用KNN实现iris的4分类问题&测试精度
import matplotlib.pyplot as plt from scipy import sparse import numpy as np import matplotlib as mt import pandas as pd from IPython.display import display from sklearn.datasets import load_iris import sklearn as sk from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier iris=load_iris() #print(iris) X_train,X_test,y_train,y_test = train_test_split(iris['data'],iris['target'],random_state=0) iris_dataframe = pd.DataFrame(X_train,columns=iris.feature_names) knn = KNeighborsClassifier(n_neighbors=1) knn.fit(X_train,y_train) # KNeighborsClassifier(algorithm='auto',leaf_size=30,metric='minkowski', # metric_params=None,n_jobs=1,n_neighbors=1,p=2,weights='uniform') X_new = np.array([[5,2.9,1,0.2]]) print("X_new.shape:{}".format(X_new.shape)) prediction = knn.predict(X_new) print("Prediction X_new:{}".format(prediction)) print("prediction X_new belong to {}".format(iris['target_names'][prediction])) #评估模型 #计算精度方法1 print("test score1:{:.2f}".format(knn.score(X_test,y_test))) #计算精度方法2 y_pred = knn.predict(X_test) print("test score2:{:.2f}".format(np.mean(y_pred == y_test)))
输出:
Prediction X_new:[0]
prediction X_new belong to ['setosa']
test score1:0.97
test score2:0.97
测试精度
knn的邻居设置会影响测试精度,举例说明:
import matplotlib.pyplot as plt import mglearn from scipy import sparse import numpy as np import matplotlib as mt import pandas as pd from IPython.display import display from sklearn.datasets import load_breast_cancer import sklearn as sk from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier cancer = load_breast_cancer() X_train,X_test,y_train,y_test =train_test_split(cancer.data,cancer.target,stratify=cancer.target,random_state=66) training_accuracy=[] test_accuracy=[] neighbors_settings = range(1,11) for n_neighbors in neighbors_settings: clf = KNeighborsClassifier(n_neighbors=n_neighbors) clf.fit(X_train,y_train) training_accuracy.append(clf.score(X_train,y_train)) test_accuracy.append(clf.score(X_test,y_test)) plt.plot(neighbors_settings,training_accuracy,label="training accuracy") plt.plot(neighbors_settings,test_accuracy,label="test accuracy") plt.xlabel("n_neighbors") plt.ylabel("accuracy") plt.legend() plt.show()
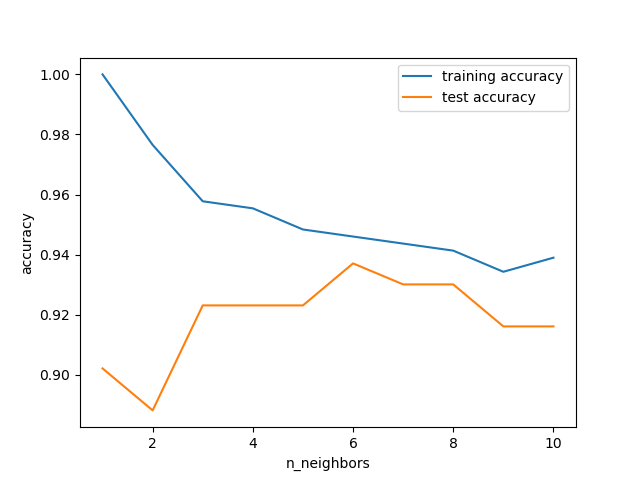
可以看出,6是最优。
KNN算法的优点是简单可解释性强,
缺点是:
- 样本大的时候性能不好
- 特征多(几百个+)的时候效果不好
- 稀疏数据集不适用
关于作者:
王昕(QQ:475660)
在广州工作生活30余年。十多年开发经验,在Java、即时通讯、NoSQL、BPM、大数据等领域较有经验。
目前维护的开源产品:https://gitee.com/475660
目前维护的开源产品:https://gitee.com/475660

 浙公网安备 33010602011771号
浙公网安备 33010602011771号