LEDNet夜间低光增强&去模糊
LEDNet: Joint Low-light Enhancement and Deblurring in the Dark
在黑暗中联合低光增强和去模糊
LEDNet: Joint Low-light Enhancement and Deblurring in the Dark论文阅读笔记
概述
Figure 1.图1所示。

A comparison on the real-world night blurry images shows that existing low-light enhancement and deblurring methods fail in coping with the night blurry images.
通过对真实夜晚模糊图像的比较,发现现有的弱光增强和去模糊方法都是失败的应对夜间模糊的图像。
(a) Input images.
(b) Motion blur in the saturated area is enlarged after performing light enhancement using a contemporary method RUAS [20] (indicated by red arrows).
(c) Applying a deblurring network MIMO-UNet [6] after light enhancement still fails in blur removal.
(d) MIMO-UNet trained on day-time GoPro dataset fails to remove blur in the night-time images.
(e)The proposed LEDNet trained with our LOL-Blur dataset yields satisfactory results through joint low-light enhancement and deblurring
(a)输入图像。
(b)光增强后饱和区域运动模糊增大使用当代方法RUAS[20](用红色箭头表示)。
(c)在光增强后应用去模糊网络MIMO-UNet[6]仍然无法去除模糊。
(d)在白天GoPro数据集上训练的MIMO-UNet无法去除夜间图像的模糊。
(e)提出的LEDNet训练与我们的loll - blur数据集通过联合低光增强和去模糊产生令人满意的结果
场景是什么?产生的原因是什么?
Night photography typically suffers from both low light and blurring issues due to the dim environment and the common use of long exposure.
由于昏暗的环境和长时间曝光的普遍使用,夜间摄影通常会面临低光和模糊问题。
长曝光导致光影模糊残影。
While existing light enhancement and deblurring methods could deal with each problem individually, a cascade of such methods cannot work harmoniously to cope well with joint degradation of visibility and textures.
虽然现有的光增强和去模糊方法可以单独处理每个问题,但这些方法的级联不能很好地协调地处理可见性和纹理的联合退化。
When capturing images at night, one would usually use a slow shutter speed (long exposure) to allow more available light to illuminate the image.
在夜间拍摄时,人们通常会使用较慢的快门速度(长曝光),以允许更多的光线照亮图像。
Even so, the captured dark images may still suffer from low contrast and distorted color induced by insufficient light, which is constrained by minimum shutter speeds that are acceptable for handheld shooting in dark environments.
即便如此,由于光线不足,在黑暗环境下手持相机拍摄的照片可能仍然存在低对比度和色彩失真的问题。
Annoyingly, long exposure inevitably causes motion blurs due to camera shake and dynamic scenes.
Thus, both low light and motion blur typically co-exist in images captured in the dark.
令人烦恼的是,长时间曝光不可避免地会由于相机抖动和动态场景而导致运动模糊。
因此,在黑暗中拍摄的图像中,暗光和运动模糊通常同时存在。
怎么解决这个问题?
Training an end-to-end network is also infeasible as no paired data is available to characterize the coexistence of low light and blurs.
We address the problem by introducing a novel data synthesis pipeline that models realistic low-light blurring degradations.
训练端到端网络也是不可行的,因为没有配对的数据可用来描述低光和模糊的共存。
我们通过引入一种新的数据合成管道来解决这个问题,该管道可以模拟真实的微光模糊退化。
We further present an effective network, named LEDNet, to perform joint lowlight enhancement and deblurring.
Our network is unique as it is specially designed to consider the synergy between the two inter-connected tasks.
我们进一步提出了一个有效的网络,名为LEDNet,以执行联合低光增强和去模糊。
我们的网络是独特的,因为它是专门设计来考虑两个相互关联的任务之间的协同作用。
1.介绍
第一段
When capturing images at night, one would usually use a slow shutter speed (long exposure) to allow more available light to illuminate the image.
在夜间拍摄时,人们通常会使用较慢的快门速度(长曝光),以允许更多的光线照亮图像。
Even so, the captured dark images may still suffer from low contrast and distorted color induced by insufficient light, which is constrained by
即使如此,捕获的暗色图像仍然可能存在低对比度和由于光线不足而导致的颜色失真,这是受
minimum shutter speeds that are acceptable for handheld shooting in dark environments.
手持式相机在黑暗环境下拍摄的最低快门速度。
Annoyingly, long exposure inevitably causes motion blurs due to camera shake and dynamic scenes.
令人烦恼的是,长时间曝光不可避免地会由于相机抖动和动态场景而导致运动模糊。
Thus, both low light and motion blur typically co-exist in images captured in the dark.
因此,在黑暗中拍摄的图像中,暗光和运动模糊通常同时存在。
第二段
Prior methods address the two tasks independently,i.e., low-light enhancement [8, 15, 38] and image deblurring [4, 10, 14, 26, 32, 44, 47].、
先前的方法分别处理这两个任务。弱光增强[8,15,38]和图像去模糊[4,10,14,26,32,44,47]。
These methods made independent assumptions in their specific problem.
这些方法对其具体问题作了独立的假设。
As a result, a forceful combination cannot solve the joint degradation caused by low light and motion blur.
因此,一个强有力的组合不能解决低光和运动模糊造成的关节退化。
Specifically, existing low-light enhancement methods [20,38] perform intensity boosting and denoising, ignoring spatial degradation of motion blurs.
具体来说,现有的微光增强方法[20,38]只进行强度增强和去噪,忽略了运动模糊的空间退化。

Instead, motion blur is even enlarged in saturated regions due to over-exposing after performing light enhancement, as shown in Figure 1(b).
相反,在进行光增强后,由于过度曝光,饱和区域的运动模糊甚至会扩大,如图1(b)所示。
Low-light enhancement methods [38, 49] also have the risk of removing informative clues for blur removal due to over-smoothing when denoising.
弱光增强方法[38,49]在去噪时由于过度平滑,也有可能去除用于去除模糊的信息线索。
Figure 1(c) shows that performing deblurring after low-light enhancement still fails the blur removal.
图1(c)显示了在弱光增强后进行去模糊仍然不能去除模糊。
第三段
As for deblurring, existing methods [6, 14, 32, 44] possess assumptions for deblurring in daytime scenes, and thus,cannot be directly applied to the non-trivial night image deblurring.
在去模糊方面,现有方法[6,14,32,44]对白天场景的去模糊存在假设,不能直接应用于非平凡的夜间图像去模糊。
白天的去模糊,不能直接应用于夜间的去模糊。
In particular, motion cues (e.g., blur trajectory) in dark regions are poorly visible and perceived due to the low dynamic range, posing a great challenge for existing deblurring methods.
特别是暗区运动线索(如模糊轨迹)由于动态范围小,可视性和可感知性差,对现有的去模糊方法提出了很大的挑战。
存在的问题,提出新需求的原因
Furthermore, night blurry images contain saturated regions (such as light streaks) in which the pixels do not conform to the blur model learned from daytime data [4,10].
此外,夜间模糊图像包含饱和区域(如光条纹),其中像素不符合从日间数据中学习到的模糊模型[4,10]。
Hence, existing methods often fail to cope with blurs in saturated regions, as shown in Figure 1(d).
因此,现有的方法往往无法处理饱和区域的模糊,如图1(d)所示。
第四段
The solution to the aforementioned problems is to train a single network that addresses both types of degradations jointly.
上述问题的解决方案是训练一个单独的网络,同时处理这两种类型的降级。
Clearly, the main obstacle is the availability of such data that come with low-light blurry and normal-light sharp image pairs.
显然,主要的障碍是这些数据的可用性,这些数据伴随着低光模糊和正常光清晰的图像对。
The collection is laborious and hard, if not impossible.
这些收藏即使不是不可能,也是费力而艰苦的。
Existing datasets for low-light enhancement, e.g., LOL [38] and SID [3], gather low-/normal-light pairs by changing exposure time and ISO in two shots.
现有的弱光增强数据集,例如,LOL[38]和SID[3],通过改变曝光时间和ISO在两个镜头中收集低/正常光对。
While deblurring datasets, e.g., RealBlur [28], need to capture paired blurry/sharp images under the long and short exposures.
而去模糊数据集,如RealBlur[28],需要在长时间和短时间曝光下捕捉成对的模糊/清晰图像。
It is challenging to merge these two data collection processes harmoniously due to the contradictory shooting settings.
由于拍摄环境的矛盾,将这两种数据采集过程和谐地融合是一个挑战。
Moreover, existing synthetic deblurring datasets [25,26,30] can not simulate blurs of saturated regions in the dark due to the limited dynamic range of captured sharp sequences.
此外,现有的合成去模糊数据集[25,26,30]由于捕获的尖锐序列的动态范围有限,无法模拟黑暗中饱和区域的模糊。
第五段
This paper makes the first attempt to generate such a dataset for joint low-light enhancement and deblurring us ing a novel data synthesis pipeline.
本文首次尝试生成这样的数据集,用于联合弱光增强和去模糊我们的一个新的数据合成管道。
The dataset, LOL-Blur,contains 12,000 pairs of low-blur/normal-sharp pairs for training and testing.
该数据集,loll -blur,包含12,000对低模糊/正常锐利的对,用于训练和测试。
We design the pipeline with the aim of generating realistic data.
我们设计管道的目的是生成真实的数据。
Specifically, we reformulate a state-of-the-art light enhancement method, Zero-DCE [8], to be conditional, so that we can control the darkness of a given high-frame-rate sequence.
具体来说,我们重新制定了一种最先进的光增强方法,Zero-DCE[8],它是有条件的,这样我们就可以控制给定的高帧率序列的黑暗。
The darken sequences are then averaged within a predefined temporal window to obtain low-light blurry images.
然后在一个预定义的时间窗口内平均变暗序列,以获得弱光模糊图像。
We pay special attention to model blurs in saturated regions correctly (e.g., light streaks in the night), which are always ignored in the prior synthetic datasets.
我们特别注意饱和区域的模型模糊(如夜间的光条纹),这些在之前的合成数据集中总是被忽略。
To generate more realistic low-light blurry images, our pipeline also considers defocus blurs via generalized Gaussian filters [36] and adds realistic noises using CycleISP [41].
为了生成更逼真的弱光模糊图像,我们还考虑了通过广义高斯滤波器[36]的离焦模糊,并使用CycleISP[41]添加逼真的噪声。
Some examples of LOL-Blur are shown in Figure 2.
loll - blur的一些例子如图2所示。

Figure 2.图2。
Paired images from the proposed LOL-Blur dataset, showing diverse darkness and motion blurs in dark dynamic scenes.
来自提议的loll - blur数据集的成对图像,在黑暗的动态场景中显示了不同的黑暗和运动模糊。
The dataset also provides realistic blurs in the simulated regions, like light streaks shown in the last two columns.
数据集还在模拟区域中提供了逼真的模糊效果,比如最后两列中显示的光条纹。
第六段
Apart from the data, we show that it is beneficial to consider both low-light enhancement and deblurring in a single context.
除了数据,我们表明,它是有益的考虑微光增强和去模糊在一个单一的背景下。
We demonstrate the benefits by training an endto-end network that we call as Low-light Enhancement and Deblurring Network (LEDNet).
我们通过训练端到端网络(我们称之为低光增强和去模糊网络(LEDNet))来证明其优点。
LEDNet consists of a lightLEDNet enhancement module (LE-Encoder) and a deblurring module (D-Decoder).
由一个LENDET组成增强模块(LE-Encoder)和去模糊模块(D-Decoder)。
Different from existing light enhancement methods that may risk wiping out useful cues for deblurring when performing noise suppression, LEDNet connects the LE-Encoder and D-Decoder using Filter Adaptive Skip Connections (FASC) based on FAC Layers [52].
与现有的光增强方法不同的是,在进行噪声抑制时,可能会消除去模糊的有用线索,LEDNet使用基于FAC Layers[52]的Filter Adaptive Skip Connections (FASC)连接LE-Encoder和D-Decoder。
FASC takes enhanced features in LE-Encoder to predict spatially-varying kernels for FAC Layers, thus, the cues from enhanced features help blur removal in D-Decoder.
FASC利用LE-Encoder中的增强特征来预测FAC层的空间变化核,因此,增强特征的线索有助于D-Decoder中的模糊去除。
To train the network stably, we apply the Pyramid Pooling Modules (PPM) [50] in LE-Encoder.
为了稳定地训练网络,我们在LE-Encoder中应用了金字塔池模块(PPM)[50]。
PPM integrates the hierarchical global prior to eliminating artifacts in the enhanced results, especially for high-resolution inputs.
PPM在消除增强结果中的工件之前集成了层次全局,特别是对于高分辨率输入。
We also propose the Curve NonLinear Unit (CurveNLU) that learns the non-linear function for feature adjustment via curves estimation, allowing our network to model complex intensity enhancement.
我们还提出了曲线非线性单元(CurveNLU),它通过曲线估计来学习非线性函数来进行特征调整,使我们的网络能够模拟复杂的强度增强。
罗列点
The main contributions are summarized as follows:主要贡献归纳如下:
• We introduce a novel data synthesis pipeline that models low-light blur degradation realistically, leading to the large-scale and diverse LOL-Blur dataset for joint low-light enhancement and deblurring.
我们引入了一种新型的数据合成管道,可以真实地模拟弱光模糊退化,从而产生大规模和多样化的loll - blur数据集,用于联合弱光增强和去模糊。
• We propose a unified framework LEDNet with delicate designs to address low-light enhancement and deblurring jointly.•
我们提出了一个具有精致设计的统一框架LEDNet,以共同解决弱光增强和去模糊问题。
The proposed FASC allows the enhancement step to facilitate deblurring through boosting more cues for FAC filter estimation.
提出的FASC允许增强步骤,以促进去模糊,通过增加更多线索的FAC滤波器估计。
• We highlight two effective modules for our task: a. PPM aggregates the hierarchical global prior that is crucial to make training more stable and suppress the artifacts in results.•
我们为我们的任务强调了两个有效的模块:a. PPM聚合了层次全局先验,这对使训练更稳定和抑制结果中的工件至关重要。
b. CurveNLU learns the non-linear functions for feature transformation, which brightens dark areas without overexposing other regions.b.
b. CurveNLU学习非线性函数进行特征变换,使深色区域变亮,而不会过度暴露其他区域。
2.相关工作
图像去模糊
Image Deblurring.图像去模糊。
Many CNN-based methods have been proposed for dynamic scene deblurring [6, 14, 26, 32, 44, 45,47].
许多基于cnn的方法被提出用于动态场景去模糊[6,14,26,32,44,45,47]。
Most early studies [7,31] employ networks to estimate the motion blur kernels followed by non-blind methods.
大多数早期研究[7,31]采用网络估计运动模糊核,然后采用非盲方法。
Owing to the emergence of training datasets for deblurring tasks [17,25,26,28–30,53], end-to-end kernel-free networks become the dominant methods.
由于用于去模糊任务的训练数据集的出现[17,25,26,28 - 30,53],端到端无核网络成为主流方法。
To obtain a large receptive field, some networks [6,26,32] adopt the multi-scale strategy to handle large blurs Similarly, some multi-patch deblurring networks [9,43,47] employ the hierarchical structures without down-sampling.
为了获得更大的接受域,一些网络[6,26,32]采用多尺度策略来处理大的模糊。类似地,一些多patch去模糊网络[9,43,47]采用分层结构而不进行下采样。
GAN-based deblurring methods [13,14] have been proposed to generate more details.
基于gan的去模糊方法[13,14]被提出以生成更多的细节。
To deal with spatially-varying blurs, Zhang et al. [45] propose spatially variant RNNs to remove blur via estimating RNN weights.
为了处理空间变化的模糊,Zhang et al.[45]提出了空间变化的RNN,通过估计RNN权值来去除模糊。
Zhou et al. [52] propose the filter adaptive convolutional
Zhou等人[52]提出了滤波器自适应卷积
(FAC) layer to handle non-uniform blurs dynamically.
(FAC)层动态处理不均匀模糊。
In our paper, we built a filter adaptive skip connection between encoder and decoder using FAC layers.
在本文中,我们利用FAC层在编码器和解码器之间建立了一个滤波器自适应跳跃连接。
第二段
Optimization-based approaches are proposed for lowlight image deblurring [4, 5, 10].
针对微光图像去模糊提出了基于优化的方法[4,5,10]。
Hu et al. [10] suggest the use of light streaks to estimate blur kernel.
Hu et al.[10]建议使用光条纹来估计模糊核。
However, their method heavily relies on light streaks and tends to fail when the light sources are not available or too large beyond pre-designed blur kernel size.
然而,他们的方法严重依赖于光条纹,当光源不可用或太大超过预先设计的模糊内核大小时,往往会失败。
Chen et al. [4,5] process saturated regions specially and ensure smaller contributions of these pixels in optimization.
Chen等[4,5]在优化过程中对饱和区域进行了特殊处理,保证了这些像素的贡献较小。
Their results show few artifacts around saturated regions.
他们的结果显示,在饱和区域周围很少有人为干扰。
While effective, all these methods are time-consuming, thus limiting their applicability.
这些方法虽然有效,但都很耗时,因此限制了它们的适用性。
暗光增强
Low-light Enhancement.光线暗的增强。
Deep networks have become the mainstream in low-light enhancement (LLE) [15].
深度网络已经成为微光增强(LLE)[15]的主流。
The first CNN model LL-Net [21] employs an autoencoder to learn denoising and light enhancement simultaneously.
第一个CNN模型llnet[21]使用了一个自动编码器来同时学习去噪和增强光线。
Inspired by the Retinex theory, several LLE networks [20,34,38,40,49] are proposed.
受Retinex理论的启发,提出了几种LLE网络[20,34,38,40,49]。
They commonly split a low-light input into reflectance and illumination maps, then adjust the illumination map to enhance the intensity.
他们通常将弱光输入分割成反射率和照度贴图,然后调整照度贴图来增强亮度。
Most methods integrate a denoising module on the reflectance map for suppressing noise in the enhanced results.
大多数方法在反射图上集成去噪模块来抑制增强结果中的噪声。
For example, Zheng et al. [51] propose an unfolding total variation network to estimate noise level for LLE.
例如,Zheng et al.[51]提出了一种展开的全变分网络来估计LLE的噪声水平。
While the joint task of LLE and deblurring has not been investigated yet in the literature.
而LLE和去模糊的联合任务在文献中还没有被研究。
第二段
To improve the generalization capability, some unsupervised methods are proposed.
为了提高泛化能力,提出了一些无监督方法。
EnlightenGAN [12] is an attention-based U-Net trained using adversarial loss.
开明的[12]是一个使用对抗性损失训练的基于注意力的U-Net。
ZeroDCE [8] and Zero-DCE++ [16] formulate light enhancement as a task of image-specific curve estimation.
ZeroDCE[8]和Zero-DCE++[16]将光增强作为图像特定曲线估计的任务。
Their training adopts several manually-defined losses on supervision of exposure or color, without limitation of paired or unpaired training data.
他们的训练采用了几个人工定义的曝光或颜色监督损失,不限制成对或不成对的训练数据。
Thus, Zero-DCE can be easily extended to generic lighting adjustments.
因此,Zero-DCE可以很容易地扩展到一般的照明调整。
In our data synthesis pipeline, we train an exposure conditioned Zero-DCE to darken images for low-light simulation.
在我们的数据合成管道中,我们训练一个曝光条件为零dce的暗化图像用于弱光模拟。
Given random low exposure degrees, we can generate darkness-diverse low-light images.
给定随机的低曝光度,我们可以生成不同黑暗的弱光图像。
3.数据集
第一段
It is infeasible to collect a dataset with low-blurry and normal-sharp image pairs due to the contradictory shooting settings.
由于拍摄设置的矛盾,低模糊和正常清晰图像对的数据集是不可行的。
In this work, we introduce a synthesis pipeline that models low-light blur degradation realistically, hence allowing us to generate a large-scale dataset (LOL-Blur) data for this joint task.
在这项工作中,我们引入了一个合成管道,可以真实地模拟弱光模糊退化,因此允许我们为这个联合任务生成一个大规模的数据集(loll - blur)。
We acquire a total of 170 videos for training and 30 videos for testing, each of which has 60 frames, amounting to 12,000 paired data in our dataset.
我们总共采集了170个训练视频和30个测试视频,每个视频有60帧,在我们的数据集中总共有12000对数据。
3.1 Preliminaries预赛
A high-quality training data is indispensable for deep learning.
高质量的训练数据对于深度学习是必不可少的。
Efforts have been made to collect real-world lowlight enhancement [2, 3, 11, 19, 33, 38] or image deblurring [28] datasets, but not both settings at the same time.
人们已经在努力收集真实世界的弱光增强[2,3,11,19,33,38]或图像去模糊[28]数据集,但不能同时进行这两种设置。
The lack of such data is not surprising as (1) Paired images of low-light enhancement datasets and image deblurring datasets are commonly collected by different camera shot settings,
缺少这样的数据并不奇怪,因为(1)成对的弱光增强数据集和图像去模糊数据集通常由不同的相机拍摄设置收集,
and (2) The collection of both kinds of data is susceptible to geometric and photometric misalignment due to camera shake or dynamic environment during data acquisition.
(2)两种数据的采集都容易受到相机抖动或动态环境等因素的几何和光度偏差的影响。
Consequently, an image synthesis pipeline is desired to generate large-scale and high-quality low-blurry and normal-sharp image pairs.
因此,需要一个图像合成管道来生成大规模的、高质量的低模糊和正常锐利的图像对。
A standard synthesis pipeline of blurry data [17, 25, 26,30,53] is to average successive frames on high frame-rate sequences for approximating the blur model [26].
模糊数据的标准合成管道[17,25,26,30,53]是在高帧率序列上平均连续帧,以逼近模糊模型[26]。
The processcan be expressed as:这个过程可以表示为:
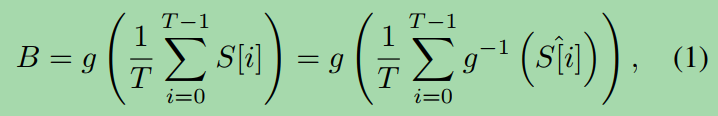
第二段
where g(·) is CRF function (Gamma curve with γ = 2:2) that maps latent signal S[i] into observed sRGB images S^[i].
式中g(·)是将潜信号S[i]映射到观测sRGB图像S^[i]的CRF函数(γ = 2:2的Gamma曲线)。
This process can be used to generate blurry-sharp pairs for daytime scenes, assuming S^[i] = g (S[i]).
假设S^[i] = g (S[i]),这个过程可以用于生成白天场景的模糊清晰度对。
However, the blur model [26] is usually inaccurate for the regions of saturated pixels that often appear in dark blurry images, such as light streaks.
然而,模糊模型[26]对于经常出现在黑暗模糊图像中的饱和像素区域(如光条纹)通常是不准确的。
This is because the saturated intensities in latent signal S[i] are clipped to the maximum value (255) when S[i] is saved as an sRGB image S^[i], due to the limited dynamic range of sRGB images, i.e., S^[i] = Clip (g (S[i])).
这是因为当S[i]保存为sRGB图像S^[i]时,由于sRGB图像的动态范围有限,即S^[i] = Clip (g (S[i]),潜伏信号S[i]的饱和强度被剪切到最大值(255)。
This clipping function damages the exceeding value of saturated regions, thus making the blur model of Eq. (1) improper for these regions [4].
这个剪切函数破坏了饱和区域的超限值,使得式(1)的模糊模型不适用于这些区域[4]。
Our dataset resolves this issue by recovering the clipped intensities in saturated regions.
我们的数据集通过恢复饱和区域的剪切强度来解决这个问题。
3.2 Data Generation Pipeline数据生成管道
Figure 3
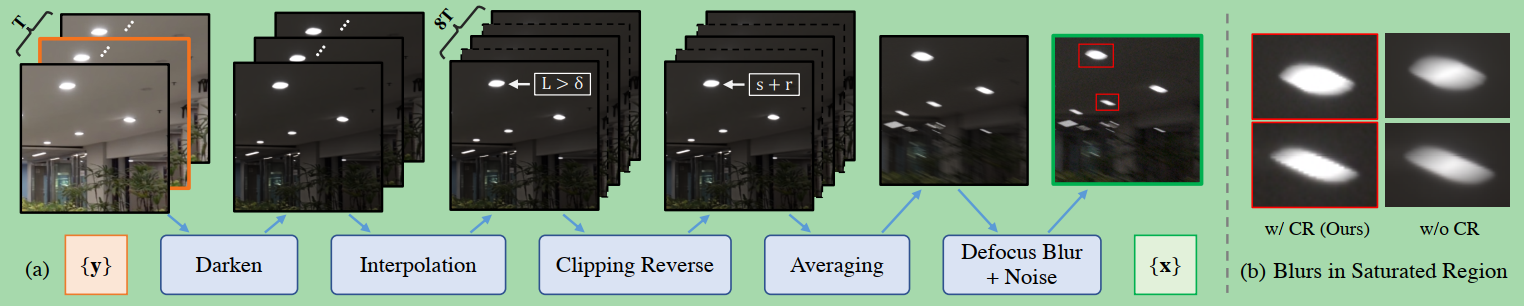
(a) An overview of our data synthesis pipeline.
(a)我们数据合成流程的概述。
(b) Comparisons on two blur simulations in the saturated regions.
(b)两种模糊模拟在饱和区域的对比。
Using Clipping Reverse (CR) can generate more realistic blurs with relative sharp boundaries in saturated regions, which better resembling real cases that are caused by the large light ratio.
使用剪切反向(CR)可以在饱和区域生成更逼真的模糊图像,边界相对清晰,更接近真实情况都是由于光比大造成的。
第一段
The overview of our data generation pipeline is shown in Figure 3.
我们的数据生成管道的概述如图3所示。
We use a Sony RX10 IV camera to record 200 high frame-rate videos at 250 fps.
我们使用了索尼RX10 IV相机,以250帧/秒的速度录制了200个高帧率视频。
With the video sequences, we first downsize each frame to a resolution of 1120 × 640 to reduce noises.
对于视频序列,我们首先将每帧的分辨率缩小到1120 × 640,以减少噪声。
We then apply VBM4D [24] for further denoising and obtain the clean sequences.
然后应用VBM4D[24]进一步去噪,得到干净的序列。
In our method, we take 7 or 9 frames as a sequence clip, as shown in Figure 3.
在我们的方法中,我们取7或9帧作为序列剪辑,如图3所示。
The mid-frame (with orange bounding box) among the sharp frames is treated as the ground truth image.
锐帧之间的中间帧(带有橙色边界框)作为地面真实图像处理。
Then, we process the following steps to generate low-light and blurred images.
然后,我们处理以下步骤生成弱光和模糊图像。
Darkening with Conditional Zero-DCE.
使用条件零dce变暗。
To simulate the degradation of low light, we reformulate the Zero-DCE [8] into an Exposure-Conditioned variant, EC-Zero-DCE.
为了模拟弱光的降解,我们将Zero-DCE[8]重新设计成曝光条件的变体,EC-Zero-DCE。
Unlike Zero-DCE that is designed for improving the brightness of an image, EC-Zero-DCE implements a reversed curve adjustment that simulates the low light and controls the darkness levels.
不像Zero-DCE是为了提高图像的亮度而设计的,EC-Zero-DCE实现了反向曲线调整,模拟低光和控制黑暗水平。
Specifically, we modify exposure control loss by replacing the fixed exposure value with a random parameter that represents darkness while other losses are kept in the same settings as Zero-DCE.
具体来说,我们通过用代表黑暗的随机参数替换固定曝光值来修改曝光控制损失,而其他损失保持在与零dce相同的设置中。
Given a random exposure level, EC-Zero-DCE can generate realistic low-light images with diverse darkness levels.
给定一个随机的曝光水平,EC-Zero-DCE可以生成具有不同黑暗水平的真实的微光图像。
Note that CE-Zero-DCE performs pixel-wise and spatially-varying light adjustment, rather than uniform light degradation.
注意CE-Zero-DCE执行像素级和空间变化的光调整,而不是均匀的光退化。
We provide the luminance adjustment map in the suppl.
我们在附录中提供了亮度调整图。
to support this statement.
为了支持这一说法。
Frame Interpolation.帧插值。
To avoid discontinuous blurs in synthetic data, we increase the frame rate to 2000 fps using a high-quality frame interpolation network [27].
为了避免合成数据出现不连续的模糊,我们采用高质量的帧插补网络[27],将帧速率提高到2000帧/秒。
Clipping Reverse for Saturated Region.饱和区域的剪切反转。
To compensate for the clipped intensity in saturated regions, a simple yet effective way is by adding a random supplementary value r 2 [20;100] to these regions.
为了补偿饱和区域的剪切强度,一种简单而有效的方法是加入一个随机的附加值r2 [20;100]到这些地区。
We reformulate the blur model in Eq. (1) as:
我们将式(1)中的模糊模型重新表述为:
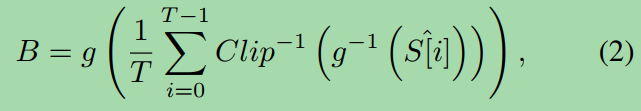
where Clip−1(s) = s + r if s in the saturated regions, otherwise Clip(s) = s. We define the saturated regions where L >
其中,当s在饱和区域时,Clip−1(s) = s + r,否则Clip(s) = s。我们定义L >
δ in the Lab color space, the threshold δ is empirically set to 98 in our pipeline.
在实验室颜色空间中,根据经验,阈值δ在我们的管道中被设置为98。
Figure 3(b) shows using clipping reverse helps generate more realistic blurs in saturated regions.
图3(b)显示使用反向裁剪有助于在饱和区域生成更真实的模糊效果。
Besides, the modified blur model can help networks trained on this dataset generalize well in the saturated regions, as shown in Figure 8.
此外,修改后的模糊模型可以帮助在该数据集上训练的网络在饱和区域有很好的泛化效果,如图8所示。
Frame Averaging.帧平均。
Next, we average 56 (7×8) or 72 (9×8) successive frames of 2000 fps videos to produce virtual blurry videos at around 24 fps with duty cycle τ = 0:8.
接下来,我们平均56 (7×8)或72 (9×8)连续帧2000 fps的视频,以产生24 fps左右的虚拟模糊视频,占空比τ = 0:8。
Adding Defocus Blur and Noise.添加离焦模糊和噪声。
To generate more realistic low-light blurry images, our pipeline also considers defocus blurs, which are implemented by applying generalized Gaussian filters [36].
为了生成更真实的弱光模糊图像,我们还考虑了散焦模糊,这是通过应用广义高斯滤波器[36]实现的。
We also add realistic noises into low-blur images using CycleISP [41].
我们还使用CycleISP[41]为低模糊图像添加真实的噪声。
Both defocus blur and noise are added in a random fashion.
散焦模糊和噪声都是随机添加的。
最后一段
Thus, our dataset offers realism in low-light blur degradation and consists of 200 common dynamic dark scenarios (indoor and outdoor) with diverse darkness and motion blurs, as shown in Figure 2.
因此,我们的数据集提供了弱光模糊退化的真实感,包含了200个常见的动态黑暗场景(室内和室外),具有不同的黑暗和运动模糊,如图2所示。
A total of 55 sequences contain saturated regions, such as various sources of artificial lighting.
共有55个序列包含饱和区域,如各种人工光源。
Thus, our data sufficiently covers hard cases with blurs in saturated areas.
因此,我们的数据可以充分覆盖饱和区域中模糊的硬情况。
Experimental results demonstrate that the networks trained using our dataset generalizes well on real-world dark blurred images.
实验结果表明,利用我们的数据集训练的网络对真实的暗模糊图像有很好的泛化效果。
LOL-Blur dataset will be released upon publication of this work.
loll - blur数据集将在本工作发布后发布。
4.LEDNet
第一段
We treat the joint task of low-light enhancement (LLE) and deblurring as a non-blind image restoration problem.
我们将弱光增强和去模糊的联合任务视为一个非盲图像恢复问题。
A low-light blurry image fxg mainly contains visibility and texture degradations.
微光模糊图像fxg主要包含可见性和纹理退化。
The two degradations are spatiallyvarying due to local lighting conditions and dynamic scene blurs.
由于局部光照条件和动态场景的模糊,这两次退化在空间上是不同的。
To solve this issue, we specially design a network, LEDNet, to map low-light blurry images fxg to its corresponding normal-light sharp images fyg.
为了解决这个问题,我们专门设计了一个网络,LEDNet,将微光模糊的图像fxg映射到对应的正光清晰的图像fyg。
Figure 4 shows the overall architecture of LEDNet.
图4显示了LEDNet的总体架构。
LEDNet is built upon an encoder-decoder architecture with filter adaptive skip connections to solve this joint spatially-varying task.
LEDNet是建立在编码器-解码器架构与滤波器自适应跳跃连接,以解决这个联合空间变化的任务。
Figure 4
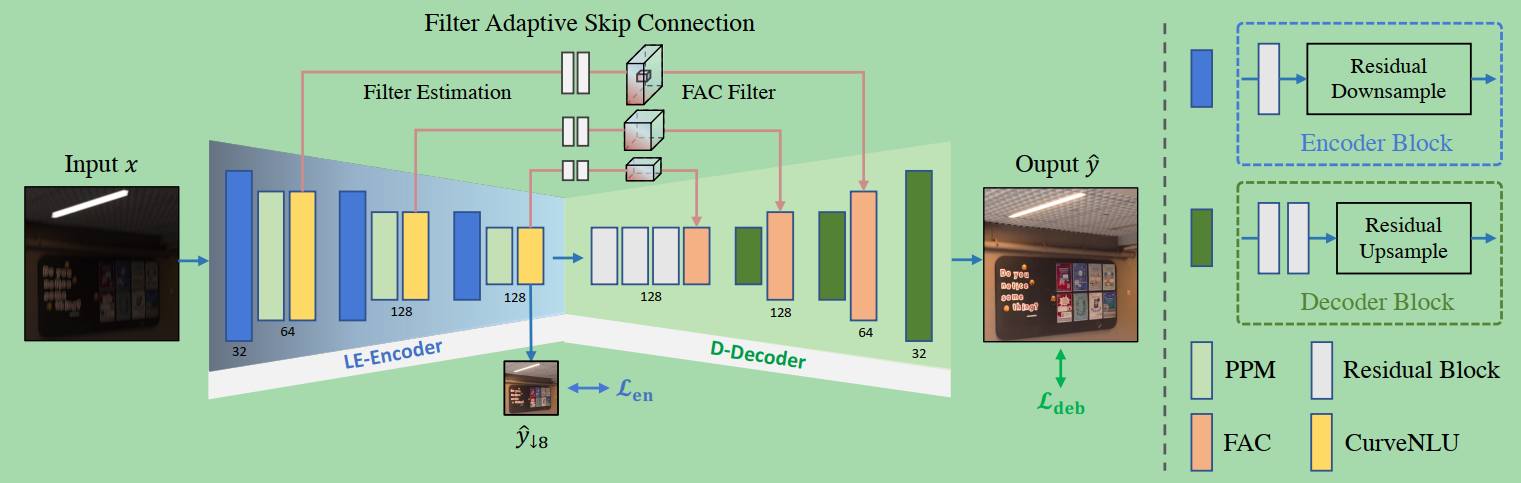
An illustration of the proposed LEDNet.
拟议的LEDNet的插图。
It contains an Encoder for Light Enhancement, LE-Encoder, and a Decoder for Deblurring, D-Decoder.
它包含一个用于光增强的编码器le -编码器和一个用于去模糊的解码器d -解码器。
They are connected by three Filter Adaptive Skip Connections (FASC).
它们由三个滤波器自适应跳过连接(FASC)连接。
The PPM and the proposed CurveNLU layers are inserted in LE-Encoder, making light enhancement more stable and powerful.
PPM层和拟议的CurveNLU层被插入LE-Encoder中,使光增强更加稳定和强大。
LEDNet applies spatially-adaptive transformation to D-Decoder using filters generated by FASC from enhanced features.
利用FASC从增强的特征中生成的滤波器,LEDNet将空间自适应变换应用于D-Decoder。
CurveNLU and FASC enable LEDNet to perform spatially-varying feature transformation for both intensity enhancement and blur removal.
CurveNLU和FASC使LEDNet能够进行空间变化的特征变换,以增强强度和去除模糊。
4.1
Low-light Enhancement Encoder光线增强编码器
The encoder (LE-Encoder) is designed for Low-light Enhancement with the supervision of intermediate enhancement loss (see Sec. 4.4).
该编码器(LE-Encoder)设计用于在中间增强损失监督下的弱光增强(见第4.4节)。
It consists of three scale blocks,each of which contains one Residual Block, one Residual Downsampling Block [42], a PPM, and a CurveNLU, as shown in Figure 4.
它由三个尺度块组成,每个尺度块包含一个残差块、一个残差Downsampling块[42]、一个PPM和一个CurveNLU,如图4所示。
To facilitate intermediate supervision, we output an enhanced image by one convolution layer at the smallest scale.
为了便于中间监督,我们以最小的尺度通过一个卷积层输出增强图像。
Our design gears LE-Encoder to embed the input image x into the feature space of normal-light images, allowing the subsequent decoder (D-Decoder) to pay more attention to the deblurring task.
我们的设计让LE-Encoder将输入图像x嵌入到正常光图像的特征空间中,允许随后的解码器(D-Decoder)更加关注去模糊任务。
Pyramid Pooling Module.金字塔池模块。
The outputs of typical light enhancement networks are often prone to local artifacts, especially when the networks are fed with high-resolution inputs.
典型的光增强网络的输出往往容易产生局部伪影,特别是当网络被提供高分辨率输入时。
We found that the problem can be significantly remedied by injecting global contextual prior into the networks.
我们发现,这个问题可以通过在网络中预先注入全局上下文来显著地解决。
To achieve this goal, we introduce Pyramid Pooling Module (PPM) [50] into our LE-Encoder.
为了实现这一目标,我们在LE-Encoder中引入了金字塔池模块(PPM)[50]。
The PPM effectively extracts hierarchical global prior using multi-scale regional pooling layers and aggregates them in the last convolution layer.
该算法利用多尺度区域池化层有效提取分层全局先验,并在最后一层卷积层中进行聚合。
We adopt the original design of PPM [50] that has four mean pooling branches with bin sizes of 1;
我们采用PPM[50]的原始设计,它有四个平均池化分支,容器大小为1;2;2;3;3;6, respectively.分别为6。
We would like to highlight that this module is crucial in our task, it suppresses artifacts that may be caused by the co-existence of other degradations of blur and noise.
我们想要强调的是,这个模块在我们的任务中是至关重要的,它抑制了可能由其他模糊和噪声退化共存引起的工件。
Please refer to the original paper [50] for more details of PPM.
有关PPM的更多细节,请参阅原始文件[50]。
Curve Non-Linear Unit.曲线非线性单元。
In low-light enhancement, local lighting effects, such as light sources, are often observed in the night environment.
在弱光增强中,通常在夜间环境中观察到局部照明效应,如光源。
The global operators tend to over- or under-enhance these local regions.
全球运营商倾向于过度或不足地增强这些局部地区。
To solve this problem, Zero-DCE [8] applies the pixel-wise curve parameters to the input image iteratively for light enhancement.
为了解决这个问题,Zero-DCE[8]将逐像素曲线参数迭代应用到输入图像上进行光增强。
Inspired by Zero-DCE [8], we propose a learnable non-linear activation function, namely Curve Non-Linear Unit (CurveNLU).
受到Zero-DCE[8]的启发,我们提出了一个可学习的非线性激活函数,即曲线非线性单元(Curve非线性Unit, CurveNLU)。
The CurveNLU is designed for feature transformation using the estimated curve parameters, as shown in Figure 5.
利用估计的曲线参数,设计CurveNLU进行特征变换,如图5所示。
Figure 5
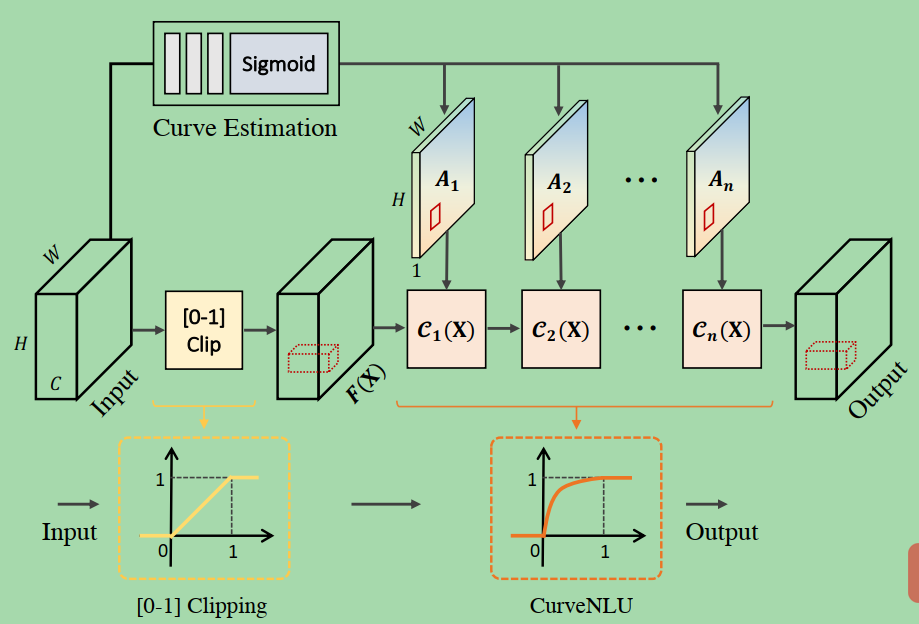
An illustration of Curve Non-Linear Unit.
曲线非线性单元的图示。
This layer can be seen as a learnable non-linear activation function between 0 and 1.
这一层可以看作是0到1之间的可学习的非线性激活函数。
Based on Eq. 3, the learned function always follows concave down increasing curves to increase feature intensities.
根据公式3,学习后的函数始终遵循凹下递增曲线,以增加特征强度。
Similar to Zero-DCE, we formulate the high-order curve in an iterative function:与Zero-DCE相似,我们用迭代函数表示高阶曲线:
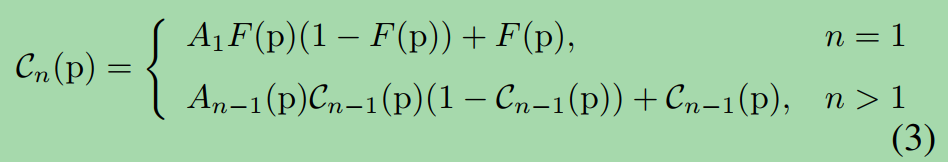
where p denotes position coordinates of features, and An−1 is the pixel-wise curve parameter for the n-th order of the estimated curve.
其中p表示特征的位置坐标,An−1为估计曲线的n阶像素方向曲线参数。
Given an input feature F 2 RH×W ×C, Curve Estimation module estimates curve parameters A 2 RH×W ×n that represent an n + 1 order curve for different positions.
给定一个输入特征F 2 RH×W ×C,曲线估计模块估计曲线参数A 2 RH×W ×n表示不同位置的n + 1阶曲线。
Feature transformation is then achieved by Eq. 3 using the estimated curve parameters.
然后通过Eq. 3利用估计的曲线参数进行特征变换。
Different from Zero-DCE that uses different curves for RGB channels, our CurveNLU applies the same curve to different channels in the feature domain.
不同于Zero-DCE对RGB通道使用不同的曲线,我们的CurveNLU将相同的曲线应用于特征域的不同通道。
Note that the parameters A lay in [0;1], ensuring that CurveNLU always learns concave down increasing curves to increase the features of dark areas without overexposing other regions. 1],
注意,参数A位于[0;确保CurveNLU始终学习凹下递增曲线,增加暗区特征,而不会过度曝光其他区域。
To meet this design, the input feature F of CurveNLU is needed to be clipped to the range of [0;1] at the beginning.
一开始为了满足这种设计,需要将CurveNLU的输入特征F裁剪到[0;
The Curve Estimation module consists of three convolution layers followed by a Sigmoid function.
曲线估计模块由三个卷积层和一个Sigmoid函数组成。
We set iteration number n to 3 in our experiments.
在我们的实验中,我们将迭代数n设为3。
4.2 Deblurring Decoder由模糊变清晰译码器
With the enhanced features from LE-Encoder, the Deblurring Decoder (D-Decoder) is able to concentrate more on deblurring.
利用LE-Encoder的增强特性,去模糊解码器(D-Decoder)能够更专注于去模糊。
It also contains three convolutional blocks, each of which has two Residual Blocks, one Residual Upsampling Block [42], and a FAC Layer [52] that is used to bridge the LE-Encoder and the D-Decoder
它还包含三个卷积块,每个卷积块有两个残差块,一个残差上采样块[42]和一个FAC层[52],用于连接LE-Encoder和D-Decoder。
4.3 Filter Adaptive Skip Connection过滤器自适应跳过连接
Both low-light enhancement and deblurring in our task are spatially varying problems.
在我们的任务中,微光增强和去模糊都是空间变化的问题。
Deblurring in the dynamic scenes is challenging due to its spatially variant blurs caused by object motion and depth variations.
在动态场景中,由于物体运动和深度变化引起的空间模糊是一项具有挑战性的任务。
Though CurveNLU applies pixel-wise adjustment in the LE-Encoder, it is not enough for the deblurring task that usually needs dynamic spatial kernels to handle motion blurs.
虽然CurveNLU在LE-Encoder中应用了像素级的调整,但对于通常需要动态空间内核来处理运动模糊的去模糊任务来说,这是不够的。
Filter Adaptive Convolutional (FAC) layer [52] has been proposed to apply dynamic convolution filters for each element in features.
Filter Adaptive Convolutional (FAC) layer[52]被提出,用于对feature中的每个元素应用动态卷积滤波器。
Built on the FAC layers, we design a Filter Adaptive Skip Connection (FASC) to solve the deblurring problem by exploiting the enhanced information from LE-Encoder.
在FAC层的基础上,我们设计了一种滤波器自适应跳跃连接(FASC),利用LE-Encoder的增强信息来解决去模糊问题。
As shown in Figure 4, given the enhanced features E 2 RH×W×C at different scales, FASC estimates the corresponding filter K 2 RH×W×Cd2 via three 3 × 3 convolution layers and a 1 × 1 convolution layer to expand the feature dimension.
如图4所示,给定不同尺度上增强的特征e2 RH×W×C, FASC通过三个3 × 3卷积层和一个1 × 1卷积层估计相应的滤波器K 2 RH×W×Cd2来扩展特征维数。
The filter K is then used by FAC layers to transform the features D 2 RH×W×C in D-Decoder.
然后FAC层使用滤波器K来转换D- decoder中的特征D 2 RH×W×C。
For each element of feature D , FAC applies a convolution operator using the corresponding d × d kernel from the filter K to obtain the refined features.
对于feature D的每个元素,FAC使用filter K对应的D × D核进行卷积运算,得到精化后的feature。
We set the kernel size d to 5 at the three scales, following the same setting in Zhou et al. [52].
我们将三个尺度下的内核大小d设置为5,与Zhou等人[52]的设置相同。
4.4 损失函数
Low-light Enhancement Losses.
光线增强损失。
To provide intermediate supervision, we employ L1 loss and perceptual loss at ×8 downsampled scale.
为了提供中间监督,我们在×8下采样尺度上采用L1损失和知觉损失。
Specifically, we predict the image y^#8 for the smallest scale of LE-Encoder, and then restrict it using scale-corresponding ground truth y#8, shown as Eq. (4):
具体来说,我们预测LE-Encoder最小尺度下的图像y^#8,然后用尺度对应的ground truth y#8对其进行限制,如式(4)所示:
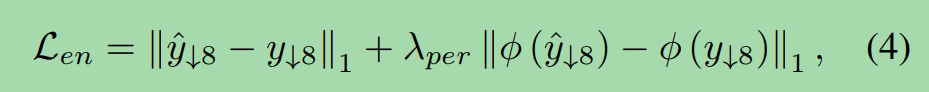
where φ(·) represents the pretrained VGG19 network.
其中φ(·)表示经过训练的VGG19网络。
We adopt multi-scale feature maps from layer fconv1;
我们采用多层fconv1的多尺度特征图;
conv4g following the widely-used setting [37].
Conv4g遵循广泛使用的设置[37]。
Due to downsampling space, the enhancement loss Len mainly supervise the exposure of intermediate output.
由于下采样空间的原因,增强损耗Len主要监控中间输出的曝光。
Deblurring Losses.
由模糊变清晰的损失。
We use the L1 loss and perceptual loss as our deblurring loss Ldeb, defined as follows:
我们使用L1损失和知觉损失作为去模糊损失Ldeb,定义如下:
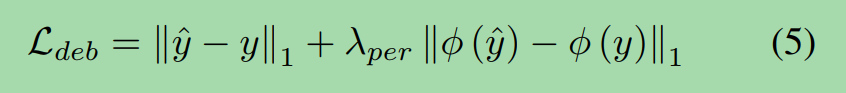
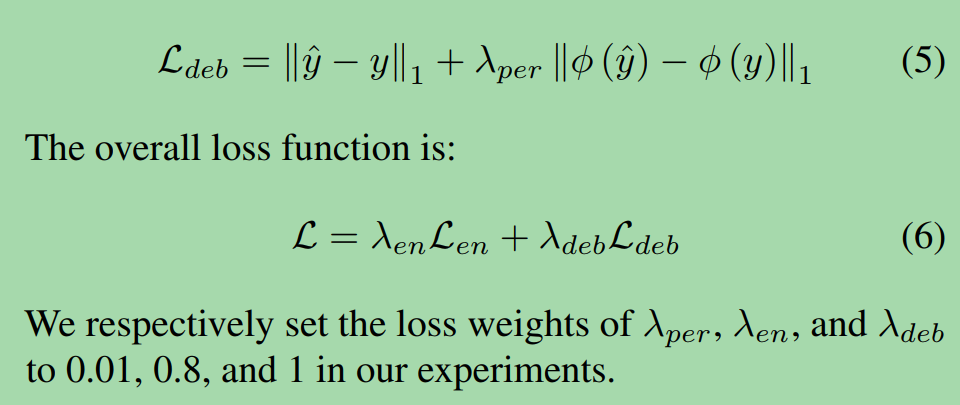
5 实验经验
Datasets and Evaluation Metrics.
数据集和评估指标。
We train our network LEDNet and other baselines using our LOL-Blur dataset.
我们使用我们的loll - blur数据集训练我们的网络LEDNet和其他基线。
170 sequences (10,200 pairs) are used for training and 30 sequences (1,800 pairs) for test.
170个序列(10200对)用于训练,30个序列(1800对)用于测试。
We adopt the commonly used PSNR and SSIM metrics for evaluation.
我们采用常用的PSNR和SSIM指标进行评价。
Experimental Settings.实验设置。
For data augmentation, we randomly crop 256×256 patches for training.
为了增加数据,我们随机裁剪256×256 patch进行训练。
All these patches are also transformed by randomly flipping and rotations of 90,180, 270◦.
所有这些补丁也被随机翻转和旋转90,180,270◦转换。
The mini-batch is set to 8.mini-batch设置为8。
We train our network using Adam optimizer with β1 = 0:9;
我们使用Adam优化器训练我们的网络β1 = 0:9;
β2 = 0:99 for a total of 500k iterations.β2 = 0:99,共500k次迭代。
The initial learning rate is set to 10−4 and updated with cosine annealing strategy [22].
初始学习速率设置为10−4,使用余弦退火策略[22]更新。
Since our LOL-Blur dataset has added defocus blurs and noise during data synthesis, we do not use extra degradation augmentation in training.
由于我们的loll - blur数据集在数据合成过程中添加了离焦模糊和噪声,我们在训练中没有使用额外的退化增强。
Due to page limit, more results and analysis are provided in the supplementary material.
由于篇幅限制,在补充材料中提供了更多的结果和分析。
Evaluation on LOL-Blur Datasetloll - blur数据集的评估
We quantitatively and qualitatively evaluate the proposed LEDNet on our LOL-Blur Dataset.
我们在我们的loll - blur数据集上定量和定性地评估了提议的LEDNet。
Since the joint task is newly-defined in this paper, there is no method available to make a comparison directly.
由于本文的联合任务是新定义的,没有直接比较的方法。
We carefully choose and combine existing representative low-light enhancement and deblurring methods, providing three types of baselines for comparisons.
我们精心选择并结合现有的代表性的弱光增强和去模糊方法,提供了三种类型的基线进行比较。
The first two types are cascade of two pretrained networks, one for enhancement and another for deblurring.
前两种是两个预训练网络的级联,一个用于增强,另一个用于去模糊。
Note that we do not retrained the cascading networks due to the unavailability of respective ground-truth for blurring and low-light.
请注意,我们没有重新训练级联网络,因为在模糊和弱光下无法获得相应的地面真相。
The models in the third type are retrained on our LOL-Blur dataset.
第三种类型的模型是在我们的loll - blur数据集上重新训练的。
Specifically, the baseline methods lay on following three categories:
具体来说,基线方法包括以下三类:
1 Enhancement to Deblurring.增强由模糊变清晰。
We choose the recent representative light enhancement networks Zero-DCE [8] and RUAS [20] followed by a state-of-the-art deblurring network MIMO-UNet [6].
我们选择了最近具有代表性的光增强网络Zero-DCE[8]和RUAS[20],然后是最先进的去模糊网络MIMO-UNet[6]。
2 Deblurring to Enhancement.去模糊增强。
For deblurring, we include a recent optimization-based method [4] particularly designed for low-light deblurring, a GAN-based network DeblurGAN-v2 [14] trained on RealBlur dataset, and a stateof-the-art deblurring network MIMO-UNet [6] trained on GoPro dataset.
在去模糊方面,我们包括了一个最新的基于优化的方法[4],特别为弱光去模糊而设计,一个基于gan的网络DeblurGAN-v2[14]在RealBlur数据集上训练,以及一个在GoPro数据集上训练的最先进的去模糊网络MIMO-UNet[6]。
Since RUAS tends to produce overexposed results in the saturated regions that may cover up previous deblurring results, we employ Zero-DCE for light enhancement in this type of baseline.
由于RUAS倾向于在饱和区域产生过度曝光的结果,这可能会掩盖之前的去模糊结果,我们在这种类型的基线中使用零dce进行光增强。
3 Networks retrained on LOL-Blur dataset.
在loll - blur数据集上重新训练网络。
We retrain some state-of-the-art baselines on our dataset using their released code.
我们使用他们发布的代码在我们的数据集上重新训练一些最先进的基线。
They include one light enhancement network DRBN [39], and three deblurring networks of DeblurGANv2 [14], DMPHN [44], and MIMO-UNet [6].
它们包括一个光增强网络DRBN[39],以及DeblurGANv2[14]、DMPHN[44]和MIMO-UNet[6]三个去模糊网络。
第一段 Quantitative Evaluations.定量评估。
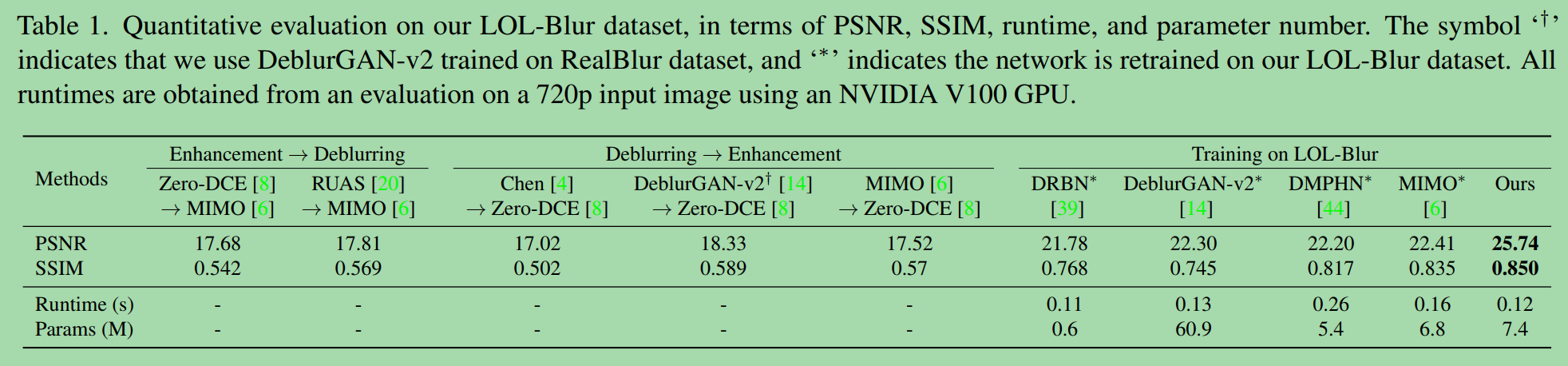
Table 1 shows quantitative results on our LOL-Blur dataset.
表1显示了我们的loll - blur数据集的定量结果。
The proposed LEDNet performs favorably against other baseline methods.
提出的LEDNet性能优于其他基线方法。
Notably, the better performance at a similar runtime cost and model size of other state-of-the-art networks.
值得注意的是,在类似的运行时成本和模型规模下,其他最先进的网络的性能更好。
The results suggest LEDNet is effective and particularly well-suited for this task due to the specially designed network structure and losses.
结果表明,由于特殊设计的网络结构和损耗,LEDNet是有效的,特别适合于这一任务。
第二段 Qualitative Evaluations.定性评估。
Figure 6 compares the proposed LEDNet model with baseline methods on LOL-Blur dataset.
图6比较了在loll - blur数据集上提出的LEDNet模型和基线方法。
It can be observed that all compared methods produce unpleasing results and suffer from serious blur artifacts, especially in saturated regions.
可以观察到,所有比较的方法都产生了令人不快的结果,并遭受严重的模糊伪影,特别是在饱和区域。
In contrast, LEDNet generates perceptually pleasant results with sharper textures.
相比之下,LEDNet产生感知愉快的结果与更清晰的纹理。

5.2 Evaluation on Real Data真实数据评价
We also collected a real test dataset that contains 240 lowlight blurry images.
我们还收集了一个包含240张微光模糊图像的真实测试数据集。
Figure 7 presents a visual comparison on this dataset.
图7显示了该数据集的可视化比较。
Apart from the baselines in Figure 6, we add a new cascading baseline composed by Hu et al. [10] and Zero-DCE.
除了图6中的基线外,我们添加了一个由Hu等人[10]和Zero-DCE组成的新的级联基线。
The methods proposed by Hu et al. [10] and Chen et al. [4] are particularly designed for low-light deblurring, however, their cascading baselines still suffer from noticeable artifacts in the presence of large saturated regions.Hu et al.[10]和Chen et al.
[4]提出的方法是专为弱光去模糊而设计的,但它们的级联基线在存在较大饱和区域时仍存在明显的伪影。
Besides, the baseline networks trained on our LOL-Blur dataset are also less effective given the real-world inputs, as their architecture are not specially designed to handle this task.
此外,在我们的loll - blur数据集上训练的基线网络在现实世界的输入下也不那么有效,因为它们的架构不是专门设计来处理这一任务的。
As shown in Figure 7, they usually suffer from undesired severe artifacts (red arrows) and blurs (yellow boxes) in their enhanced results.
如图7所示,在增强的结果中,它们通常遭受不希望的严重工件(红色箭头)和模糊(黄色框)。
Overall, LEDNet shows the best visual quality, with fewer artifacts and blurs.
总的来说,LEDNet显示了最好的视觉质量,较少的工件和模糊。
The better performance is attributed to our CurveNLU and FASC, which enable LEDNet to perform spatially-varying feature transformation for both intensity enhancement and blur removal.
更好的性能归功于我们的CurveNLU和FASC,它们使LEDNet能够进行空间变化的特征变换,以增强强度和去除模糊。
The comparisons in real cases strongly suggest the effectiveness of both our proposed dataset and network.
在实际案例中的比较强烈地表明了我们提出的数据集和网络的有效性。



5.3 Ablation Study烧蚀研究
In this subsection, we present an ablation study to demonstrate the effectiveness of the main components in data synthesis pipeline and LEDNet.
在本小节中,我们介绍了一项消融研究,以证明数据合成管道和LEDNet中主要组件的有效性。
Clipping Reverse (CR).剪切扭转(CR)。
As shown in Figure 3(b), CR in data synthesis pipeline helps generate more realistic blurs in saturated regions.
如图3(b)所示,数据合成管道中的CR有助于在饱和区域生成更加真实的模糊。
Figure 8 provides a comparison on realworld data.
图8提供了对现实数据的比较。
The figure shows that applying CR in training data generation helps the network to generalize better in blur removal around saturated regions.
从图中可以看出,在训练数据生成中应用CR可以使网络在饱和区域附近的模糊去除中得到更好的泛化。
Effectiveness of PPM.PPM的有效性。
In Table 2(a), removing PPM significantly degrades the network performance.
在表2(a)中,去除PPM显著降低了网络性能。
Other baselines without PPM suffer from artifacts in their enhanced images, as shown in Figure 7.
没有PPM的其他基线会受到增强图像中的工件的影响,如图7所示。
Effectiveness of CurveNLU.CurveNLU的有效性。
Figure 9 shows the feature enhancement rate Fin=Fout of input Fin and output Fout of CurveNLU.
图9显示了输入Fin和输出Fout的特征增强速率Fin=Fout of CurveNLU。
A saturated region tends to have a small enhancement rate, so that the output will not be over-exposed.
饱和区域往往有一个小的增强率,这样输出就不会被过度曝光。
As can be observed, feature adjustment in CurveNLU is adaptive to different regions in the image.
可以看出,CurveNLU的特征调整对图像中的不同区域是有适应性的。
The merit of CurveNLU is also validated in Table 2.
表2也验证了CurveNLU的优点。
Effectiveness of FASC Connections.FASC连接的有效性。
Comparing Table 2(c) and (e), our LEDNet with FASC connection achieves better performance compared to simple connection based on concatenation.
通过对比表2(c)和(e),我们的FASC连接的LEDNet比简单的连接方式获得了更好的性能。
This is because the saturated and unsaturated areas in the night scene follow different blur models.
这是因为夜景中的饱和和不饱和区域采用了不同的模糊模型。
The task in this paper poses more requirements of spatiallyvarying operations.
本文的任务对空间变化操作提出了更多的要求。
Effectiveness of Enhancement Loss.增强效果损失。
The intermediate enhancement loss Len is necessary in our method.
在我们的方法中,中间增强损耗是必要的。
Removing it from training harm the performance as shown in Table 2(d).
将其从训练中移除会对性能造成损害,如表2(d)所示。
6 总结
We have presented a novel data synthesis pipeline to model realistic low-light blurring.
我们提出了一种新的数据合成管道模型逼真的微光模糊。
Based on the pipeline, we built a large-scale and diverse paired dataset (LOL-Blur) for learning and benchmarking the new joint task of low-light enhancement and deblurring.
在此基础上,我们建立了一个大规模和多样化的配对数据集(LOL-Blur),用于学习和基准测试微光增强和去模糊的新联合任务。
We have also proposed a simple yet effective model, LEDNet, which performs illumination enhancement and blur removal in a single forward pass.
我们还提出了一个简单而有效的模型,LEDNet,在一个单一的前向通道中执行照明增强和模糊去除。
We showed that PPM is beneficial and introduced CurveNLU to make the learned network more stable and robust.
我们证明了PPM是有益的,并引入了CurveNLU使学习后的网络更加稳定和健壮。
We further described FASC for better deblurring.
为了更好的去模糊,我们进一步描述了FASC。
Our dataset and network offer a foundation for further exploration for low-light enhancement and deblurring in the dark.
我们的数据集和网络为进一步探索弱光增强和在黑暗中去模糊提供了基础。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号