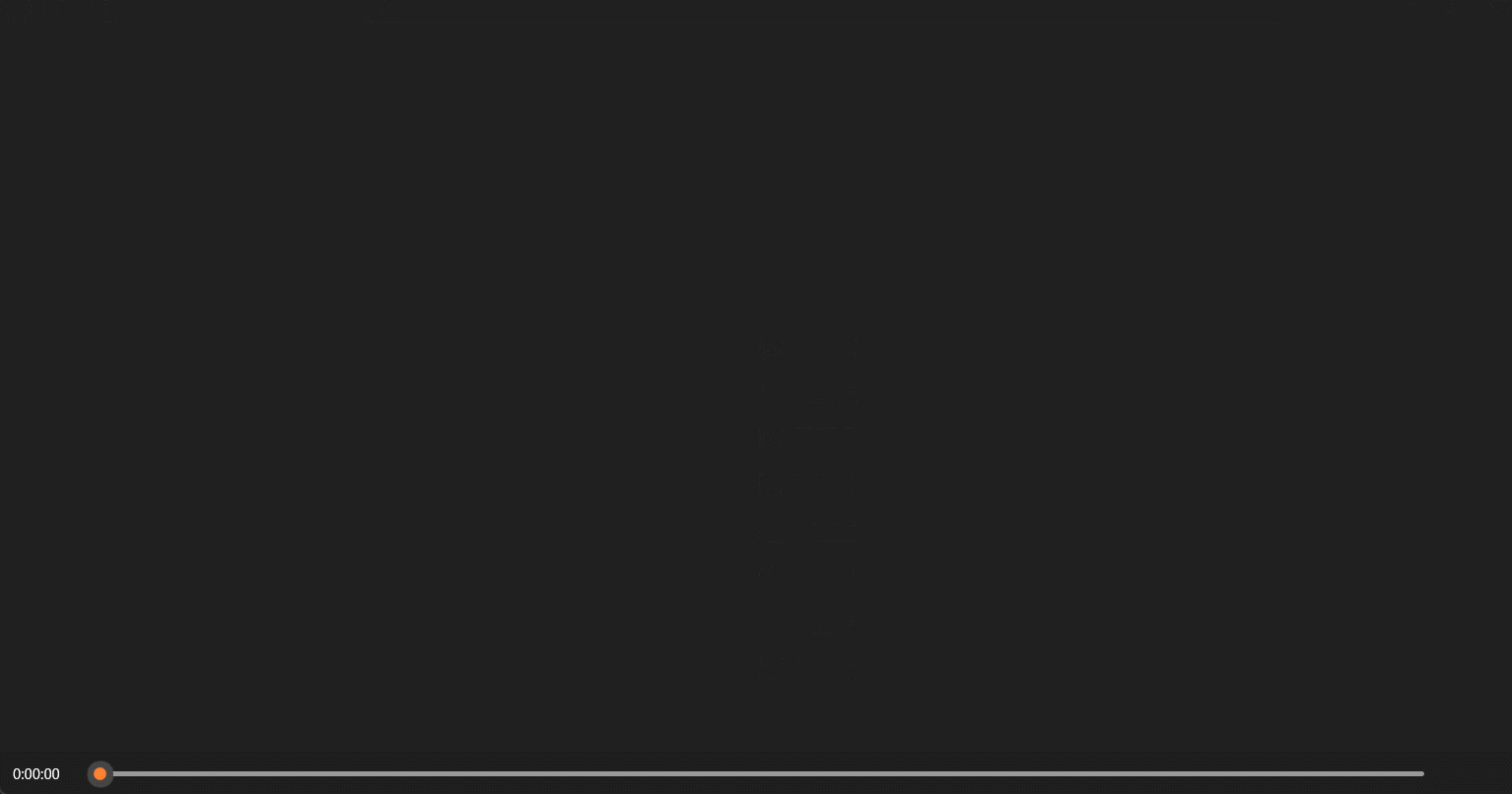
step2:解析数据
# 使用正则表达式提取学校名称、省市代码、类型代码和总分信息
name = re.findall(r'univNameCn:"(.*?)",', html) # 提取学校名称
province_code = re.findall(r'province:(.*?),', html) # 提取省市代码
univCategory_code = re.findall(r'univCategory:(.*?),', html) # 提取学校类型代码
score = re.findall(r'score:(.*?),', html) # 提取总分
step3:找到对应的映射关系,并处理为列表格式,通过位置映射
# 从HTML中提取用于解码省市和类型的映射信息
code = re.findall('function(.*?){', html)
value = re.findall('mutations:(.*?);', html)
code = code[0][1:-1].split(",") # 处理编码数据
value = value[0][5:-3].split(",") # 处理数值数据
# 解码省市和学校类型
province = []
univCategory = []
for p, u in zip(province_code, univCategory_code):
# 使用提取的编码与数值对照表解码省市和类型信息
province.append(value[code.index(p)][1:-1])
univCategory.append(value[code.index(u)][1:-1])
step4:运行得到结果

step5:存储到数据库中
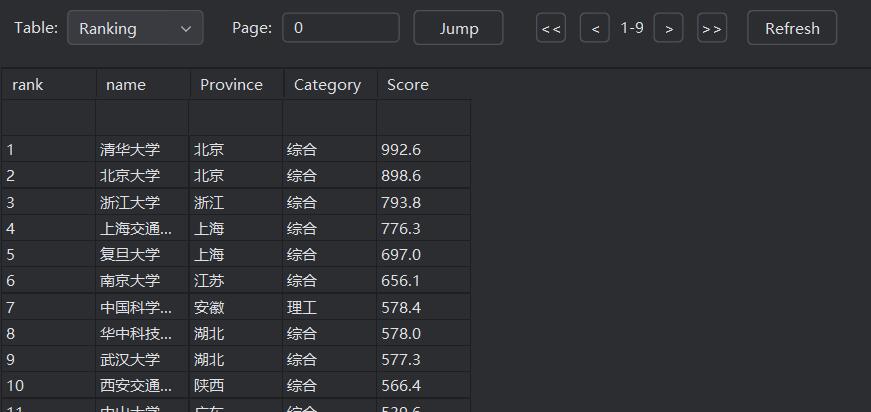
1.2完整代码Gitee链接
作业2/3.py · 曹星才/2022级数据采集与融合技术 - 码云 - 开源中国
(二)心得体会
解析获取到的响应数据可以得到,该响应数据分为三部分,第一部分是开始得function部分,为主体部分的变量名;第二部分,也就是主体部分,有些数据存储在这,但是有些数据是以变量名代替的,和第一部分的function变量相对应;第三部分是最后的mutations部分,里面存储了变量名的值,根据位置索引定位,所以根据索引关系可以找到每一个变量对应的值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号