Kmeans聚类算法原理与实现
Kmeans聚类算法
1 Kmeans聚类算法的基本原理
K-means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一。K-means算法的基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
假设要把样本集分为k个类别,算法描述如下:
(1)适当选择k个类的初始中心,最初一般为随机选取;
(2)在每次迭代中,对任意一个样本,分别求其到k个中心的欧式距离,将该样本归到距离最短的中心所在的类;
(3)利用均值方法更新该k个类的中心的值;
(4)对于所有的k个聚类中心,重复(2)(3),类的中心值的移动距离满足一定条件时,则迭代结束,完成分类。
Kmeans聚类算法原理简单,效果也依赖于k值和类中初始点的选择。
2 算法结构与实现方法
Kmeans算法相对比较简单,本次算法实现采用C++语言,作为面向对象设计语言,为保证其良好的封装性以及代码重用性。软件包含三个部分,即kmeans.h,kmeans.cpp和main.cpp。
在kmeans.h中,首先定义一个类,class KMeans,由于本算法实现需要对外部数据进行读取和存储,一次定义了一个容器Vector,其中数据类型为结构体st_point,包含三维点坐标以及一个char型的所属类的ID。其次为函数的声明。
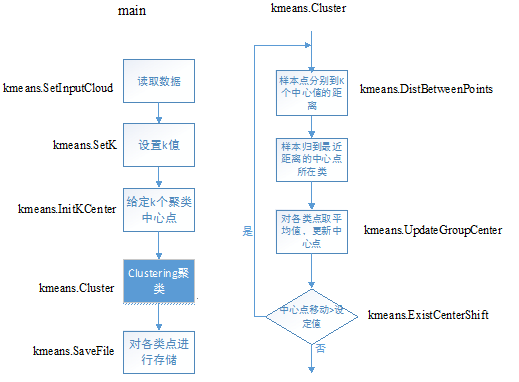 图4.1 程序基本机构与对应函数
图4.1 程序基本机构与对应函数
在kmeans.cpp中具体给出了不同功能的公有函数,如图_1中所示,函数比较细化,便于后期应用的扩展,比较具体是聚类函数:cluster,其中严格根据kmeans基本原理,聚类的相似度选用的是最简单的欧式距离,而迭代的结束判定条件选用两次中心值之间的偏差是否大于给定Dist_near_zero值。具体参见程序源代码。
3 数据描述
本次算法实验采用数据为三维点云数据,类似于实验室中三维激光扫描仪器所采得数据,形式上更为简单,整齐有规律,在cloudcompare中显示出来,如下图:

图4.2 数据原始图
数据为三维坐标系下的三个点云集,分别为球体,园面以及正方体,而test.txt文件中是一组三维的点集,是混乱的,聚类算法要做的便是将其中分类存储起来。很自然的,聚类中K值选择了3。
在软件实现时,建立了一个含有结构体类型的容器,对原始数据进行读取。
typedef struct st_point
{ st_pointxyz pnt; //st_pointxyz 为三维点结构类型数据 stru st_pointxyz
int groupID;
st_point () { }
st_point(st_pointxyz &p, int id)
{pnt = p;
groupID = id;
}
}st_point;
该数据结构类型中包含三维点数据以及所分类的ID,数据容器为vector<st_point>。
4 算法描述与源码分析
本节重点分析项目中culster聚类函数的具体代码,由于C++语言较适用于大型程序编写,本算法又相对简单,因此未免冗长,具体完整程序见项目源程序。下面只分析Kmeans原理中(2)(3)步骤的程序实现。
如下面程序源代码:
1 bool KMeans::Cluster() 2 { 3 std::vector<st_pointxyz> v_center(mv_center.size()); 4 5 do 6 { 7 for (int i = 0, pntCount = mv_pntcloud.size(); i < pntCount; ++i) 8 { 9 double min_dist = DBL_MAX; 10 int pnt_grp = 0; 11 for (int j = 0; j < m_k; ++j) 12 { 13 double dist = DistBetweenPoints(mv_pntcloud[i].pnt, mv_center[j]); 14 if (min_dist - dist > 0.000001) 15 { 16 min_dist = dist; 17 pnt_grp = j; 18 } 19 } 20 m_grp_pntcloud[pnt_grp].push_back(st_point(mv_pntcloud[i].pnt, pnt_grp)); 21 } 22 23 //保存上一次迭代的中心点 24 for (size_t i = 0; i < mv_center.size(); ++i) 25 { 26 v_center[i] = mv_center[i]; 27 } 28 29 if (!UpdateGroupCenter(m_grp_pntcloud, mv_center)) 30 { 31 return false; 32 } 33 if (!ExistCenterShift(v_center, mv_center)) 34 { 35 break; 36 } 37 for (int i = 0; i < m_k; ++i){ 38 m_grp_pntcloud[i].clear(); 39 } 40 41 } while (true); 42 43 return true; 44 }
5 算法结果分析
原数据文件test.txt中的数据被分为三类,分别存储在文件k_1,k_2,k_3中,我们对三个聚类后所得数据点云进行颜色添加后显示在cloudcompare上,得下面的显示图:

图4.3 Kmeans聚类结果
上图是在给定的初始三个聚类中心点为{ 0, 0, 0 },{ 2.5, 2.5, 2.5 },{ 3, 3, -3 }的情况下得到的结果。这是比较理想的,再看下图:

图4.4 改变初始聚类中心后的结果
本结果对应的初始三个中心点为{ 2, 2, 2 },{ -2.5, 2.5, 2.5 },{ 3, -3, -3 },很明显,数据聚类并不理想,这说明K-Means算法一定程度上初始聚类种子点,这个聚类种子点太重要,不同的随机种子点会有得到完全不同的结果。
上面改动了初始点,下面给出当k=4的聚类结果,分别取了两组不同的初始点集:

图4.5.1 k=4聚类结果1

图4.5.2 k=4聚类结果
由上述聚类结果可知,当k增加时,选取聚类初始点合适,可以得到满意的结果,如5_1所示,与最初结果相比只是将球点云聚类成了两部分,而5_2与5_1相比结果很不理想,由颜色可以看出,图中只有两类,另外两类是空的,说明k值不当,初始值不当的情况下,聚类是会失败的。
综上实验结果分析可以看出,kmeans聚类算法是一类非常快捷的聚类算法,效果也很明显,局部性较好,容易并行化,对大规模数据集很有意义。但比较依赖于k值得选定与初始聚类中心点的选择,所以该算法比较适合有人工参与的较大型聚类场合。
工程源码:http://pan.baidu.com/s/1ntN6Pjb
Kmeans聚类算法 - 开源中国社区 http://www.oschina.net/code/snippet_588162_50491
参考文献
[1] Hartigan J A, Wong M A. Algorithm AS 136: A k-means clustering algorithm[J]. Applied statistics, 1979: 100-108.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号