C语言中的字符串与字符集详解
字符集理论及应用详解
一、字符集和字符编码
1、定义
字符集(Character Set/Charset)是一个系统支持的所有抽象字符的集合。字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。[1]简单来说,字符集就是一个表。这个表有两列,一列是各种字符,另一列是每个字符锁对应的编号。注意,字符集只是一个规则,或者说是标准。它只定义每个字符对应的编码,建立字符和数字的对应关系,而不存储每个字符的图像。存储字符图像的是字体文件。可以这样理解:字体文件中存了很多张图片,每一张图片都是一个字符的样子,同时每个图片都有自己的名字(可能不止一个),这个名字就是图片中的字符在字符集中的编码。
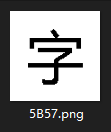
图片可以看作是字体文件中的一个字符,名字可以看作是其对应的编码(这里是Unicode字符集指定的编码)
字符编码(Character Encoding)是一套法则,使用该法则能够对自然语言的字符的一个集合(如字母表或音节表),与其他东西的一个集合(如号码或电脉冲)进行配对。即在符号集合与数字系统之间建立对应关系,它是信息处理的一项基本技术。通常人们用符号集合(一般情况下就是文字)来表达信息。而以计算机为基础的信息处理系统则是利用元件(硬件)不同状态的组合来存储和处理信息的。元件不同状态的组合能代表数字系统的数字,因此字符编码就是将符号转换为计算机可以接受的数字系统的数,称为数字代码。[1]简单来说,字符编码就是表示字符的方法。例如,如何将字符集中字符自己的编号存在计算机中。
2、常见字符集
常见字符集有两大类,分别是ANSI和Unicode。其中ANSI又包含了很多具体的字符集,例如GB2312,BIG5,Shift-JIS等。
ANSI字符集:
ANSI编码包含了一系列字符集,所以准确来讲,它并不能被叫做一个字符集。但是由于技术原因(下面会讲),这一系列字符集同时只能使用一个,所以把整个ANSI编码称作ANSI字符集来讨论也没有什么大问题。ANSI字符集比Unicode字符集出现的早,它出现的目的是去解决当时ASCII编码不够用的情况。ASCII是美国当时造出来编码英文字符的一套系统,也可以算是一种字符集。最先它使用[0,0x7f]范围内的数字来编码英文字母,标点符号以及控制字符(例如空格,换行等)。后来又添加了一些拉丁字母和乱七八糟的东西,又使用了[0x80,0xff]范围内的数字来编码。这部分被叫做ASCII扩展表。总而言之,ASCII字符集使用[0,0xff]区间内的数字为字符编码,存储起来也只需要一个字节。
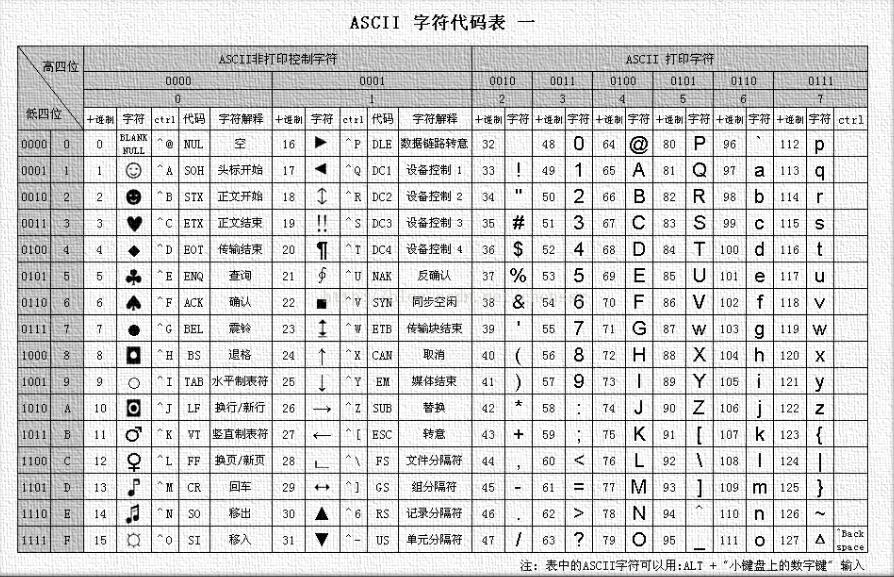
ASCII基本表
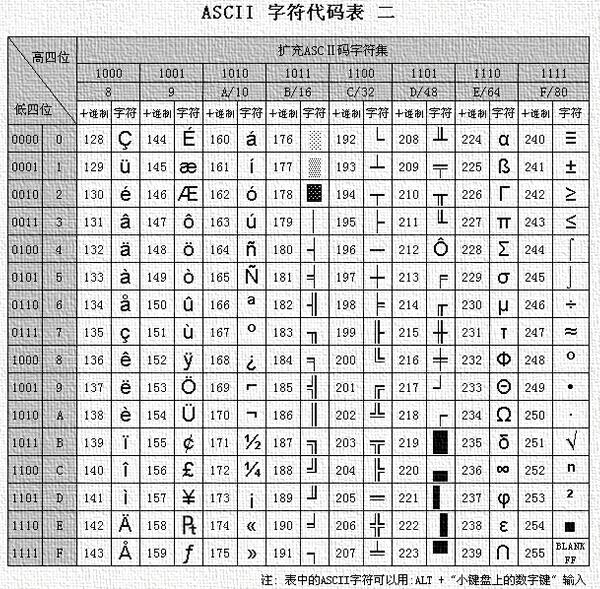
ASCII扩展表
然而,ASCII字符集仍然不能包含汉字字符。这事因为汉字真的太多了,[0,0xff]这个区间内只有255个数字,对汉字来说根本不够用。为了解决这个问题,ANSI编码出现了。ANSI规定使用两个字节来为一个字符编码,这样就包含了[0,0xffff]区间内的数字,一共可以为65536个字符编码。为了兼容之前的ASCII字符集,ANSI编码还规定,[0,0x7f]这个范围内的编码必须和ASCII字符集一样。
65536个字符虽多,但是仍然是不足以涵盖世界上所有字符的。因此,每类文字有各自不同的字符集标准,叫做代码页(Code Page)。每个代码页有不同的编码规则,因此同一个字码(数字)在不同代码页中对应不同的字符。这样的后果就是,在显示一段文字之前,必须先指定其代码页,而且同一次显示的文字只能使用同一个代码页。(如何切换代码页)
常见的代码页有:GB2312(简体中文),BIG5(繁体中文),Shift-JIS(日文)等。
代码页例子
Unicode字符集:
Unicode字符集晚于ANSI字符集出现,而它的出现彻彻底底地解决了为世界上所有文字编码的问题。Unicode字符集规定使用4个字节来为一个字符编码,理论上编码范围为[0,0xffffffff],也就是4294967296个字符(42亿)。事实上Unicode字符集并不能够包含这么多字符,也没必要。Unicode字符集只使用了[0,0x10ffff]区间内的数字为字符编码,而且还包含一些保留区间,例如[0xd800,0xdfff]区间就是为了兼容UTF-16编码格式的保留区间。它将每65536个字符编为一个平面:其中[0,0xffff]被称为基本平面,包含所有语言常用字符;[0x010000,0x10ffff]被称为扩展平面,包含其他所有的不常用字符、其他符号以及生僻语言(例如表情、小图标、楔形文字等)。
3、Unicode字符集的常见编码格式
UTF-8:
一个字符的UTF-8编码长度为1-4字节,具体长度由该字符的Unicode码确定。(编码规则见下表)
| Unicode码范围 | Unicode码(二进制) | UTF-8编码 | UTF-8编码长度(字节) |
|---|---|---|---|
| [0,0x7f] | 高位00000000 00000000 0aaaaaaa低位 | 首字节0aaaaaaa | 1 |
| [0x80,0x07ff] | 高位00000000 00000bbb bbaaaaaa低位 | 首字节110bbbbb 10aaaaaa尾字节 | 2 |
| [0x0800,0xffff] | 高位00000000 ccccbbbb bbaaaaaa低位 | 首字节1110cccc 10bbbbbb 10aaaaaa尾字节 | 3 |
| [0x010000,0x10ffff] | 高位000dddcc ccccbbbb bbaaaaaa低位 | 首字节11110ddd 10cccccc 10bbbbbb 10aaaaaa尾字节 | 4 |
举例:如何得出字符'𣱕'的UTF-8编码格式的Unicode码

'𣱕'字的资料,摘自Unicode标准文档[2]
(提示:三个字符分别为三个字型, 其字码都是相同的)
1:0x23C55在0x10000与0x10FFFF之间,它的结构应该符合上表中的第四行所描述的结构。
2:将0x23C55转为二进制,应为:
高位00000010 00111100 01010101低位
3:按照规则,进行转换:
高位00000010 00111100 01010101低位
↓ ↓ ↓
首字节11110000 10100011 10110001 10010101尾字节
得出,字符'𣱕'的UTF-8编码格式的Unicode码为:首字节0xf0 0xa3 0xb1 0x95尾字节
UTF-16:
一个字符的UTF-16编码长度为2字节或者4字节,具体长度由该字符的Unicode码确定。(编码规则见下表)
| Unicode码范围 | Unicode码 | UTF-16编码 | UTF-16编码长度(字节) |
|---|---|---|---|
| [0,0xffff] | X | 首字X的低16位(其实就是一模一样) | 2 |
| [0x010000,0x100000] | X | 首字((X-0x010000)的[10,19]位)+0xd800 ((X-0x010000)的[0,9]位)+0xdc00尾字 | 4 |
举例:如何得出字符'𣱕'的UTF-16编码格式的Unicode码
1:0x23C55在0x10000与0x10ffff之间,它的结构应该符合上表中的第四行所描述的结构。
2:将0x23c55减去0x10000, 得到0x13c55;
3:将0x13c55转为2进制:
高位00000001 00111100 01010101低位
4:按照规则,进行转换:
高位00000001 00111100 01010101低位
[10,19]位 [0,9]位
+0xd800 +0xdc00
↓ ↓ ↓
首字1101100001001111 1101110001010101尾字
得出,字符'𣱕'的UTF-16编码格式的Unicode码为:首字0xd84f 0xdc55尾字
小端:首字节0x4f 0xd8 0x55 0xdc尾字节
大端:首字节0xd8 0x4f 0xdc 0x55尾字节
UTF-32:
一个字符的UTF-16编码长度为4个字节,值与其Unicode码一模一样,只是存储分小端和大端而已。(不常用)
UCS-2
一个字符的UCS-2编码长度为2个字节,只能编码[0,0xffff]范围内的Unicode基本平面字符。值和Unicode码一样,分大小端。
UCS-4
同UTF-32。
二、程序实现
1、互相转换
引用
1. "字符集和字符编码(Charset & Encoding)" RUNOOB.COM https://www.runoob.com/w3cnote/charset-encoding.html (accessed Jun. 30, 2021)
2. The Unicode Standard, Version 13.0, 2020. [Online]. Available: https://www.unicode.org/Public/13.0.0/charts/CodeCharts.pdf

 浙公网安备 33010602011771号
浙公网安备 33010602011771号