Cassandra开发入门文档第一部分
Cassandra的特点
横向可扩展性:
Cassandra部署具有几乎无限的存储和处理数据的能力。当需要额外的容量时,可以简单地将更多的机器添加到集群中。当新机器加入集群时,Cassandra需要对现有数据进行重新平衡,以使扩展集群中的每个节点具有大致相等的份额。而且,Cassandra集群的性能与集群内的节点数成正比。当您继续添加实例时,读写吞吐量将保持线性增长。
高可用性:
Cassandra集群中的所有节点都是没有主节点的对等节点。如果一台机器变得不可用,Cassandra将继续向与该机器共享数据的其他节点写入数据,并在失败的节点重新加入集群时对操作进行排队和更新。这意味着在一个典型的配置中,多个节点必须同时发生故障,才能在Cassandra的可用性中出现任何应用程序可见的中断。
写优化:
传统的关系数据库和文档数据库针对读取性能进行了优化。将数据写入关系数据库通常涉及对磁盘上的复杂数据结构进行就地更新,以便维护能够高效灵活地读取的数据结构。从磁盘I/O的角度来看,更新这些数据结构是一项非常昂贵的操作,而磁盘I/O通常是数据库性能的限制因素。由于写操作比读操作更昂贵,因此通常会避免对关系数据库进行任何不必要的更新,即使以额外的读操作为代价。
另一方面,Cassandra对写吞吐量进行了高度优化,事实上,它从不修改磁盘上的数据;它只附加到现有文件或创建新文件。这在磁盘I/O上要容易得多,这意味着Cassandra可以提供惊人的高写吞吐量。由于向Cassandra写入数据和在Cassandra中存储数据都很便宜,因此非规范化成本很低,是确保在各种访问场景中可以有效读取数据的好方法。
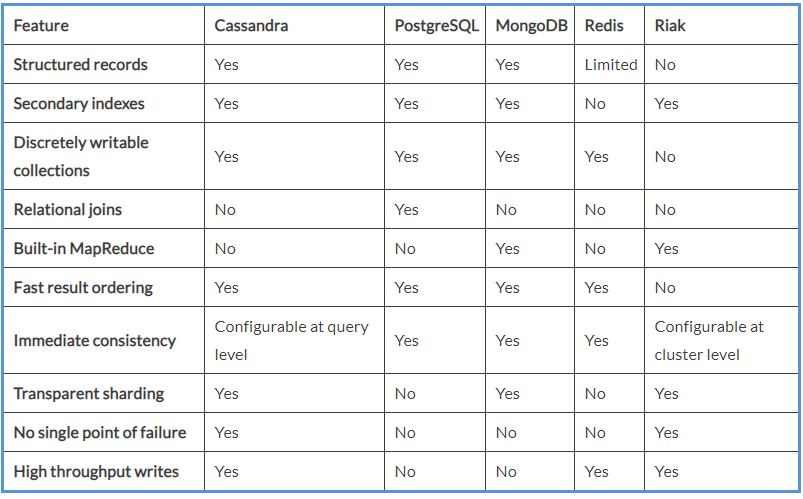
结构化记录:
我们看到的前三个数据库特性通常出现在分布式数据存储中。然而,诸如Riak和Voldemort这样的数据库纯粹是键值存储;这些数据库不知道存储在特定键中的记录的内部结构。这意味着诸如只更新记录的一部分、只读取记录中的某些字段或检索在给定字段中包含特定值的记录等有用的功能是不可能的。
二级索引:
二级索引(通常在关系数据库上下文中称为索引)是一种允许通过主键以外的某些属性高效查找记录的结构。这是一个非常有用的功能;例如,在开发blog应用程序时,您希望能够轻松检索特定作者编写的所有文章。Cassandra支持二级索引;虽然Cassandra的版本不像典型关系数据库中的索引那样通用,但在适当的情况下它是一个强大的功能。在某些情况下,对二级索引的查询可能执行得很差;因此,应该谨慎地使用它,并且只在某些情况下使用。
物化视图:
Cassandra3.0之前,查询非主键列的唯一方法是创建一个辅助索引并对其进行查询。但是,如果二级索引包含高基数数据,则二级索引具有性能权衡。通常,高基数的辅助索引必须扫描所有节点上的数据并聚合它们以返回查询结果。这违背了拥有分布式系统的目的。
为了避免二次索引和客户端非规范化,Cassandra引入了物化视图的特性,实现了服务器端的非规范化。
有效排序:
检索按特定字段排序的记录集是很常见的;例如,照片共享服务将按创建的降序检索最新的照片。由于对数据进行动态排序是一项非常昂贵的操作,因此数据库必须将有关记录排序的信息保存在磁盘上,以便有效地按顺序返回结果。在关系数据库中,这是辅助索引的作业之一。
在Cassandra中,二级索引不能用于结果排序,但是可以对表进行结构化,使行始终按给定的一列或多列进行排序,称为聚类列。在读取时按任意列排序是不可能的,但对于分布式数据库来说,高效地以任何方式对记录排序并根据这种排序检索记录范围的能力是一种异常强大的能力。
即时一致性:
当我们将一段数据写入数据库时,我们希望该数据可以立即提供给任何其他可能希望读取它的进程。从另一个角度来看,当我们从数据库中读取一些数据时,我们希望得到保证,我们检索的数据是最近更新的版本。这种保证称为即时一致性,它是大多数常见的单主数据库(如MySQL和PostgreSQL)的属性。
像Cassandra这样的分布式系统通常不能提供即时的一致性保证。相反,开发人员必须愿意接受最终的一致性,这意味着当数据更新时,系统将在未来某个时刻反映更新。开发人员之所以愿意放弃即时一致性,正是因为这是对高可用性的直接权衡。
在Cassandra的例子中,这种取舍是通过可调的一致性来明确的。每次为数据设计写或读路径时,您都可以选择立即一致性(与弹性较差的可用性保持一致),或最终一致性(与弹性极高的可用性保持一致)。
离散可写集合:
虽然将记录内部构造为离散字段很有用,但记录的给定属性并不总是单个值,例如字符串或整数。处理包含值集合的字段的一种简单方法是使用JSON等格式对其进行序列化,然后将序列化的集合保存到文本字段中。但是,为了更新以这种方式存储的集合,必须从数据库中读取序列化的数据,对其进行解码、修改,然后将其全部写回数据库。如果两个客户端同时尝试对同一记录执行此类修改,则其中一个更新将被另一个覆盖。由于这个原因,许多数据库提供了可以离散更新的内置集合结构:可以在不读取和重写整个集合的情况下向集合添加值或从集合中删除值。Cassandra也不例外,它提供list、set和map集合,并支持将数字3追加到列表末尾等操作。客户机和Cassandra本身都不需要读取集合的当前状态来更新它,这意味着集合更新也非常高效。
关系连接:
关系数据库允许我们执行使这些关系显式的查询(通过Join),在数据量超千万的时候,3个以上的join就是个灾难;然而,Cassandra不是关系数据库,不支持连接Join。
相反,使用Cassandra的应用程序通常会对数据进行非规范化,并巧妙地使用集群来执行将在关系数据库中使用连接的数据访问类型。
另外还有一种常用的方式是通过编程客户端将数据进行关联。对于尚未非规范化的数据集,应用程序还可以执行客户端连接,它通过在应用程序级别执行多个查询并连接结果来模拟关系数据库的行为。客户端连接比预先读取已被非正规化的数据效率低,但是它们提供了更多的灵活性。
Cassandra数据模型规则
Cassandra不支持JOINS,GROUP BY,OR子句,聚合等等。因此必须按照需要存储数据的方式存储数据。
最大化数据重复,因为Cassandra是分布式数据库,数据重复提供即时可用性而无单点故障。
数据建模目标
在Cassandra中建模数据时,您应该有以下目标:
在群集中均匀传播数据:在Cassandra群集的每个节点上传播相等数量(均衡)的数据,必须选择整数作为主键。
主键的第一部分的是分区键,分区键用于指定到不同的节点。
查询数据时读取的分区数最小化:读取查询发出时,从不同的分区收集不同节点的数据,所以分区数应该较少。
这并不意味着不应该创建多个分区。 如果您的数据非常大,则无法在单个分区上保留大量数据,所以必须有一个平衡数量的分区。
键空间(Keyspace)
键空间(Keyspace)用于保存列族,用户定义类型的对象。 键空间(Keyspace)就像RDBMS中的数据库。
它包含:列族,索引,用户定义类型。
策略:
简单策略:在一个数据中心的情况下使用简单的策略。 在这个策略中,第一个副本被放置在所选择的节点上,剩下的节点被放置在环的顺时针方向,而不考虑机架或节点的位置。
网络拓扑策略:该策略用于多个数据中心。 在此策略中,您必须分别为每个数据中心提供复制因子。
复制因子:复制因子是放置在不同节点上的数据的副本数。 超过两个复制因子是很好的获得没有单点故障。 所以3个以上是很好的复制因子。
持久写入Durable_writes:
默认情况下,持久写入设置为true。
当收到写请求时,节点首先将数据的副本写入名为commitlog的仅附加的磁盘结构。然后,它将数据写入名为memtable的内存结构。当memtable已满或达到一定大小时,它将被刷新为磁盘上不可变的结构SSTable。将持久写入设置为true可确保将数据写入commitlog。如果节点重新启动,memtables就会消失,因为它们驻留在内存中。但是,可以通过重放commitlog来重建memtables,因为即使节点重新启动,磁盘结构也不会被清除。
cqlsh基础
创建: CREATE KEYSPACE myKs WITH replication = {'class':'SimpleStrategy', 'replication_factor' : 3}; 查看: DESCRIBE myKs; 等同 DESCRIBE myks; 注意键空间是不分大小写的,因为会把大写都变成小写 查看所有的键空间: DESCRIBE keyspaces 使用创建的键空间: USE myks; 修改键空间: Keyspace Name: 键名称不能更改。 Strategy Name: 可以通过使用新的策略。 Replication Factor : 可以使用新的复制因子。 DURABLE_WRITES :如果设置为false,则不会将更新写入提交日志。 ALTER KEYSPACE myks WITH replication = {'class':'NetworkTopologyStrategy', 'replication_factor' : 1}; 删除KEYSPACE: DROP keyspace myks; 创建表: USE myks; CREATE TABLE "personal_info" (id int PRIMARY KEY, name text, dob text); CREATE TABLE "users" ("username" text PRIMARY KEY,"email" text,"encrypted_password" blob); CREATE TABLE student( student_id int PRIMARY KEY, student_name text, student_city text, student_fees varint, student_phone varint ); 创建之前,要先使用键空间。 在表级别,Cassandra有很多配置选项称为表属性。这些属性允许您优化表的许多底层方面,例如缓存、压缩、垃圾收集和读取修复。 Cassandra的表构造成行和列,就像关系数据库一样。与关系数据库一样,表可用的列也是预先定义的。插入数据时,无法添加新列,必须先更新现有表结构。 每个表定义一个或多个列作为主键;每一行由其主键列中的值唯一标识,并且这些列在任何行中都不能留空。 Cassandra不提供自动递增主键;创建每一行时,客户端必须显式地为其分配主键。构造主键的一个好方法是使用自然键。 修改表,增加列: ALTER TABLE student ADD student_email text; 修改表,删除一列: ALTER TABLE student DROP student_email; 删除table: DROP TABLE student; 截断table: TRUNCATE student; TRUNCATE命令用于截断表。 如果您截断表,表的所有行将永久删除。 创建索引: CREATE INDEX name ON student (student_name); describe student; 删除索引: Drop index student_name_index; 压缩: CREATE TABLE simple ( id int, key text, value text, PRIMARY KEY (key, value) ) with compression = {'class': 'LZ4Compressor', 'chunk_length_in_kb': 4}; 插入数据: INSERT INTO personal_info (id, name, dob) VALUES ( 1 , 'Alice' , '02-25-1954' ); INSERT INTO student (student_id, student_fees, student_name) VALUES(1,5000, 'Maxsu'); INSERT INTO student (student_id, student_fees, student_name) VALUES(2,3000, 'Minsu'); INSERT INTO student (student_id, student_fees, student_name) VALUES(3, 2000, 'Modlee'); 更新数据: UPDATE student SET student_fees=10000,student_name='XunWang' WHERE student_id=2; 删除数据: DELETE FROM student WHERE student_id=3 查询数据: SELECT * FROM personal_info WHERE id = 1; 集合类型: -- 创建含set列的表 create table employee( id int, name text, email set<text>, primary key(id) ); describe employee; -- 插入数据 INSERT INTO employee (id, email, name) VALUES(1, {'yestouu@gmail.com'}, 'yestouu'); INSERT INTO employee (id, email, name) VALUES(2,{'kanchan@qq.com'}, 'Kanchan'); INSERT INTO employee (id, email, name) VALUES(3, {'maxsu@126.com'}, 'Maxsu'); -- 创建含map列的表 CREATE TABLE users ( id text PRIMARY KEY, name text, favs map<text, text> // A map of text keys, and text values ); INSERT INTO users (id, name, favs) VALUES ('jsmith', 'John Smith', { 'fruit' : 'Apple', 'band' : 'Beatles' }); UPDATE users SET favs = { 'fruit' : 'Banana' } WHERE id = 'jsmith'; UPDATE users SET favs['author'] = 'Ed Poe' WHERE id = 'jsmith'; UPDATE users SET favs = favs + { 'movie' : 'Cassablanca', 'band' : 'ZZ Top' } WHERE id = 'jsmith'; DELETE favs['author'] FROM users WHERE id = 'jsmith'; UPDATE users SET favs = favs - { 'movie', 'band'} WHERE id = 'jsmith'; -- 创建含List列的表 CREATE TABLE plays ( id text PRIMARY KEY, game text, players int, scores list<int> // A list of integers ) INSERT INTO plays (id, game, players, scores) VALUES ('123-afde', 'quake', 3, [17, 4, 2]); UPDATE plays SET scores = [ 3, 9, 4] WHERE id = '123-afde'; UPDATE plays SET scores[1] = 7 WHERE id = '123-afde'; UPDATE plays SET scores = scores - [ 12, 21 ] WHERE id = '123-afde'; 用户定义类型: CREATE TYPE phone ( country_code int, number text, ) CREATE TYPE address ( street text, city text, zip text, phones map<text, phone> ) CREATE TABLE user ( name text PRIMARY KEY, addresses map<text, frozen<address>> ) 从Cassandra 4.0-alpha3开始,UDT在大多数情况下都必须冻结,因此上面表定义中的冻结<address>。 元组类型: CREATE TABLE durations ( event text, duration tuple<int, text>, ) INSERT INTO durations (event, duration) VALUES ('ev1', (3, 'hours')); Blobs类型 lob类型存储非结构化二进制数据。blob是图像、音频和加密数据的好选择。在CQL中,blob文本是一个十六进制数字序列,前缀是x,例如0x1d4375023013dba2d5f9a。 插入结果响应: 如果INSERT语句起作用,则无法在shell中看到任何响应;它只应为您提供一个新的命令提示符。这不仅仅是CQL shell的一个怪癖,而是用Cassandra编写数据的一个基本事实;编写数据通常不会从数据库中得到有关操作的任何信息,除非写入失败时出现错误消息。当您执行成功的写入查询时,大多数客户端库将返回一个空值,或问题语言中的等效值。 如果您习惯于使用SQL数据库,这可能会让您感到意外,因为在您编写数据时,SQL数据库通常会提供详细的反馈,例如返回的主键。 缺失主键查询: 当我们查询一个不存在的主键时会发生什么?我们试试看: SELECT * FROM "users" WHERE "username" = 'bogus'; 您将看到,不返回任何结果;尝试检索不存在的主键并不是一个错误。 查询多行: SELECT * FROM "users" WHERE "username" IN ('alice', 'bob');
目前维护的开源产品:https://gitee.com/475660

 浙公网安备 33010602011771号
浙公网安备 33010602011771号