MySQL Join算法与调优白皮书(一)
正文
Inside君发现很少有人能够完成讲明白MySQL的Join类型与算法,网上流传着的要提升Join性能,加大变量join_buffer_size的谬论更是随处可见。当然,也有一些无知的PGer攻击MySQL不支持Hash Join,所以不适合一些分析类的操作。MySQL的确不支持Hash Join,也不支持Sort Merge Join,但是MySQL在Join上也有自己的独特的优化与处理,此外,分支版本MariaDB已支持Hash Join,因此拿MySQL来做一些“简单”的分析查询也是完全能够接受的。当然,如果数据量真的上去了,那么即使支持Hash Join的传统MPP架构的关系型数据库可能也是不合适的,这类分析查询或许应该交给更为专业的Hadoop集群来计算。
Join的成本
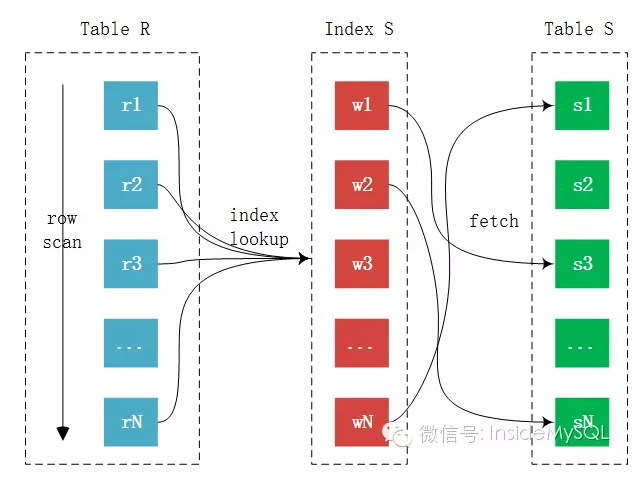
在讲述MySQL的Join类型与算法前,看看两张表的Join的过程:
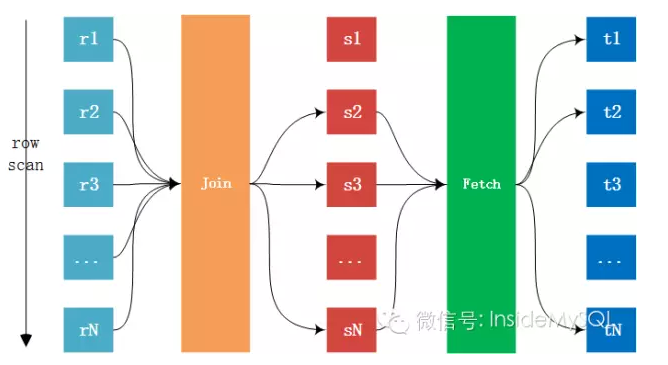
上图的Fetch阶段是指当内表关联的列是辅助索引时,但是需要访问表中的数据,那么这时就需要再访问主键索引才能得到数据的过程,不论表的存储引擎是InnoDB存储引擎还是MyISAM,这都是无法避免的,只是MyISAM的回表速度要快点,因为其辅助索引存放的就是指向记录的指针,而InnoDB存储引擎是索引组织表,需要再次通过索引查找才能定位数据。
Fetch阶段也不是必须存在的,如果是聚集索引链接,那么直接就能得到数据,无需回表,也就没有Fetch这个阶段。另外,上述给出了两张表之间的Join过程,多张表的Join就是继续上述这个过程。
接着计算两张表Join的成本,这里有下列几种概念:
外表的扫描次数,记为O。通常外表的扫描次数都是1,即Join时扫描一次驱动表的数据即可
内表的扫描次数,记为I。根据不同Join算法,内表的扫描次数不同
读取表的记录数,记为R。根据不同Join算法,读取记录的数量可能不同
Join的比较次数,记为M。根据不同Join算法,比较次数不同
回表的读取记录的数,记为F。若Join的是辅助索引,可能需要回表取得最终的数据
评判一个Join算法是否优劣,就是查看上述这些操作的开销是否比较小。当然,这还要考虑I/O的访问方式,顺序还是随机,总之Join的调优也是门艺术,并非想象的那么简单。
Simple Nested-Loop Join
网上大部分说MySQL只支持Nested-Loop Join,故性能差。但是Nested-Loop join一定差吗?Hash Join比Nested-Loop Join强?Inside君感觉这样的理解都是片面的,Hash Join可能仅是Nested-Loop Join的一种变种。所以Inside君打算从算法的角度来分析MySQL支持的Join,并以此分析对于Join语句的优化。
首先来看Simple Nested-Loop Join(以下简称SNLJ),也就是最朴素的Nested-Loop Join,其算法伪代码如下所示:
For each row r in R do
Foreach row s in S do
If r and s satisfy the join condition
Then output the tuple
下图能更好地显示整个SNLJ的过程:
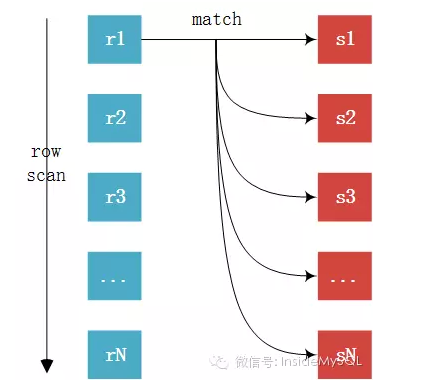
SNLJ的算法相当简单、直接。即外表(驱动表)中的每一条记录与内表中的记录进行判断。但是这个算法也是相当粗暴的,粗暴的原因在于这个算法的开销其实非常大。假设外表的记录数为R,内表的记录数位S,根据上一节Inside君对于Join算法的评判标准来看,SNLJ的开销如下表所示:

可以看到读取记录数的成本和比较次数的成本都是S*R,也就是笛卡儿积。假设外表内表都是1万条记录,那么其读取的记录数量和Join的比较次数都需要上亿。这样的算法开销,Inside君也只能:呵呵。
Index Nested-Loop Join
SNLJ算法虽然简单明了,但是也是相当的粗暴。因此,在Join的优化时候,通常都会建议在内表建立索引,以此降低Nested-Loop Join算法的开销,MySQL数据库中使用较多的就是这种算法,以下称为INLJ。来看这种算法的伪代码:
For each row r in R do
lookupr in S index
if found s == r
Then output the tuple
由于内表上有索引,所以比较的时候不再需要一条条记录进行比较,而可以通过索引来减少比较,从而加速查询。整个过程如下图所示:
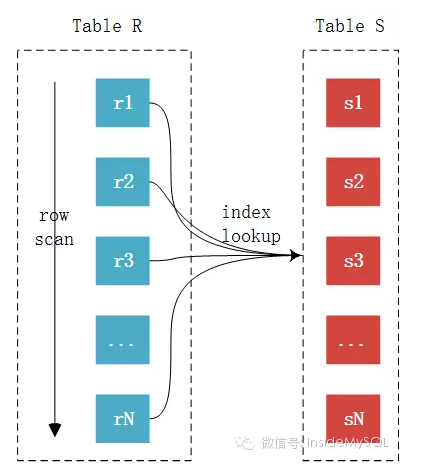
可以看到外表中的每条记录通过内表的索引进行访问,因为索引查询的成本是比较固定的,故优化器都倾向于使用记录数少的表作为外表(这里是否又会存在潜在的问题呢?)。故INLJ的算法成本如下表所示:
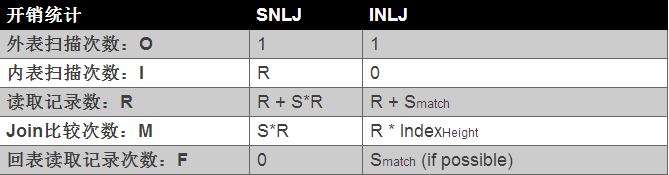
上表Smatch表示通过索引找到匹配的记录数量。同时可以发现,通过索引可以大幅降低内表的Join的比较次数,每次比较1条外表的记录,其实就是一次indexlookup(索引查找),而每次index lookup的成本就是树的高度,即IndexHeight。
INLJ的算法并不复杂,也算简单易懂。但是效率是否能达到用户的预期呢?其实如果是通过表的主键索引进行Join,即使是大数据量的情况下,INLJ的效率亦是相当不错的。因为索引查找的开销非常小,并且访问模式也是顺序的(假设大多数聚集索引的访问都是比较顺序的)。
大部分人诟病MySQL的INLJ慢,主要是因为在进行Join的时候可能用到的索引并不是主键的聚集索引,而是辅助索引,这时INLJ的过程又需要多一步Fetch的过程,而且这个过程开销会相当的大:
由于访问的是辅助索引,如果查询需要访问聚集索引上的列,那么必要需要进行回表取数据,看似每条记录只是多了一次回表操作,但这才是
由于访问的是辅助索引,如果查询需要访问聚集索引上的列,那么必要需要进行回表取数据,看似每条记录只是多了一次回表操作,但这才是INLJ算法最大的弊端。首先,辅助索引的index lookup是比较随机I/O访问操作。其次,根据index lookup再进行回表又是一个随机的I/O操作。所以说,INLJ最大的弊端是其可能需要大量的离散操作,这在SSD出现之前是最大的瓶颈。而即使SSD的出现大幅提升了随机的访问性能,但是对比顺序I/O,其还是慢了很多,依然不在一个数量级上。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号