
Redis缓存和数据库双写一致方案
Redis 和数据库读操作
数据缓存往往会在 Redis 上设置超时时间,当设置 Redis 的数据超时后,Redis 就没法读出数据了,这个时候就会触发程序读取数据库,然后将读取的数据库数据写入 Redis(此时会给 Redis 重设超时时间),这样程序在读取的过程中就能按一定的时间间隔刷新数据了,读取数据的流程如图 2 所示。
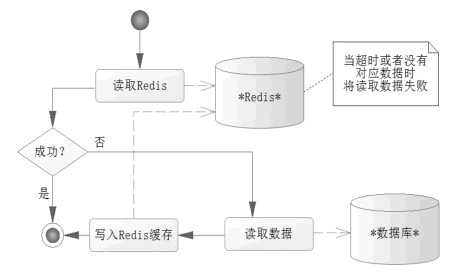
读取数据的流程
下面写出这个流程的伪代码:
public DataObject readMethod(args) { // 尝试从Redis中读取数据 DataObject data = getRedis(key); if(data != null) { // 读取数据返回为空,失败 // 从数据库中读取数据 data = getFromDataBase(); // 重新写入Redis,以便以后读出 writeRedis(key,data); // 设置Redis的超时时间为5分钟 setRedisExpire(key,5); } return data; }
这样每当读取 Redis 数据超过 5 分钟,Redis 就不能读到超时数据了,只能重新从 Redis 中读取,保证了一定的实时性,也避免了多次访问数据库造成的系统性能低下的情况。
Redis 和数据库写操作
写操作要考虑数据一致的问题,尤其是那些重要的业务数据,所以首先应该考虑从数据库中读取最新的数据,然后对数据进行操作,最后把数据写入 Redis 缓存中,如图 3 所示。
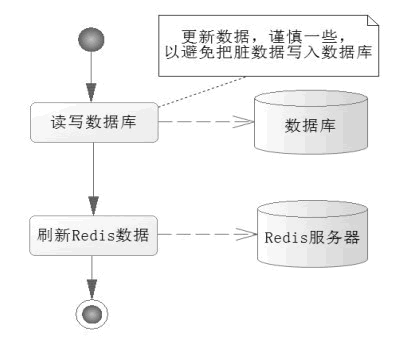
写入业务数据,先从数据库中读取最新数据,然后进行业务操作,更新业务数据到数据库后,再将数据刷新到 Redis 缓存中,这样就完成了一次写操作。这样的操作就能避免将脏数据写入数据库中,这类问题在操作时要注意。
下面写出这个流程的伪代码:
public DataObject writeMethod(args) { //从数据库里读取最新数据 DataObject dataObject = getFromDataBase(args); //执行业务逻辑 ExecLogic(dataObject); //更新数据库数据 updateDataBase(dataObject); //刷新Redis缓存 updateRedisData(dataObject); }
首先,从数据库中读取最新的数据,以规避缓存中的脏数据问题,执行了逻辑,修改了部分业务数据。然后,把这些数据保存到数据库里,最后,刷新这些数据到 Redis 中。
Cache Aside Pattern
写缓存同步也可以使用删除key的方式。这个用于可能缓存比较冷,并不常被读出的情景(内涵就是我都不读,你频繁写有啥好处呢,还不如直接删了等读的时候懒加载)
最经典的缓存+数据库读写的模式,就是 Cache Aside Pattern。
- 读的时候,先读缓存,缓存没有的话,就读数据库,然后取出数据后放入缓存,同时返回响应。
- 更新的时候,先更新数据库,然后再删除缓存。
为什么是删除缓存,而不是更新缓存?
原因很简单,很多时候,在复杂点的缓存场景,缓存不单单是数据库中直接取出来的值。
比如可能更新了某个表的一个字段,然后其对应的缓存,是需要查询另外两个表的数据并进行运算,才能计算出缓存最新的值的。
另外更新缓存的代价有时候是很高的。是不是说,每次修改数据库的时候,都一定要将其对应的缓存更新一份?也许有的场景是这样,但是对于比较复杂的缓存数据计算的场景,就不是这样了。如果你频繁修改一个缓存涉及的多个表,缓存也频繁更新。但是问题在于,这个缓存到底会不会被频繁访问到?
举个栗子,一个缓存涉及的表的字段,在 1 分钟内就修改了 20 次,或者是 100 次,那么缓存更新 20 次、100 次;但是这个缓存在 1 分钟内只被读取了 1 次,有大量的冷数据。实际上,如果你只是删除缓存的话,那么在 1 分钟内,这个缓存不过就重新计算一次而已,开销大幅度降低。用到缓存才去算缓存。
Cache Aside Pattern带来的脏读风险
数据发生了变更,先删除了缓存,然后要去修改数据库,此时还没修改。一个请求过来,去读缓存,发现缓存空了,去查询数据库,查到了修改前的旧数据,放到了缓存中。随后数据变更的程序完成了数据库的修改。完了,数据库和缓存中的数据不一样了...
只有在对一个数据在并发的进行读写的时候,才可能会出现这种问题。其实如果说你的并发量很低的话,特别是读并发很低,每天访问量就 1 万次,那么很少的情况下,会出现刚才描述的那种不一致的场景。但是问题是,如果每天的是上亿的流量,每秒并发读是几万,每秒只要有数据更新的请求,就可能会出现上述的数据库+缓存不一致的情况。
解决方案如下:
1、按照先修改数据库再修改缓存来实现(即不删除缓存)
2、用zookeeper或者redis建一个key标记,说明这个修改(数据库)行为还没结束,先锁住,等(修改成功)结束了再释放锁,读的时候自然是新的数据,在锁住的时候让客户端延迟读。
目前维护的开源产品:https://gitee.com/475660

 浙公网安备 33010602011771号
浙公网安备 33010602011771号