gunicorn
# gunicorn
一、gunicorn的简介
Gunicorn是基于unix系统,被广泛应用的高性能的Python WSGI HTTP Server。用来解析HTTP请求的网关服务。
它通常是在进行反向代理(如nginx),或者进行负载均衡(如 AWS ELB)和一个web 应用(比如 Django 或者 Flask)之间。
它的运行模型基于pre-fork worker 模型,即就是支持eventlet,也支持greenlet。
二、gunicorn特点
其特点:
- 能和大多数的Python Web框架兼容;
- 简单易上手;
- 轻量级的资源消耗;
- 目前,gunicorn只能运行在Linux环境中,不支持windows平台。
三、谈谈WSGI HTTP Server
所谓WSGI(Web Server Gateway Interface)。它不是web server,也不是web app;而正是为了将web和app解耦、再连接起来的一道桥梁。因为它是一种通用的接口规范,规定了web server(如Apache、Nginx)和web app(或web app框架)之间的标准。
因为如此,web app开发者就能专注于业务逻辑、专注于HTML文档的生成,而不用操心繁琐的网络底层实现(HTTP请求接收、建立连接、返回响应等),并能方便地组合搭配不同的web server + web app/框架了。

四、谈谈pre-fork worker model
worker model:意味着这个模型有一个master进程,来管理一组worker进程;
fork:意味着worker进程是由master进程fork(复刻)出来的;
pre-:意味着在任何客户端请求到来之前,就已从master进程fork出了多个worker进程,坐等请求到来;
执行流程:
在worker进程创建时,就被实例化了Python web app;并由worker进程监听端口、处理请求。当请求到来时,worker进程就能解析HTTP请求、调用Python web app处理、得到处理结果后,再整理成HTTP Response,通过TCP返回给客户端。
注:master进程不是管理处理请求的,只负责管理worker进程,比如对worker进程的创建、销毁、以及根据负载情况增减。(启动时设置的–workers参数只是worker数,而gunicorn还会创建个master进程。所以,即使配置workers为1,你的app也至少有两个进程:master负责管理,worker负责处理请求)。
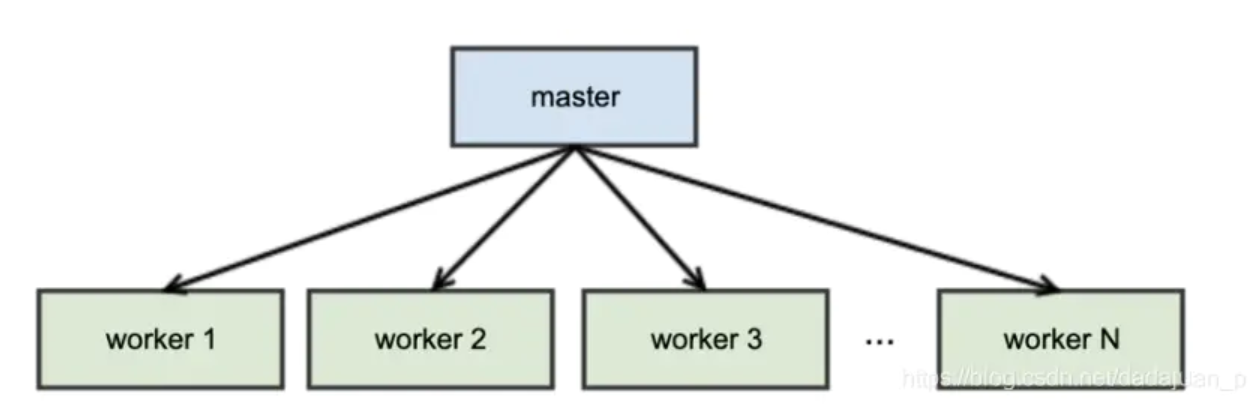
对于Gunicorn来说,gunicorn是WSGI的实现,但同时也自带web server,能直接对外提供web服务。包括大部分的web app框架,比如Flask和Django也都带有web server。
但是,在生产环境中,一般它们都是各司其职,Web框架Flask、Django只用于写app、Gunicorn只用于运行和管理Python web app,而在它们钱看有专门的web server,比如Nginx。
五、gunicorn的使用
gunicorn支持使用不同的worker进程类型,可通过worker-class参数配置。
启动后,gunicorn的所有worker共用一组listener(Gunicorn支持绑定多个socket,所以说是一组)。在启动worker时,worker内为每个listener创建一个WSGI server,接收HTTP请求,并调用app对象去处理请求。
gunicorn的工作模式一般分为同步worker使用和异步worker使用。
1、同步worker(Sync Worker)
默认的、最简单的worker模式,就是同步模式。
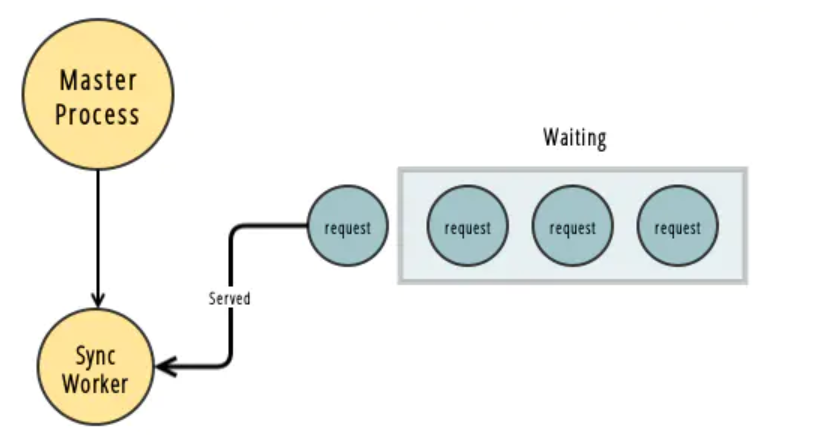
每个worker进程,一次只处理一个请求;如果此时又有其他请求被分配到了这个worker进程中,那只能被堵塞了,只能等待第一个请求完成。
并且,一个请求一个进程,并发时,是非常消耗CPU和内存的。
注:因此,只能适合在访问量不大、CPU密集而非I/O的情形。
但是也有好处,好处就是,即使一个worker的进程crash了,也只会影响到一个请求。不会影响其他的请求
2、异步workers(Async Worker)
异步worker有Gevent和Eventlet两种,都是基于Greenlet实现的。
当使用了异步worker,就能同时处理不止一个请求,就不会出现上面同步worker那样,当一个请求就把后续请求都block堵塞住了。
注:gunicorn允许通过设置对应的worker类来使用这些异步Python库。
例如:我们想在单核机器上运行的gevent:
gunicorn --worker-class=gevent --worker-connections=1000 --workers=3 main:app
解释:worker-connection 是对于 gevent worker 类的特殊设置。(2CPU)+1 仍然是建议的worker数量。
因为这里是单核,我们设置的是3个worker。在这种情况下,最大的并发请求数是3000(3个worker1000个连接数/worker)
六、gunicorn是如何实现高并发的?
对于gunicorn而言,当启动时,就已经把worker进程预先fork出来了。当多个请求到来的时候,会轮流复用这些worker进程,从而能提高服务器的并发负载能力。
对于worker数的配置,一般推荐2CPU数+1。这样一来,在任何时间,都有大概一般的worker是在做I/O,剩下一般才是需要CPU的。
如果在开多进程的同时,也开多线程(也就是选择gthread类型的worker),那么,配置总的并发数(worker进程数线程数),仍然建议2CPU数+1
七、gunicorn部署
gunicorn是一个wsgi http server。
1、首先需要安装gunicorn应用
【这里为cengtos7系统】
1.1、首先我们需要先创建虚拟环境
cd /opt/typhoonae
mkdir appenv
python3 -m appenv appenv
1.2、然后激活虚拟环境
source appenv/bin/activate
1.3、然后根据 requirements.txt 文件安装依赖包
pip3 install -r requirements.txt
1.4、安装gunicorn,安装直接可以使用pip
pip3 install gunicorn
1.5、在项目根目录下创建一个wsgi.py文件
from app import create_app
application = create_app('production')
if __name__ == '__main__':
application.run()
此时,不再通过manage.py启动服务,那只在开发的时候使用
然后启动服务:
gunicorn -w 4 -b 127.0.0.1:8000 wsgi:application
2、使用案例
一般情况下,在生产环境中,进程的启停和状态的监控最好应用supervisor之类的监控工具。然后在gunicorn的前端防止一个http proxy server,比如nginx。
例如:
下面是supervisor、gunicorn以及nginx的配置
2.1、supervisor_gunicorn.conf
[program:gunicorn_demo]
process_name=%(program_name)s
numprocs=1
priority=901
directory = /opt/gunicorn_demo/
command = /opt/virtualenv/bin/python /opt/virtualenv/bin/gunicorn -c gunicorn_demo.py gunicorn_demo:app
autostart = true
startsecs = 20
autorestart = true
startretries = 3
user = root
redirect_stderr = true
stdout_logfile_maxbytes = 20MB
stdout_logfile_backups = 10
stdout_logfile = /dev/null
-c gunicorn_demo.py,即就是gunicorn本身的配置文件.
2.2、gunicorn_demo.py 【gunicorn的基本配置文件】
import multiprocessing
bind = '127.0.0.1:8000'
workers = multiprocessing.cpu_count() * 2 + 1
backlog = 2048
worker_class = "gevent"
worker_connections = 1000
daemon = False
debug = True
proc_name = 'gunicorn_demo'
pidfile = './log/gunicorn.pid'
errorlog = './log/gunicorn.log'
注:gunicorn的配置文件必须为一个python文件,只是将命令行中的参数写进py文件中而已,如果需要设置哪个参数,则在py文件中为该参数赋值即可。
例如:
配置文件为example.py
#example.py
bind = "127.0.0.1:8000"
workers = 2
运行gunicorn命令为:
gunicorn -c example.py test:app
#等同于:
gunicorn -w 2 -b 127.0.0.1:8000 test:app
此时,当然了,配置文件还可以设置的更加复杂,根据实际情况而言:
假如:
配置文件为:gunicorn_test.py
#gunicorn_test.py
import logging
import logging.handlers
from logging.handlers import WatchedFileHandler
import os
import multiprocessing
bind = '127.0.0.1:8000' #绑定ip和端口号
backlog = 512 #监听队列
chdir = '/home/test/server/bin' #gunicorn要切换到的目的工作目录
timeout = 30 #超时
worker_class = 'gevent' #使用gevent模式,还可以使用sync 模式,默认的是sync模式
workers = multiprocessing.cpu_count() * 2 + 1 #进程数
threads = 2 #指定每个进程开启的线程数
loglevel = 'info' #日志级别,这个日志级别指的是错误日志的级别,而访问日志的级别无法设置
access_log_format = '%(t)s %(p)s %(h)s "%(r)s" %(s)s %(L)s %(b)s %(f)s" "%(a)s"' #设置gunicorn访问日志格式,错误日志无法设置
"""
其每个选项的含义如下:
h remote address
l '-'
u currently '-', may be user name in future releases
t date of the request
r status line (e.g. ``GET / HTTP/1.1``)
s status
b response length or '-'
f referer
a user agent
T request time in seconds
D request time in microseconds
L request time in decimal seconds
p process ID
"""
accesslog = "/home/test/server/log/gunicorn_access.log" #访问日志文件
errorlog = "/home/test/server/log/gunicorn_error.log" #错误日志文件
那么此时执行命令就为:
gunicorn -c gunicorn_test.py test:app
2.3、nginx.conf 的部分配置
server {
listen 80;
server_name sam_rui.com;
access_log /var/log/nginx/access.log;
location / {
proxy_pass http://127.0.0.1:8000;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
八、gunicorn相关参数说明
1)-c CONFIG,–config=CONFIG
指定一个配置文件(py文件)
2)-b BIND,–bind=BIND
与指定socket进行绑定
3)-D,–daemon
后台进程方式运行gunicorn进程
4)-w WORKERS,–workers=WORKERS
工作进程的数量
5)-k WORKERCLASS,–worker-class=WORKERCLASS
工作进程类型,包括sync(默认),eventlet,gevent,tornado,gthread,gaiohttp
6)–backlog INT
最大挂起的连接数
7)–log-level LEVEL
日志输出等级
8)–access-logfile FILE
访问日志输出文件
9)–error-logfile FILE
错误日志输出文件
gunicorn的参数详解
-c CONFIG : CONFIG,配置文件的路径,通过配置文件启动;生产环境使用;
-b ADDRESS : ADDRESS,ip加端口,绑定运行的主机;
-w INT, --workers INT:用于处理工作进程的数量,为正整数,默认为1;
-k STRTING, --worker-class STRTING:要使用的工作模式,默认为sync异步,可以下载eventlet和gevent并指定
--threads INT:处理请求的工作线程数,使用指定数量的线程运行每个worker。为正整数,默认为1。
--worker-connections INT:最大客户端并发数量,默认情况下这个值为1000。
--backlog int:未决连接的最大数量,即等待服务的客户的数量。默认2048个,一般不修改;
-p FILE, --pid FILE:设置pid文件的文件名,如果不设置将不会创建pid文件
--access-logfile FILE : 要写入的访问日志目录
--access-logformat STRING:要写入的访问日志格式
--error-logfile FILE, --log-file FILE : 要写入错误日志的文件目录。
--log-level LEVEL : 错误日志输出等级。
--limit-request-line INT : HTTP请求头的行数的最大大小,此参数用于限制HTTP请求行的允许大小,默认情况下,这个值为4094。值是0~8190的数字。
--limit-request-fields INT : 限制HTTP请求中请求头字段的数量。此字段用于限制请求头字段的数量以防止DDOS攻击,默认情况下,这个值为100,这个值不能超过32768
--limit-request-field-size INT : 限制HTTP请求中请求头的大小,默认情况下这个值为8190字节。值是一个整数或者0,当该值为0时,表示将对请求头大小不做限制
-t INT, --timeout INT:超过这么多秒后工作将被杀掉,并重新启动。一般设定为30秒;
--daemon: 是否以守护进程启动,默认false;
--chdir: 在加载应用程序之前切换目录;
--graceful-timeout INT:默认情况下,这个值为30,在超时(从接收到重启信号开始)之后仍然活着的工作将被强行杀死;一般使用默认;
--keep-alive INT:在keep-alive连接上等待请求的秒数,默认情况下值为2。一般设定在1~5秒之间。
--reload:默认为False。此设置用于开发,每当应用程序发生更改时,都会导致工作重新启动。
--spew:打印服务器执行过的每一条语句,默认False。此选择为原子性的,即要么全部打印,要么全部不打印;
--check-config :显示现在的配置,默认值为False,即显示。
-e ENV, --env ENV: 设置环境变量;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号