《Cross-Modal & Metric Learning 跨模态检索专题-1》学习
出处:https://zhuanlan.zhihu.com/p/115273380
文章脉络:
多模态研究背景,多模态研究两种套路,在工业界中注意transfer learning
1、多模态研究背景
为什么进行多模态研究?
世界是多元的,信息以各种模态出现,例如文字、图片、视频等等。为了对这些信息有更加充分的理解,需要对多模态信息进行统一的分析与处理。
多模态研究的应用方向
生成(Generate): 任务包括给定一张图片,生成一段文字来描述它(image caption);或者给定一段文字,生成一张图片(各种GAN)。
问答(VQA): 任务包括给定一张图片,让你进行相关的问答。
检索(Retrieval): 给定一个模态中的信号,找到另一个模态中最“接近”的几个信号。或者给定两个模态的信号,判断它们是否相关。
2、多模态研究两种套路
检索本质:"映射"这一跨模态检索的本质就是对不同模态的信号分别进行编码得到其语义表示 embedding,同时要建立一个度量方法用该距离来判断这些 embedding 之间的关系
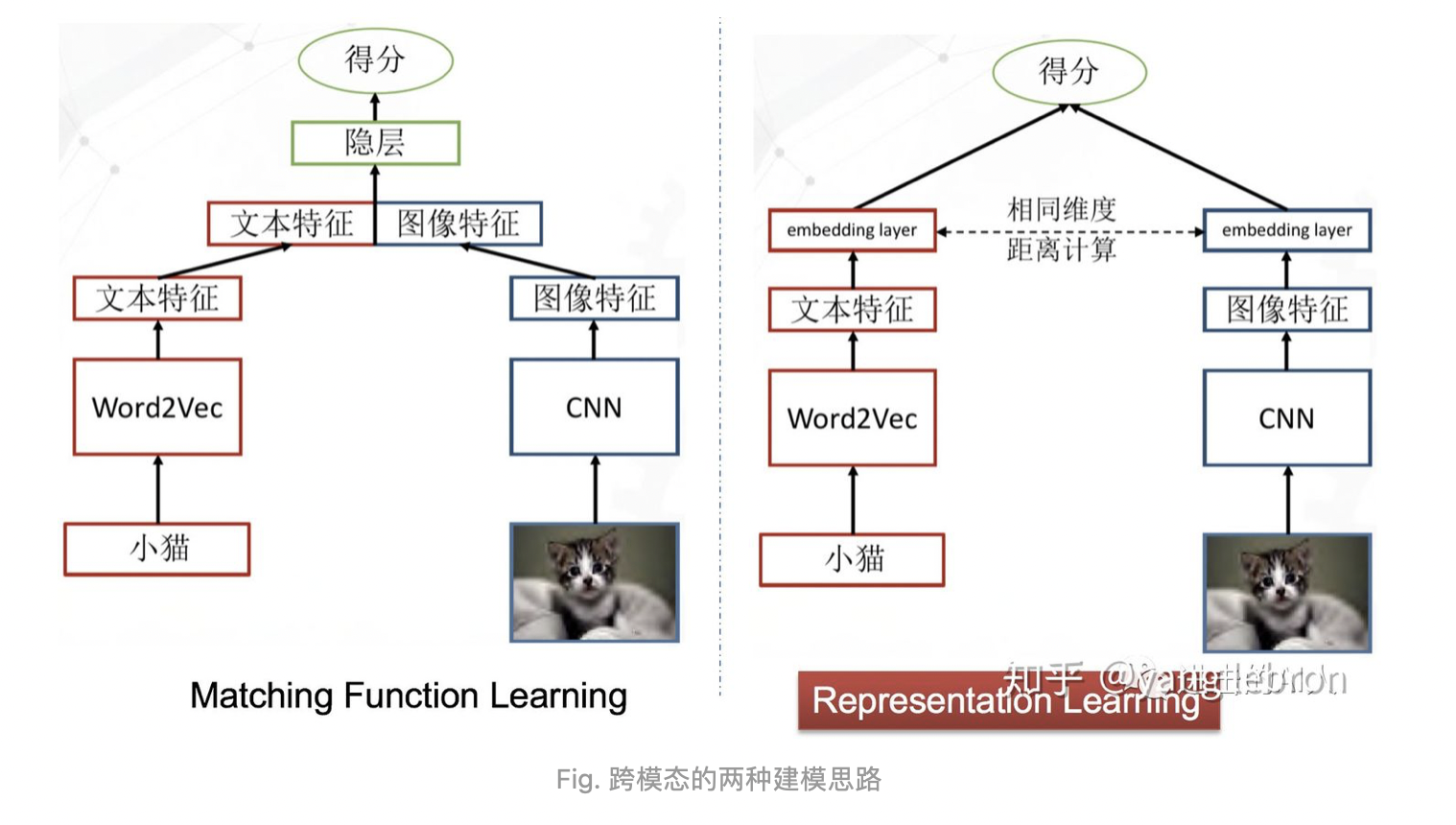
上图是两个极其简洁的图文跨模态匹配模型。虽然简洁,但是代表了这类问题的2种研究思路。后续发展出的一堆复杂的变形金刚模型,其本质还是依照上面这2个"套路"的指导。左侧模型的思想是,图文特征先融合,然后再过隐层,让隐层来学习出一个不可解释的跨模态距离函数,最终得到一个图文关系得分。右侧模型(一般称双塔结构)的思想是,图文特征分别计算得到最终顶层的 embedding,然后用可解释的距离函数(如 cosine、L2等)来约束图文关系。
3、实际工作中注意transfer learning
实际工作中,我们应重视借助 transfer learning 的能力来加速/提高模型的训练和效果。理论上,如果有足够的数据,train from scratch 也是可以的,比如文本就是用one-hot表示然后自己搞一套 word2vec。但是跨模态应用场景下,往往这种 pair 数据很难获得,因此需要更多的借助 pre-trained 模型。在一般情况下,把跨模态匹配问题变成了一个纯粹的空间映射问题(比如2048维的 resnet 图像特征空间 VS 768维的 bert 文本输出空间),这样会简化任务,得到一个基本"能用"的结果。
关键词:
模态中的信号
生成、问答、检索
语义表示embedding
双塔结构
2048维 resent 图像特征空间、768维bert文本输出空间

 浙公网安备 33010602011771号
浙公网安备 33010602011771号