YOLOv1学习笔记
https://zhuanlan.zhihu.com/p/24916786(大部分内容)
https://zhuanlan.zhihu.com/p/70387154(补充)
核心思想
RCNN系列核心思想是proposal(建议区域)+分类;
YOLO系列核心思想是直接在输出层回归bounding box位置和bounding box的所属类别;
大致流程
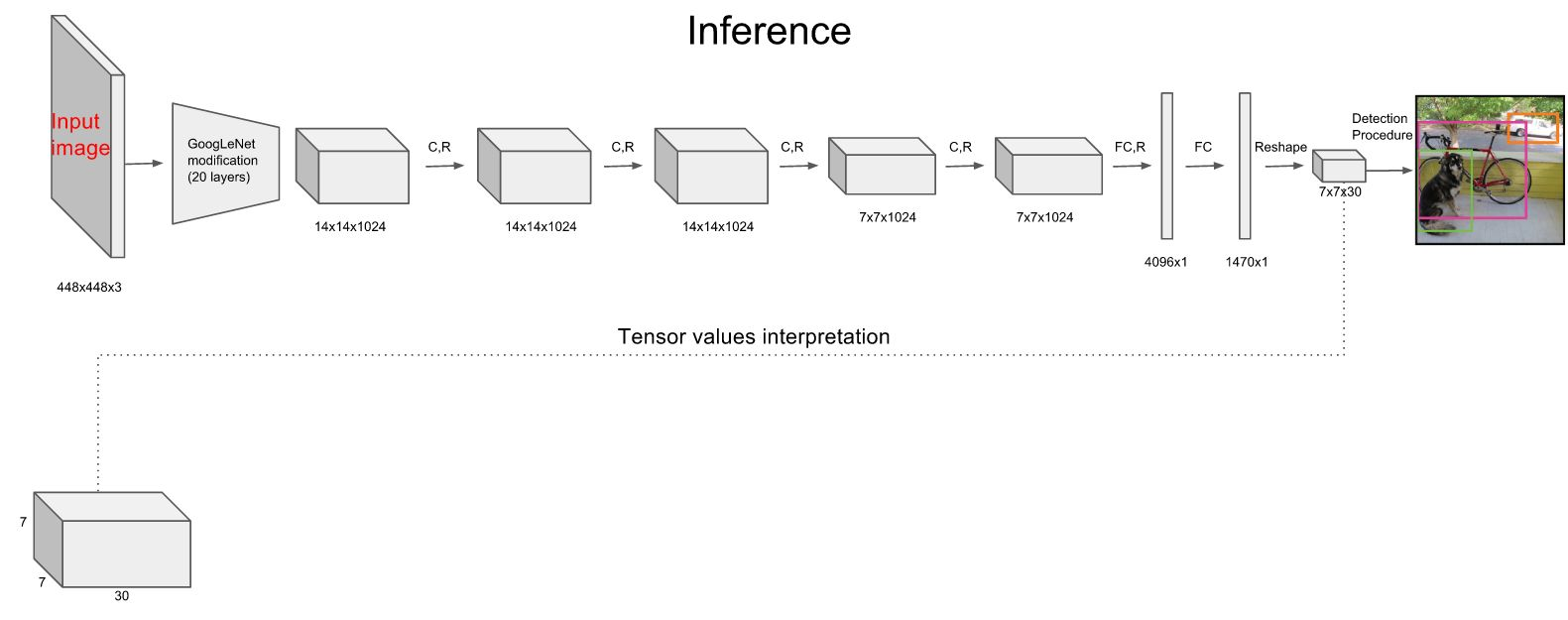
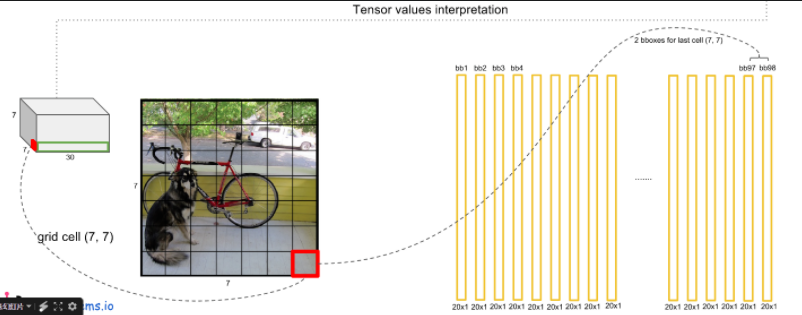
resize:图片resize成448*448,分割成7*7网格的cell;
CNN提取特征和预测:卷积负责提取特征,全连接层负责预测;(S=7,是参数可以改)
7*7*2=98个bounding box(bbox)的坐标Xcenter,Ycenter,w,h,confidence;
7*7=49个cell所属类别;(每个cell负责一个物体,所以最多可预测49个物体)
使用NMS非极大值抑制过滤bounding box数量;
网络设计
网络结构借鉴GoogleNet,由于来自《Object detection networks on convolutional feature maps》提到说在训练网络中增加卷积和全链接层可以改善性能,所以在20个卷积层的基础之上,添加了4个卷积层和2个全连接层。
检测要求细粒度的视觉信息,所以把网络输入也又224*224变成448*448。
每个网格向量
单个网格的责任
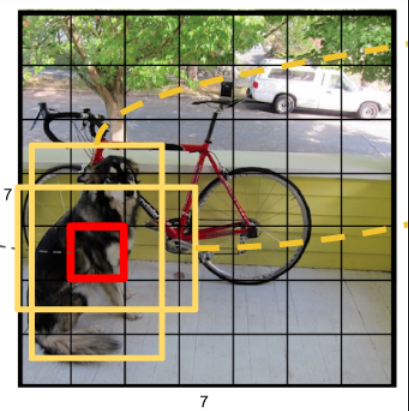
整幅图像划分为7*7的网格grid cell,若是某个物体的中心位置落在这个网格内,那么这个网格就负责预测这个物体;

坐标维度信息
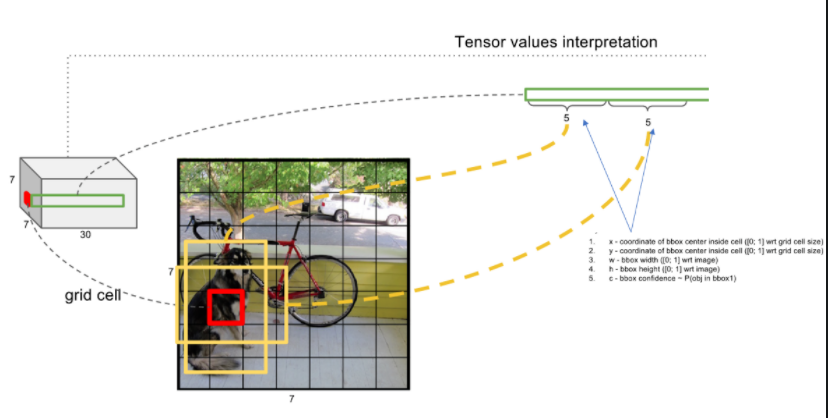
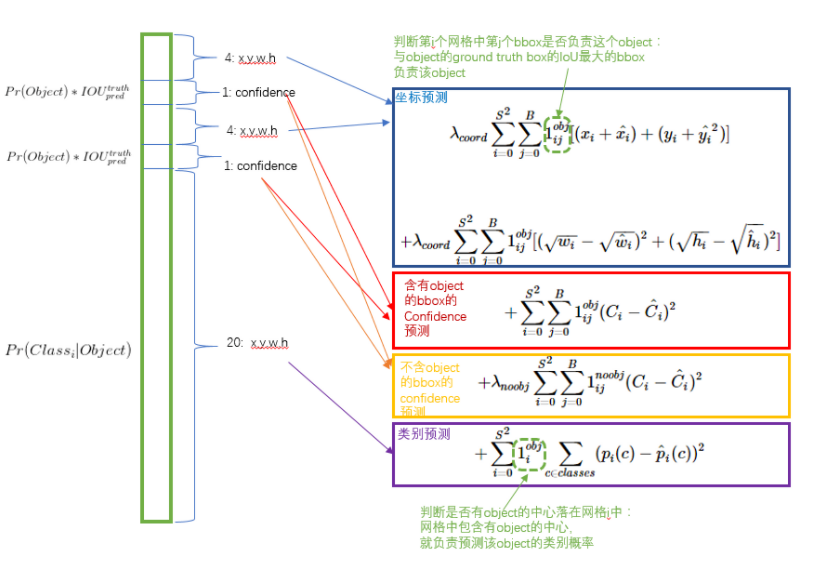
网络最后一层输出是7*7*30个维度,每个1*1*30的维度对应一个网格cell所含的信息,也就是坐标信息和confidence类别信息;
每个cell要预测2个bbox,每个bbox有(x,y,w,h,c),也就是说 2*5=10,就是1*1*30的前10个;
x,y,w,h需要归一化到0-1之间,加快网络收敛;
confidence值表示所预测的box中含有object的置信度和这个box预测准确率的两种含义;
confidence=Pr(Object)*IOU-truth/pred;
第一项表示如果cell有物体就等于1,否则等于0;
第二项表示预测bounding box和真实ground truth box的IOU值;
回归offset偏移量代替回归坐标
直接回归整数(2.3.4.6)比较困难,所以先归一化到0-1之间,然后得到(0.3,0.6)然后加上(2,4)【也就是当前cell网格的顶点坐标】就获得了当前cell负责预测物体的中心坐标了。
预测类别维度信息
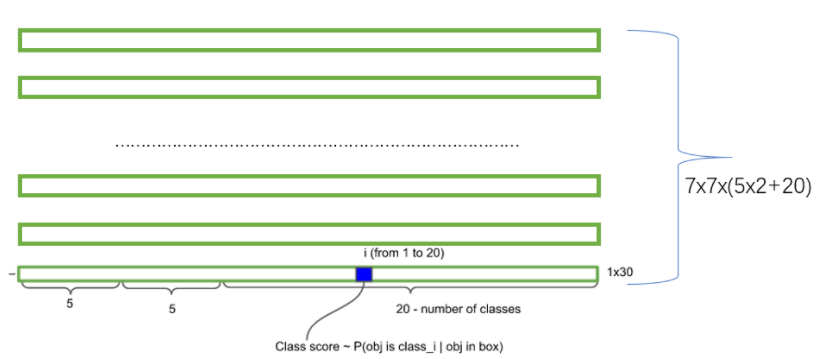
数据集一共有20个类别,所以输出就是,7*7*(5*2+20);
通用公式表示输出就是S*S(5*B+C)的一个tensor;
损失函数
位置损失
rcoord参数:为了防止背景干扰造成的训练样本样本,设置参数为5,增强正样本作用;
Yolo面临的物体检测问题,是一个典型的类别数目不均衡的问题。
此时如果不采取点措施,那么物体检测的mAP不会太高,因为模型更倾向于不含有物体的格点。
这个控制参数的作用,就是让含有物体的格点,在损失函数中的权重更大,让模型更加“重视”含有物体的格点所造成的损失。
1-obj/ij参数:第i个cell的第j个bbox有没有obj,有就是等于1,没有等于0;也就是只对那些有真实物体所属的格点进行损失计算,若该格点不包含物体,那么预测数值不对损失函数造成影响。
坐标参数是两个数相减再平方,图中有误;(简单的平方和误差)
长宽损失
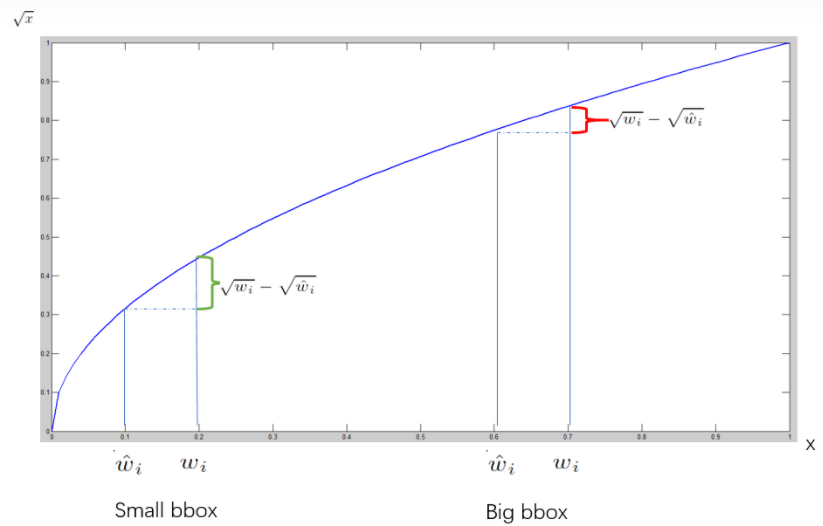
开根号参数:开根号后,小目标框表示的差值更大,更适用于小目标框对位置更敏感这一特点;
不取根号会更倾向于大尺寸的预测框。
取根号是为了尽可能的消除大尺寸框与小尺寸框之间的差异。
含obj的bbox的confidence损失
预测是物体的概率*IOU
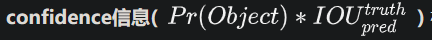
不含obj的bbox的confidence损失
rnoobj参数:设置为0.5,消除负样本影响;
类别预测损失
物体类别概率P,对应的类别位置,该标签数值为1,其余位置为0,与分类网络相同。

预测
预测某个类别
每个网格预测的class信息(Pr项)和bbox预测的confidence信息(Pr*IOU项)相乘,得到每个bbox的confidence score;
等式左边第一项就是每个网格预测的类别信息;
第二三项就是每个bounding box预测的confidence。
这个乘积的结果即encode了预测的box属于某一类的概率,也有该box准确度的信息。
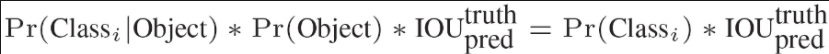
每个cell
对每一个网格的每一个bbox执行同样操作: 7x7x2 = 98 bbox (每个bbox既有对应的class信息又有坐标信息)
设阈值&NMS
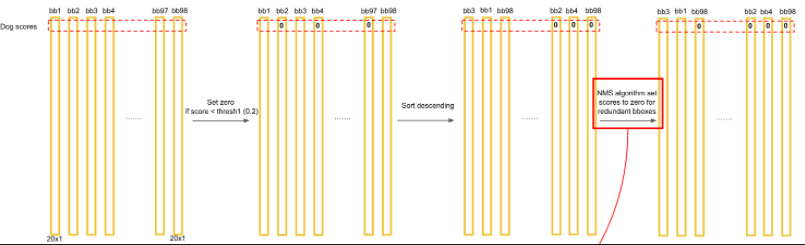
得到每个bbox的class-specific confidence score以后,设置阈值,滤掉得分低的boxes,对保留的boxes进行NMS处理,就得到最终的检测结果。
缺陷
每个cell只能预测一个物体,如果两个物体靠的比较近,检测效果不好;
固定的预测框长宽比,在遇到不常见物体的长宽时,泛化能力差;
损失函数在定位误差和检测大小物体上需要改进;
特点
位置定位错误率高,但是对背景误检率低;
对小目标效果差;
利用整幅图像预测,而不是基于滑动框的建议框做预测;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号