浅谈RNN与LSTM
参考链接:https://www.cnblogs.com/wangduo/p/6773601.html
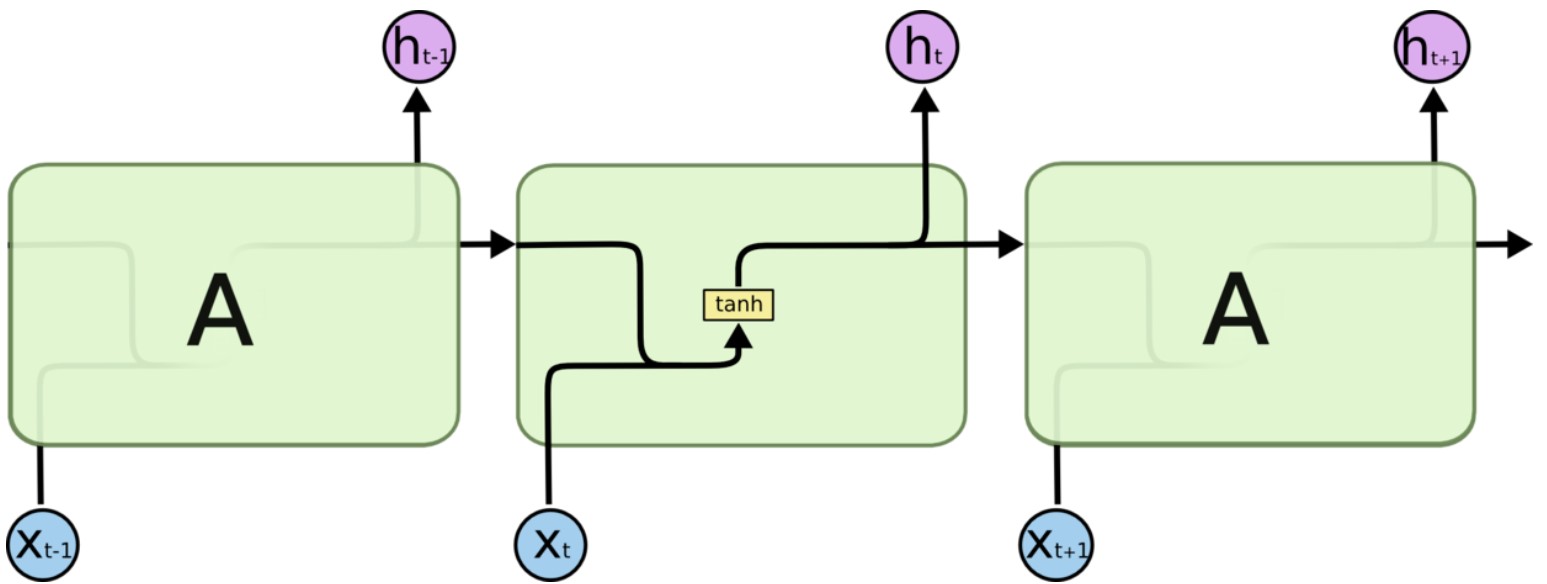
RNN
- 输入为序列 \(X=\{x_0,x_1,...,x_t,...\}\) ,输出为 \(H=\{h_0,h_1,...,h_t,...\}\),将内部的隐藏层认为是 A。
- 当前输出不仅依赖于当前的输入,还依赖于上一次的输出:\(h_t=tanh(W[h_{t-1},x_t]+b)\)。
- 存在的问题的是,对于长序列,如果相距过远,序列关系很难挖掘。
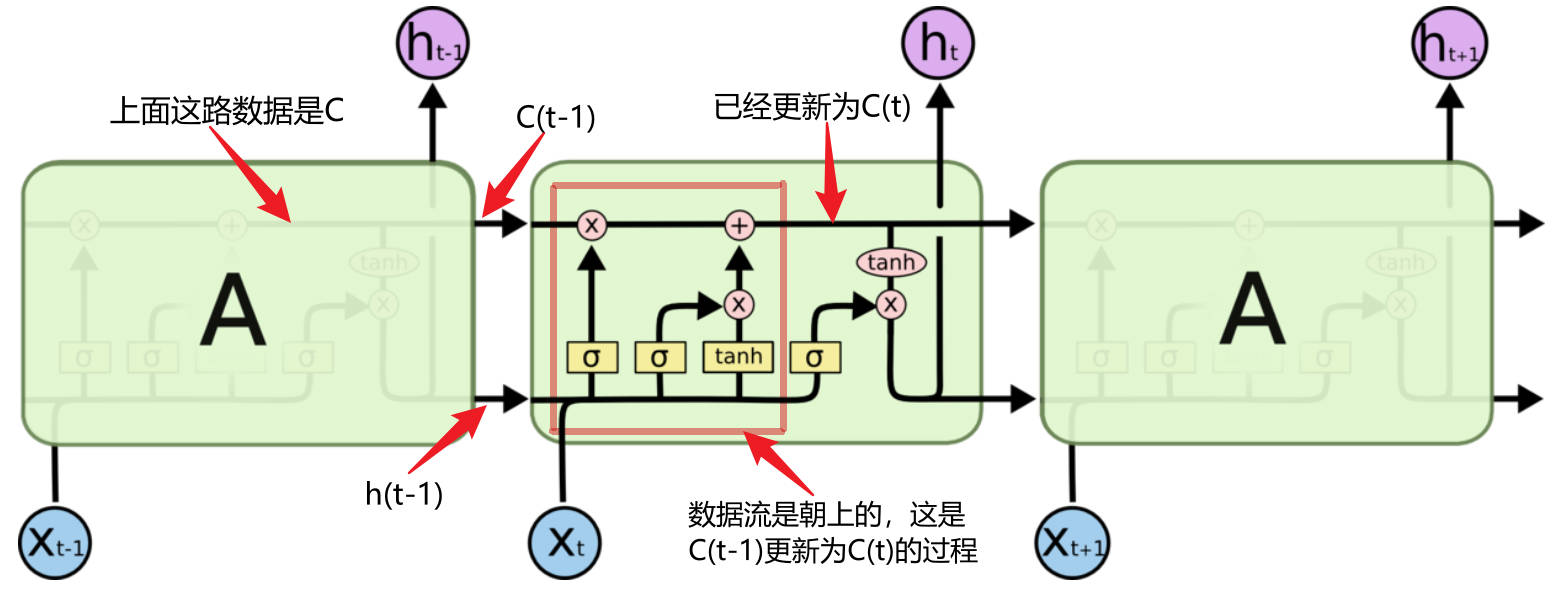
LSTM
相比于 RNN 直接将上一输出 \(h_{t-1}\) 交给A,还设计了一个称为 cell state 的东西,用来保存长期记忆,这里用 \(C=\{c_0,c_1,...,c_t,...\}\) 表示。很自然地,确定当前状态 \(c_t\) 的值成了一个问题。
具体来说,有以下两个方面:
-
根据当前状态 \(h_t(x_t,h_{t-1},c_{t-1})\),过去 cell state 即 \(c_{t-1}\) 的信息如何调整;
-
在当前的输入 \((x_t,h_{t-1})\)下,哪些特征是需要保留在 cell state 里的。
这就要提到 LSTM 里的一个重要的设计,称为“门”,类似信号处理里的“窗”,其作用是 选择信息。LSTM 的门由 sigmoid 和乘操作实现。在一些解释里,可能会有遗忘门,记忆门这样的说法,这里稍作参考。
sigmoid 函数如下:
其取值范围在 (0,1),x 趋近于负无穷,值趋近于0,x趋近于正无穷,值趋近于1。这里就当作是按 0 和 1 来取值。这是一种毫不犹豫地取舍,1完全保留,0完全抛弃。经过sigmoid 的取舍后,可以得到一组 特征数据,表示着对各个维度的关注程度。
乘:在线性代数中,向量/矩阵的乘法其实是一种在不同的基下的映射/变换。所以,乘是 目标数据 在 特征数据 下,做了一次映射/变换。简单理解就是, 目标数据 在 特征数据 所在的空间,进行投影。
以 \(c_{t-1}\) 为例,门的功能如下: \(T\cdot c_{t-1}=\overline{c_t}\),其中,T 表示经过 sigmoid 选择后的特征数据,\(T=\sigma(W[x_t,h_{t-1}]+b)\),其中的变量是 \([x_t,h_{t-1}]\),W,b 是参数。
接下来,对 A 里面的一些动作进行分解。
- \(c_{t}\) 的更新:
- \(\overline{c_t}=T_1\cdot c_{t-1}\)。这里的 \(T_1\cdot\) 是常说的遗忘门,对 长时记忆cell state 进行选择,进行调整;
- \(\widetilde{c}=T_2\cdot tanh(W[x_t,h_{t-1}]+b)\)。这 \(T_2\cdot\) 是常说的记忆门,对当前打算保存到 Cell state 的候选数据 \(tanh(W[x_t,h_{t-1}]+b)\) 进行选择;
- \(c_t=\overline{c_t}+\widetilde{c}\)。至此,长时记忆做了调整,加入了新的短时记忆,更新完成。
- 输出 \(h_t\):\(h_t=T_3\cdot tanh(c_t)\)。这里的 \(T_3\cdot\) 就是常说的输出门。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号