第一单元总结——我对面向对象的探索
第一单元的面向对象作业以表达式求导为主线,逐步加深复杂度。我在完成这三次作业的过程中,终于跳出熟悉的面向过程领域,初步体会到了面向对象编程思想与面向过程编程思想的不同。
教科书上对于面向对象的特征描述十分简单:封装、继承、多态。我在这三次作业中对着三个特性逐渐形成了自己的理解。
第一次作业
程序分析
用java实现简单的表达式求导,原子因子只有幂函数和带符号整数。第一次作业复杂性并不高,正好可以作为由面向过程向面向对象过度的作业。
我的第一次作业的类图和类间依赖图如下:
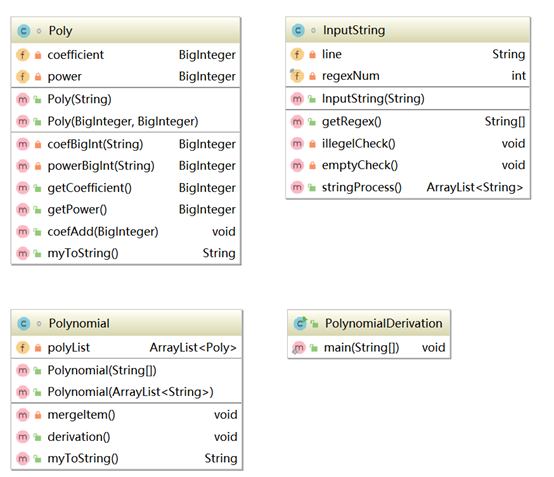

第一次作业的代码中透露出浓浓的面向过程的气息。代码的核心是函数,而数据域则是因为和函数有关而被和函数封装到一起形成了类。在类中只是简陋的把方法和变量放在一起,既没有用private设定可见性也没有充分封装。Poly类就更惨了,基本上是被当作了struct使用。即便是这样,Poly类还是封装了构造方法(类比于初始化struct的函数),合并方法以及字符串转化方法(没有重写toString是因为当时我不知道重写这个操作),相对于面向过程已经体现出面向对象强大的封装能力。
代码复杂性分析
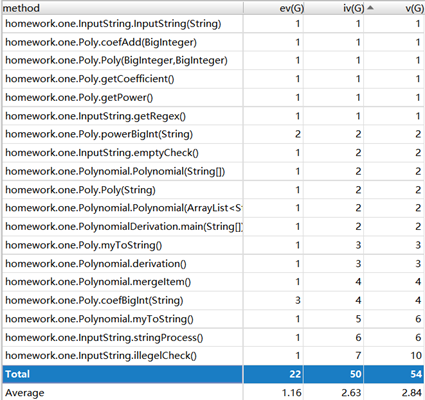
因为第一次作业不是很复杂,代码复杂性并不是很高。但是在合法性检查中使用了大量的分支语句,使代码复杂度增大,逻辑变得复杂,很有可能造成bug(事实上的确造成一个bug)。
bug分析
此次bug出现在合法性分析中,是由复杂的正则匹配逻辑所导致的。我的想法是合法的输入字符串是由合法的项字符串拼接而成的,那就可以把合法的项字符串全部删掉,如果还剩下非空白字符,那么这个字符串一定是不合法的。问题出在删除的过程中,将合法项字符串删除之后,我又将前后的剩余部分拼接在一起,这就导致前后的字符可能拼成新的合法项字符串。
该bug的错误样例确不好构造,在构建分类树时如果没有严谨全面的思维很难构造出这种情况。现在我的解决办法是在构造分类树时将已有的正确和错误类型进行组合,看能否构造出新的树节点。
Bug探寻
寻找WrongFormat bug, 例如\v,爆栈。利用分类树找到bug:-1*x^-1
第二次作业
程序分析
第二次作业的复杂性较第一次作业并没有增加多少,sin(x)和cos(x)作为原子因子出现,并未支持嵌套。但是第二次的代码量却增大很多,主要增大在输出优化上。
我的第二次作业的类图和类间依赖图如下:

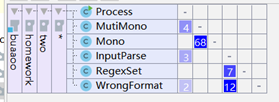
可以看到,第二次作业同样没有任何继承关系,这是因为我在第二次作业中采取了四元组保存项的设计思路,所以代码结构和第一次作业没有本质区别。值得一提的是,第二次作业用hashMap作为数据结构对于合并同类相有奇效。用四元组中x,sin,cos的幂集合生成key,将系数作为v,实现每个项都由因子的幂集合唯一编码,而系数只是项的可变属性。这个操作虽然无关于程序的整体设计,却体现了hash思想的精妙。第二次作业仍然面向过程的气息浓厚,很多方法写成面向过程的函数,例如MutiMono的mutiDerivation方法。但是面向对象的元素也比第一次更多。在类的依赖方面,因为多项式是由项组合而成,所以多项式类对单项式依赖性很强。实际上,多项式类是单项式类的一个聚合,体现出高内聚性低耦合性的特点。
代码复杂性分析
因为设计思路和整体框架与第一题差距不大,所以代码的复杂性差距不大。复杂度并不高,这是因为使用的是四元组思路而不是多态继承思路,再加上hashMap的操作,程序的控制流并不复杂。
bug分析
第二次作业被同学找出了一处bug,这处bug出现在化简的时候。化简时需要对项进行拆分和合并,有多重循环和一次添加或删除多个项的操作。如果以hashMap为基础执行这两项操作会造成bug,在删除项之后的遍历过程不可预期。
所以化简部分采用ArrayList数据结构。但是还是没有成功避免bug。因为确定项的编码是通过三个幂组成的集合。在删除时会多删除项,导致bug的产生。
Bug探寻
第二次探寻bug采用自己编写的对拍器。首先调用python的xeger库,生成合法的字符串。之后通过添加,替换,删除操作制造不合法字符串。系统调用java命令从而得到八个人的输出。用sympy对输出进行代值,再进行比较,如果八个人输出结果不同则将该次样例打印到标准输出。
这个简易测评机的效果不错,de出了一些bug,就是在寻找bug的原因时比较费力。
第三次作业
程序分析
第三次作业加入嵌套规则,使因子的原子性不复存在,从而使复杂性极大地增加。我的程序设计时间超过编程时间,但是却没精力做出输出优化。
我的第二次作业的类图和类间依赖图如下:
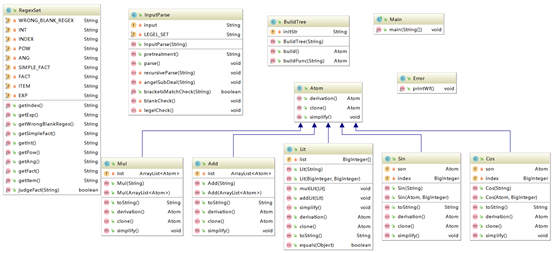

我的第三次作业体现出面向对象继承和多态的特性。Mul,Add,Sin,Cos,Lit都继承自Atom。继承结构如此单薄的原因是在设计的时候没有考虑到可以增加中间的继承层次,虽然在编码的时候发现这一点,但因为时间紧迫就没有添加。
在依赖矩阵图中会发现两处循环依赖。第一处循环依赖是因为处理嵌套字符串需要递归处理,递归方法在BulidTree类中,所以BulidTree类会依赖Atom的子类。当某项的因子是嵌套因子时,Atom的子类会调用BulidTree中的递归方法进行递归处理。所以在BulidTree和Atom子类之间形成循环依赖。第二处循环依赖是因为封装解耦的不够完善,代码内聚性不够强。一个本应该属于RegexSet的数据域被放在了InputParse中,导致两个类耦合性非常强。
代码复杂性分析

第三次作业方法过多,只放类的复杂度图。可以清晰的看到,输入处理类,加法乘法类和表达式树构建类过于复杂,在编程时没有对这三个类进行拆分、解耦和封装。例如加法类和乘法类多余地承担化简的功能,化简这个行为应该独立出来。
bug分析
第三次作业在强测和互测中没有被找出bug,故此部分略去。
Bug探寻
第三次探寻bug改进了对拍器。新版对拍器能生成嵌套的样例,增强了生成式的随机性。但是sympy库对表达式化简的能力有限,在输出化简格式不同的时候也会反馈,这是一个需要解决的问题。
我的面向对象思想发展
第一次作业
歪打正着的是,第一次作业实现了封装的原始形态。一般函数都有对可变数据域的依赖(完全不依赖可变数据域的函数不就进入到函数式编程的范畴了么?)。将数据域和与之相关的函数封装起来,就形成了对象。例如第一次作业中的的InputString类,当输入字符串被读入程序时,就要对输入字符串进行合法性检查,如果检查合法就要对字符串进行分割。到这里,涉及到的数据域有输入字符串,行为(函数)有合法性检查和分割。输入字符串是逃不过被合法性检查的命运的,也就是说,在我的第一次作业的程序中,输入字符串增加了一项普通字符串所不具备的属性——合法性。在字符串的大家族中,出现了一个新的种类:第一次作业合法输入字符串。第一次作业合法输入字符串之所以与众不同,是因为它具有合法性的属性,也是因为它是由项字符串拼接在一起。
若是采用面向过程的编程思想,合法性检查函数和分割函数会独立于输入字符串存在。输入字符串的特殊性只能体现在它会被这两个函数处理,体现在程序的控制流代码中。这两个函数也可以作用于其他种类的字符串,效果如何就不得而知了。输入字符串的特殊性存在于我们的脑中,感觉总是缺少什么,为什么输入字符串还是独立存在,又为什么这两个函数还可以随意的调来调去?
这时候就是封装大显神威的时候了:现在这两个函数和输入字符串结合成为对象。要想调用两个函数,它们的作用数据域只能是对象中的输入字符串。我们不但可以防止这两个函数被到处乱调,甚至可以用private来让这两个函数只用由我们自己调用(真的是嗨的不行,没想到编程领域也能弄只属于自己的小私产)。
到这里我得出一个结论:与数据相关的行为也是数据属性的一部分,数据和行为应该被封装在一起,形成类。
第二次作业
第二次作业在面向对象方面,虽然没有使用继承和多态,但是却在封装上前进了一步。首先,每个类都有作为类的基本的尊严:成为了某种对象的抽象。不再是简单地将数据和函数封装在一起,而是根据项和因子的模型抽象出类。每个类都的属性都是从实际对象中抽象而出,方法不再是单纯地为计算而设计,还考虑到描述对象地实际行为。
其次,上文提到了合法字符串输入实际上是由项字符串拼接而成,那么识别合法字符串的基础操作就是识别项字符串。所以第二次作业将正则表达式和识别方法封装为RegexSet类,这个类本质上是第二次作业因子识别类。这个类虽然在此次作业中只出现一次,并没有很好的起到代码复用的效果,但是它会在第三次作业中发挥它的作用。
这里提到了代码复用的问题,在面向过程和面向对象中都有代码复用,它们有什么不同呢?同样的,面向过程由于没有对数据域和方法的封装,代码复用大多体现在函数本身,也就是说是在利用函数完成重复操作的过程中完成复用;在面向对象中,代码复用由对象完成,具体是在对象与对象之间的交互中完成复用的。
第三次作业
第三次作业的Error类里面只有打印Wrong Format!的静态方法,为什么一个简单的方法会被封装为一个类呢?在这里我考虑到了面向对象的一个思维模式:专家模式。当程序发现字符串非法时,应该交给处理错误的“专家”来处理。打印Wrong Format!并退出程序就是专家的处理过程。虽然处理过程比较简单,但是将处理细节封装隐藏是面向对象思想重要的一环。
关于Atom继承和多态的应用补足我对面向对象特性的认识。前面通过对InputString类的分析,我得出结论:属性和行为的封装是对现实世界的抽象。那么,面向对象的多态和继承又的特性又有怎样的现实意义呢?
这里需要先引出令我困惑许久的问题:抽象类和抽象接口之间在很大程度上是可以相互取代的,它们的区别到底体现在哪呢?我们知道,如果接口被类拓展,该接口就会成为这个类的父类。接口和抽象类都可以作为父类,但是接口的变量只能是public static final的,其在对象属性抽象描述的能力上天生弱于抽象类。也就是说,java语言设计决定了接口最适合抽象描述对象的行为。到这里,抽象类和抽象接口之间的差别已经被找到:抽象类着重于描述对象的属性,而接口着重于描述对象的行为。
从抽象类和接口的区别我们就能发现面向对象背后的思维模式:两种抽象的事物分类方法。它们分别是通过属性分类和通过行为分类。两个事物的属性如果相同,我们就把它们抽象为类;两个事物的行为如果相同,我们就抽象出接口。对于属性和行为的抽象并不会考虑对象背后的原理,除非其原理是抽象的标准。
例如第三次作业中的RegexSet类,实际上是一个接口。RegexSet的所有变量都是public static final 的,所有方法都是一类抽象的行为——对表达式因子的分析。虽然在作业三中这个接口的作用比较局限,但实际上这个接口的抽象范围很广。在应用场景发生变化之后,即使Atom及其子类都不能适应新的要求,这个接口仍然很可能适用。
总结
三次作业,为我打开了面向对象的大门,让我对面向对象的思想有了初步的认识。
从这三次作业可以看出,我的编程思路还不是很清晰,在没想清楚的时候就下手编程,结果导致代码比较丑陋。在对自己代码中的问题进行总结反思过后,我发现在编程时需要增强结构性和封装程度。总之一句话:先思考,后编程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号