SpringBoot结合ShardingSphere实现分库分表、读写分离
这次在上一篇的基础上,这次用到4个库,将库db0、db1各增加一个从库dbS0\dbS1
四个库再执行脚本:
-- ----------------------------
-- Table structure for `user0`
-- ----------------------------
DROP TABLE IF EXISTS `user0`;
CREATE TABLE `user0` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(10) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=105 DEFAULT CHARSET=utf8mb4;
-- ----------------------------
-- Records of user0
-- ----------------------------
INSERT INTO `user0` VALUES ('1', 'wangxin02', '99');
-- ----------------------------
-- Table structure for `user1`
-- ----------------------------
DROP TABLE IF EXISTS `user1`;
CREATE TABLE `user1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(10) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1000 DEFAULT CHARSET=utf8mb4;
-- ----------------------------
-- Records of user1
-- ----------------------------
INSERT INTO `user1` VALUES ('1', 'wangxin', '99');
只分表不分库
首先先只分表不分库,使用master来执行写操作
核心配置
#数据分表规则--仅分表不分库 #注意:tables.user中的user是逻辑表 #指定所需分的表,分user1、user2 spring.shardingsphere.sharding.tables.user.actual-data-nodes=master.user$->{0..1} #行表达式分片策略 spring.shardingsphere.sharding.tables.user.table-strategy.inline.sharding-column=id #分表两个,所以规则为主键除以2取模 spring.shardingsphere.sharding.tables.user.table-strategy.inline.algorithm-expression=user$->{id % 2} ##用于单分片键的标准分片场景 ##指定自增主键 #spring.shardingsphere.sharding.tables.user.key-generator.column= id ##自增列值生成器类型,缺省表示使用默认自增列值生成器。可使用用户自定义的列值生成器或选择内置类型:SNOWFLAKE/UUID #spring.shardingsphere.sharding.tables.user.key-generator.type= SNOWFLAKE
map新增
<insert id="insertSharding" parameterType="com.xin.shardingspherejdbcdemo.entity.User"> insert into user (id,name, age) values ( #{id,jdbcType=INTEGER},#{name,jdbcType=VARCHAR}, #{age,jdbcType=INTEGER}) </insert>
控制器新增
@GetMapping("/saveUserShardingOnlyTable")
public void saveUserShardingOnlyTable() {
List<User> userList = Lists.newArrayList();
userList.add(new User(100,"用户1", 31));
userList.add(new User(101,"用户2", 30));
userList.add(new User(102,"用户3", 28));
userList.add(new User(103,"用户4", 64));
userList.add(new User(104,"用户5", 62));
userList.add(new User(105,"用户6", 16));
for (User u : userList){
userService.saveSharding(u);
}
}
执行saveUserShardingOnlyTable后,我们发现db0中的两个表分别加入了3条记录
user0加入:
100 用户1 31
102 用户3 28
104 用户5 62
user1加入:
101 用户2 30
103 用户4 64
105 用户6 16
日志:


2020-05-22 14:33:33.807 INFO 9952 --- [nio-8086-exec-1] ShardingSphere-SQL : Actual SQL: master ::: insert into user0 (id,name, age) values (?, ?, ?) ::: [100, 用户1, 31] 2020-05-22 14:33:33.944 INFO 9952 --- [nio-8086-exec-1] ShardingSphere-SQL : Rule Type: sharding 2020-05-22 14:33:33.945 INFO 9952 --- [nio-8086-exec-1] ShardingSphere-SQL : Logic SQL: insert into user (id,name, age) values ( ?,?, ?) 2020-05-22 14:33:33.945 INFO 9952 --- [nio-8086-exec-1] ShardingSphere-SQL : SQLStatement: InsertSQLStatementContext(super=CommonSQLStatementContext(sqlStatement=org.apache.shardingsphere.sql.parser.sql.statement.dml.InsertStatement@8a9d30d, tablesContext=TablesContext(tables=[Table(name=user, alias=Optional.absent())], schema=Optional.absent())), columnNames=[id, name, age], insertValueContexts=[InsertValueContext(parametersCount=3, valueExpressions=[ParameterMarkerExpressionSegment(startIndex=45, stopIndex=45, parameterMarkerIndex=0), ParameterMarkerExpressionSegment(startIndex=47, stopIndex=47, parameterMarkerIndex=1), ParameterMarkerExpressionSegment(startIndex=56, stopIndex=56, parameterMarkerIndex=2)], parameters=[101, 用户2, 30])]) 2020-05-22 14:33:33.945 INFO 9952 --- [nio-8086-exec-1] ShardingSphere-SQL : Actual SQL: master ::: insert into user1 (id,name, age) values (?, ?, ?) ::: [101, 用户2, 30] 2020-05-22 14:33:33.985 INFO 9952 --- [nio-8086-exec-1] ShardingSphere-SQL : Rule Type: sharding 2020-05-22 14:33:33.985 INFO 9952 --- [nio-8086-exec-1] ShardingSphere-SQL : Logic SQL: insert into user (id,name, age) values ( ?,?, ?) 2020-05-22 14:33:33.985 INFO 9952 --- [nio-8086-exec-1] ShardingSphere-SQL : SQLStatement: InsertSQLStatementContext(super=CommonSQLStatementContext(sqlStatement=org.apache.shardingsphere.sql.parser.sql.statement.dml.InsertStatement@8a9d30d, tablesContext=TablesContext(tables=[Table(name=user, alias=Optional.absent())], schema=Optional.absent())), columnNames=[id, name, age], insertValueContexts=[InsertValueContext(parametersCount=3, valueExpressions=[ParameterMarkerExpressionSegment(startIndex=45, stopIndex=45, parameterMarkerIndex=0), ParameterMarkerExpressionSegment(startIndex=47, stopIndex=47, parameterMarkerIndex=1), ParameterMarkerExpressionSegment(startIndex=56, stopIndex=56, parameterMarkerIndex=2)], parameters=[102, 用户3, 28])]) 2020-05-22 14:33:33.985 INFO 9952 --- [nio-8086-exec-1] ShardingSphere-SQL : Actual SQL: master ::: insert into user0 (id,name, age) values (?, ?, ?) ::: [102, 用户3, 28] 2020-05-22 14:33:34.043 INFO 9952 --- [nio-8086-exec-1] ShardingSphere-SQL : Rule Type: sharding 2020-05-22 14:33:34.043 INFO 9952 --- [nio-8086-exec-1] ShardingSphere-SQL : Logic SQL: insert into user (id,name, age) values ( ?,?, ?) 2020-05-22 14:33:34.043 INFO 9952 --- [nio-8086-exec-1] ShardingSphere-SQL : SQLStatement: InsertSQLStatementContext(super=CommonSQLStatementContext(sqlStatement=org.apache.shardingsphere.sql.parser.sql.statement.dml.InsertStatement@8a9d30d, tablesContext=TablesContext(tables=[Table(name=user, alias=Optional.absent())], schema=Optional.absent())), columnNames=[id, name, age], insertValueContexts=[InsertValueContext(parametersCount=3, valueExpressions=[ParameterMarkerExpressionSegment(startIndex=45, stopIndex=45, parameterMarkerIndex=0), ParameterMarkerExpressionSegment(startIndex=47, stopIndex=47, parameterMarkerIndex=1), ParameterMarkerExpressionSegment(startIndex=56, stopIndex=56, parameterMarkerIndex=2)], parameters=[103, 用户4, 64])]) 2020-05-22 14:33:34.043 INFO 9952 --- [nio-8086-exec-1] ShardingSphere-SQL : Actual SQL: master ::: insert into user1 (id,name, age) values (?, ?, ?) ::: [103, 用户4, 64]
分库 + 分表同时进行
核心配置
server.port=8086 #指定mybatis信息 mybatis.config-location=classpath:mybatis-config.xml # 数据源 主库、从库 -- 读写分离 #spring.shardingsphere.datasource.names=master,slave0 # 数据源 主库 --仅分表不分库 #spring.shardingsphere.datasource.names=master # 数据源 主库db0、主库db1 -- 分库分表 spring.shardingsphere.datasource.names=master0,master1 # 数据源 主库 spring.shardingsphere.datasource.master0.type=com.alibaba.druid.pool.DruidDataSource spring.shardingsphere.datasource.master0.driver-class-name=com.mysql.jdbc.Driver spring.shardingsphere.datasource.master0.url=jdbc:mysql://localhost:3307/db0?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai spring.shardingsphere.datasource.master0.username=root spring.shardingsphere.datasource.master0.password=mysql # 数据源 主库 spring.shardingsphere.datasource.master1.type=com.alibaba.druid.pool.DruidDataSource spring.shardingsphere.datasource.master1.driver-class-name=com.mysql.jdbc.Driver spring.shardingsphere.datasource.master1.url=jdbc:mysql://localhost:3307/db1?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai spring.shardingsphere.datasource.master1.username=root spring.shardingsphere.datasource.master1.password=mysql # 数据源 从库 spring.shardingsphere.datasource.slave0.type=com.alibaba.druid.pool.DruidDataSource spring.shardingsphere.datasource.slave0.driver-class-name=com.mysql.jdbc.Driver spring.shardingsphere.datasource.slave0.url=jdbc:mysql://localhost:3307/db1?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai spring.shardingsphere.datasource.slave0.username=root spring.shardingsphere.datasource.slave0.password=mysql ## 读写分离 ##spring.shardingsphere.masterslave.load-balance-algorithm-type=round_robin #spring.shardingsphere.masterslave.name=ms #spring.shardingsphere.masterslave.master-data-source-name=master #spring.shardingsphere.masterslave.slave-data-source-names=slave0 ## 分库 #根据ID分库 #spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=id #spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=master$->{id % 2} #根据年龄分库 spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=age spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=master$->{age > 30?0:1} #数据分表规则--仅分表不分库 #注意:tables.user中的user是逻辑表 #仅分表时使用,单一写表,指定所需分的表,分user1、user2 #spring.shardingsphere.sharding.tables.user.actual-data-nodes=master.user$->{0..1} #同时分库分表时使用 spring.shardingsphere.sharding.tables.user.actual-data-nodes=master$->{0..1}.user$->{0..1} #行表达式分片策略 spring.shardingsphere.sharding.tables.user.table-strategy.inline.sharding-column=id #分表两个,所以规则为主键除以2取模 spring.shardingsphere.sharding.tables.user.table-strategy.inline.algorithm-expression=user$->{id % 2} ##用于单分片键的标准分片场景 ##指定自增主键 #spring.shardingsphere.sharding.tables.user.key-generator.column= id ##自增列值生成器类型,缺省表示使用默认自增列值生成器。可使用用户自定义的列值生成器或选择内置类型:SNOWFLAKE/UUID #spring.shardingsphere.sharding.tables.user.key-generator.type= SNOWFLAKE #打印sql spring.shardingsphere.props.sql.show=true
控制器
@GetMapping("/saveUserShardingDBwithTable")
public void saveUserShardingDBwithTable() {
List<User> userList = Lists.newArrayList();
userList.add(new User(10000,"用户1", 31));
userList.add(new User(10001,"用户2", 30));
userList.add(new User(10002,"用户3", 28));
userList.add(new User(10003,"用户4", 64));
userList.add(new User(10004,"用户5", 62));
userList.add(new User(10005,"用户6", 16));
for (User u : userList){
userService.saveSharding(u);
}
}
分库分表+读写分离
只需要在上面的基础上添加读写分离的配置即可
#指定master0为主库,slave0为它的从库 spring.shardingsphere.sharding.master-slave-rules.master0.master-data-source-name=master0 spring.shardingsphere.sharding.master-slave-rules.master0.slave-data-source-names=slave0 #指定master1为主库,slave1为它的从库 spring.shardingsphere.sharding.master-slave-rules.master1.master-data-source-name=master1 spring.shardingsphere.sharding.master-slave-rules.master1.slave-data-source-names=slave1
完整配置说明
数据分片 spring.shardingsphere.datasource.names= #数据源名称,多数据源以逗号分隔 spring.shardingsphere.datasource.<data-source-name>.type= #数据库连接池类名称 spring.shardingsphere.datasource.<data-source-name>.driver-class-name= #数据库驱动类名 spring.shardingsphere.datasource.<data-source-name>.url= #数据库url连接 spring.shardingsphere.datasource.<data-source-name>.username= #数据库用户名 spring.shardingsphere.datasource.<data-source-name>.password= #数据库密码 spring.shardingsphere.datasource.<data-source-name>.xxx= #数据库连接池的其它属性 spring.shardingsphere.sharding.tables.<logic-table-name>.actual-data-nodes= #由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持inline表达式。缺省表示使用已知数据源与逻辑表名称生成数据节点,用于广播表(即每个库中都需要一个同样的表用于关联查询,多为字典表)或只分库不分表且所有库的表结构完全一致的情况 #分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一 #用于单分片键的标准分片场景 spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.standard.sharding-column= #分片列名称 spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.standard.precise-algorithm-class-name= #精确分片算法类名称,用于=和IN。该类需实现PreciseShardingAlgorithm接口并提供无参数的构造器 spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.standard.range-algorithm-class-name= #范围分片算法类名称,用于BETWEEN,可选。该类需实现RangeShardingAlgorithm接口并提供无参数的构造器 #用于多分片键的复合分片场景 spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.complex.sharding-columns= #分片列名称,多个列以逗号分隔 spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.complex.algorithm-class-name= #复合分片算法类名称。该类需实现ComplexKeysShardingAlgorithm接口并提供无参数的构造器 #行表达式分片策略 spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.inline.sharding-column= #分片列名称 spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.inline.algorithm-expression= #分片算法行表达式,需符合groovy语法 #Hint分片策略 spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.hint.algorithm-class-name= #Hint分片算法类名称。该类需实现HintShardingAlgorithm接口并提供无参数的构造器 #分表策略,同分库策略 spring.shardingsphere.sharding.tables.<logic-table-name>.table-strategy.xxx= #省略 spring.shardingsphere.sharding.tables.<logic-table-name>.key-generator.column= #自增列名称,缺省表示不使用自增主键生成器 spring.shardingsphere.sharding.tables.<logic-table-name>.key-generator.type= #自增列值生成器类型,缺省表示使用默认自增列值生成器。可使用用户自定义的列值生成器或选择内置类型:SNOWFLAKE/UUID spring.shardingsphere.sharding.tables.<logic-table-name>.key-generator.props.<property-name>= #属性配置, 注意:使用SNOWFLAKE算法,需要配置worker.id与max.tolerate.time.difference.milliseconds属性。若使用此算法生成值作分片值,建议配置max.vibration.offset属性 spring.shardingsphere.sharding.binding-tables[0]= #绑定表规则列表 spring.shardingsphere.sharding.binding-tables[1]= #绑定表规则列表 spring.shardingsphere.sharding.binding-tables[x]= #绑定表规则列表 spring.shardingsphere.sharding.broadcast-tables[0]= #广播表规则列表 spring.shardingsphere.sharding.broadcast-tables[1]= #广播表规则列表 spring.shardingsphere.sharding.broadcast-tables[x]= #广播表规则列表 spring.shardingsphere.sharding.default-data-source-name= #未配置分片规则的表将通过默认数据源定位 spring.shardingsphere.sharding.default-database-strategy.xxx= #默认数据库分片策略,同分库策略 spring.shardingsphere.sharding.default-table-strategy.xxx= #默认表分片策略,同分表策略 spring.shardingsphere.sharding.default-key-generator.type= #默认自增列值生成器类型,缺省将使用org.apache.shardingsphere.core.keygen.generator.impl.SnowflakeKeyGenerator。可使用用户自定义的列值生成器或选择内置类型:SNOWFLAKE/UUID spring.shardingsphere.sharding.default-key-generator.props.<property-name>= #自增列值生成器属性配置, 比如SNOWFLAKE算法的worker.id与max.tolerate.time.difference.milliseconds spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.master-data-source-name= #详见读写分离部分 spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.slave-data-source-names[0]= #详见读写分离部分 spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.slave-data-source-names[1]= #详见读写分离部分 spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.slave-data-source-names[x]= #详见读写分离部分 spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.load-balance-algorithm-class-name= #详见读写分离部分 spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.load-balance-algorithm-type= #详见读写分离部分 spring.shardingsphere.props.sql.show= #是否开启SQL显示,默认值: false spring.shardingsphere.props.executor.size= #工作线程数量,默认值: CPU核数 读写分离 #省略数据源配置,与数据分片一致 spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.master-data-source-name= #主库数据源名称 spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.slave-data-source-names[0]= #从库数据源名称列表 spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.slave-data-source-names[1]= #从库数据源名称列表 spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.slave-data-source-names[x]= #从库数据源名称列表 spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.load-balance-algorithm-class-name= #从库负载均衡算法类名称。该类需实现MasterSlaveLoadBalanceAlgorithm接口且提供无参数构造器 spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.load-balance-algorithm-type= #从库负载均衡算法类型,可选值:ROUND_ROBIN,RANDOM。若`load-balance-algorithm-class-name`存在则忽略该配置 spring.shardingsphere.props.sql.show= #是否开启SQL显示,默认值: false spring.shardingsphere.props.executor.size= #工作线程数量,默认值: CPU核数 spring.shardingsphere.props.check.table.metadata.enabled= #是否在启动时检查分表元数据一致性,默认值: false 数据脱敏 #省略数据源配置,与数据分片一致 spring.shardingsphere.encrypt.encryptors.<encryptor-name>.type= #加解密器类型,可自定义或选择内置类型:MD5/AES spring.shardingsphere.encrypt.encryptors.<encryptor-name>.props.<property-name>= #属性配置, 注意:使用AES加密器,需要配置AES加密器的KEY属性:aes.key.value spring.shardingsphere.encrypt.tables.<table-name>.columns.<logic-column-name>.plainColumn= #存储明文的字段 spring.shardingsphere.encrypt.tables.<table-name>.columns.<logic-column-name>.cipherColumn= #存储密文的字段 spring.shardingsphere.encrypt.tables.<table-name>.columns.<logic-column-name>.assistedQueryColumn= #辅助查询字段,针对ShardingQueryAssistedEncryptor类型的加解密器进行辅助查询 spring.shardingsphere.encrypt.tables.<table-name>.columns.<logic-column-name>.encryptor= #加密器名字
后台原理
ShardingSphere的核心由SQL解析 => 执行器优化 => SQL路由 => SQL改写 => SQL执行 => 结果归并的流程组成。
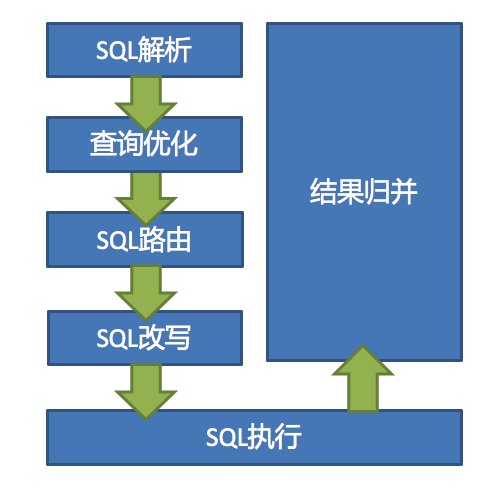
SQL解析
分为词法解析和语法解析。 先通过词法解析器将SQL拆分为一个个不可再分的单词。再使用语法解析器对SQL进行理解,并最终提炼出解析上下文。 解析上下文包括表、选择项、排序项、分组项、聚合函数、分页信息、查询条件以及可能需要修改的占位符的标记。
执行器优化
合并和优化分片条件,如OR等。
SQL路由
根据解析上下文匹配用户配置的分片策略,并生成路由路径。目前支持分片路由和广播路由。
SQL改写
将SQL改写为在真实数据库中可以正确执行的语句。SQL改写分为正确性改写和优化改写。
SQL执行
通过多线程执行器异步执行。
结果归并
将多个执行结果集归并以便于通过统一的JDBC接口输出。结果归并包括流式归并、内存归并和使用装饰者模式的追加归并这几种方式。
具体见:https://shardingsphere.apache.org/document/current/cn/features/sharding/principle/
全部源码
目前维护的开源产品:https://gitee.com/475660

 浙公网安备 33010602011771号
浙公网安备 33010602011771号