论文笔记:周志华-弱监督学习综述
参考文献:周志华-弱监督学习综述
原论文主要介绍了三类基本的弱监督学习,最好把这个当作弱监督学习方向的论文索引,根据具体的方向,再去拜读引用的论文。
弱监督学习主要的三种类型three typical types of weak supervision(在实际的案例中,这些情况往往是同时出现的):不完整监督、不精确监督和不准确监督(后面详细)
不完整监督
数据集中部分无标签 incomplete supervision, where only a subset of training data is given with labels。对此,主要有两种方法主动学习和半监督学习。
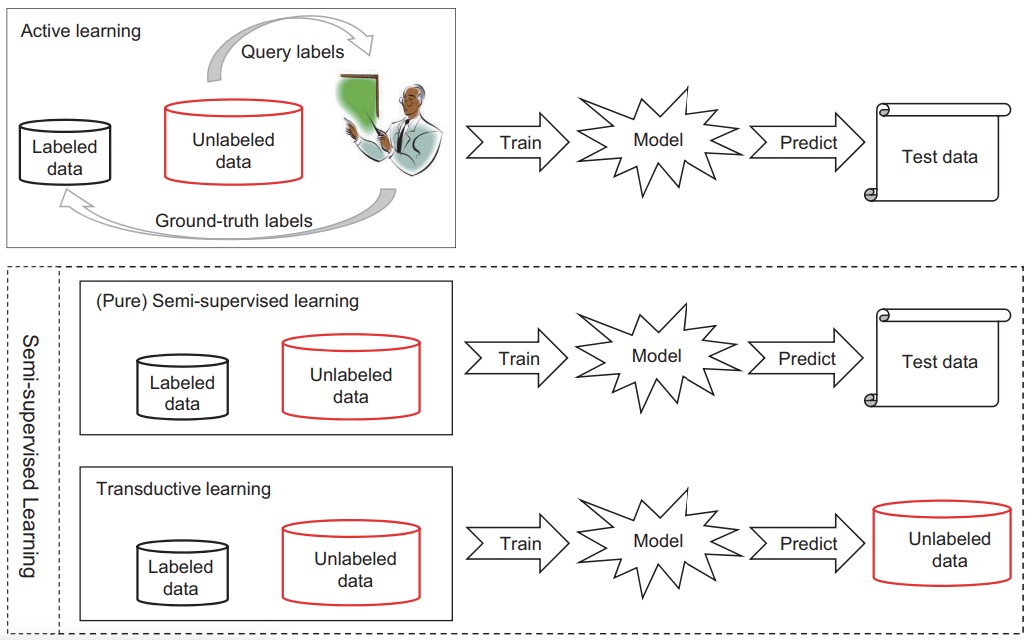
主动学习
假设有一个”老师“,从它那里可以查询未标记数据的真实label。目标是最大限度的减少查询数,它要尝试选择查询 ”最有价值“ 的无label数据。怎么选择,有两个广泛使用的标准,”信息量“ 和 ”代表性“。把它想象成聪明的,会主动学习的学霸,老师是一个很懒的 ”老师“。
- 基于 ”代表性“ 的方法利用了未标记数据的聚类结构,通常采用聚类方法。因此,其性能很大程度上取决于未标记数据未标记的聚类结果
- Uncertainty sampling:单个学习者,查询置信度最低的样本
- query-by-committee:多个学习者,查询争议最大的样本(应该有种投票机制在里面)
- 基于 “信息性” 的方法缺点在于:严重依赖标记数据,标记数据很少时,性能不稳定
半监督学习
不找 ”老师“ 查询的情况
-
转导学习:未标记数据就是测试数据,目标是优化测试数据的性能
-
纯半监督学习:未标记数据不一定是测试数据
-
四类主要的学习方法
- 生成方法设标记和未标记的数据都是从相同的固有模型生成的。因此,未标记实例的标签可以被视为模型参数的缺失值,并通过诸如EM(期望最大化)算法之类的方法进行估计。依赖生成模型,需要领域知识
- 基于图的方法构造一个图,其中节点对应于训练实例,边对应于实例之间的关系(通常是某种相似性或距离),然后根据某些标准在图上传播标签信息。性能将在很大程度上取决于图形的构造方式,存储和计算的复杂度都很高,可扩展性差
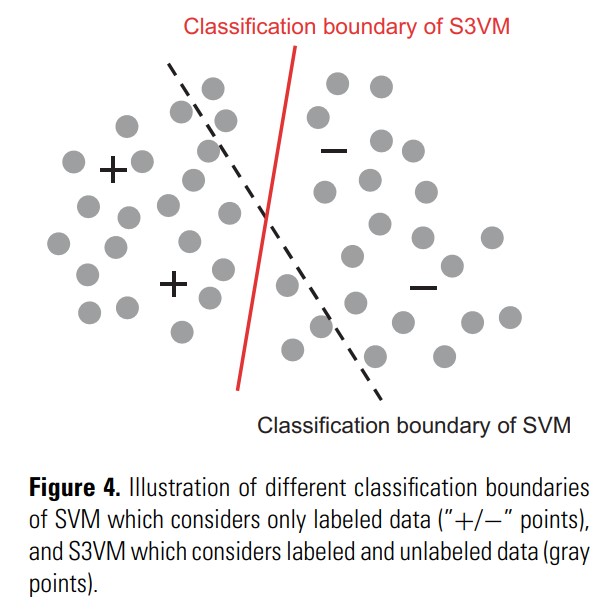
- 低密度分离方法强制分类边界跨越输入空间中密度较低的区域。最著名的代表是S3VM(半监督支持向量机)
- 基于分歧的方法产生多个学习者,并让他们协作以利用未标记的数据,其中学习者之间的分歧对于允许学习过程继续进行至关重要。基于分歧的方法提供了一种将半监督学习与主动学习相结合的自然方法:除了让学习者相互学习之外,还可以选择一些未标记的实例
- 值得一提的是,尽管通过利用未标记的数据可以提高学习性能,但在某些情况下,半监督学习后的性能可能会变得更糟。
半监督的两个基本假设
- 集群假设 cluster assumption:假设数据具有固有的集群结构,因此,落入同一集群的实例具有相同的类标签
- 流行假设 manifold assumption:假设数据位于流形上,因此,附近的实例具有类似的预测
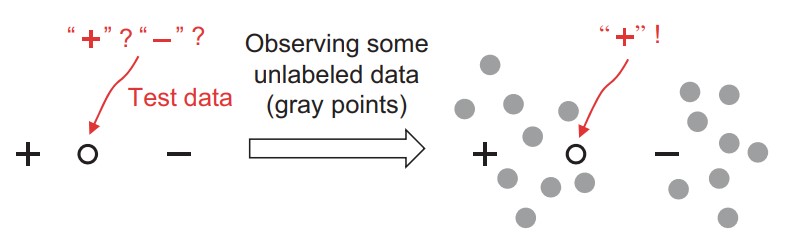
本质在于相信相似的数据点应该具有相似的输出,而未标记的数据可能有助于披露哪些数据点是相似的。
Q:why data without labels can help construct predictive models?
假设数据来自具有 n 个混合成分的高斯混合模型,即
其中,\(\alpha_i\) 是混合系数,有 \(\sum_{i=1}^n\alpha_i=1\) ,\(\Theta={\theta_i}\) 是模型参数。此时,标签 \(y_i\) 可以认为是一个随机变量,其分布 \(P(y_i|x_i,g_i)\) 由混合分量 \(g_i\) 和特征向量 \(x_i\) 决定。根据最大后验准则,我们有模型
其中
该目标函数通过从训练数据估计 \(P(y_i=c|g_i=j,x_i)\) 和 \(P(g_i=j|x_i)\) 来实现。很明显,只有第一项需要标签信息。因此,未标记的数据可用于帮助改进第二项的估计值,从而提高学习模型的性能。
不精确监督
标签粒度比较糙 inexact supervision, where the training data are given with only coarse-grained labels。数据集是 bag 和标签的一对一对组合,bag 里面包含多个实例,但是不知道具体。目标是预测未知的 bag 的标签,成为多实例学习。
一些研究方向:预测未知 bag 的标签,找出有标签 bag 的关键实例(这里假设每个 bag 一定含一个key instance)
存在的问题:bag 异构的情况。目前多实例学习理论结果罕见。
不准确监督
标签不保证正确 inaccurate supervision, where the given labels are not always ground-truth
一个典型的场景:对带噪声的标签学习。
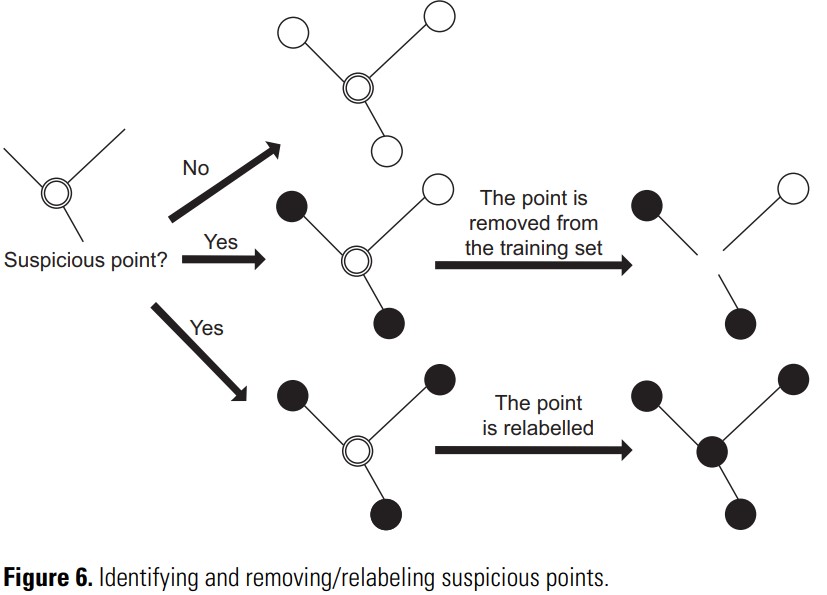
其中一个方法:数据编辑方法data-editing,构造一个相对邻域图,其中每个节点对应于一个训练示例,并且连接具有不同标签的两个节点*的边称为割边。然后,测量一个切削的权重统计数据,如果实例与许多切边相关联,则实例是可疑的。可疑实例可以删除或重新标记。该方法依赖于咨询邻域信息,因此,它们在高维特征空间中不太可靠。
一个场景:分析众包得来的标签。需要在成本和标签准确性之前平衡

 浙公网安备 33010602011771号
浙公网安备 33010602011771号